包阅导读总结
1. 关键词:Redis、String 类型、List 类型、业务场景、应用案例
2. 总结:本文详细介绍了 Redis 的 String 类型和 List 类型,包括其基本命令和常见业务场景应用案例,如缓存、计数器、分布式锁、限流、共享 session、消息队列、排行榜等,并提及了注意事项。
3. 主要内容:
– Redis 常见数据类型
– String 类型
– 基本命令:SET、GET、DEL、INCR、DECR 等
– 常见业务场景
– 缓存功能:缓存商品信息等
– 计数器:统计网页访问量等
– 分布式锁:保证互斥访问
– 限流:防止系统被过度访问
– 共享 session:保持多服务器登录状态
– List 类型
– 基本命令:LPUSH、RPUSH、LPOP、RPOP、LRANGE 等
– 常见业务场景
– 消息队列:处理异步任务
– 排行榜:存储和管理排行榜数据
– 注意事项
– String 类型:值最大容量、计数器原子性、分布式锁机制、对象存储等
– List 类型:性能优化、处理消息顺序和丢失问题
思维导图: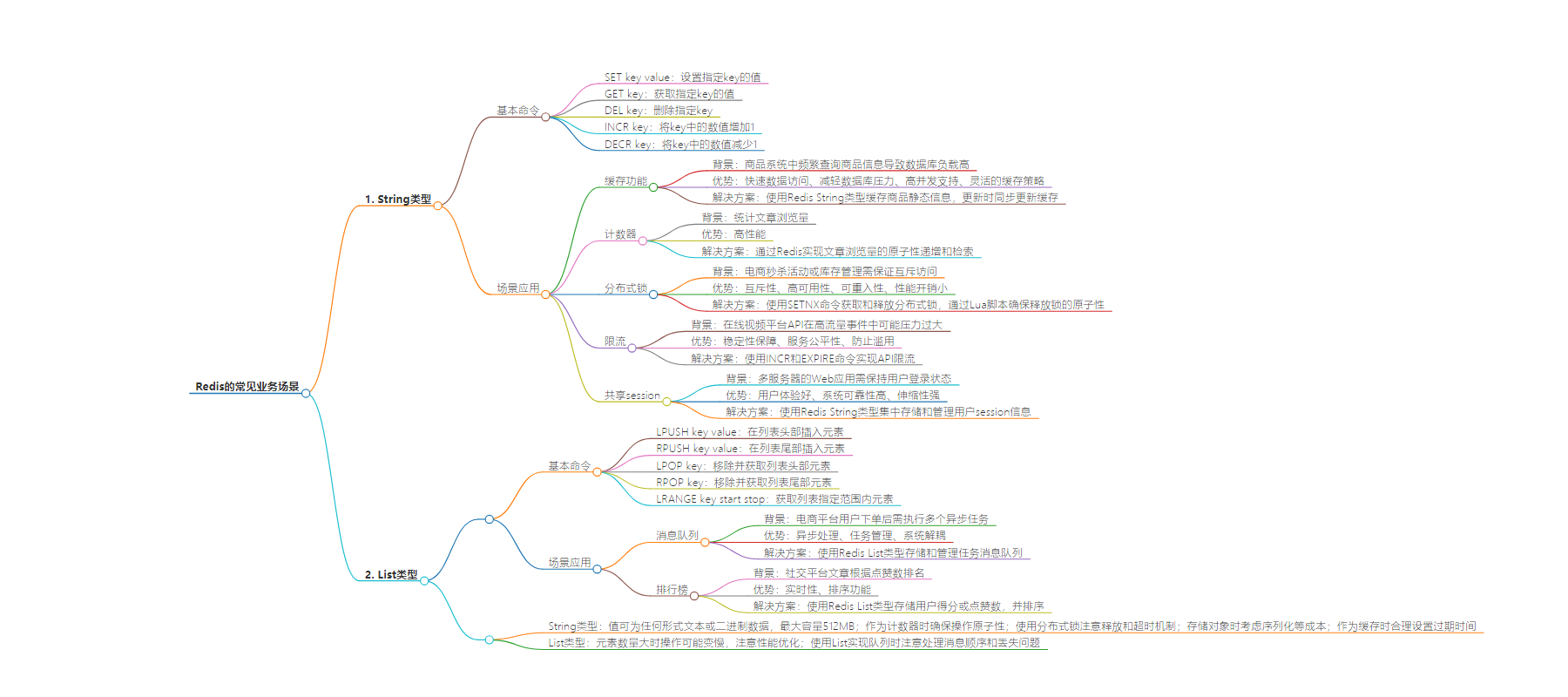
文章地址:https://mp.weixin.qq.com/s/srkd73bS2n3mjIADLVg72A
文章来源:mp.weixin.qq.com
作者:腾讯程序员
发布时间:2024/9/6 7:42
语言:中文
总字数:11191字
预计阅读时间:45分钟
评分:91分
标签:Redis,缓存,分布式锁,计数器,限流
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

