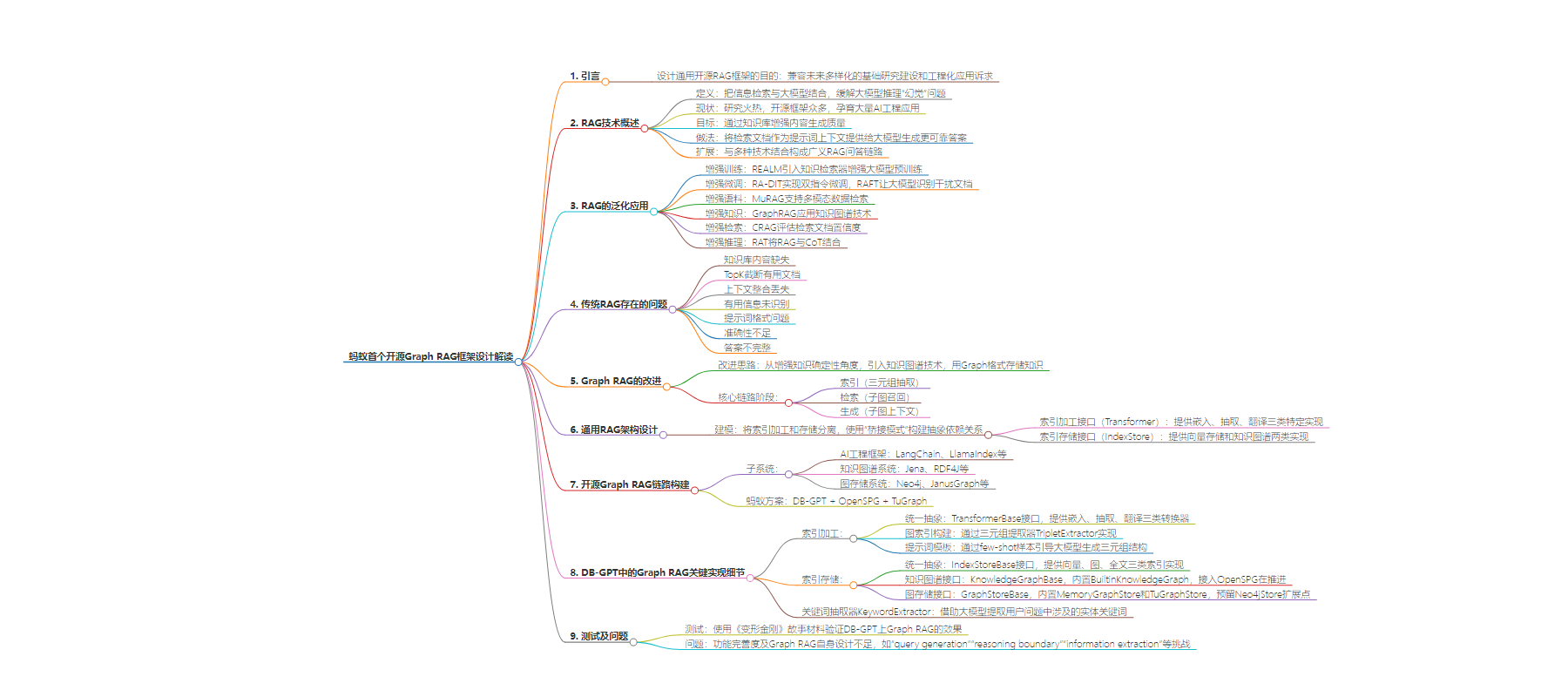
TRIPLET_EXTRACT_PT = ("Some text is provided below. Given the text, ""extract up to knowledge triplets as more as possible ""in the form of (subject, predicate, object).\n""Avoid stopwords.\n""---------------------\n""Example:\n""Text: Alice is Bob's mother.\n""Triplets:\n(Alice, is mother of, Bob)\n" ...TL;DR..."Text: Philz is a coffee shop founded in Berkeley in 1982.\n""Triplets:(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n(Philz, founded in, 1982)\n""---------------------\n""Text: {text}\n""Triplets:\n")
KEYWORD_EXTRACT_PT = ( "A question is provided below. Given the question, extract up to " "keywords from the text. Focus on extracting the keywords that we can use" "to best lookup answers to the question.\n" "Generate as more as possible synonyms oraliasof the keywords " "considering possible cases of capitalization, pluralization, " "common expressions, etc.\n" "Avoid stopwords.\n" "Provide the keywords and synonyms in comma-separated format." "Formatted keywords and synonyms text should be separated by a semicolon.\n" ""Example:\n""Text: Alice is Bob's mother.\n""Keywords:\nAlice,mother,Bob;mummy\n""Text: Philz is a coffee shop founded in Berkeley in 1982.\n""Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n""---------------------\n""Text: {text}\n""Keywords:\n")
asyncdefasimilar_search_with_scores( self, text, topk, score_threshold: float, filters: Optional[MetadataFilters] = None,) -> List[Chunk]:"""Search neighbours on knowledge graph."""ifnot filters: logger.info("Filters on knowledge graph not supported yet") keywords = await self._keyword_extractor.extract(text) subgraph = self._graph_store.explore(keywords, limit=topk) logger.info(f"Search subgraph from {len(keywords)} keywords") content = ("The following vertices and edges data after [Subgraph Data] ""are retrieved from the knowledge graph based on the keywords:\n"f"Keywords:\n{','.join(keywords)}\n""---------------------\n""You can refer to the sample vertices and edges to understand ""the real knowledge graph data provided by [Subgraph Data].\n""Sample vertices:\n""(alice)\n""Sample edges:\n""(alice)-[reward]->(alice)\n""---------------------\n"f"Subgraph Data:\n{subgraph.format()}\n" )return [Chunk(content=content, metadata=subgraph.schema())]
GraphRAG, like RAG, has clear limitations, which include how to form graphs, generate queries for querying these graphs, and ultimately decide how much information to retrieve based on these queries. The main challenges are ‘query generation’, ‘reasoning boundary’, and ‘information extraction’.
