
包阅导读总结
1.
“`
RAG系统、文档解析、非结构化数据、版面恢复、表格识别
“`
2.
RAG系统可解决专业领域问答,其核心组件是知识数据库,需将非结构化文档解析为结构化数据。重点介绍了docx和pdf的文件结构与解析方式,以及开源的pdf解析工具Papermage,还提到了版面元素恢复、表格识别、阅读顺序还原等关键问题。
3.
– RAG系统
– 解决专业领域问答
– 核心组件是知识数据库
– 需将非结构化文档转换为结构化数据
– 文档格式与解析
– docx格式
– 遵循Office Open XML标准
– 可按标准读取底层xml文件
– 解析开源工具多
– doc格式
– 是OLE复合文档
– 转换为docx文件解析
– pdf格式
– 倾向阅读和打印
– 需额外版面恢复和表格识别操作
– 开源工具Papermage
– 三步解析pdf
– 纯文本提取
– 视觉标注
– 字符级标注
– 总结开源工具优缺点
– 关键问题
– 版面元素恢复
– 表格结构识别
– 阅读顺序还原
– RAG文档解析能力已在阿里云搜索开发工作台发布,新用户有免费开通及调用额度等服务。
思维导图: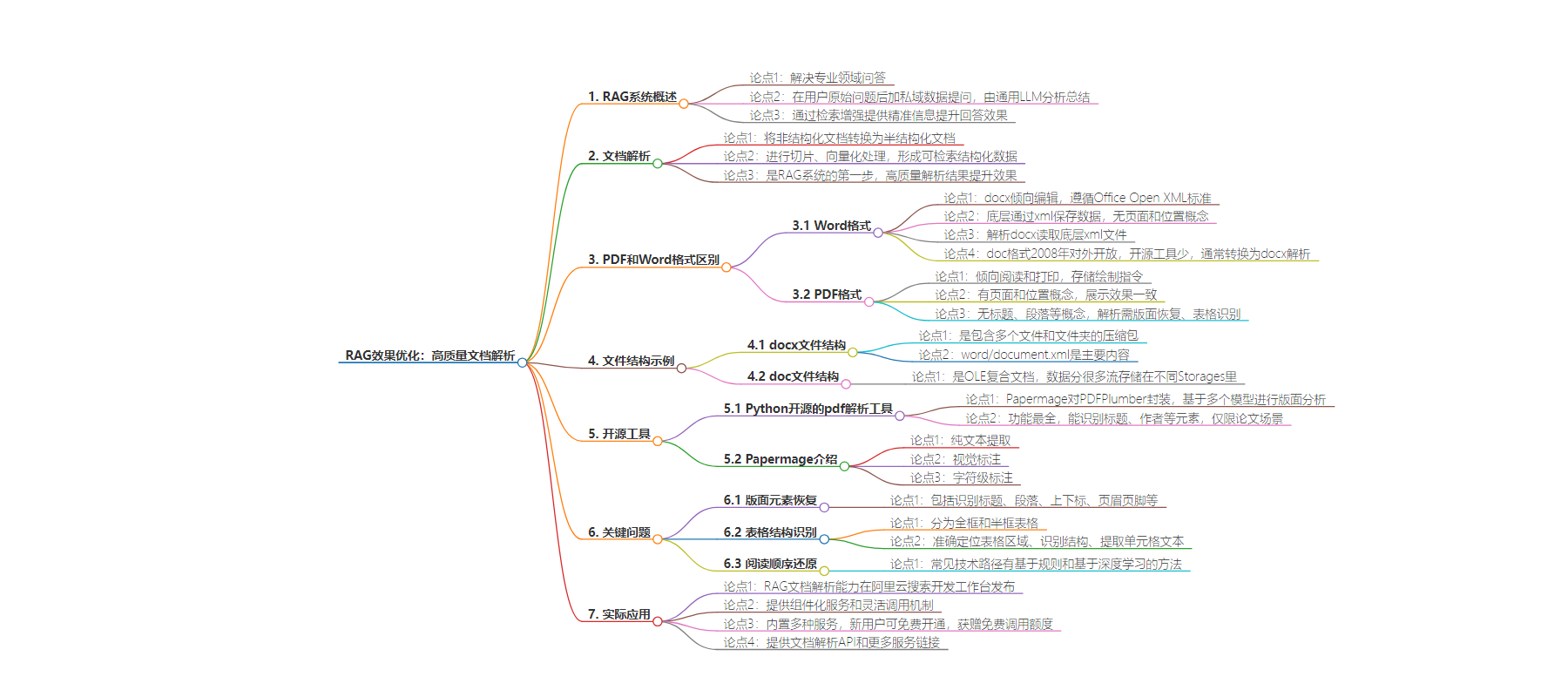
文章地址:https://mp.weixin.qq.com/s/-aocUBeHsE0fbT5MTshqCA
文章来源:mp.weixin.qq.com
作者:才胜、南也
发布时间:2024/8/27 9:54
语言:中文
总字数:4236字
预计阅读时间:17分钟
评分:90分
标签:RAG系统,文档解析,非结构化数据,结构化数据,PDF解析
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

尽管通用大语言模型(LLM)在知识问答方面取得了非常大的进展,但是对于专业领域依然无能为力,因为专业领域的数据不会对外公开,通用LLM没有学习过,自然不会回答。一种思路是将这些专业数据喂给LLM进行微调,但是对技术和成本要求往往太高,而RAG系统则是解决专业领域问答的另一种思路,在用户原始问题之后加上与之相关的私域数据一起提问,由通用LLM进行分析和总结。通过检索增强的方式为LLM提供更加精准的信息,从而提升最终回答效果,如下图所示:
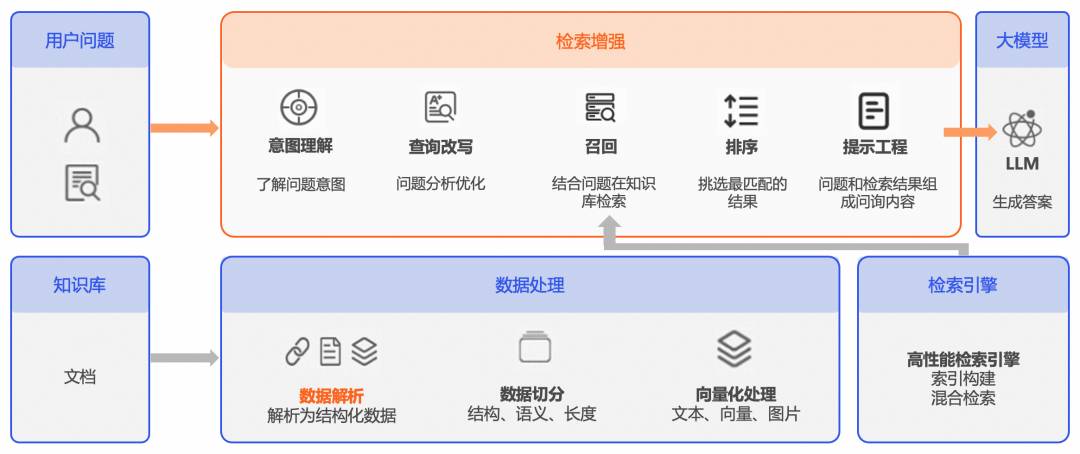
知识数据库是RAG系统的核心组件,需要离线将各类私域文档转换成计算机可检索的数据。实际场景中,大部分专业文档都是以pdf、doc等非结构化数据进行存储,它们有标题、段落、表格、图片等元素,易于人类阅读,却不适合计算机进行检索和处理。文档解析是将这些非结构化文档转换为半结构化的文档(如markdown、html),由系统后续进行切片、向量化处理,最终形成可检索的结构化数据。因此,文档解析是RAG系统的第一步,所谓better input better output,高质量的解析结果自然会提升RAG系统整体的效果。