作者:knightwwang1. String类型
Redis的String数据结构是一种基础的键值对类型。
-
SET key value – 设置指定 key的值。如果key已经存在,这个命令会更新它的值。
SETmyKey"myValue"
GETmyKey
DELmyKey
-
INCR key – 将
key中的数值增加1。如果key不存在,它将首先被设置为0。INCRmycounter -
DECR key – 将
key中的数值减少1。DECRmycounter
场景应用场景分析
1. 缓存功能
场景
缓存功能:String类型常用于缓存经常访问的数据,如数据库查询结果、网页内容等,以提高访问速度和降低数据库的压力 。
案例讲解
背景
在商品系统中,商品的详细信息如描述、价格、库存等数据通常不会频繁变动,但会被频繁查询。每次用户访问商品详情时,都直接从数据库查询这些信息会导致不必要的数据库负载。
优势
-
快速数据访问:Redis作为内存数据库,提供极速的读写能力,大幅降低数据访问延迟,提升用户体验。 -
减轻数据库压力:缓存频繁访问的静态数据,显著减少数据库查询,从而保护数据库资源,延长数据库寿命。 -
高并发支持:Redis设计用于高并发环境,能够处理大量用户同时访问,保证系统在流量高峰时的稳定性。 -
灵活的缓存策略:易于实现缓存数据的更新和失效,结合适当的缓存过期和数据同步机制,确保数据的实时性和一致性。
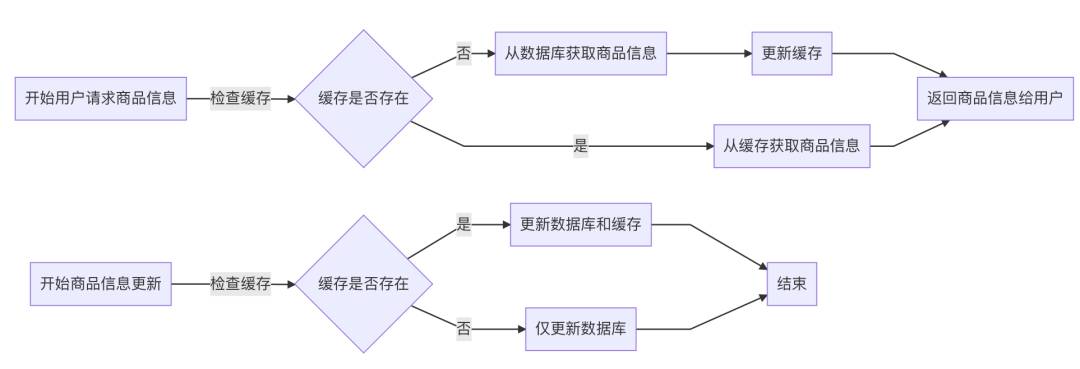
解决方案
使用Redis String类型来缓存商品的静态信息。当商品信息更新时,相应的缓存也更新或失效。
//商品信息缓存键的生成
funcgenerateProductCacheKey(productIDstring)string{
return"product:"+productID
}
//将商品信息存储到Redis缓存中
funccacheProductInfo(productIDstring,productInfomap[string]interface{}){
cacheKey:=generateProductCacheKey(productID)
//序列化商品信息为JSON格式
productJSON,_:=json.Marshal(productInfo)
//将序列化后的商品信息存储到Redis
rdb.Set(ctx,cacheKey,string(productJSON),0)//0表示永不过期,实际使用时可以设置过期时间
}
//从Redis缓存中获取商品信息
funcgetProductInfoFromCache(productIDstring)(map[string]interface{},error){
cacheKey:=generateProductCacheKey(productID)
//从Redis获取商品信息
productJSON,err:=rdb.Get(ctx,cacheKey).Result()
iferr!=nil{
returnnil,err
}
//反序列化JSON格式的商品信息
varproductInfomap[string]interface{}
json.Unmarshal([]byte(productJSON),&productInfo)
returnproductInfo,nil
}
//当商品信息更新时,同步更新Redis缓存
funcupdateProductInfoAndCache(productIDstring,newProductInfomap[string]interface{}){
//更新数据库中的商品信息
//更新Redis缓存中的商品信息
cacheProductInfo(productID,newProductInfo)
}
2. 计数器
场景
计数器:利用INCR和DECR命令,String类型可以作为计数器使用,适用于统计如网页访问量、商品库存数量等 。
案例讲解
背景
对于文章的浏览量的统计,每篇博客文章都有一个唯一的标识符(例如,文章ID)。每次文章被访问时,文章ID对应的浏览次数在Redis中递增。可以定期将浏览次数同步到数据库,用于历史数据分析。

优势
-
高性能:Redis的原子操作保证了高并发场景下的计数准确性。
解决方案
通过Redis实现对博客文章浏览次数的原子性递增和检索,以优化数据库访问并实时更新文章的浏览统计信息。
//recordArticleView记录文章的浏览次数
funcrecordArticleView(articleIDstring){
//使用Redis的INCR命令原子性地递增文章的浏览次数
result,err:=redisClient.Incr(ctx,articleID).Result()
iferr!=nil{
//如果发生错误,记录错误日志
log.Printf("Errorincrementingviewcountforarticle%s:%v",articleID,err)
return
}
//可选:记录浏览次数到日志或进行其他业务处理
fmt.Printf("Article%shasbeenviewed%dtimes\n",articleID,result)
}
//getArticleViewCount从Redis获取文章的浏览次数
funcgetArticleViewCount(articleIDstring)(int,error){
//从Redis获取文章的浏览次数
viewCount,err:=redisClient.Get(ctx,articleID).Result()
iferr!=nil{
iferr==redis.Nil{
//如果文章ID在Redis中不存在,可以认为浏览次数为0
return0,nil
}else{
//如果发生错误,记录错误日志
log.Printf("Errorgettingviewcountforarticle%s:%v",articleID,err)
return0,err
}
}
//将浏览次数从字符串转换为整数
count,err:=strconv.Atoi(viewCount)
iferr!=nil{
log.Printf("Errorconvertingviewcounttointegerforarticle%s:%v",articleID,err)
return0,err
}
returncount,nil
}
//renderArticlePage渲染文章页面,并显示浏览次数
funcrenderArticlePage(articleIDstring){
//在渲染文章页面之前,记录浏览次数
recordArticleView(articleID)
//获取文章浏览次数
viewCount,err:=getArticleViewCount(articleID)
iferr!=nil{
//处理错误,例如设置浏览次数为0或跳过错误
viewCount=0
}
}
3. 分布式锁
场景
分布式锁:通过SETNX命令(仅当键不存在时设置值),String类型可以实现分布式锁,保证在分布式系统中的互斥访问 。
案例讲解
背景
在分布式系统中,如电商的秒杀活动或库存管理,需要确保同一时间只有一个进程或线程可以修改共享资源,以避免数据不一致的问题。

