
包阅导读总结
1. 关键词:快手、可图大模型、文生图、开源、图像生成
2. 总结:7 月 6 日快手宣布旗下文生图大模型可图全面开源,其生成效果比肩 Midjourney-v6,具备强大的复杂文本理解和文字生成能力,在多个评测中表现出色,已落地快手下游业务,开源社区反响热烈。
3.
– 快手可图大模型 Kolors 全面开源
– 开源背景及发布:7 月 6 日在世界人工智能大会上宣布
– 性能优势
– 支持中英文,生成效果比肩 Midjourney-v6
– 能理解长文本,具备中英文写字能力
– 技术特点
– 基于 U-Net 架构和隐空间扩散模型
– 引入大语言模型进行文本表征
– 训练策略
– 两阶段渐进训练
– 数据重打标和混合描述
– 评测表现
– 主观综合评分全球第二
– 图像质量评分第一
– 应用落地
– 应用于快手多个下游业务
– 普通用户可通过官网和小程序免费使用
– 开源反响
– Github 收获 2k star,Huggingface 模型下载热榜第一
– 已有开发者提供加速等应用
思维导图:
文章地址:https://mp.weixin.qq.com/s/V1ouADUM7kCCqv7VUt_v3A
文章来源:mp.weixin.qq.com
作者:可图大模型
发布时间:2024/7/11 11:24
语言:中文
总字数:2936字
预计阅读时间:12分钟
评分:82分
标签:文生图大模型,开源,中文处理,大语言模型,文本理解
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
文生图开源社区迎来重大突破:比肩Midjourney-v6的开源文生图大模型来了!

在最近的智源FlagEval文生图模型评测榜单中,可图(Kolors)凭借其卓越表现,主观综合评分全球第二,仅次于闭源的DALL-E 3。尤其在主观图像质量上,可图(Kolors)表现突出,显著优于其他开源和闭源模型,评分排名第一。
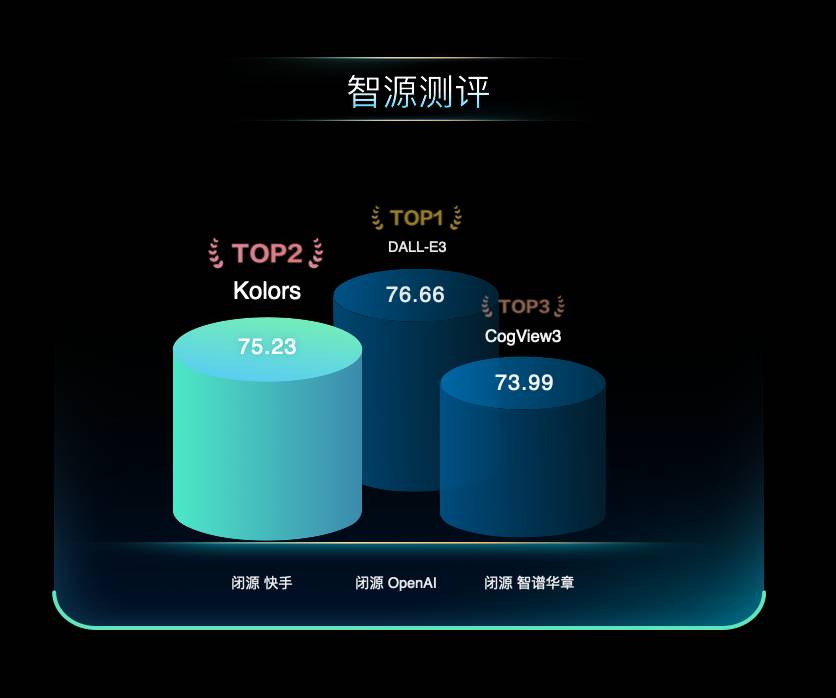
图1. 智源FlagEval评测榜单
可图(Kolors)使用了基于U-Net架构的隐空间扩散模型,并创新性地引入了大语言模型进行文本表征。这使得可图(Kolors)具备强大的复杂长文本理解能力,并且具备中英文文字生成能力。同时,通过两阶段渐进训练策略(概念学习和美感提升),可图(Kolors)在图像美感和质量上达到了国际领先水平。
可图(Kolors)开源短短几天,在Github已收获2k star,Huggingface模型下载热榜第一。引发国内外开发者广泛热议。
与当前使用英文CLIP作为文本编码器的文生图模型不同,可图(Kolors)使用了大语言模型ChatGLM3进行中英文文本表征。文本提示词长度达256字符,远超CLIP的77字符。