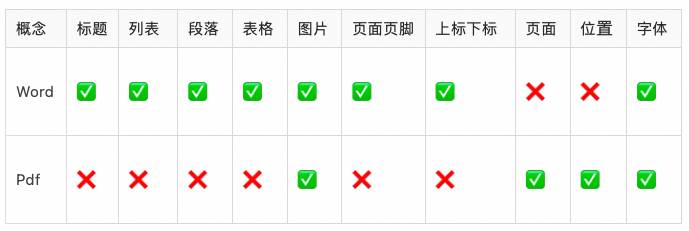
Pdf和Word(MS Office 2007之前为doc,之后为docx)是两种最常见的文档格式,但是二者有本质区别:
-
Word倾向于编辑。Docx格式遵循Office Open XML标准[1],底层通过xml保存数据,有标题、段落、表格等概念,但是不含页面和位置的概念,文档各个元素最终展现的位置由实际的渲染引擎决定(同一份文档不同软件打开后显示结果可能不同)。解析docx文件只需要按照标准读取底层的xml文件即可。doc格式在2008年才对外开放(此时已被docx替代),能够解析的开源工具很少,通常是转换为docx文件后进行解析。
-
Pdf倾向于阅读和打印。文档存储了一系列绘制字符、线条等基本元素的指令,指示了阅读器或打印机在屏幕或纸张上显示符号的位置和方式。相比word,pdf有页面和位置的概念,在不同终端的展示效果一致。因为不需要编辑,pdf中没有标题、段落、表格等概念,例如标题只是大号加粗的文字,表格只是对齐排列的线条和文字。解析pdf文件除了需要提取出文字外,还需要进行额外的版面恢复、表格识别等操作。
以下是docx和pdf文件结构的示例:
<w:document><w:body><!-- 段落 --><w:p w:rsidR="005F670F" w:rsidRDefault="005F79F5"><w:r><!-- 文本属性 --><w:rPr><w:rFonts w:ascii="Arial" w:hAnsi="Arial" w:cs="Arial"/><w:color w:val="000000"/></w:rPr><w:t>Hello world!</w:t></w:r></w:p><!-- 页面属性 --><w:sectPr w:rsidR="005F670F"><w:pgSz w:w="12240" w:h="15840"/><w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720"w:gutter="0"/><w:cols w:space="720"/><w:docGrid w:linePitch="360"/></w:sectPr></w:body></w:document>4 0 obj % 页面内容流<< >>stream % 流的开始1. 0. 0. 1. 50. 700. cm % 位置在(50,700)BT % 开始文本块/F0 36. Tf % 在36pt选择/F0字体(Hello, World!) Tj % 放置文本字符串ET % 结束文本块endstream % 流结束endobj