优势
-
互斥性:确保同一时间只有一个进程可以访问共享资源,防止数据竞争和冲突。 -
高可用性:分布式锁能够在节点故障或网络分区的情况下仍能正常工作,具备自动故障转移和恢复的能力。 -
可重入性:支持同一个进程或线程多次获取同一个锁,避免死锁的发生。 -
性能开销:相比于其他分布式协调服务,基于Redis的分布式锁实现简单且性能开销较小。
解决方案
使用Redis的SETNX命令实现分布式锁的获取和释放,通过Lua脚本确保释放锁时的原子性,并在执行业务逻辑前尝试获取锁,业务逻辑执行完毕后确保释放锁,从而保证在分布式系统中对共享资源的安全访问。
//伪代码:在分布式系统中实现分布式锁的功能
//尝试获取分布式锁
functryGetDistributedLock(lockKeystring,valstring,expireTimeint)bool{
//使用SET命令结合NX和PX参数尝试获取锁
//NX表示如果key不存在则可以设置成功
//PX指定锁的超时时间(毫秒)
//这里的val是一个随机值,用于在释放锁时验证锁是否属于当前进程
result,err:=redisClient.SetNX(ctx,lockKey,val,time.Duration(expireTime)*time.Millisecond).Result()
iferr!=nil{
//记录错误,例如:日志记录
log.Printf("Errortryingtogetdistributedlockforkey%s:%v",lockKey,err)
returnfalse
}
//如果result为1,则表示获取锁成功,result为0表示锁已被其他进程持有
returnresult==1
}
//释放分布式锁
funcreleaseDistributedLock(lockKeystring,valstring){
//使用Lua脚本来确保释放锁的操作是原子性的
script:=`
ifredis.call("get",KEYS[1])==ARGV[1]then
returnredis.call("del",KEYS[1])
else
return0
end
`
//执行Lua脚本
result,err:=redisClient.Eval(ctx,script,[]string{lockKey},val).Result()
iferr!=nil{
//记录错误
log.Printf("Errorreleasingdistributedlockforkey%s:%v",lockKey,err)
}
//如果result为1,则表示锁被成功释放,如果为0,则表示锁可能已经释放或不属于当前进程
ifresult==int64(0){
log.Printf("Failedtoreleasethelock,itmighthavebeenreleasedbyothersorexpired")
}
}
//执行业务逻辑,使用分布式锁来保证业务逻辑的原子性
funcexecuteBusinessLogic(lockKeystring){
val:=generateRandomValue()//生成一个随机值,作为锁的值
iftryGetDistributedLock(lockKey,val,30000){//尝试获取锁,30秒超时
deferreleaseDistributedLock(lockKey,val)//无论业务逻辑是否成功执行,都释放锁
//执行具体的业务逻辑
//...
}else{
//未能获取锁,处理重试逻辑或返回错误
//...
}
}
//generateRandomValue生成一个随机值作为锁的唯一标识
funcgenerateRandomValue()string{
returnstrconv.FormatInt(time.Now().UnixNano(),10)
}
4. 限流
场景
限流:使用EXPIRE命令,结合INCR操作,可以实现API的限流功能,防止系统被过度访问 。
案例讲解
背景
一个在线视频平台提供了一个API,用于获取视频的元数据。在高流量事件(如新电影发布)期间,这个API可能会收到大量并发请求,这可能导致后端服务压力过大,甚至崩溃。

优势
-
稳定性保障:通过限流,可以防止系统在高负载下崩溃,确保核心服务的稳定性。 -
服务公平性:限流可以保证不同用户和客户端在高并发环境下公平地使用服务。 -
防止滥用:限制API的调用频率,可以防止恶意用户或爬虫对服务进行滥用。
解决方案
-
请求计数:每次API请求时,使用 INCR命令对特定的key进行递增操作。 -
设置过期时间:使用 EXPIRE命令为计数key设置一个过期时间,过期时间取决于限流的时间窗口(例如1秒)。 -
检查请求频率:如果请求计数超过设定的阈值(例如每秒100次),则拒绝新的请求或进行排队。
//伪代码:API限流器
funcrateLimiter(apiKeystring,thresholdint,timeWindowint)bool{
currentCount,err:=redisClient.Incr(ctx,apiKey).Result()
iferr!=nil{
log.Printf("ErrorincrementingAPIkey%s:%v",apiKey,err)
returnfalse
}
//如果当前计数超过阈值,则拒绝请求
ifcurrentCount>threshold{
returnfalse
}
//重置计数器的过期时间
_,err=redisClient.Expire(ctx,apiKey,timeWindow).Result()
iferr!=nil{
log.Printf("ErrorresettingexpiretimeforAPIkey%s:%v",apiKey,err)
returnfalse
}
returntrue
}
//在API处理函数中调用限流器
funchandleAPIRequest(apiKeystring){
ifrateLimiter(apiKey,100,1){//限流阈值设为100,时间窗口为1秒
//处理API请求
}else{
//限流,返回错误或提示信息
}
}
5. 共享session
场景
在多服务器的Web应用中,用户在不同的服务器上请求时能够保持登录状态,实现会话共享。
案例讲解
背景
考虑一个大型电商平台,它使用多个服务器来处理用户请求以提高可用性和伸缩性。当用户登录后,其会话信息(session)需要在所有服务器间共享,以确保无论用户请求到达哪个服务器,都能识别其登录状态。

