
包阅导读总结
1. 大模型、能效提升、AI 计算、芯片、算力生态
2. 本文主要探讨了生成式 AI 时代大模型的能效提升问题。包括人工智能的发展阶段、AI 2.0 面临的挑战,还介绍了提升能效的途径、清华在相关研究及算力生态建设方面的成果,以及对算电融合和可持续未来的思考。
3.
– 生成式 AI 时代的挑战
– 应用需求对算力规模提出挑战,计算设施扩张带来能源和环境压力。
– 能耗水平将成 AI 计算产业核心竞争力。
– 人工智能的发展
– 经历计算智能、感知智能与认知智能三个阶段。
– 从 AI 1.0 到 2.0,算法模型从针对应用开发到基于基础模型微调。
– 能效提升的研究
– 从芯片工艺进步到加速器,再到新器件。
– 打通算法和电路协同优化空间。
– 从算法、数据结构等多方面联合优化提升能效。
– 产业中的能效系统
– 清华在 AI 核心算法和算力及与其他行业结合方面的研究。
– 中国算力规模发展面临限制,需提升国产芯片应用。
– 发布异构分布式混合训练系统及云平台的相关成果。
– 比特/瓦特的能效系统
– 大模型算力提升带来能源需求大增,需思考电力系统稳定性和绿能消纳。
– 研究算电融合,提高用能效率,赋能大模型发展。
思维导图: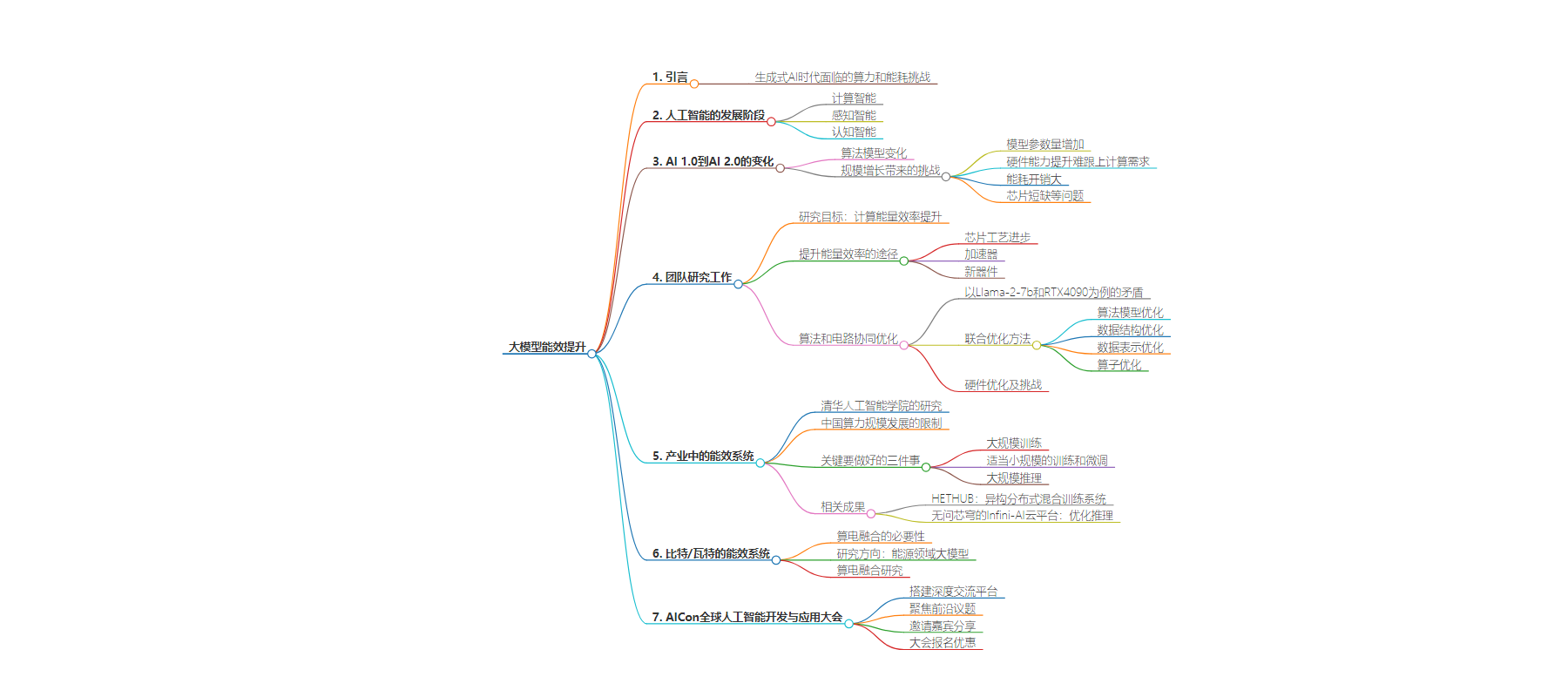
文章地址:https://mp.weixin.qq.com/s/4N1QhDXjkwon98m_5zKZvw
文章来源:mp.weixin.qq.com
作者:汪玉
发布时间:2024/7/12 5:59
语言:中文
总字数:4936字
预计阅读时间:20分钟
评分:92分
标签:生成式AI,大模型,能效提升,软硬件协同优化,算力生态建设
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
演讲嘉宾 | 汪玉 清华大学电子工程系教授、系主任 & 无问芯穹发起人
审核|傅宇琪 褚杏娟
策划 | 蔡芳芳
进入生成式 AI 时代后,应用侧日益高涨的服务需求给基础设施的算力规模提出了巨大的挑战。与此同时,不断扩张的计算设施对能源供应和生态环境的压力也在飞速增长,迫使产业采取多种手段提升从芯片到集群,再到整个数据中心生态的能耗效率。SemiAnalysis 不久前发布的一篇报告指出,能耗水平将成为 AI 计算产业的核心竞争力要素,对整个产业的发展起到关键作用。