在大语言模型的加持下,可图(Kolors)展现出强大的复杂文本理解能力。如图2所示,面对DALL-E 3的经典提示文本,使用GLM的模型能够正确绘制多主体(如小贩和女子),并且画面中包含了所有元素(如满月、电话等)。针对文生图模型常见的颜色混淆问题,使用GLM后多种颜色的服饰与多主体能够准确对应。

图2. 复杂语义理解能力
同时,与DALL–E 3类似,可图团队对海量训练数据图像进行重打标来生成精细化文本描述。对比了多个开源多模态大语言模型,选择了效果相对较好的CogVLM进行打标。针对多模态大模型无法识别特定的概念,训练过程中采用混合描述的方式:50%用原始文本,50%用合成的文本。这种方法在SD3发表前便已应用。
可图(Kolors)的一大亮点是其文字生成能力,特别是中文写字。可图团队专门构建了一个覆盖五万余个常用汉字的中文写字数据集,包括合成数据以及真实数据。尽管DALL-E 3和SD3支持英文文字生成,但可图(Kolors)是第一个原生支持中文文字生成的文生图模型(无Control逻辑)。如图3所示,可图(Kolors)能够准确绘制简单甚至结构复杂的汉字,且文字与背景之间的贴合感弱。同时,可图(Kolors)也支持英文文字生成,并蕴含一定的设计美学与创意。

图3. 中英文文字生成能力
此外,面对SD3的超高难度复杂提示,可图(Kolors)依然表现出色,准确绘制了对应的数量、位置、颜色、英文、中文和数字等多种属性。

图4. 超高难度的复杂文本遵循能力
可图(Kolors)在主观图像质量方面的卓越表现,主要得益于其训练策略的优化。可图(Kolors)将模型训练划分成两个关键阶段:概念学习与质量微调。在概念学习阶段,可图(Kolors)使用了数十亿图像文本对进行训练,覆盖了广泛实体概念。在质量微调阶段,采用了更为精细的数据筛选机制,从海量数据中精选出数百万张兼具高质量与高美感的图像,用于对模型进行精细调整。此外,可图(Kolors)还提出了全新的加噪策略,该策略针对高分辨率图像的特性进行了优化,有效提升了模型在生成高分辨率图像时的稳定性。这一系列训练策略的优化措施大幅提升了模型的出图质量和美感。如图5所示,通过对比模型在高质量微调前后的效果,可以直观地感受到这种改进所带来的积极影响。