优势
-
用户体验:用户在任何服务器上都能保持登录状态,无需重复登录。 -
系统可靠性:集中管理session减少了因服务器故障导致用户登录状态丢失的风险。 -
伸缩性:易于扩展系统以支持更多服务器,session管理不受影响。
解决方案
使用Redis的String类型来集中存储和管理用户session信息。
-
存储Session:当用户登录成功后,将用户的唯一标识(如session ID)和用户信息序列化后存储在Redis中。 -
验证Session:每次用户请求时,通过请求中的session ID从Redis获取session信息,验证用户状态。 -
更新Session:用户活动时,更新Redis中存储的session信息,以保持其活跃状态。 -
过期策略:设置session信息在Redis中的过期时间,当用户长时间不活动时自动使session失效。
//伪代码:用户登录并存储session
funcuserLogin(usernamestring,passwordstring)(string,error){
//验证用户名和密码
//创建sessionID
sessionID:=generateSessionID()
//序列化用户信息
userInfo:=map[string]string{"username":username}
serializedInfo,err:=json.Marshal(userInfo)
iferr!=nil{
//处理错误
return"",err
}
//存储session信息到Redis,设置过期时间
err=redisClient.Set(ctx,sessionID,string(serializedInfo),time.Duration(30)*time.Minute).Err()
iferr!=nil{
//处理错误
return"",err
}
returnsessionID,nil
}
//伪代码:从请求中获取并验证session
funcvalidateSession(sessionIDstring)(map[string]string,error){
//从Redis获取session信息
serializedInfo,err:=redisClient.Get(ctx,sessionID).Result()
iferr!=nil{
//处理错误或session不存在
returnnil,err
}
//反序列化用户信息
varuserInfomap[string]string
err=json.Unmarshal([]byte(serializedInfo),&userInfo)
iferr!=nil{
//处理错误
returnnil,err
}
returnuserInfo,nil
}
//伪代码:生成新的session ID
funcgenerateSessionID()string{
returnstrconv.FormatInt(time.Now().UnixNano(),36)
}
注意事项:
-
String类型的值可以是任何形式的文本或二进制数据,最大容量为512MB 。 -
在使用String类型作为计数器时,应确保操作的原子性,避免并发访问导致的数据不一致 。 -
使用分布式锁时,要注意锁的释放和超时机制,防止死锁的发生 。 -
存储对象时,应考虑序列化和反序列化的成本,以及数据的压缩和安全性 。 -
在使用String类型作为缓存时,需要合理设置过期时间,以保证数据的时效性 。
2. List(列表)类型
Redis的List数据结构是一个双向链表,它支持在头部或尾部添加和删除元素,使其成为实现栈(后进先出)或队列(先进先出)的理想选择。
基本命令
-
LPUSH key value – 在列表的头部插入元素。
LPUSHmylist"item1" -
RPUSH key value – 在列表的尾部插入元素。
RPUSHmylist"item2" -
LPOP key – 移除并获取列表头部的元素。
LPOPmylist -
RPOP key – 移除并获取列表尾部的元素。
RPOPmylist -
LRANGE key start stop – 获取列表中指定范围内的元素。
LRANGEmylist0-1
场景应用场景分析
1. 消息队列
场景
消息队列:List类型常用于实现消息队列,用于异步处理任务,如邮件发送队列、任务调度等。
案例讲解
背景
在一个电商平台中,用户下单后,系统需要执行多个异步任务,如订单处理、库存更新、发送确认邮件等。

优势
-
异步处理:使用List作为消息队列,可以将任务异步化,提高用户体验和系统响应速度。 -
任务管理:方便地对任务进行管理和监控,如重试失败的任务、监控任务处理进度等。 -
系统解耦:各个任务处理模块可以独立运行,降低系统间的耦合度。
解决方案
使用Redis List类型存储和管理任务消息队列。
//将新订单添加到订单处理队列
funcaddOrderToQueue(orderOrder){
redisClient.LPUSH(ctx,"order_queue",order.ToString())
}
//从订单处理队列中获取待处理的订单
funcgetNextOrder()(Order,error){
orderJSON,err:=redisClient.RPOP(ctx,"order_queue").Result()
iferr!=nil{
returnOrder{},err
}
varorderOrder
json.Unmarshal([]byte(orderJSON),&order)
returnorder,nil
}
//订单处理完成后,执行后续任务
funcprocessOrder(orderOrder){
//处理订单逻辑
//...
//发送确认邮件
//...
//更新库存
//...
}
2. 排行榜
场景
排行榜:使用List类型,可以存储和管理如游戏得分、文章点赞数等排行榜数据。
案例讲解
背景
在一个社交平台中,用户发表的文章根据点赞数进行排名,需要实时更新和展示排行榜。

