
包阅导读总结
1.
关键词:大语言模型、多轮对话、指令跟随、Parrot、强化训练
2.
总结:多数开源大语言模型在多轮对话指令跟随方面表现不佳,作者针对现有不足提出Parrot方法,包括多轮数据收集、CaPO策略等,Parrot-Chat模型性能优于开源模型,虽有局限但有望推动相关研究和应用,快手大模型与多媒体技术部诚邀加入。
3.
主要内容:
– 开源大语言模型在单轮交互表现好,但多轮指令跟随有不足
– 训练方法未针对性优化多轮指令上下文关系
– 多轮数据集轮次短且与真实用户指令分布差异大
– 评测基准不足以评测多轮指令跟随表现
– Parrot方法
– 训练Parrot-Ask模型自动生成多轮指令序列并收集Parrot-40K数据集
– 提出CaPO策略构建训练样本对强化模型能力得到Parrot-Chat模型
– 评估与比较
– 扩展MT-Bench形成MT-Bench++评测集
– Parrot-Chat性能优于现有开源模型
– 消融实验证明Parrot方法有效性
– 快手大模型与多媒体技术部诚邀加入
思维导图: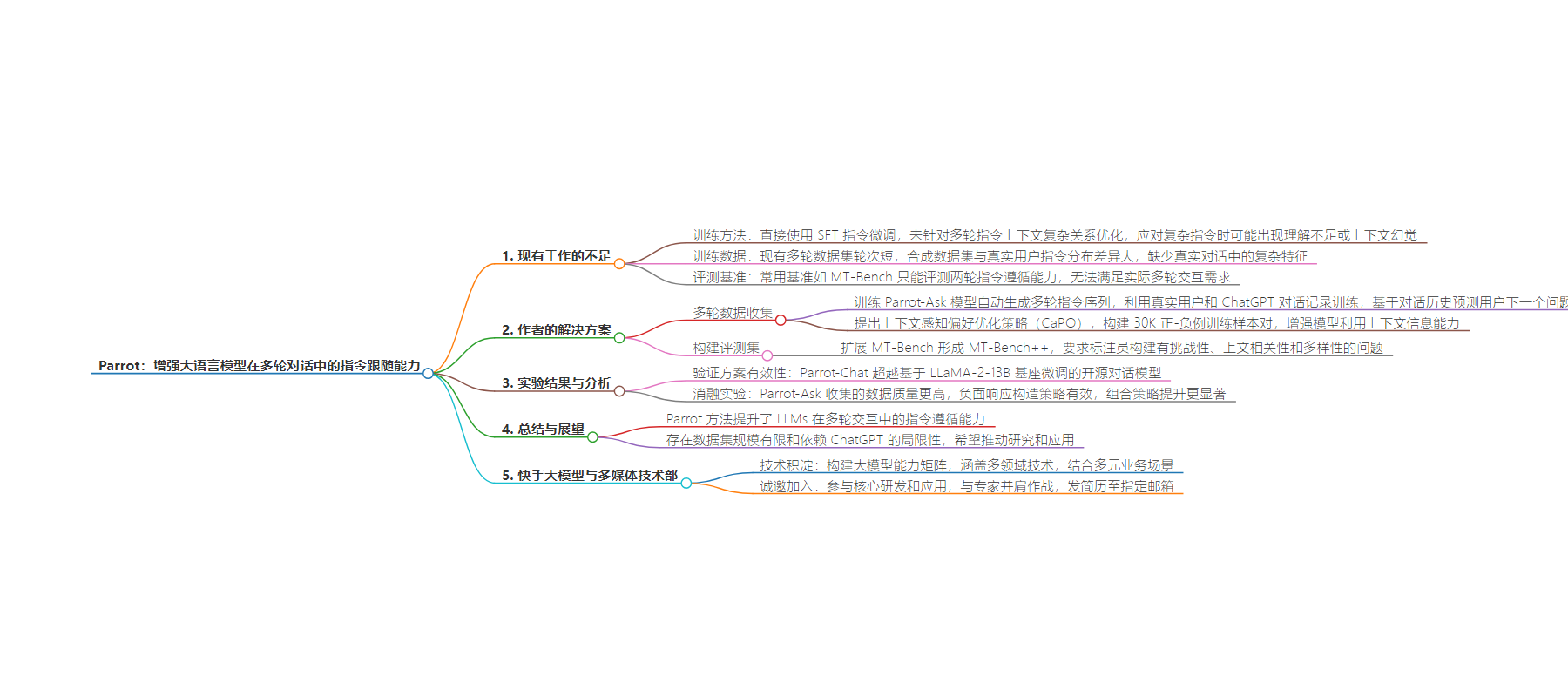
文章地址:https://mp.weixin.qq.com/s/vlddfd13VI6YiutCSGTbHA
文章来源:mp.weixin.qq.com
作者:让你更懂AI的
发布时间:2024/7/23 10:05
语言:中文
总字数:2997字
预计阅读时间:12分钟
评分:87分
标签:大语言模型,多轮对话,指令跟随,自然语言处理,快手技术
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
 图1: Parrot-Ask 合成多轮数据
图1: Parrot-Ask 合成多轮数据
训练数据方面,现有的多轮数据集通常轮次很短,比如常用的 ShareGPT 约 60% 的数据都在三轮以内。一些合成的多轮数据集使用 ChatGPT 或 GPT-4 来模拟用户,并通过迭代式对话来收集多轮数据,但是这些合成的指令和真实用户指令的分布差异很大,特别是缺少如图 1 所示的真实用户对话中的复杂特征,如指代、省略、口语化等等。
评测基准方面,常用的 MT-Bench 基准虽然包含了八种类别的指令,但只能评测两轮的指令遵循能力。而实际应用中用户与 LLM 的交互可能会远远超过 2 轮,这导致 MT-Bench 不足以评测 LLMs 的多轮指令跟随表现。