图5. 质量微调前后对比图
此外,如图6所示,可图(Kolors)在人像、建筑、动物、超现实、风格化、中国元素等多个类目均有出色表现。更多案例详见技术报告。

图6. 可图(Kolors)生成图像展示
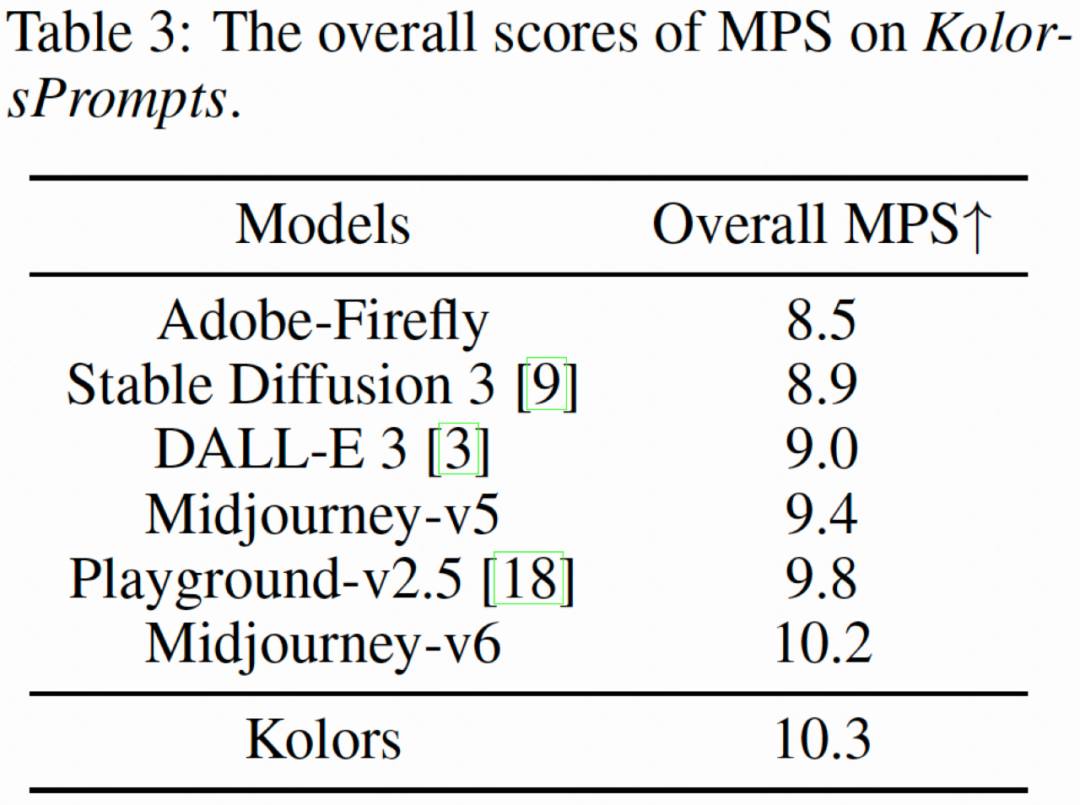
为了主观评测文生图模型的生成能力,快手可图团队提出一个新的文生图评测集合KolorsPrompts,涵盖了14个垂类并归纳出12个挑战项。模型针对每个prompt分别生成4幅图像,并邀请约50名专业评测人员对每幅图像进行5次打分,评估维度包括综合满意度、图像质量、图文相关性三个维度。从图7中可以看出,可图(Kolors)在综合满意度达到Midjourney-v6水平,特别在图像质量上,可图(Kolors)对比目前开源和闭源模型优势显著,这与智源的评估结果一致。
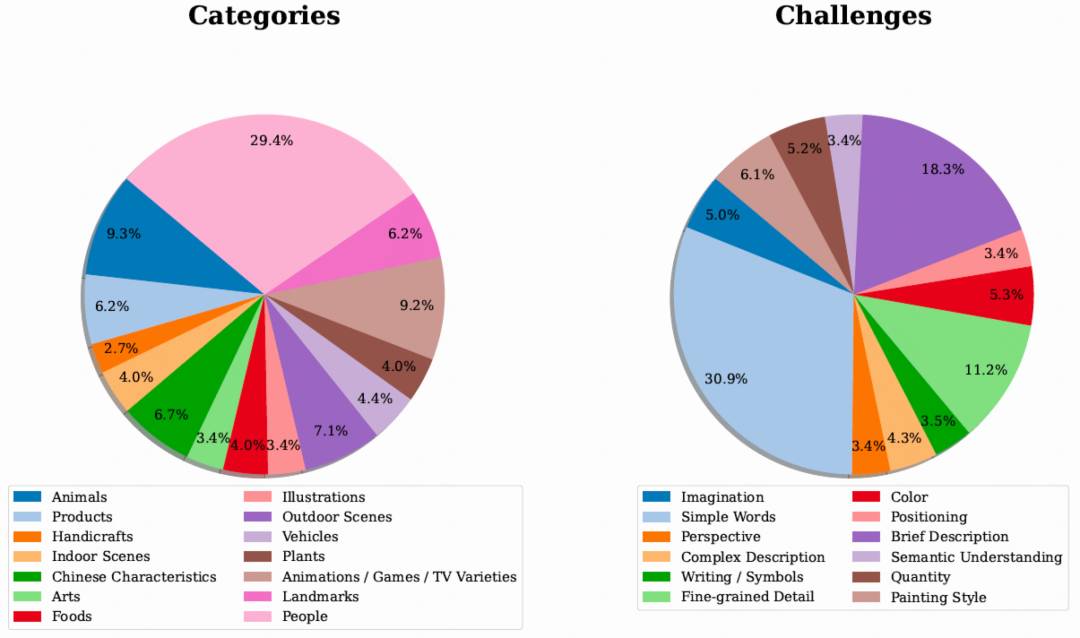
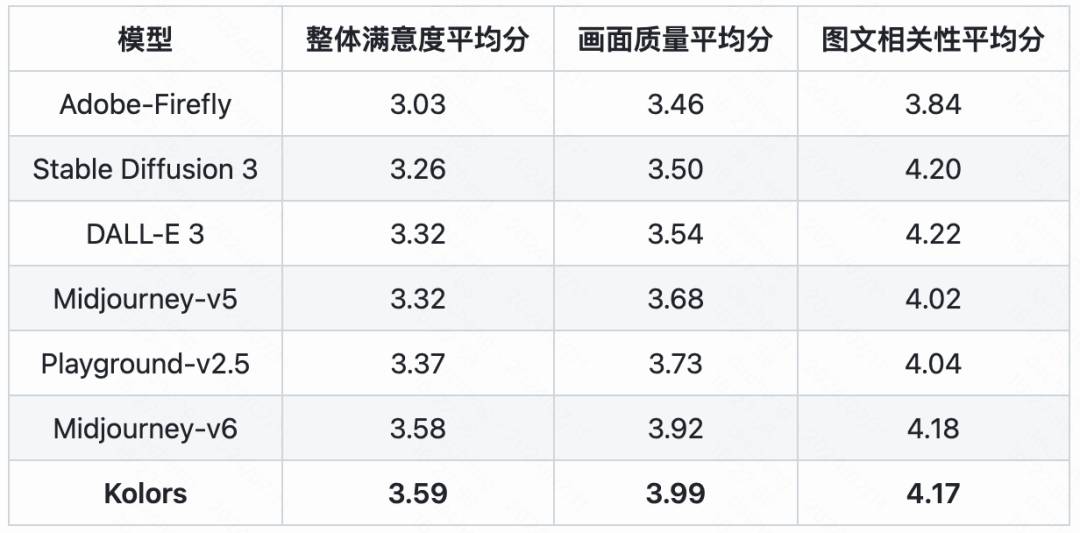
图7. KolorsPrompts评测集分布情况和人工评测结果
同时,采用快手CVPR2024最新提出的MPS (Multi-dimensional Human preference Score) 机评指标来进行模型评估。可图(Kolors)也取得了最高MPS分数,这与人工评估的指标一致。
目前,可图文生图大模型的能力已经广泛落地到快手的下游业务中,包括AI玩评、主站魔表、快影等多个场景。快手在今年5月31日完成可图大模型的对外开放,支持文生图和图生图两类功能,已上线多种风格。目前可图大模型的各项功能已经集成至可灵AI中,普通用户可以通过可灵AI官方网站和可图大模型微信小程序免费使用各项功能。
可灵AI官网链接(点击文末“阅读原文”,即可直达):
https://klingai.kuaishou.com/
👇点击下图,即可跳转至“可图大模型”小程序,快来体验吧!