优势
-
实时性:能够快速响应用户的点赞行为,实时更新排行榜。 -
排序功能:利用 LRANGE命令,可以方便地获取指定范围内的排行榜数据。
解决方案
使用Redis List类型存储用户的得分或点赞数,并根据需要对List进行排序。
//为文章点赞,更新排行榜
funclikeArticle(articleIDstring){
//假设每个文章都有一个对应的得分List
redisClient.INCR(ctx,"article:"+articleID+":score")
//可以进一步使用SortedSet来维护更复杂的排行榜
}
//获取文章排行榜
funcgetArticleRankings()[]Article{
articles:=[]Article{}
//遍历所有文章的得分List
//根据得分进行排序
//...
returnarticles
}
注意事项:
-
List类型在列表元素数量较大时,操作可能会变慢,需要考虑性能优化。 -
在使用List实现队列时,要注意处理消息的顺序和丢失问题。 -
可以使用 BRPOP或BLPOP命令在多个列表上进行阻塞式读取,适用于多消费者场景。
3. Set(集合)类型
Redis的Set数据结构是一个无序且元素唯一的集合,它支持集合运算,如添加、删除、取交集、并集、差集等。这使得Set类型非常适合用于实现一些需要进行成员关系测试或集合操作的场景。
基本命令
-
SADD key member – 向指定的集合添加元素。
SADDmySet"item1" -
SREM key member – 从集合中删除元素。
SREMmySet"item1" -
SISMEMBER key member – 检查元素是否是集合的成员。
SISMEMBERmySet"item1" -
SINTER key [key …] – 取一个或多个集合的交集。
SINTERmySetmyOtherSet -
SUNION key [key …] – 取一个或多个集合的并集。
SUNIONmySetmyOtherSet -
SDIFF key [key …] – 取一个集合与另一个集合的差集。
SDIFFmySetmyOtherSet
场景应用场景分析
1. 标签系统
场景
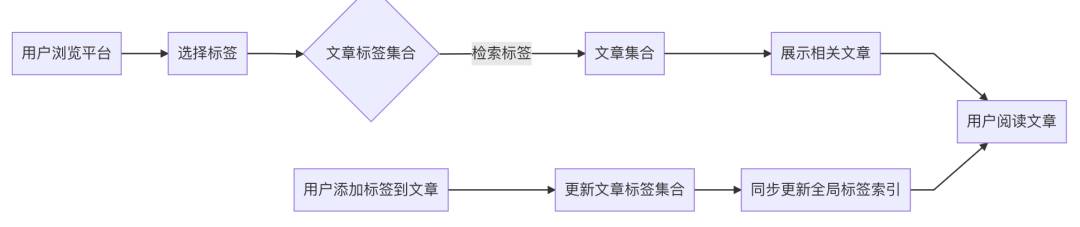
标签系统:Set类型可用于存储和处理具有标签特性的数据,如商品标签、文章分类标签等。
案例讲解
背景
在一个内容平台上,用户可以给文章打上不同的标签,系统需要根据标签过滤和推荐文章。
优势
-
快速查找:使用Set可以快速判断一个元素是否属于某个集合。 -
灵活的标签管理:方便地添加和删除标签,实现标签的灵活管理。 -
集合运算:通过集合运算,如交集和并集,可以轻松实现复杂的标签过滤逻辑。
解决方案
使用Redis Set类型存储文章的标签集合,实现基于标签的推荐和搜索。
//给文章添加标签
funcaddTagToArticle(articleIDstring,tagstring){
redisClient.SADD(ctx,"article:"+articleID+":tags",tag)
}
//根据标签获取文章列表
funcgetArticlesByTag(tagstring)[]string{
returnredisClient.SMEMBERS(ctx,"global:tags:"+tag).Val()
}
//获取文章的所有标签
funcgetTagsOfArticle(articleIDstring)[]string{
returnredisClient.SMEMBERS(ctx,"article:"+articleID+":tags").Val()
}
2. 社交网络好友关系
场景
社交网络好友关系:Set类型可以表示用户的好友列表,支持快速好友关系测试和好友推荐。
案例讲解
背景
在一个社交网络应用中,用户可以添加和删除好友,系统需要管理用户的好友关系。
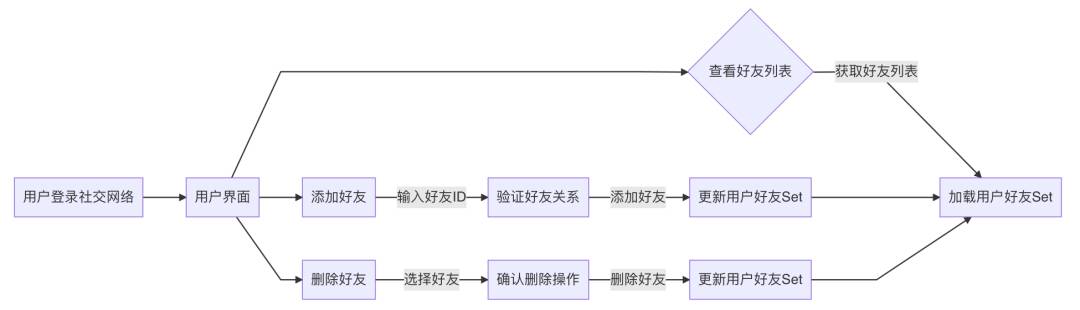
优势
-
好友推荐:利用集合运算,如差集,推荐可能认识的好友。
解决方案
使用Redis Set类型存储用户的好友集合,实现好友关系的管理。
//添加好友
funcaddFriend(userOneIDstring,userTwoIDstring){
redisClient.SADD(ctx,"user:"+userOneID+":friends",userTwoID)
redisClient.SADD(ctx,"user:"+userTwoID+":friends",userOneID)
}
//判断是否是好友
funcisFriend(userOneIDstring,userTwoIDstring)bool{
returnredisClient.SISMEMBER(ctx,"user:"+userOneID+":friends",userTwoID).Val()==1
}
//获取用户的好友列表
funcgetFriendsOfUser(userIDstring)[]string{
returnredisClient.SMEMBERS(ctx,"user:"+userID+":friends").Val()
}
注意事项:
-
虽然Set是无序的,但Redis会保持元素的插入顺序,直到集合被重新排序。 -
Set中的元素是唯一的,任何尝试添加重复元素的操作都会无效。 -
使用集合运算时,需要注意结果集的大小,因为它可能会影响性能。
4. Sorted Set类型
Redis的Sorted Set数据结构是Set的一个扩展,它不仅能够存储唯一的元素,还能为每个元素关联一个分数(score),并根据这个分数对元素进行排序。
基本命令
-
ZADD key score member – 向
key对应的Sorted Set中添加元素member,元素的分数为score。如果member已存在,则会更新其分数。ZADDmySortedSet5.0element1 -
ZRANGE key start stop [WITHSCORES] – 获取
key对应的Sorted Set中指定分数范围内的元素,可选地使用WITHSCORES获取分数。ZRANGEmySortedSet0-1WITHSCORES -
ZREM key member – 从
key对应的Sorted Set中删除元素member。ZREMmySortedSetelement1 -
ZINCRBY key increment member – 为
key中的member元素的分数增加increment的值。ZINCRBYmySortedSet2.5element1 -
ZCARD key – 获取
key对应的Sorted Set中元素的数量。ZCARDmySortedSet
场景应用场景分析
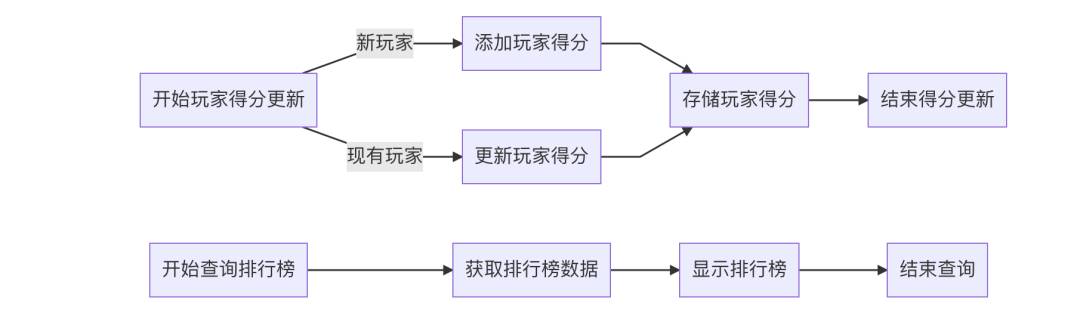
1. 排行榜系统
场景
排行榜系统:Sorted Set类型非常适合实现排行榜系统,如游戏得分排行榜、文章热度排行榜等。
案例讲解
背景
在一个在线游戏中,玩家的得分需要实时更新并显示在排行榜上。使用Sorted Set可以方便地根据得分高低进行排序。
优势
-
实时排序:根据玩家的得分自动排序,无需额外的排序操作。 -
动态更新:可以快速地添加新玩家或更新现有玩家的得分。
解决方案
使用Redis Sorted Set来存储和管理游戏玩家的得分排行榜。
//更新玩家得分
funcupdatePlayerScore(playerIDstring,scorefloat64){
sortedSetKey:="playerScores"
//添加或更新玩家得分
rdb.ZAdd(ctx,sortedSetKey,&redis.Z{Score:score,Member:playerID})
}
//获取排行榜
funcgetLeaderboard(startint,stopint)[]string{
sortedSetKey:="playerScores"
//获取排行榜数据
leaderboard,_:=rdb.ZRangeWithScores(ctx,sortedSetKey,start,stop).Result()
varresult[]string
for_,entry:=rangeleaderboard{
result=append(result,fmt.Sprintf("%s:%.2f",entry.Member.(string),entry.Score))
}
returnresult
}
2. 实时数据统计
场景
实时数据统计:Sorted Set可以用于实时数据统计,如网站的访问量统计、商品的销量统计等。
案例讲解
背景
在一个电商平台中,需要统计商品的销量,并根据销量对商品进行排序展示。
优势
解决方案
使用Redis Sorted Set来实现商品的销量统计和排序。