docx格式
一个DOCX文件实际上是一个包含多个文件和文件夹的压缩包,可以用解压缩工具进行解压。最小结构如下,示例为:
.├── [Content_Types].xml├── _rels│ └── .rels└── word├── document.xml└── _rels└── document.xml.rels
其中word/document.xml是DOCX文档的主要内容。参考上面的示例,以下是一些关键标签:
<w:document>:根元素,包含整个文档内容。 <w:body>:文档主体部分,包含所有段落、表格和其他内容。 <w:r>(Run):包含一段连续的文本,带有相同的格式。 <w:sectPr>(Section Properties):节属性,定义页面设置如页边距、页码、页眉页脚等。
doc格式
doc格式本身是一个OLE(Object Linking and Embedding)复合文档,文档将数据分成很多流(Steams),存储在不同的 Storages 里,详见MS-DOC文件格式规范[2]。其中WordDocument二进制流是文档的主要内容,必须存在。据目前所知,python环境下没有任何库能够直接读取doc文件中的内容。python olefile虽然可以打开doc文件,但也仅限于打开,无法理解(decode)WordDocument等流。因此python环境下一般通过libreoffice将doc文件转换为docx文件进行解析。同时为了避免文件加密导致转换失败,可以借助olefile及文件格式规范进行提前判断。
开源工具
目前python开源的pdf解析工具很多,总结如下:
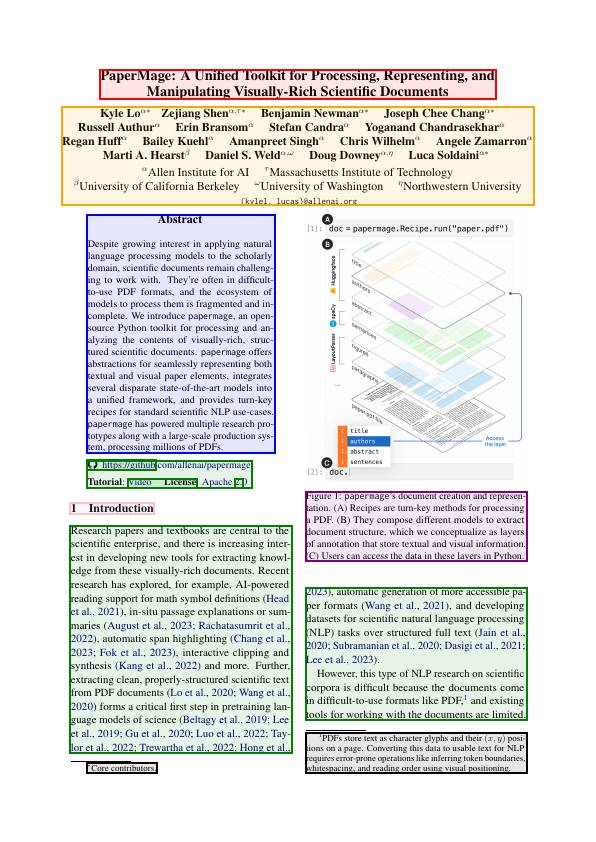
其中Papermage对PDFPlumber进行了封装,并基于多个模型进行版面分析,功能最全,能识别标题、作者、摘要等元素,但仅限于论文场景。类似的还有ragflow-deepdoc[3](参考:深度解读RAGFlow的深度文档理解DeepDoc[4])。下面详细介绍下Papermage。
PaperMage介绍
第一步——纯文本提取
基于PDFPlumber将pdf中的文字部分提取出来,得到words集合,并基于words位置关系检测文本行(lines)。
第二步——视觉标注
将pdf按页光栅化成位图,通过目标检测技术识别位图中的元素,得到blocks,每个block包括了边界框(bounding box,bbox)和标签(如图片、表格等)信息。光栅化操作使用了pdf2image库(底层是poppler),目标检测模型用的是efficientdet系列模型:layoutparser/efficientdet · Hugging Face[5]。可视化结果如下:
