
包阅导读总结
1.
“`
语义缓存、LLM 应用、数据处理、系统性能、智能检索
“`
2.
语义缓存能理解用户查询的含义,使数据访问更快、系统响应更智能,对 GenAI 应用至关重要。它由嵌入模型、向量数据库等关键组件构成,可提升 LLM 应用性能,通过最佳实践实现有效部署,Redis 能优化其效果,未来其作用将更关键。
3.
– 语义缓存特点
– 与传统缓存不同,理解用户查询的语义意义
– 使数据访问更快,系统响应更聪明
– 语义缓存的工作原理
– 解释和存储用户查询的语义
– 基于意图而非字面匹配检索信息
– 关键组件
– 嵌入模型:评估不同查询和响应的相似度
– 向量数据库:结构化存储嵌入数据,便于基于语义相似性快速检索
– 缓存:存储响应及其语义意义
– 向量搜索:评估查询与缓存数据的相似度以决定最佳响应
– 对 LLM 应用的影响
– 提升性能,减少计算需求,加快响应速度
– 如在聊天机器人中加快常见问题的回答速度
– 与 LLM 的集成
– 向量搜索在语义缓存框架中起关键作用
– 改善性能和效率的用例
– 自动化客户支持
– 实时语言翻译
– 内容推荐系统
– 实施的最佳实践
– 评估基础设施
– 设计考虑可扩展性和性能
– 确保准确性和一致性
– 实施步骤
– 未来展望
– 角色更关键,应对复杂查询和实时数据处理需求
– Redis 能优化语义缓存效果
思维导图: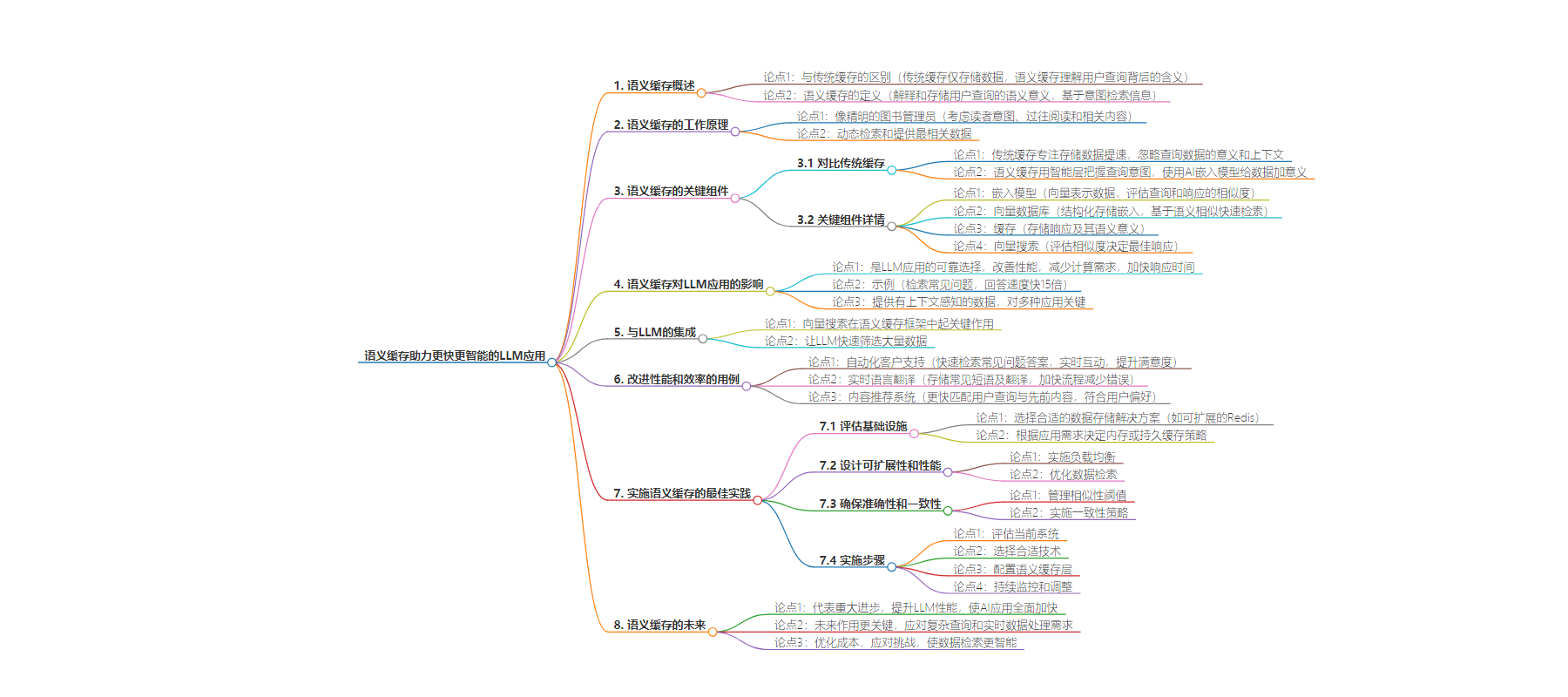
文章地址:https://redis.io/blog/what-is-semantic-caching/
文章来源:redis.io
作者:Jim Allen Wallace
发布时间:2024/7/9 21:39
语言:英文
总字数:1324字
预计阅读时间:6分钟
评分:90分
标签:语义缓存,大型语言模型 (LLM),人工智能 (AI),嵌入,向量数据库
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Unlike traditional caching, which just stores data without context, semantic caching understands the meaning behind user queries. It makes data access faster and system responses smarter, making it critical for GenAI apps.