//更新商品销量
funcupdateProductSales(productIDstring,salesint64){
sortedSetKey:="productSales"
//增加商品销量
rdb.ZIncrBy(ctx,sortedSetKey,float64(sales),productID)
}
//获取商品销量排行
funcgetProductSalesRanking()[]string{
sortedSetKey:="productSales"
//获取销量排行数据
ranking,_:=rdb.ZRangeWithScores(ctx,sortedSetKey,0,-1).Result()
varresult[]string
for_,entry:=rangeranking{
result=append(result,fmt.Sprintf("%s:%d",entry.Member.(string),int(entry.Score)))
}
returnresult
}
注意事项:
-
Sorted Set中的分数可以是浮点数,这使得它可以用于更精确的排序需求。 -
元素的分数可以动态更新,但应注意更新操作的性能影响。 -
使用Sorted Set进行范围查询时,应注意合理设计分数的分配策略,以避免性能瓶颈。 -
在设计排行榜或其他需要排序的功能时,应考虑数据的时效性和更新频率,选择合适的数据结构和索引策略。
5. Hash类型
Redis的Hash数据结构是一种键值对集合,其中每个键(field)对应一个值(value),整个集合与一个主键(key)关联。这种结构非常适合存储对象或键值对集合。
基本命令
-
HSET key field value – 为指定的
key设置field的值。如果key不存在,会创建一个新的Hash。如果field已经存在,则会更新它的值。HSETmyHashname"JohnDoe" -
HGET key field – 获取与
key关联的field的值。HGETmyHashname -
HDEL key field – 删除
key中的field。HDELmyHashname -
HINCRBY key field increment – 将
key中的field的整数值增加increment。HINCRBYmyHashage1 -
HGETALL key – 获取
key中的所有字段和值。HGETALLmyHash
场景应用场景分析
1. 用户信息存储
场景
用户信息存储:Hash类型常用于存储和管理用户信息,如用户ID、姓名、年龄、邮箱等。
案例讲解
背景
在社交网络应用中,每个用户都有一系列属性,如用户名、年龄、兴趣爱好等。使用Hash类型可以方便地存储和查询单个用户的详细信息。
优势
-
结构化存储:将用户信息以字段和值的形式存储,易于理解和操作。 -
快速读写:Redis的Hash操作提供高速的读写性能。 -
灵活更新:可以单独更新用户信息中的某个字段,而无需重新设置整个对象。
解决方案
使用Redis Hash类型来存储和管理用户信息。当用户信息更新时,只更新Hash中的对应字段。

//存储用户信息到RedisHash
funcstoreUserInfo(userIDstring,userInfomap[string]interface{}){
hashKey:="user:"+userID
//将用户信息存储到Redis的Hash中
forfield,value:=rangeuserInfo{
rdb.HSet(ctx,hashKey,field,value)
}
}
//从RedisHash获取用户信息
funcgetUserInfo(userIDstring)map[string]string{
hashKey:="user:"+userID
//从Redis获取用户信息
fields,err:=rdb.HGetAll(ctx,hashKey).Result()
iferr!=nil{
//处理错误
returnnil
}
//将字段转换为字符串映射
varuserInfo=make(map[string]string)
fork,v:=rangefields{
userInfo[k]=v
}
returnuserInfo
}
2. 购物车管理
场景
购物车管理:Hash类型可以用于实现购物车功能,其中每个用户的购物车是一个Hash,商品ID作为字段,数量作为值。
案例讲解
背景
在电商平台中,用户的购物车需要记录用户选择的商品及其数量。使用Hash类型可以有效地管理每个用户的购物车。
优势
-
快速添加和修改:可以快速添加商品到购物车或更新商品数量。 -
批量操作:可以一次性获取或更新购物车中的多个商品。
解决方案
使用Redis Hash类型来实现购物车功能,每个用户的购物车作为一个独立的Hash存储。