可以发现,bbox是一个大致区域,主要目的是通过位置关系将words划分到不同label的blocks中,即第三步中的block_ids和labels。
第三步——字符级标注
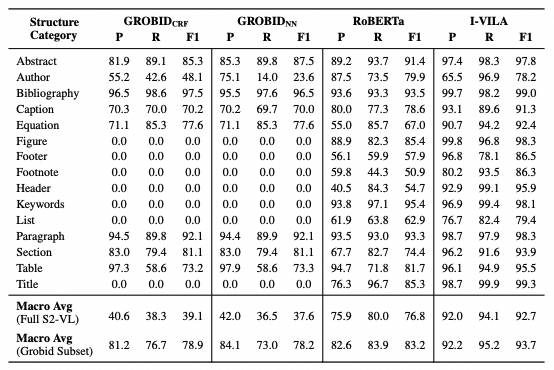
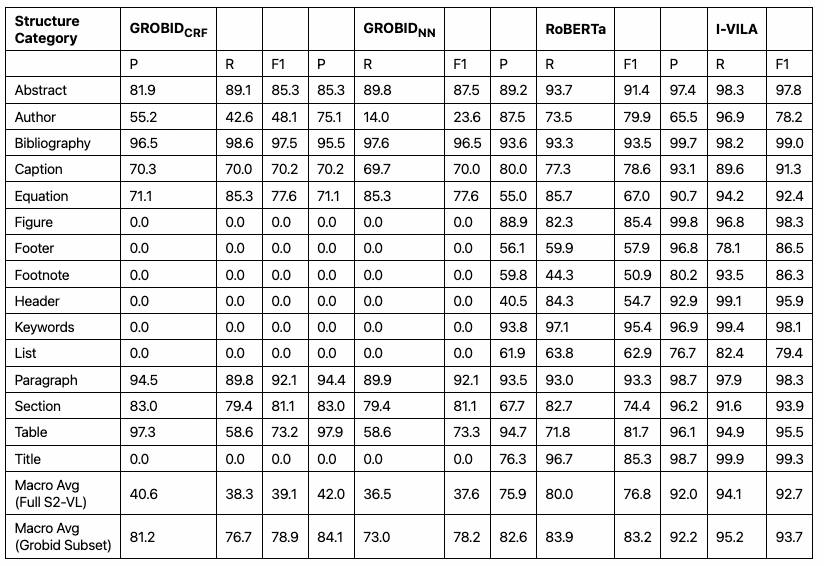
字符标注模型使用了I-VILA系列模型(allenai/ivila-block-layoutlm-finetuned-s2vl-v2[6]),将前两步的结果作为输入,输入格式入下:
{"words": ["word1", "word2", ...],"block_ids": [0, 0, 0, 1 ...],"line_ids": [0, 1, 1, 2 ...],"labels": [0, 0, 0, 1 ...],}预测出的标签有:
{"0": "Title","1": "Author","2": "Abstract","3": "Keywords","4": "Section","5": "Paragraph","6": "List","7": "Bibliography","8": "Equation","9": "Algorithm","10": "Figure","11": "Table","12": "Caption","13": "Header","14": "Footer","15": "Footnote"}模型对于每个word都会预测出一个标签,相同标签的word聚合成一个实体(如titles、authors等),而实体的外接框为实体中所有word的外接框。
可视化结果如下(不同颜色表示不同实体,如红色表示标题,橙色表示作者,绿色表示段落,黑色表示脚注等):
可以发现如果某个区域未提取到任何word,则该区域就不会被标注,因此上图中图片未识别到(目标检测模型虽然检测到,但标签识别错误)。
总结:
目前开源工具可以分为两类。
(1)基于规则的方式,优势:适用性广泛、速度快。劣势:效果一般,识别的版面元素有限,且识别效果较差; (2)基于模型的方式,优势:能够识别更多更上层的版面元素,有利于后续切片。劣势:速度慢,依赖GPU资源,适用的场景有限,识别过程黑盒(比如难以纠正上图中图片未识别的错误)。
关键问题
版面元素恢复
前面提到,pdf相比word缺少了很多版面元素的概念,如果仅提取文本则会丢失很多信息(如语义段落信息,文字大小,位置信息等),不利于后续的文档切片。版面恢复主要包括识别标题、段落、上下标、页眉页脚等。
表格结构识别
