
包阅导读总结
1.
关键词:火山引擎云搜索、混合搜索、向量检索、图像搜索、实战过程
2.
总结:本文介绍了基于火山引擎云搜索的混合搜索实战,包括传统搜索和语义搜索的优劣势,混合搜索方案的原理及流程,还以图像搜索应用为例,展示了借助火山引擎云搜索服务快速开发混合搜索应用的具体步骤。
3.
主要内容:
– 搜索应用中的传统 Keyword Search 和 Semantic Search 各有优劣势,简单组合效果不佳。
– Keyword Search 适合精确匹配,但不考虑上下文。
– Semantic Search 基于向量检索,能理解上下文,但依赖模型与问题领域的相关性。
– 混合搜索方案能单独执行查询子句,收集分片级结果,归一化合并评分返回最终结果。
– 通常分为查询、评分归一化和合并阶段。
– 以图像搜索应用为例的火山引擎云搜索混合搜索实战
– 准备工作:创建实例集群,启用 AI 节点,选择模型,安装依赖,连接 OpenSearch。
– 具体步骤:创建 Ingest Pipeline、Search Pipeline、k-NN 索引,加载并上传数据集,进行查询示例。
思维导图: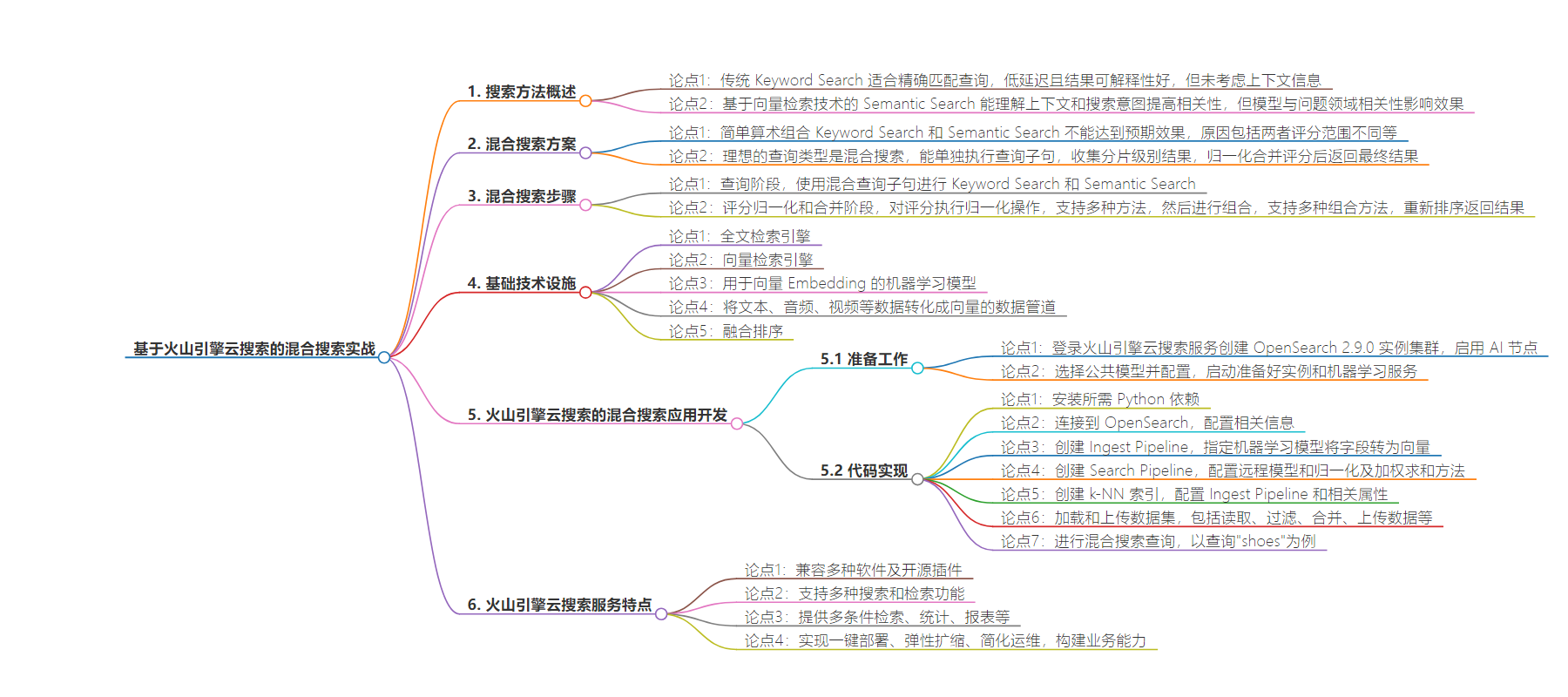
文章地址:https://mp.weixin.qq.com/s/4Atfs40Azc99pGlGk3xS5A
文章来源:mp.weixin.qq.com
作者:匡博
发布时间:2024/7/9 7:32
语言:中文
总字数:2642字
预计阅读时间:11分钟
评分:90分
标签:搜索技术,混合搜索(Hybrid Search),向量检索,文本检索,火山引擎
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
来源|字节跳动云搜索团队
Keyword Search 和 Semantic Search 都存在明显的优劣势,那么是否可以通过组合它们的优点来整体提高搜索的相关性?答案是简单的算术组合并不能收到预期的效果,主要原因有两个:
综上,我们需要寻找一种理想的查询类型来解决这些问题,它能单独执行每个查询子句,同时收集分片级别的查询结果,最后对所有查询的评分进行归一化合并后返回最终的结果,这就是混合搜索(Hybrid Search) 方案。
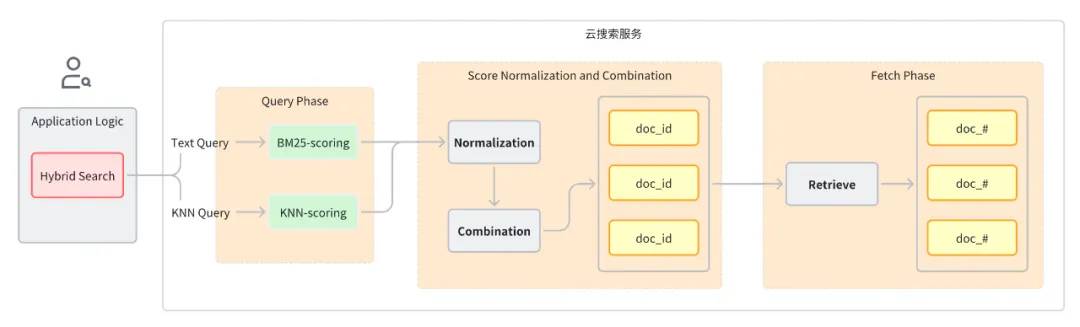
通常一次混合搜索查询可以分为以下几步:
-
查询阶段:使用混合查询子句进行 Keyword Search 和 Semantic Search。
-
评分归一化和合并阶段,该阶段在查询阶段之后。
-
由于每种查询类型都会提供不同范围的评分,该阶段对每一个查询子句的评分结果执行归一化操作,支持的归一化方法有 min_max、l2、rrf。
-