通过以上介绍,相信大家对RAG到Graph RAG的技术演进有了更进一步的了解,并且基于RAG的索引、检索、生成三个基本阶段抽象出了通用的RAG框架,兼容了Vector、Graph、FullText等多种索引形式,最终在开源技术中完整落地。最后通过探讨Graph RAG未来的优化与演进方向,总结了内容索引和检索生成阶段的不同改进思路,以及RAG向Agent架构的演化趋势。Graph RAG是个相对新颖AI工程领域,需要探索和改进的工作还有很多要做,我们诚邀DB-GPT/OpenSPG/TuGraph的广大开发者们一起参与共建。前不久Jerry Liu(LlamaIndex CEO)在技术报告《Beyond RAG: Building Advanced Context-Augmented LLM Applications》中也抛出了“RAG的未来是Agent”相似观点。所以,无论是“RAG for Agents”还是“Agents for RAG”,亦或是“从RAG到Graph RAG再到Agents”,目光可及的是智能体将是未来AI应用的主旋律。1. RALM_Survey:https://github.com/2471023025/RALM_Survey2. Retrieval-Augmented Generation for Large Language Models: A Survey:https://arxiv.org/abs/2312.109973. A Survey on Retrieval-Augmented Text Generation for Large Language Models:https://arxiv.org/abs/2404.109814. Retrieving Multimodal Information for Augmented Generation: A Survey:https://arxiv.org/abs/2303.108685. Evaluation of Retrieval-Augmented Generation: A Survey:https://arxiv.org/abs/2405.074376. GFMPapers:https://github.com/BUPT-GAMMA/GFMPapers7. REALM: Retrieval-Augmented Language Model Pre-Training:https://arxiv.org/abs/2002.089098. RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation:https://arxiv.org/abs/2403.053139. RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing:https://arxiv.org/pdf/2404.1954310. RA-DIT: Retrieval-Augmented Dual Instruction Tuning:https://arxiv.org/abs/2310.0135211. RAFT: Adapting Language Model to Domain Specific RAG:https://arxiv.org/abs/2403.1013112. MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text:https://arxiv.org/abs/2210.0292813. Corrective Retrieval Augmented Generation:https://arxiv.org/abs/2401.1588414. Full Fine-Tuning, PEFT, Prompt Engineering, and RAG: Which One Is Right for You?:https://deci.ai/blog/fine-tuning-peft-prompt-engineering-and-rag-which-one-is-right-for-you/15. An Easy Introduction to Multimodal Retrieval-Augmented Generation:https://developer.nvidia.com/blog/an-easy-introduction-to-multimodal-retrieval-augmented-generation/16. Towards Long Context RAG:https://www.llamaindex.ai/blog/towards-long-context-rag17. Full Fine-Tuning, PEFT, Prompt Engineering, and RAG: Which One Is Right for You?:https://deci.ai/blog/fine-tuning-peft-prompt-engineering-and-rag-which-one-is-right-for-you/18. Advance RAG- Improve RAG performance:https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a19. Advanced Retrieval-Augmented Generation: From Theory to LlamaIndex Implementation:https://towardsdatascience.com/advanced-retrieval-augmented-generation-from-theory-to-llamaindex-implementation-4de1464a993020. RAGFlow:https://github.com/infiniflow/ragflow21. LangChain RAG:https://python.langchain.com/v0.1/docs/use_cases/question_answering/22. From Local to Global: A Graph RAG Approach to Query-Focused Summarization:https://arxiv.org/abs/2404.1613023. Seven Failure Points When Engineering a Retrieval Augmented Generation System:https://arxiv.org/abs/2401.0585624. Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning:https://arxiv.org/abs/2310.0106125. GraphRAG: Unlocking LLM discovery on narrative private data:https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/26. From RAG to GraphRAG , What is the GraphRAG and why i use it?:https://medium.com/@jeongiitae/from-rag-to-graphrag-what-is-the-graphrag-and-why-i-use-it-f75a7852c10c27. GraphRAG: Design Patterns, Challenges, Recommendations:https://gradientflow.com/graphrag-design-patterns-challenges-recommendations/28. lettria:https://www.lettria.com/features/graphrag29. Implementing GraphRAG for Query-Focused Summarization:https://dev.to/stephenc222/implementing-graphrag-for-query-focused-summarization-47ib30. LlamaIndex Graph RAG:https://docs.llamaindex.ai/en/stable/examples/query_engine/knowledge_graph_rag_query_engine/31. DB-GPT Graph RAG:https://docs.dbgpt.site/docs/latest/cookbook/rag/graph_rag_app_develop32. RAGAS: Automated Evaluation of Retrieval Augmented Generation:https://arxiv.org/abs/2309.1521733. Benchmarking Large Language Models in Retrieval-Augmented Generation:https://arxiv.org/abs/2309.0143134. CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models:https://arxiv.org/abs/2401.17043v235. ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems:https://arxiv.org/abs/2311.0947636. RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge:https://arxiv.org/abs/2311.0814737. MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion:https://arxiv.org/abs/2404.0946838. OneKE:https://github.com/zjunlp/DeepKE/blob/main/example/llm/OneKE.md39. Apache Jena:https://github.com/apache/jena40. Eclipse RDF4J:https://github.com/eclipse-rdf4j/rdf4j41. Oxigraph:https://github.com/oxigraph/oxigraph42. OpenSPG:https://github.com/OpenSPG/openspg43. Neo4j:https://github.com/neo4j/neo4j44. JanusGraph:https://github.com/JanusGraph/janusgraph45. NebulaGraph:https://github.com/vesoft-inc/nebula46. TuGraph:https://github.com/TuGraph-family/tugraph-db47. DB-GPT v0.5.6: https://github.com/eosphoros-ai/DB-GPT/releases/tag/v0.5.648. Graph RAG PR: https://github.com/eosphoros-ai/DB-GPT/pull/150649. tranformers_story.md: https://github.com/eosphoros-ai/DB-GPT/blob/main/examples/test_files/tranformers_story.md50. DB-GPT:https://github.com/eosphoros-ai/DB-GPT