应用实践 1:IP定制
使用Dreambooth & Lora实现模型微调和IP定制。下图为快手吉祥物小快和招财鸭IP。

应用实践 2:AI人像
人像ID保持,支持多种风格化人像,增加玩法趣味性。

应用实践3:虚拟试衣
开放域虚拟试穿呈现出业务落地的技术可行性,千人千面的商品素材生成从此将成为可能。

视频为动态试穿
快手此次开源了具备强大复杂语义理解和高质量图像生成能力的基座模型可图(Kolors),并计划陆续开源可图(Kolors)的相关应用,如ControlNet等。目前开源社区反响热烈,已经有开发者提供了加速、ComfyUI等应用。这一系列开源项目的产生,将为开发者提供更加全面和多样化的工具和资源,进一步丰富文生图领域的开源生态,为探索更多的应用场景和技术创新提供便利,共同推动文生图技术的进步和普及。
快手大模型与多媒体技术部,专注于快手大模型及应用的研发。凭借深厚的技术积淀,全面构建了快手大模型能力矩阵,涵盖语言、视觉、音频及多模态技术,并深度结合多元业务场景,如内容理解、短视频/直播创作、社交互动、商业化AIGC等,应用前景广阔。快手大模型与多媒体技术部、 Al Platform,诚邀你加入!
在这里你可以获得:
-
参与大模型核心研发和应用,见证和推动技术变革
-
为亿万用户带来精彩纷呈的智能体验
-
和行业算法专家并肩作战
我们期待你的加入!请发简历到:
dongbinbin@kuaishou.com;