对归一化后的评分进行组合,组合方法有 arithmetic_mean、geometric_mean、harmonic_mean。
-
根据组合后的评分对文档重新排序并返回给用户。
从前面原理介绍,我们可以看到要实现一个混合检索应用,至少需要用到这些基础技术设施
-
全文检索引擎
-
向量检索引擎
-
用于向量 Embedding 的机器学习模型
-
将文本、音频、视频等数据转化成向量的数据管道
-
融合排序
火山引擎云搜索构建在开源的 Elasticsearch 和 OpenSearch 项目上,从第一天上线就支持了完善成熟的文本检索和向量检索能力,同时针对混合搜索场景也进行了一系列的功能迭代和演进,提供了开箱即用的混合搜索解决方案。本文将以图像搜索应用为例,介绍如何借助火山引擎云搜索服务的解决方案快速开发一个混合搜索应用。
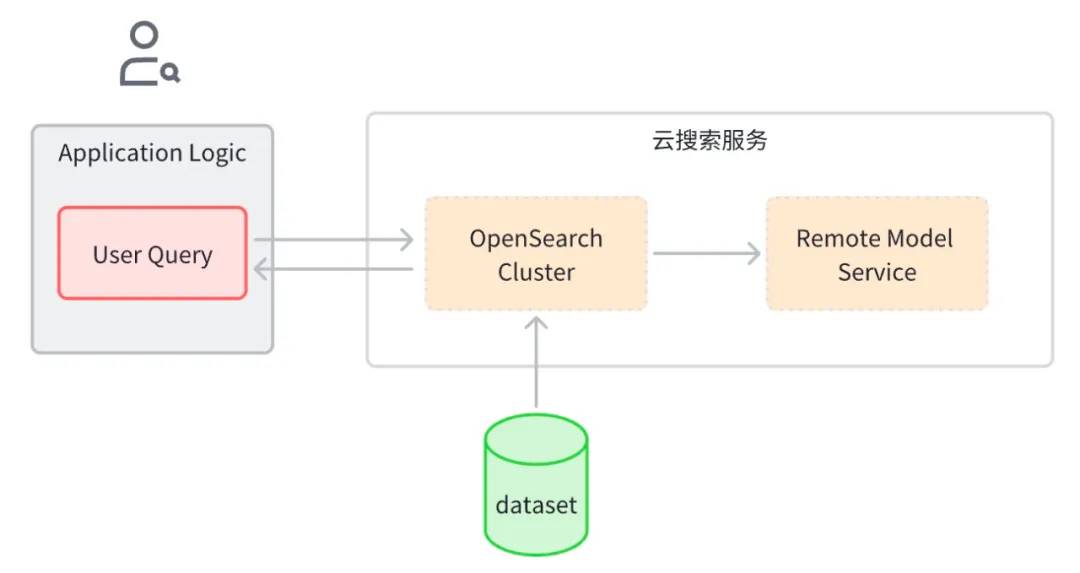
其端到端流程概括如下:
-
配置创建相关对象
-
Ingestion Pipeline:支持自动调用模型把图片转换向量并存到索引中
-
Search Pipeline:支持把文本查询语句自动转换成向量以便进行相似度计算
-
k-NN索引:存放向量的索引
-
将图像数据集数据写入 OpenSearch 实例,OpenSearch 会自动调用机器学习模型将文本转为 Embedding 向量。
-
Client 端发起混合搜索查询时,OpenSearch 调用机器学习模型将传入的查询转为 Embedding 向量。
-
OpenSearch 执行混合搜索请求处理,组合 Keyword Seach 和 Semantic Seach 的评分,返回搜索结果。
-
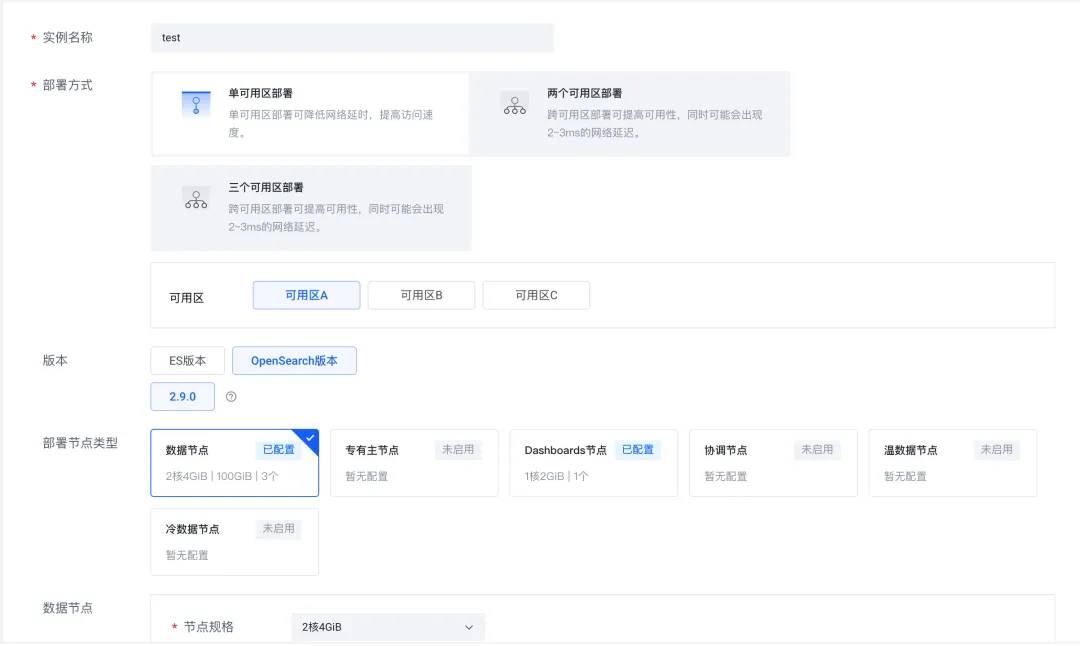
登录火山引擎云搜索服务(https://console.volcengine.com/es),创建实例集群,版本选择 OpenSearch 2.9.0。
-
待实例创建完毕,启用 AI 节点。
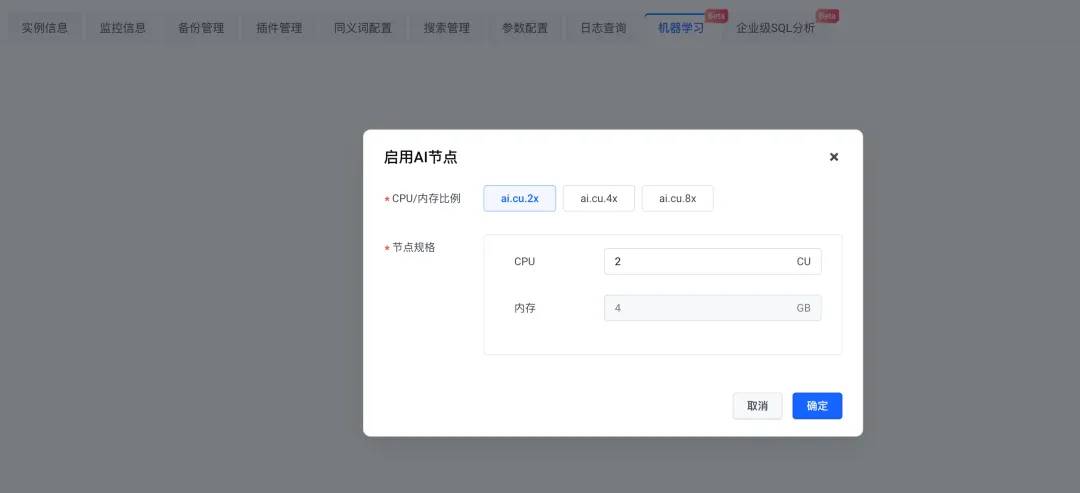
-
在模型选择上,可以创建自己的模型,也可以选择公共模型。这里我们选择公共模型,完成配置后,点击立即启动。
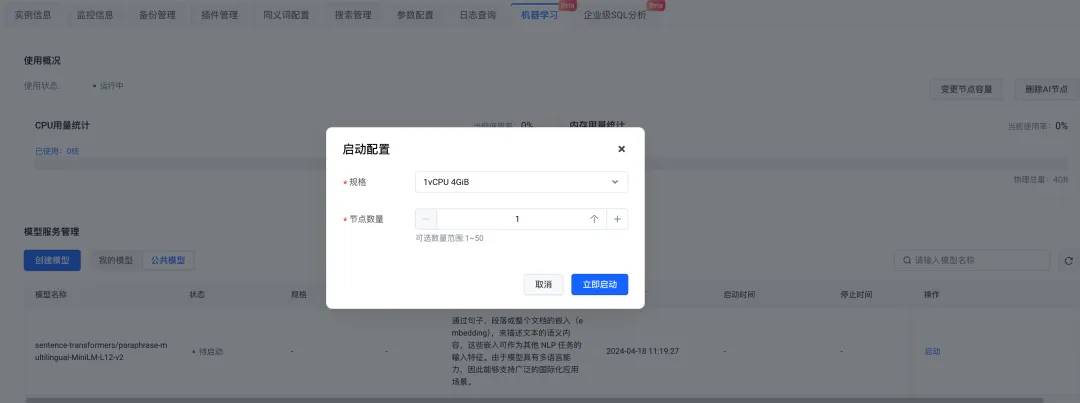
至此,准备好了 OpenSearch 实例和混合搜索所依赖的机器学习服务。
使用 Amazon Berkeley Objects Dataset(https://registry.opendata.aws/amazon-berkeley-objects/)作为数据集,数据集无需本地下载,直接通过代码逻辑上传到 OpenSearch,详见下面代码内容。
安装 Python 依赖
