
包阅导读总结
1.
关键词:Workers AI、Embedded Function Calling、ai-utils 、Developer Experience、Open-Source Models
2.
总结:Cloudflare 推出嵌入式函数调用和新的 ai-utils 包,简化开发者工作流程。对比其他平台,强调自身在开源模型和开发者体验上的优势,介绍了传统函数调用的工作方式和新的嵌入式函数调用的特点及相关工具和方法。
3.
主要内容:
– Workers AI 推出嵌入式函数调用和新的 ai-utils 包
– 新的 ai-utils 包简化开发者流程,已开源
– 目标是让 AI 开发更简单,创造更多可能
– Cloudflare 的 AI 平台优势
– 匹配 OpenAI 的开发者体验,支持开源模型
– 兼具开源模型推理和出色的开发者体验
– 传统函数调用工作方式
– 指定函数名和参数及提示,LLM 返回后由客户执行
– 需多次网络往返,开发者处理复杂
– 嵌入式函数调用
– 在 Workers 平台同一执行环境运行,减少不必要请求
– 因 Cloudflare 平台提供多种服务得以实现
– 新的 ai-utils 包相关
– runWithTools 方法用于嵌入式函数调用,可处理多种情况
– createToolsFromOpenAPISpec 函数根据 OpenAPI 规范动态生成工具模式和 API 端点
– 函数调用推理请求时,仅需提示,其余自动处理
思维导图:
文章地址:https://blog.cloudflare.com/embedded-function-calling
文章来源:blog.cloudflare.com
作者:Harley Turan
发布时间:2024/6/27 18:00
语言:英文
总字数:1250字
预计阅读时间:5分钟
评分:93分
标签:产品新闻,Workers AI,开发者平台,开发者,开源
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

Introducing embedded function calling and a new ai-utils package
Today, we’re excited to announce a novel way to do function calling that co-locates LLM inference with function execution, and a new ai-utils package that upgrades the developer experience for function calling.
This is a follow-up to our mid-June announcement for traditional function calling, which allows you to leverage a Large Language Model (LLM) to intelligently generate structured outputs and pass them to an API call. Function calling has been largely adopted and standardized in the industry as a way for AI models to help perform actions on behalf of a user.
Our goal is to make building with AI as easy as possible, which is why we’re introducing a new @cloudflare/ai-utils npm package that allows developers to get started quickly with embedded function calling. These helper tools drastically simplify your workflow by actually executing your function code and dynamically generating tools from OpenAPI specs. We’ve also open-sourced our ai-utils package, which you can find on GitHub. With both embedded function calling and our ai-utils, you’re one step closer to creating intelligent AI agents, and from there, the possibilities are endless.
Why Cloudflare’s AI platform?
OpenAI has been the gold standard when it comes to having performant model inference and a great developer experience. However, they mostly support their closed-source models, while we want to also promote the open-source ecosystem of models. One of our goals with Workers AI is to match the developer experience you might get from OpenAI, but with open-source models.
There are other open-source inference providers out there like Azure or Bedrock, but most of them are focused on serving inference and the underlying infrastructure, rather than being a developer toolkit. While there are external libraries and frameworks like AI SDK that help developers build quickly with simple abstractions, they rely on upstream providers to do the actual inference. With Workers AI, it’s the best of both worlds – we offer open-source model inference and a killer developer experience out of the box.
With the release of embedded function calling and ai-utils today, we’ve advanced how we do inference for function calling and improved the developer experience by making it dead simple for developers to start building AI experiences.
How does traditional function calling work?
Traditional LLM function calling allows customers to specify a set of function names and required arguments along with a prompt when running inference on an LLM. The LLM returns the names and arguments for the functions that the customer can then make to perform actions. These actions give LLMs the ability to do things like fetch fresh data not present in the training dataset and “perform actions” based on user intent.

Traditional function calling requires multiple back-and-forth requests passing through the network in order to get to the final output. This includes requests to your origin server, an inference provider, and external APIs. As a developer, you have to orchestrate all the back-and-forths and handle all the requests and responses. If you were building complex agents with multi-tool calls or recursive tool calls, it gets infinitely harder. Fortunately, this doesn’t have to be the case, and we’ve solved it for you.
Embedded function calling
With Workers AI, our inference runtime is the Workers platform, and the Workers platform can be seen as a global compute network of distributed functions (RPCs). With this model, we can run inference using Workers AI, and supply not only the function names and arguments, but also the runtime function code to be executed. Rather than performing multiple round-trips across networks, the LLM inference and function can run in the same execution environment, cutting out all the unnecessary requests.