//添加商品到购物车
funcaddToCart(cartIDstring,productIDstring,quantityint){
cartKey:="cart:"+cartID
//使用HINCRBY命令增加商品数量
rdb.HIncrBy(ctx,cartKey,productID,int64(quantity))
}
//获取购物车中的商品和数量
funcgetCart(cartIDstring)map[string]int{
cartKey:="cart:"+cartID
//从Redis获取购物车内容
items,err:=rdb.HGetAll(ctx,cartKey).Result()
iferr!=nil{
//处理错误
returnnil
}
//将商品ID和数量转换为映射
varcartmap[string]int
forproductID,quantity:=rangeitems{
cart[productID],_=strconv.Atoi(quantity)
}
returncart
}
注意事项:
-
Hash类型的字段值可以是字符串,最大容量为512MB。 -
在并发环境下,应确保对Hash的操作是线程安全的,可以使用事务或Lua脚本来保证。 -
存储较大的Hash时,应注意性能和内存使用情况,合理设计数据结构以避免过度膨胀。 -
定期清理和维护Hash数据,避免数据冗余和失效数据的累积。
6. Bitmap类型
Redis的Bitmap是一种基于String类型的特殊数据结构,它使用位(bit)来表示信息,每个位可以是0或1。Bitmap非常适合用于需要快速操作大量独立开关状态的场景,如状态监控、计数器等。
基本命令
-
SETBIT key offset value – 对
key指定的offset位置设置位值。value可以是0或1。SETBITmyBitmap1001 -
GETBIT key offset – 获取
key在指定offset位置的位值。GETBITmyBitmap100 -
BITCOUNT key [start end] – 计算
key中位值为1的数量。可选地,可以指定一个范围[start end]来计算该范围内的位值。BITCOUNTmyBitmap -
BITOP operation destkey key [key …] – 对一个或多个键进行位操作(AND, OR, XOR, NOT)并将结果存储在
destkey中。BITOPANDresultBitmapkey1key2
场景应用场景分析
1. 状态监控
场景
状态监控:Bitmap类型可以用于监控大量状态,例如用户在线状态、设备状态等。
案例讲解
背景
在一个大型在线游戏平台中,需要实时监控成千上万的玩家是否在线。使用Bitmap可以高效地记录每个玩家的在线状态。
优势
-
空间效率:使用位来存储状态,极大地节省了存储空间。 -
快速读写:Bitmap操作可以快速地读取和更新状态。
解决方案
使用Redis Bitmap来存储和查询玩家的在线状态。

//更新玩家在线状态
funcupdatePlayerStatus(playerIDint,isOnlinebool){
bitmapKey:="playerStatus"
offset:=playerID//假设playerID可以直接用作offset
ifisOnline{
rdb.SetBit(ctx,bitmapKey,int64(offset),1)
}else{
rdb.SetBit(ctx,bitmapKey,int64(offset),0)
}
}
//查询玩家在线状态
funccheckPlayerStatus(playerIDint)bool{
bitmapKey:="playerStatus"
offset:=playerID//假设playerID可以直接用作offset
bitValue,err:=rdb.GetBit(ctx,bitmapKey,int64(offset)).Result()
iferr!=nil{
//处理错误
returnfalse
}
returnbitValue==1
}
2. 功能开关
场景
功能开关:Bitmap类型可以用于控制功能开关,例如A/B测试、特性发布等。
案例讲解
背景
在一个SaaS产品中,需要对新功能进行A/B测试,只对部分用户开放。使用Bitmap可以快速地控制哪些用户可以访问新功能。
优势
-
易于扩展:随着用户数量的增加,Bitmap可以无缝扩展。
解决方案
使用Redis Bitmap来作为功能开关,控制用户对新功能的访问。

//为用户设置功能访问权限
funcsetFeatureAccess(userIDint,hasAccessbool){
featureKey:="featureAccess"
offset:=userID//假设userID可以直接用作offset
ifhasAccess{
rdb.SetBit(ctx,featureKey,int64(offset),1)
}else{
rdb.SetBit(ctx,featureKey,int64(offset),0)
}
}
//检查用户是否有新功能访问权限
funccheckFeatureAccess(userIDint)bool{
featureKey:="featureAccess"
offset:=userID//假设userID可以直接用作offset
bitValue,err:=rdb.GetBit(ctx,featureKey,int64(offset)).Result()
iferr!=nil{
//处理错误
returnfalse
}
returnbitValue==1
}
注意事项:
-
Bitmap使用String类型底层实现,所以它的最大容量与String类型相同,为512MB。 -
位操作可以快速执行,但应注意不要超出内存和性能的限制。 -
在设计Bitmap应用时,应考虑数据的稀疏性,以避免不必要的内存浪费。
7. HyperLogLog类型
Redis的HyperLogLog数据结构是一种概率数据结构,用于统计集合中唯一元素的数量,其特点是使用固定量的空间(通常为2KB),并且可以提供非常接近准确值的基数估计。
基本命令
-
PFADD key element [element …] – 向
key对应的HyperLogLog中添加元素。如果key不存在,会创建一个新的HyperLogLog。PFADDmyUniqueSetelement1element2 -
PFCOUNT key – 获取
key对应的HyperLogLog中的基数,即唯一元素的数量。PFCOUNTmyUniqueSet -
PFMERGE destkey sourcekey [sourcekey …] – 将多个HyperLogLog集合合并到一个
destkey中。PFMERGEmergedSetmyUniqueSet1myUniqueSet2
场景应用场景分析
1. 唯一用户访问统计
场景
唯一用户访问统计:HyperLogLog类型非常适合用来统计一段时间内访问网站或应用的唯一用户数量。
案例讲解
背景
在一个新闻门户网站,需要统计每天访问的唯一用户数量,以评估用户基础和内容的吸引力。
优势
解决方案
使用Redis HyperLogLog来统计每天访问的唯一用户数量。