在 2024 年 5 月举办的 AICon 全球人工智能开发与应用大会暨大模型应用生态展上,清华大学电子工程系教授、系主任 & 无问芯穹发起人汪玉围绕生成式 AI 时代的高能效计算发表了题为《可持续的智能:大模型高能效系统前瞻》的演讲报告,本篇内容根据该报告编写、更新而来。
InfoQ 将于 8 月 18-19 日举办 AICon 上海站,我们已经邀请到了「蔚来创始人 李斌」,他将在主论坛分享基于蔚来汽车 10 年来创新创业过程中的思考和实践,聚焦 SmartEV 和 AI 结合的关键问题和解决之道。更多精彩议题可访问官网了解:
https://aicon.infoq.cn/2024/shanghai/track
在分析人工智能这个主题之前,首先要思考的一个问题是“到底何为智能”?诺贝尔奖获得者 Daniel Kahneman 在他的著作《思考,快与慢》中从人类智能的角度给出了一个视角:Daniel 将人类的智能分成两类系统,第一类系统是“大脑快速、自动、直观的方法”,第二类是“思维的慢速、理性占主导的分析模式”。
与人类智能的两类系统类似,人工智能的发展也经历了计算智能、感知智能与认知智能三个阶段。回顾人工智能的发展,我们可以将人工智能算法抽象为函数 y=f(x),其中 f 代表人工智能算法的计算规则,x 代表数据,y 则是决策。在计算智能时代,由人类制定 f() 的计算规则;在感知智能时代,人工智能算法从大量数据中进行学习,通过拟合的方式得到 f();而在认知智能时代,人工智能将从海量数据中挖掘并学习对象之间关系,获得模拟人类的认知能力的 f()。
而在芯片行业,从业者所解决的问题就是如何更高效地实现 y=f(x) 的计算。早期芯片设计人员将函数中所有最基本的元件抽象成加减乘除,设计指令集与通用处理器 CPU ,然后用软件的方式实现各种各样的功能,追求的目标是让芯片可以快速支持通用计算任务。
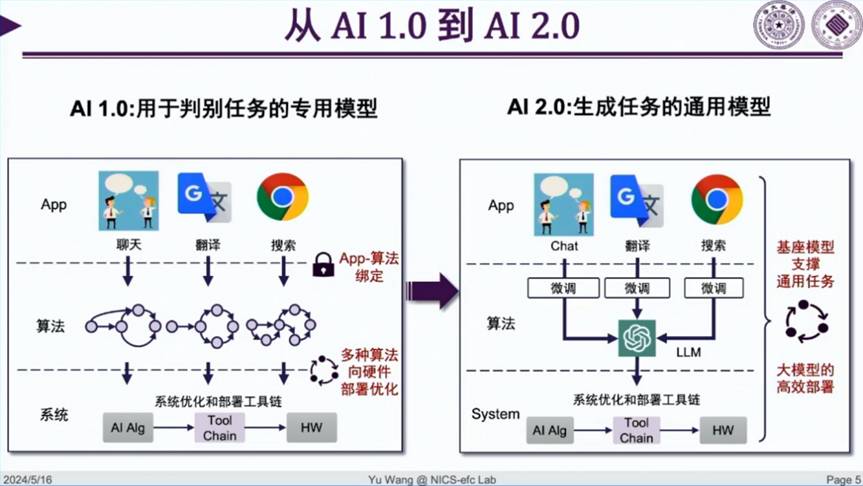
在 AI 1.0 时代,人们设计了一系列面向不同应用的智能算法,例如面向图像处理的卷积神经网络算法,面向自然语言处理的循环神经网络算法。芯片设计人员面向特定算法设计领域定制集成电路(ASIC),研究特定算法向硬件的部署优化方法。
从过去的 AI 1.0 到今天的 AI 2.0 时代,最大的变化是:过去,算法研究者会面向每一个应用类别的数据来开发一个专门的算法模型,而现在,我们会使用所有的数据训练一个基础模型,再利用各行各业的专业数据,对基础模型进行微调,来完成各行各业的任务。对做系统或做硬件的人来说,只需要考虑如何优化这一个基础算法就可以了。