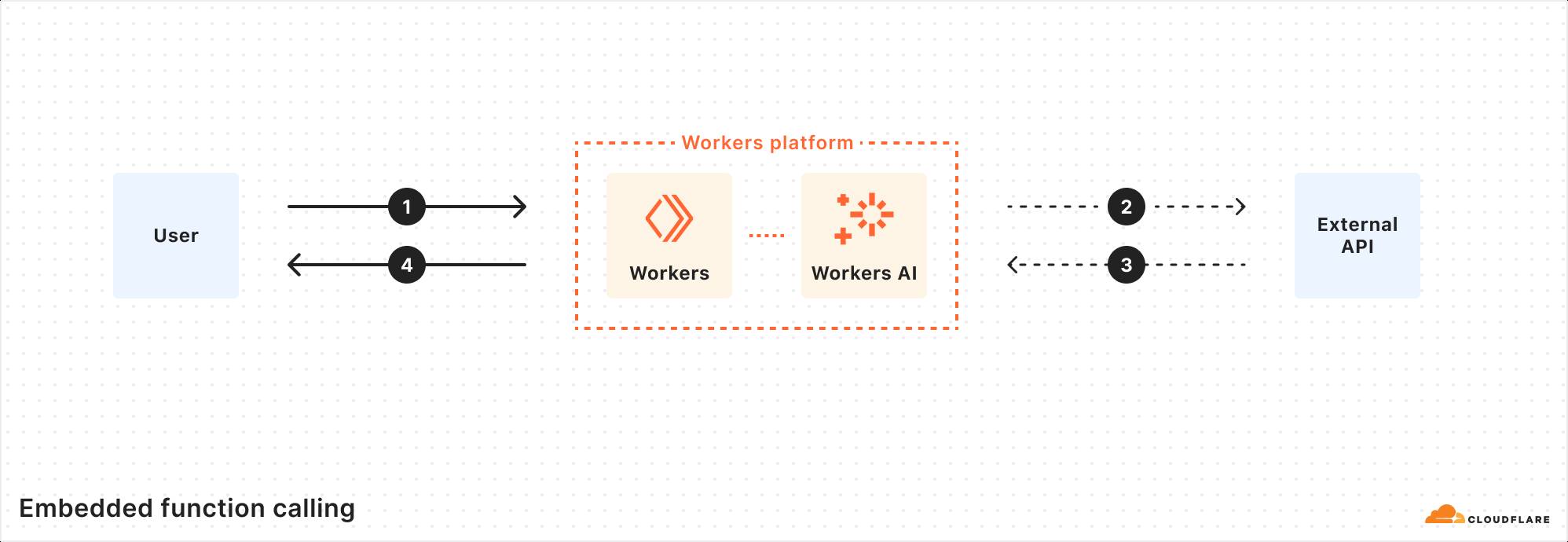
Cloudflare is one of the few inference providers that is able to do this because we offer more than just inference – our developer platform has compute, storage, inference, and more, all within the same Workers runtime.
We made it easy for you with a new ai-utils package
And to make it as simple as possible, we created a @cloudflare/ai-utils package that you can use to get started. These powerful abstractions cut down on the logic you have to implement to do function calling – it just works out of the box.
runWithTools
runWithTools is our method that you use to do embedded function calling. You pass in your AI binding (env.AI), model, prompt messages, and tools. The tools array includes the description of the function, similar to traditional function calling, but you also pass in the function code that needs to be executed. This method makes the inference calls and executes the function code in one single step. runWithTools is also able to handle multiple function calls, recursive tool calls, validation for model responses, streaming for the final response, and other features.
Another feature to call out is a helper method called autoTrimTools that automatically selects the relevant tools and trims the tools array based on the names and descriptions. We do this by adding an initial LLM inference call to intelligently trim the tools array before the actual function-calling inference call is made. We found that autoTrimTools helped decrease the number of total tokens used in the entire process (especially when there’s a large number of tools provided) because there’s significantly fewer input tokens used when generating the arguments list. You can choose to use autoTrimTools by setting it as a parameter in the runWithTools method.
const response = await runWithTools(env.AI,"@hf/nousresearch/hermes-2-pro-mistral-7b", { messages: [{ role: "user", content: "What's the weather in Austin, Texas?"}], tools: [ { name: "getWeather", description: "Return the weather for a latitude and longitude", parameters: { type: "object", properties: { latitude: { type: "string", description: "The latitude for the given location" }, longitude: { type: "string", description: "The longitude for the given location" } }, required: ["latitude", "longitude"] }, // function code to be executed after tool call function: async ({ latitude, longitude }) => { const url = `https://api.weatherapi.com/v1/current.json?key=${env.WEATHERAPI_TOKEN}&q=${latitude},${longitude}` const res = await fetch(url).then((res) => res.json()) return JSON.stringify(res) } } ] }, { streamFinalResponse: true, maxRecursiveToolRuns: 5, trimFunction: autoTrimTools, verbose: true, strictValidation: true })createToolsFromOpenAPISpec
For many use cases, users will need to make a request to an external API call during function calling to get the output needed. Instead of having to hardcode the exact API endpoints in your tools array, we made a helper function that takes in an OpenAPI spec and dynamically generates the corresponding tool schemas and API endpoints you’ll need for the function call. You call createToolsFromOpenAPISpec from within runWithTools and it’ll dynamically populate everything for you.
const response = await runWithTools(env.AI, "@hf/nousresearch/hermes-2-pro-mistral-7b", { messages: [{ role: "user",content: "Can you name me 5 repos created by Cloudflare"}], tools: [ ...(await createToolsFromOpenAPISpec( "https://raw.githubusercontent.com/github/rest-api-description/main/descriptions-next/api.github.com/api.github.com.json" )) ]})Putting it all together
When you make a function calling inference request with runWithTools and createToolsFromOpenAPISpec, the only thing you need is the prompts – the rest is automatically handled. The LLM will choose the correct tool based on the prompt, the runtime will execute the function needed, and you’ll get a fast, intelligent response from the model. By leveraging our Workers runtime’s bindings and RPC calls along with our global network, we can execute everything from a single location close to the user, enabling developers to easily write complex agentic chains with fewer lines of code.
We’re super excited to help people build intelligent AI systems with our new embedded function calling and powerful tools. Check out our developer docs on how to get started, and let us know what you think on Discord.