pip install -U elasticsearch7==7.10.1pip install -U pandaspip install -U jupyterpip install -U requestspip install -U s3fspip install -U alive_progresspip install -U pillowpip install -U ipython
连接到 OpenSearch
from elasticsearch7 import Elasticsearch as CloudSearchfromsslimportcreate_default_contextopensearch_domain = '{{ OPENSEARCH_DOMAIN }}'opensearch_port = '9200'opensearch_user = 'admin'opensearch_pwd='{{OPENSEARCH_PWD}}'model_remote_config = {"method": "POST","url": "{{ REMOTE_MODEL_URL }}","params": {},"headers": {"Content-Type": "application/json"},"advance_request_body": {"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"}}knn_dimension=384ssl_context=create_default_context(cafile='./ca.cer')cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],ssl_context=ssl_context,scheme="https",http_auth=(opensearch_user, opensearch_pwd))index_name='index-test'pipeline_id='remote_text_embedding_test'search_pipeline_id = 'rrf_search_pipeline_test'
-
填入 OpenSearch 链接地址和用户名密码信息。model_remote_config是远程机器学习模型连接配置,可在模型调用信息查看,将调用信息中的remote_config配置全部复制到model_remote_config。
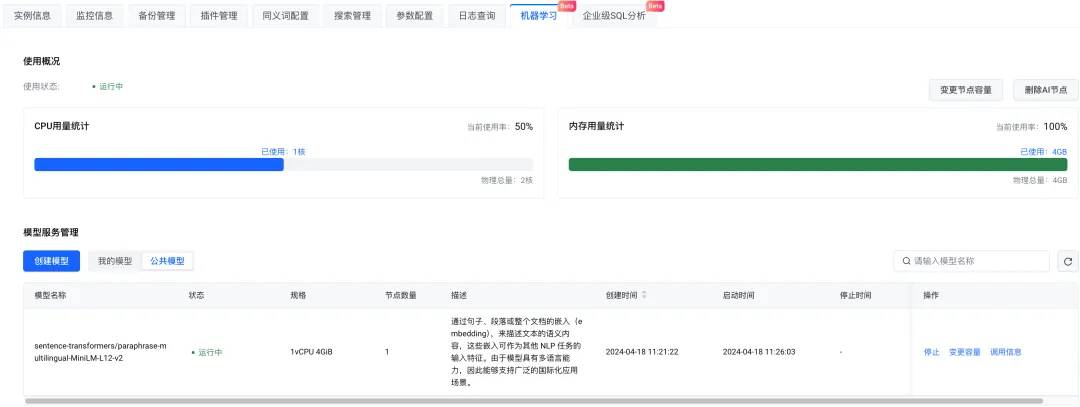
-
给定索引名称、Pipeline ID 和 Search Pipeline ID。
创建 Ingest Pipeline