What is semantic caching?
Semantic caching interprets and stores the semantic meaning of user queries, allowing systems to retrieve information based on intent, not just literal matches. This method allows for more nuanced data interactions, where the cache surfaces responses that are more relevant than traditional caching and faster than typical responses from Large Language Models (LLMs).
Think of semantic caching like a savvy librarian. Not only do they know where every book is – they understand the context of each request. Instead of handing out books purely by title, they consider the reader’s intent, past readings, and the most relevant content for the inquiry. Just like this librarian, semantic caching dynamically retrieves and supplies data that’s most relevant to the query at hand, making sure each response matches the user’s needs.
Make your app’s data handling faster, boost performance, and cut costs with RedisVL. Start your journey to smarter data handling with the Redis Semantic Caching User Guide.
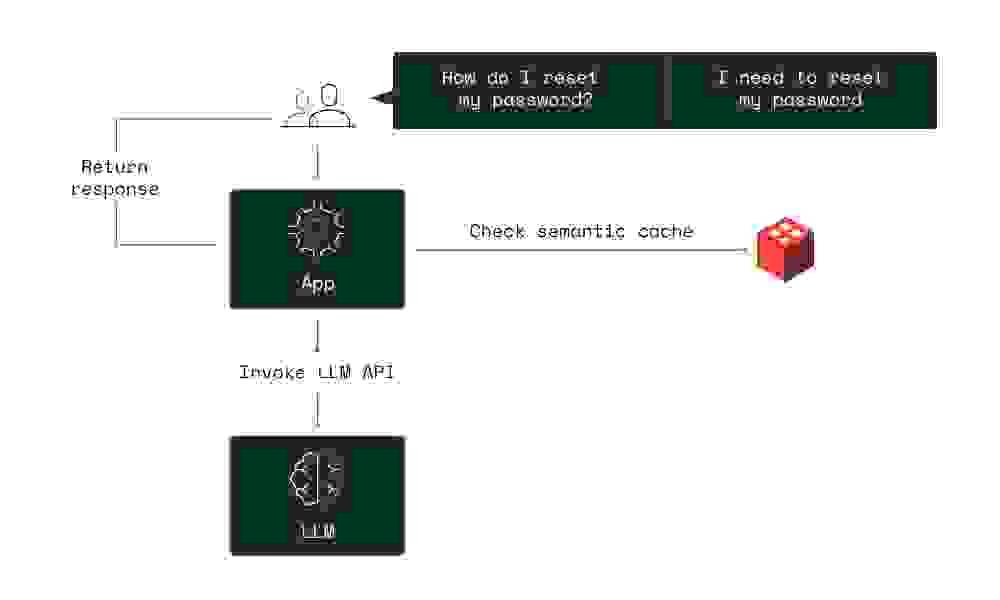
Comparing semantic caching vs traditional caching
Traditional caching focuses on temporarily storing data to make load times faster for frequently accessed information, but ignores the meaning and context of the data being queried. That’s where semantic caching comes in. It uses an intelligent layer to grasp the intent of each query, ensuring only the most relevant data is stored and retrieved. Semantic caching uses an AI embedding model to add meaning to the segment of data, making retrieval faster and more relevant. This approach cuts down on unnecessary data processing and enhances system efficiency.
Key components of semantic caching systems
- Embedding model – Semantic caching systems use embeddings. These are vector representations of data that help assess the similarity between different queries and stored responses.
- Vector database – This component stores the embeddings in a structured way. It facilitates fast retrieval based on semantic similarity instead of using exact matches.
- Cache – The central storage for cached data, where responses and their semantic meaning are stored for future use and fast retrieval.
- Vector search – A key process in semantic caching, this step involves evaluating the similarity between incoming queries and existing data in the cache to decide the best response– fast.