AI 2.0 背后的挑战不言而喻。从规模角度来看,2018 年到 2022 年,模型参数量增加了至少 5 个数量级,现在还在不断增长。以 SORA 为例,其参数规模推测达到 300 亿,单次训练算力需求可达 8.4*10^23 Flops 水平。
在硬件层面,行业面临的主要挑战是硬件能力的提升速度很难跟上计算需求的增长速度。以中国市场为例,如果将来 14 亿人同时在云端使用大模型,中国现有的智能算力基础设施将难以支撑 14 亿人的算力需求,差距可达 3~4 个数量级。虽然国内的基础设施建设在飞速前进,但我们确实也面临芯片短缺等挑战。
从另外一个角度来看,现在大模型训练任务大致占到所有算力的 70%,大模型训练的能耗开销可达国内数百个家庭一年的用电量。但如果大模型应用开始普及,未来推理任务的算力占比大概会达到 70~80%,这才意味着大模型应用真正达到了成熟和流行的状态。
2023 年美国对芯片出口提出了新的管制规定,限制了中国可以获得的芯片技术水平,也限制了中国在海外生产的算力规模。所以我们也在很努力地推进中国自主的芯片制造厂和工艺,这是整个国家和企业界在努力推进的方向,我相信在 5~10 年内我们是有希望解决这个问题的。
回到我们团队的研究工作,我们的研究目标瞄准计算能量效率的提升。在我读博的 2002 到 2007 年器件,我主要关注的是芯片工艺的进步,也就是 Scaling Down。比如:芯片工艺从 45nm 进化到 28-14nm 的过程中是提高能量效率的,因为晶体管越做越小,电容就会变小,每一次充电的能量就会变小,每一次的翻转的速度会变快。所以晶体管做小后,速度变快了,需要的能量变小了,所以能量效率就提升了。
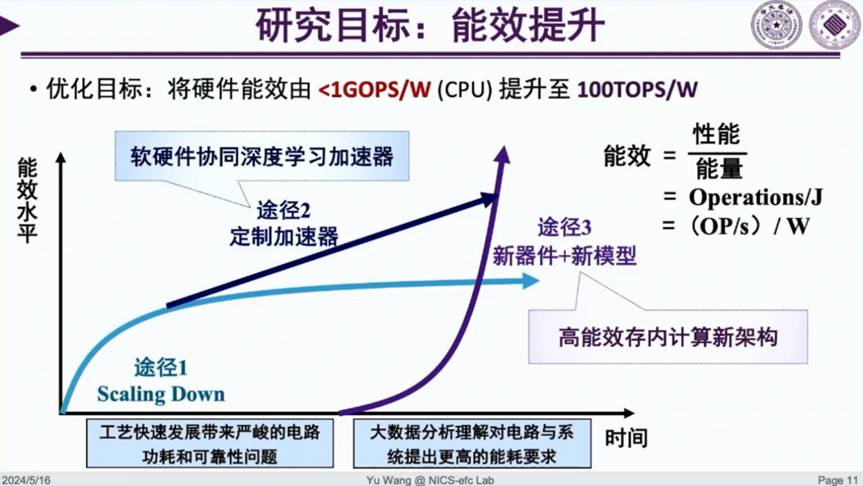
但是到了 2007 年之后,提升能量效率主要的路径就变成了加速器。因为工艺发展变缓了,大家发现多核甚至异构多核可能是一条路,芯片铺很多核就会有计算性能与能效的线性提升,所以我们会画一条线性的线来表示能效水平的提升。2010 年到 2020 年是 AI 加速器飞速发展的阶段,我们看到了 5 个数量级的能量效率提升。第三条途径则是新器件,包括量子计算、光计算、存内计算等,有希望突破现有的计算范式,以获得更高的能量效率。