pipeline_body = {"description": "text embedding pipeline for remote inference","processors": [{"remote_text_embedding": {"remote_config": model_remote_config,"field_map": {"caption": "caption_embedding"}}}]}resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)print(resp)
创建 Search Pipeline
创建查询需要使用的 Pipeline,配置好远程模型。
支持的归一化方法和加权求和方法:
这里选择 rrf 归一化方法。
importrequestssearch_pipeline_body = {"description": "post processor for hybrid search","request_processors": [{"remote_embedding": {"remote_config": model_remote_config}}],"phase_results_processors": [{"normalization-processor": {"normalization": {"technique": "rrf","parameters": {"rank_constant": 60}},"combination": {"technique": "arithmetic_mean","parameters": {"weights": [0.4,0.6]}}}}]}headers = {'Content-Type': 'application/json',}resp = requests.put(url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,auth=(opensearch_user, opensearch_pwd),json=search_pipeline_body,headers=headers,verify='./ca.cer')print(resp.text)
创建 k-NN 索引
-
将事先创建好的 Ingest Pipeline 配置到index.default_pipeline字段中; -
同时,配置 properties,将caption_embedding设置为 knn_vector,这里使用 faiss 中的 hnsw。
index_body = {"settings": {"index.knn": True,"number_of_shards": 1,"number_of_replicas": 0,"default_pipeline": pipeline_id},"mappings": {"properties": {"image_url": {"type": "text"},"caption_embedding": {"type": "knn_vector","dimension": knn_dimension,"method": {"engine": "faiss","space_type": "l2","name": "hnsw","parameters": {}}},"caption": {"type": "text"}}}}resp = cloud_search_cli.indices.create(index=index_name, body=index_body)print(resp)
加载数据集
读取数据集到内存中,并过滤出部分需要使用的数据。
import pandas as pdimport stringappended_data = []for character in string.digits[0:] + string.ascii_lowercase:if character == '1':breaktry:meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",lines=True)except FileNotFoundError:continueappended_data.append(meta)appended_data_frame=pd.concat(appended_data)appended_data_frame.shapemeta=appended_data_framedef func_(x):us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]returnus_texts[0]ifus_textselseNonemeta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]print(f"#products with US English title: {len(meta)}")meta.head()image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")dataset.head()
上传数据集
上传数据集到 Opensearch,针对每条数据,传入 image_url 和 caption。无需传入caption_embedding,将通过远程机器学习模型自动生成。