针对上述问题,作者设计了上下文感知的强化训练策略,提出了一套高效的多轮数据收集方法,最后通过所构建的包含 8 轮次的多轮指令跟随评测集 MT-Bench++,系统地研究了如何增强和评估大语言模型(LLM)的多轮指令遵循能力。

图2:Parrot 框架图
多轮数据收集:
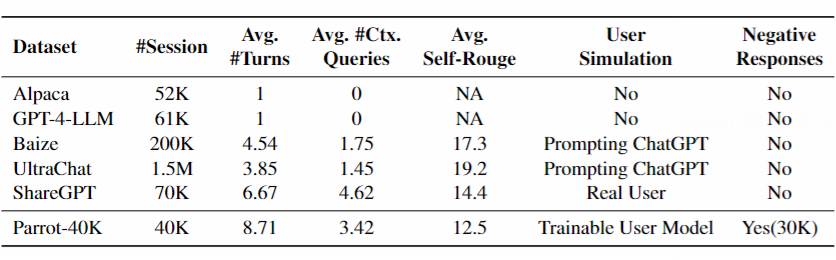
表1:Parrot 数据集和其他数据集的比较
-
忽略上下文:通过让 ChatGPT 生成回复时不考虑对话历史,模拟当语言模型没有参考对话历史时可能产生的错误回复。 -
上下文幻觉:首先提示 ChatGPT 猜测指代词或省略所指的是什么,然后基于它的猜测生成回应。这种策略模拟了语言模型在缺乏足够的指代省略推理能力,因此产生幻觉的错误情况。 -
上下文误解:指示 ChatGPT 从对话历史中选择不相关的信息,并强制模型误解它,来为当前查询中的省略或指代信息生成回应。这种方法模拟了语言模型错误推理指代省略等信息导致的错误。

表2:MT-Bench++ 中关于经济主题的八个问题
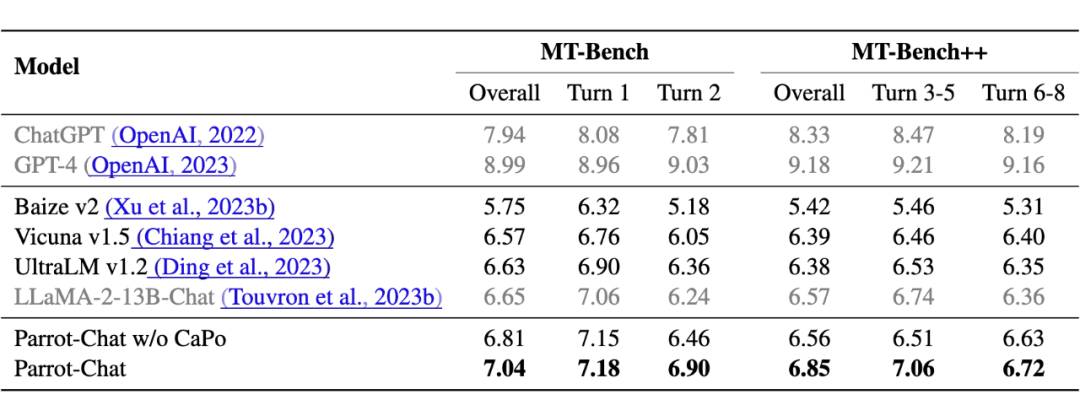
表3:Parrot-Chat 和基线模型的性能比较
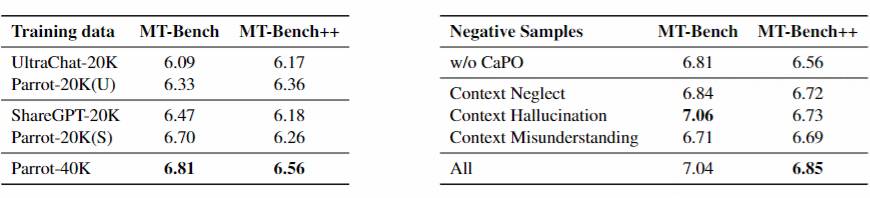 表4:消融实验
表4:消融实验Parrot 通过提出 CaPO 训练策略以及新的多轮指令数据合成方法,提升了 LLMs 在多轮交互中的指令遵循能力。尽管存在数据集规模有限和依赖 ChatGPT 进行数据收集与评测的局限性,本文希望能为推动 LLMs 在多轮对话领域的研究和应用带来帮助。
快手大模型与多媒体技术部,专注于快手大模型及应用的研发。凭借深厚的技术积淀,全面构建了快手大模型能力矩阵,涵盖语言、视觉、音频及多模态技术,并深度结合多元业务场景,如内容理解、短视频/直播创作、社交互动、商业化AIGC等,应用前景广阔。快手大模型与多媒体技术部、AI Platform,诚邀你加入!
在这里你可以获得:
-
参与大模型核心研发和应用,见证和推动技术变革
-
为亿万用户带来精彩纷呈的智能体验
-
和行业算法专家并肩作战
我们期待你的加入!请发简历到:
dongbinbin@kuaishou.com