面向非神经网络的传统算法,一般来说会在算法设计完后再去做电路设计,但我们发现在人工智能时代,是有可能打通算法和电路的协同优化空间,而且该优化空间足够庞大。这也就意味着,任何一个算法,如果底层硬件是给定的,就可以通过微调,甚至是重新训练、重新选结构等方法针对底层硬件对算法进行优化,使算法在硬件上跑起来更快。这也是我所有的成果里最核心的一个方法论,也就是利用智能算法的可学习特性,同时优化算法和电路来实现能效的数量级提升,从不到 1GOPS/W 提升至 100TOPS/W。
以 Llama-2-7b 大模型和 RTX4090 计算卡为例,模型直接部署在硬件平台上的能量效率是很低的,直接用 fp16 存储会遇到存储空间不足的问题,但改用 Int2 存储又会出现算法准确率很低的现象,这是当下大模型计算的一个关键矛盾。
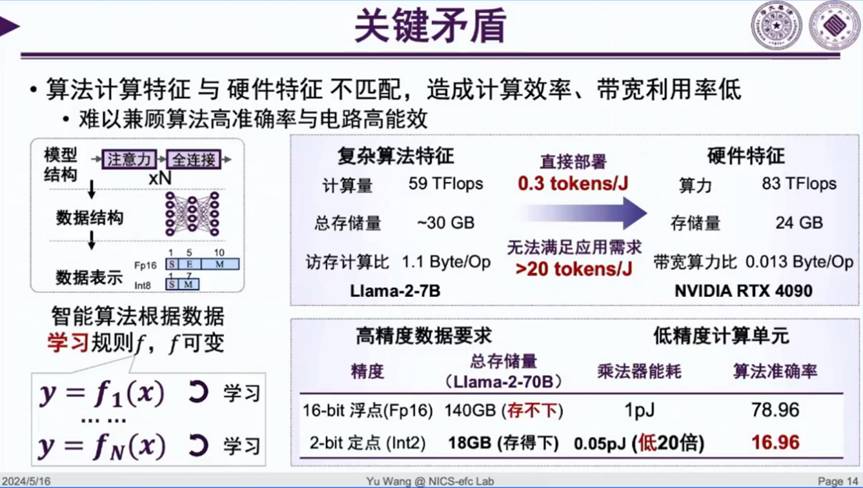
对此,要运用可学习的特性,从算法到数据结构、数据表示、计算图,再到硬件,一同做联合优化。如果底层数据变成了 4bit、2bit 的乘法器,会比 32bit、16bit 的乘法器小很多,在固定的面积里可以放的计算单元会更多,从而提高峰值能力。而对计算图和架构的设计优化将可以有效提高计算资源的利用效率。
在算法模型优化方面,我们发现大语言模型的输出具有结构上的并行性,因此,我们可以先根据用户输入,由大模型生成回答内容的提纲,然后再从提纲中的要点进行并行展开,使用这样的思想就可以把一部分大模型算法加速 2~3 倍。
在数据结构优化方面,大模型的注意力计算层是比较占计算量的,当 token 数变多时计算量会很大。对此可以通过稀疏方法减小计算和存储的复杂度,并针对不同的注意力头(Attention Head)使用不同的稀疏模板,从而在将计算量存储量降低 50% 的情况下,使端到端推理速度再提升 2~3 倍。
数据表示优化层面的主要方法是量化。算法的数据特征在各层都是不一样的,大模型参数与数据的动态范围也比较大。针对数据离群点问题,我们将大部分数据表示变成 Int2,一小部分管件数据还是用 fp16,从而将平均位宽做到 2.8bit 时,且平均精度损失也只有 1% 左右,这样就可以进行实际应用,而且塞到显存较小的卡里做算子优化。
对于算子优化,我们发现不同的算子特征是不一样的,比如说 softmax 的输入分布比较集中,还有 decode 阶段的矩阵计算都是一些矮胖的矩阵。所以我们通过这些特征来调整计算流程、重写算子,也可以实现很高的性能提升,同时这个思想也可以用在所有的国产卡上。
我们自己也做了硬件,把算法放到硬件上。我们使用单块 FPGA 对比工艺接近的 GPU,可以实现 6 倍左右的能量效率提升。所以这也是告诉大家,其实做推理芯片是可以的,但推理芯片怎样能去适应算法的变化是比较大的挑战。