importjsonfromalive_progressimportalive_barcnt = 0batch = 0action = json.dumps({"index": {"_index": index_name}})body_=''with alive_bar(len(dataset), force_tty=True) as bar:for index, row in (dataset.iterrows()):if row['path'] == '87/874f86c4.jpg':continuepayload = {}payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']payload['caption'] = row['item_name_in_en_us']body_ = body_ + action + "\n" + json.dumps(payload) + "\n"cnt=cnt+1if cnt == 100:resp = cloud_search_cli.bulk(request_timeout=1000,index=index_name,body=body_)cnt = 0batch = batch + 1body_=''bar()print("Total Bulk batches completed: " + str(batch))
以查询shoes为例,查询中包含两个查询子句,一个是match查询,一个是remote_neural查询。查询时将事先创建好的 Search Pipeline 指定为查询参数,Search Pipeline 会将传入的文本转为向量,存储到caption_embedding字段,用于后续查询。
fromurllibimportrequestfrom PIL import ImageimportIPython.displayasdisplaydef search(text, size):resp = cloud_search_cli.search(index=index_name,body={"_source": ["image_url", "caption"],"query": {"hybrid": {"queries": [{"match": {"caption": {"query": text}}},{"remote_neural": {"caption_embedding": {"query_text": text,"k": size}}}]}}},params={"search_pipeline": search_pipeline_id},)returnrespk = 10ret = search('shoes', k)for item in ret['hits']['hits']:display.display(Image.open(request.urlopen(item['_source']['image_url'])))print(item['_source']['caption'])
以上就是以图像搜索应用为例,介绍如何借助火山引擎云搜索服务的解决方案快速开发一个混合搜索应用的实战过程,欢迎大家登陆火山引擎控制台操作!