These components boost app performance with faster, more context-aware responses. The integration of these elements into LLMs transforms how models interact with large datasets, making semantic caching an important part of modern AI systems.
Making LLM apps fast – The impact of semantic caching
Semantic caching is a solid choice for LLM-powered apps. LLMs process a wide range of queries requiring fast, accurate, and context-aware responses. Semantic caching improves performance by efficiently managing data, cutting down computational demands, and delivering faster response times.
One example is using semantic caching to retrieve frequently-asked questions. In this chatbot example, users ask questions about internal source files like IRS filing documents, and get answers back 15X faster.
With context-aware data a top priority, semantic caching helps AI systems deliver not just faster, but more relevant responses. This is key for apps ranging from automated customer service to complex analytics in research.
Integrating semantic caching with LLMs
In apps with LLMs, vector search plays a crucial role in semantic caching frameworks. It lets LLMs sift through vast amounts of data fast, finding the most relevant information by comparing vectors for user queries and cached responses.
Improving performance & efficiency – use cases
Semantic caching gives AI apps a serious performance boost. Here are a few use cases that show offits power:
- Automated customer support – In customer service, semantic caching makes answer retrieval to FAQs fast. Interaction is now real-time and responses are context-aware, boosting user satisfaction.
- Real-time language translation – In language translation apps, semantic caching helps store common phrases and their translations. This reuse of cached data makes the translation process faster and reduces errors, enhancing the overall user experience.
- Content recommendation systems – In recommendation engines, semantic caching matches user queries with previously queried or viewed content faster. This not only speeds up the recommendation process but also ensures that the content is aligned with user preferences.
Best practices for implementing semantic caching
Assessing your infrastructure
Effective implementation of semantic caching starts with choosing the right infrastructure. Some key considerations include:
- Data storage solutions – Opt for scalable storage solutions like Redis that can handle large volumes of data and support fast data retrieval. These systems are adept at managing the complex data structures necessary for semantic caching.
- Caching strategies – Decide between in-memory and persistent caching based on the application’s needs. In-memory caching offers faster access times but at a higher cost and with limitations on data volume. Persistent caching, while slower, can handle larger data sets and ensures data durability.
Designing for scalability & performance
To ensure that your semantic caching systems can handle increasing loads and maintain high performance, consider the following strategies:
- Load balancing – Implement load balancing to distribute queries effectively across the system, preventing any single part of the system from becoming a bottleneck.
- Data retrieval optimization – Use efficient algorithms for data retrieval that minimize latency. This includes optimizing the way data is indexed and queried in your vector and cache stores.
Ensuring accuracy & consistency
Maintaining accuracy and consistency in responses is essential, especially in dynamic environments where data and user interactions continuously evolve.
- Similarity thresholds – Manage similarity thresholds carefully to balance between response accuracy and the breadth of cached responses. Too tight a threshold may limit the usefulness of the cache while too loose a threshold might reduce the relevance of responses.
- Consistency strategies – Implement strategies to ensure that cached data remains consistent with the source data. This may involve regular updates and checks to align cached responses with current data and query trends.
Implementing semantic caching
To wrap these practices into a coherent implementation strategy, you can follow these steps:
- Step 1: Assess your current system’s capabilities and determine the need for scalability, response time, and cost improvement.
- Step 2: Choose appropriate caching and storage technologies that align with your system’s demands and budget.
- Step 3: Configure your semantic caching layer, focusing on key components like LLM wrappers, vector databases, and similarity searches.
- Step 4: Continuously monitor and adjust similarity thresholds and caching strategies to adapt to new data and changing user behavior patterns.
By following these best practices, organizations can harness the full potential of semantic caching, leading to enhanced performance, improved user experience, and greater operational efficiency.
A new era for apps
Semantic caching represents a big leap forward, boosting the performance of LLMs and making AI apps faster across the board. By intelligently managing how data is stored, accessed, and reused, semantic caching reduces computational demands, makes response times real-time, and ensures that outputs are both accurate and context-aware. In data-heavy environments, fast and relevant responses are everything.
As we look to the future, the role of semantic caching is set to become even more critical. Queries are getting more complex and the increasing need for real-time data processing demand more sophisticated caching strategies. GenAI processing and post-processing is getting more complex and time-consuming, requiring strategies to accelerate responses. As models become more powerful and compute costs to use the best models rise, companies will only continue to optimize their spend. Semantic caching is ready to tackle these challenges head-on, making data retrieval faster and more intelligent.
Use smarter tools. Get faster results.
To get the most out of semantic caching, you need robust and versatile tools. Redis, the world’s fastest data platform, takes your semantic caching strategy to real-time. With high-performance data handling and support for diverse data structures, Redis optimizes responsiveness and efficiency, making your GenAI apps fast.