整体来看,第一部分从算法本身到模型数据结构表示,再到计算图和结构上都可以做优化。再考虑到工艺进步,将还有 5~10 倍的能量效率提升。
最近清华成立了人工智能学院,专注于两部分的研究,一部分叫 AI core,核心算法和算力;另外一部分是 AI+,即 AI 与其他各行各业的结合。尽管我们发现算力中心的规划涨幅没有我们预想的 100 倍那么大,但在算力规模方面的发展还是很迅速的。
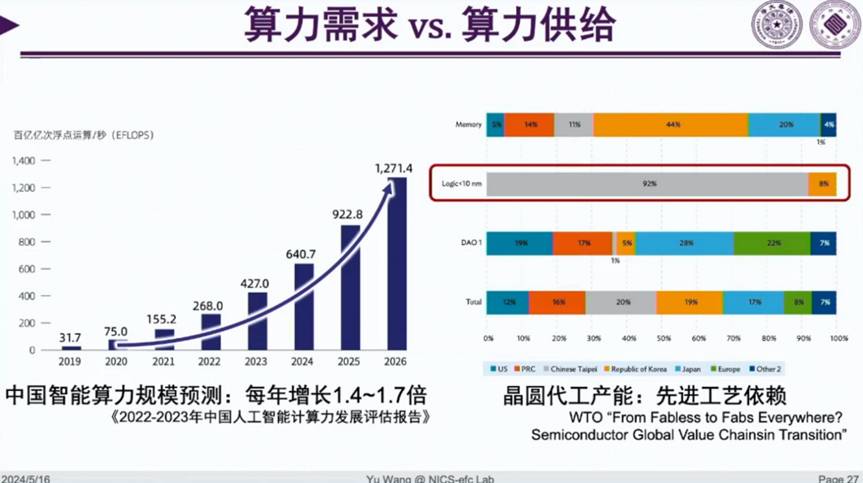
在核心供给方面,芯片逻辑工艺小于 10nm 的代工厂里,92% 的份额被 TSMC 拿走。也就是说中国要扩展算力规模,不得不大量使用 TSMC 工艺,但这时就会受到美国禁令对于算力总量和算力密度的限制。
整体来看,我们总的生产能力是受限的,同时我们也没有那么多的进口算力支持,怎么办?算法层面,大家有很多算法,在向万亿参数量级发展;算力层面,有很多国产芯片公司在努力,设法让我们的模型和算力能够更好地结合起来。
如何把中国的算力都用起来就是一个非常值得探讨的问题。我们同海外的生态不太一样,国外主要还是英伟达以及英伟达上面的这套体系,包括 CUDA 和一系列优化库,但中国有各种各样的芯片,软件接口层也有很多选项。
但从我的角度看,关键要做好三件事,也就是说产品维度有三个。一是大规模训练,二是适当小规模的训练和微调,三是大规模推理。底层硬件平台其实并不需要用户或算法研究者关心,有一些厂商或者软件、云服务能够把底层屏蔽掉。
我们也在向这个方向努力,我们来提供中间层的训练能力、混训能力、运管能力、部署能力和对国产芯片的支持,让大家用起来更方便。
英伟达的训练大家都可以干,但怎样把国产的千卡维度的训练做起来?就在前几天,我们发布了 HETHUB,这是一个用于大规模模型的异构分布式混合训练系统,是业内首次实现六种不同品牌芯片间的交叉混合训练,异构混合训练集群算力利用率最高达到了 97.6%。
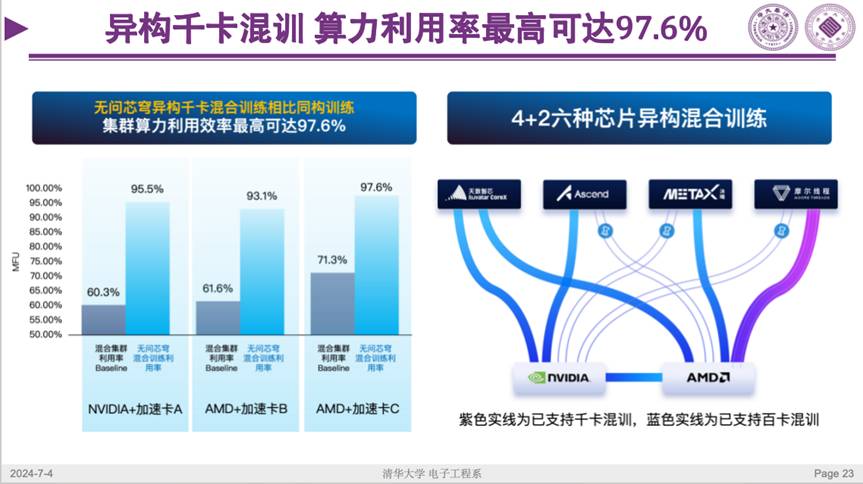
这给了我们极大的信心。混训的难度在于,如果都是一样的卡,把任务均匀拆分就好了,但由于算力总量不足,以及工艺被限制,我们这里不是一样的卡。因此我们必须去做各种各样的切分,然后做异构数据的并行,用异构的卡去训练大模型。目前这个异构千卡混训的能力已经结合进无问芯穹的 Infini-AI 云平台了,把高效互联互通、精密的分布式并行策略比如张量并行、数据并行、通信 overlap 等封装起来给大家提供服务。