表格分为两种,一种是全框表格,另一种是半框表格(如论文中常见的三线表)。准确识别表格的前提是准确定位到表格区域,然后识别出表格结构,最后提取出每个单元格对应的文本。
阅读顺序还原
通过版式恢复后,能够输出版面元素的bounding box,如何准确的还原出符合人类阅读顺序的文档内容也是尤为重要。常见技术路径有:基于规则的方法(xy-cut等)、基于深度学习的方法(Layoutreader[7]等)
图中左侧和中间为doc/docx文件解析,右侧为pdf文件解析。对于pdf解析,我们采用了基于规则的方式,相比基于模型的方式,主要有以下考虑:
我们定位为通用场景,文档版面丰富多样,页数可能达到千页,模型性能泛化性达不到要求; GPU资源瓶颈,会限制服务最大吞吐量,而基于规则的方式只依赖CPU资源,可以无限扩缩; 模型效果黑盒化,badcase难以纠正。
所有格式最终输出为markdown格式,支持的版面元素:


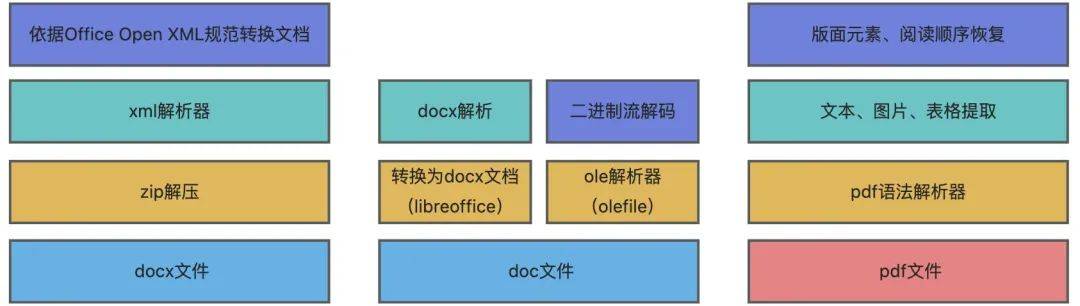
-
页眉、页脚
pdf格式另外还支持:
-
PPT类型优化
原文:PaperMage.pdf[8]
版面元素恢复

段落划分及阅读顺序,页脚识别

标题、段落、上下标、图片等元素识别
表格结构识别
原文
markdown
测试集:53篇论文
解析速度:

其中表格识别准确率(人工评测):

RAG文档解析能力已在阿里云搜索开发工作台发布,搜索开发工作台围绕智能搜索及RAG场景,提供优质的组件化服务以及灵活的调用机制,内置文档解析、文档切片、文本向量、召回、排序及大模型等服务,可实现一站式灵活的AI搜索业务开发。
目前新用户可免费开通搜索开发工作台,获赠100次服务免费调用额度。
免费开通:https://common-buy.aliyun.com/?spm=5176.14058969.J_8356059010.3.548254f8Gi92L1&commodityCode=opensearch_platform_public_cn
文档解析API:https://help.aliyun.com/zh/open-search/search-platform/developer-reference/api-details
查看及体验搜索开发工作台更多服务:https://opensearch.console.aliyun.com/cn-shanghai/rag/server-market
参考:
8、https://pdfs.semanticscholar.org/a0e7/
13、https://www.toptal.com/xml/an-informal-introduction-to-docx
本方案使用阿里云多端低代码开发平台魔笔低代码快速搭建适配于微信、支付宝等多平台的小程序,帮助您提升开发效率、降低维护成本。
点击阅读原文查看详情。