//记录用户访问
funcrecordUserVisit(userIDstring){
uniqueSetKey:="uniqueVisitors"
//向HyperLogLog中添加用户ID
rdb.PFAdd(ctx,uniqueSetKey,userID)
}
//获取唯一用户访问量
funcgetUniqueVisitorCount()int64{
uniqueSetKey:="uniqueVisitors"
//获取HyperLogLog中的基数
count,_:=rdb.PFCount(ctx,uniqueSetKey).Result()
returncount
}
2. 事件独立性分析
场景
事件独立性分析:HyperLogLog可以用于分析不同事件的独立性,例如,不同来源的点击事件是否来自相同的用户群体。
案例讲解
背景
在一个广告平台,需要分析不同广告来源的点击事件是否由相同的用户群体产生。
优势
-
合并分析:可以合并多个HyperLogLog集合进行综合分析。
解决方案
使用Redis HyperLogLog来独立统计不同广告来源的点击事件,并合并集合以分析用户群体的独立性。

//记录点击事件
funcrecordClickEvent(clickIDstring,sourceIDstring){
sourceSetKey:="clicks:"+sourceID
//向对应来源的HyperLogLog中添加点击ID
rdb.PFAdd(ctx,sourceSetKey,clickID)
}
//合并点击事件集合并分析用户群体独立性
funcanalyzeAudienceIndependence(sourceIDs[]string)int64{
destKey:="mergedClicks"
//合并所有来源的HyperLogLog集合
rdb.PFMerge(ctx,destKey,sourceIDs)
//计算合并后的基数
count,_:=rdb.PFCount(ctx,destKey).Result()
returncount
}
注意事项:
-
HyperLogLog提供的是近似值,对于大多数应用场景来说已经足够准确。 -
由于HyperLogLog的特性,它不适合用于精确计数或小规模数据集的统计。 -
可以安全地将多个HyperLogLog集合合并,合并操作不会增加内存使用量,并且结果是一个更准确的基数估计。 -
在设计使用HyperLogLog的场景时,应考虑数据的更新频率和集合的数量,以确保性能和准确性。
8. GEO类型
Redis的GEO数据结构用于存储地理位置信息,它允许用户进行各种基于地理位置的操作,如查询附近的位置、计算两个地点之间的距离等。
基本命令
-
GEOADD key longitude latitude member – 向
key对应的GEO集合中添加带有经纬度的成员member。GEOADDmyGeoSet116.40752639.904030"Beijing" -
GEOPOS key member [member …] – 返回一个或多个成员的地理坐标。
GEOPOSmyGeoSet"Beijing" -
GEODIST key member1 member2 [unit] – 计算两个成员之间的距离。
GEODISTmyGeoSet"Beijing""Shanghai" -
GEOHASH key member [member …] – 返回一个或多个成员的Geohash表示。
GEOHASHmyGeoSet"Beijing" -
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] – 查询给定位置周围指定半径内的所有成员。
GEORADIUSmyGeoSet116.40752639.904030500kmWITHCOORDWITHDISTWITHHASH
场景应用场景分析
1. 附近地点搜索
场景
附近地点搜索:GEO类型可以用于实现基于地理位置的搜索功能,如查找附近的餐馆、影院等。
案例讲解
背景
在一个旅游应用中,用户需要查找当前位置附近的旅游景点。
优势
-
灵活的搜索范围:可以自定义搜索半径,适应不同的搜索需求。
解决方案
使用Redis GEO类型来实现基于用户当前位置的附近地点搜索。

//搜索附近地点
funcsearchNearbyPlaces(longitudefloat64,latitudefloat64,radiusfloat64)[]string{
geoSetKey:="touristSpots"
//执行GEORADIUS命令搜索附近地点
places,_:=rdb.GeoRadius(
ctx,geoSetKey,longitude,latitude,radius,"km",
&redis.GeoRadiusQuery{WithCoord:true,WithDist:true,WithHash:true}).Result()
varnearbyPlaces[]string
for_,place:=rangeplaces{
nearbyPlaces=append(nearbyPlaces,fmt.Sprintf("Name:%s,Distance:%.2fkm",place.Member.(string),place.Dist))
}
returnnearbyPlaces
}
2. 用户定位与导航
场景
用户定位与导航:GEO类型可以用于记录用户的地理位置,并提供导航服务。
案例讲解
背景
在一个打车应用中,需要根据司机和乘客的位置进行匹配,并提供导航服务。
优势
-
距离计算:快速计算司机与乘客之间的距离,为匹配提供依据。
解决方案
使用Redis GEO类型来记录司机和乘客的位置,并计算他们之间的距离。

//记录司机位置
funcrecordDriverPosition(driverIDstring,longitudefloat64,latitudefloat64){
geoSetKey:="drivers"
rdb.GeoAdd(ctx,geoSetKey,&redis.GeoLocation{Longitude:longitude,Latitude:latitude,Member:driverID})
}
//计算司机与乘客之间的距离并匹配
funcmatchDriverToPassenger(passengerLongitudefloat64,passengerLatitudefloat64)(string,float64){
driversGeoSetKey:="drivers"
passengerGeoSetKey:="passengers"
//记录乘客位置
rdb.GeoAdd(ctx,passengerGeoSetKey,&redis.GeoLocation{Longitude:passengerLongitude,Latitude:latitude,Member:"PassengerID"})
//搜索最近的司机
nearestDriver,_:=rdb.GeoRadius(
ctx,driversGeoSetKey,passengerLongitude,passengerLatitude,5,"km",
&redis.GeoRadiusQuery{Count:1,Any:true}).Result()
iflen(nearestDriver)>0{
//计算距离
distance:=nearestDriver[0].Dist
returnnearestDriver[0].Member.(string),distance
}
return"",0
}
注意事项:
-
GEO类型操作依赖于经纬度的准确性,因此在添加位置信息时应确保数据的准确。 -
GEO类型提供了丰富的地理位置查询功能,但应注意不同查询操作的性能影响。 -
在使用GEORADIUS等查询命令时,应考虑查询半径的大小,以平衡查询结果的准确性和性能。 -
GEO类型是Redis较新的功能,使用时应注意版本兼容性。