在大规模集群推理层面,特别是在缓存层面上,原来是有一部分无效缓存,但如果我们把顺序稍微调整一下,就可以做到缓存的极致利用,把模型的显存占用降到最低。这个云平台也集成了我们 Serving 优化技术能力,当并发量很高,多个用户同时发送请求时,这个系统会通过请求调度、提示词缓存、并行解码等方式优化计算任务的派发和计算结果的返回,累计可以实现 30 倍以上的 token 吞吐率提升。
预期到今年底,我们能做到模型到芯片的 M×N 的自动路由,让大家想用什么卡就用什么卡。
如果大模型的算力提升真能达到 100 倍的规模,它对能源的需求会变得非常大。2025 年人工智能业务在全球数据中心用电量的占比将从 2% 猛增到 10%,相关用能成本、碳排放量也会飙升。那么电力系统如何进一步提升稳定性,如何消纳风光等绿色能源,都是我们要思考的问题。
我们应该把算力中心尽可能放到能源集中的地方,但这里又面临着通信的问题,要把延迟和带宽挑战处理好,做好联合优化。我们系里也有团队在研究如何打造能源领域的大模型,支撑算力中心的用能方案的综合优化,来提高用能效率,赋能电力系统,解决电网的绿电消纳和峰值调频等问题。比如说电价是有波动的,计算任务也是有变化的,怎样把计算中心和能源模型适当结合起来做调配?还有预测发电的情况、波动的情况等等。
我们还在同我校电机系一起做算电融合的研究,希望在这个方向上能够和大家一同推进。这个领域还处于早期规划阶段,这也是中国最优势的一个方向,就是怎样把能源和基建算力结合起来,赋能我们的大模型发展。
从单算法到芯片的联合优化,到多算法和多芯片的联合优化,再到算力和能源的联合优化,我们有希望对整个巨大的系统进行优化,让我们的人工智能有充沛的能源和算力。
AICon 全球人工智能开发与应用大会*,为资深工程师、产品经理、数据分析师等专业人群搭建深度交流平台。聚焦大模型训练与推理、AI Agent、RAG 技术、多模态等前沿议题,汇聚 AI 和大模型超全落地场景与最佳实践,期望帮助与会者在大模型时代把握先机,实现技术与业务的双重飞跃。
在主题演讲环节,我们已经邀请到了「蔚来创始人 李斌」,分享基于蔚来汽车 10 年来创新创业过程中的思考和实践,聚焦 SmartEV 和 AI 结合的关键问题和解决之道。大会火热报名中,7 月 31 日前可以享受 9 折优惠,单张门票节省 480 元(原价 4800 元),详情可联系票务经理 13269078023 咨询。
