包阅导读总结
1. 关键词:大模型、AI 基础设施、Llama 3.1、语言模型、技术优化
2. 总结:7 月 29 日的学术篇涵盖多个大模型相关内容,包括零一万物的 AI 基础设施建设方案,Llama 3.1 的技术要点,以及在单个节点上对其微调的方法、vTensor 系统、语言模型物理研究、Triton 内核优化等,还涉及人形机器人和相关评测与服务器项目。
3. 主要内容:
– 搭建 AI 学习社群
– 提供《大模型日报》最新推送
– 零一万物 AI 基础设施建设
– 硬件异构整合和软件编排优化为核心
– 实现资源高效利用和提升任务调度效率
– Llama 3.1
– 模型设计优化
– 数据处理确保高质量
– 多方面能力提升
– 在单个节点上微调 Llama 3.1 405B
– 采用低秩适应等技术克服内存限制
– vTensor 系统
– 实现内存共享和动态资源调配
– 语言模型物理研究
– 知识提取、处理和容量等方面的探讨
– Triton 内核优化
– 代码、并行化、内存访问等优化策略
– 人形机器人
– 技术发展历程和应用
– 存在的挑战和未来展望
– 相关项目
– llm-colosseum 评测平台
– Lollms 文本生成服务器
思维导图: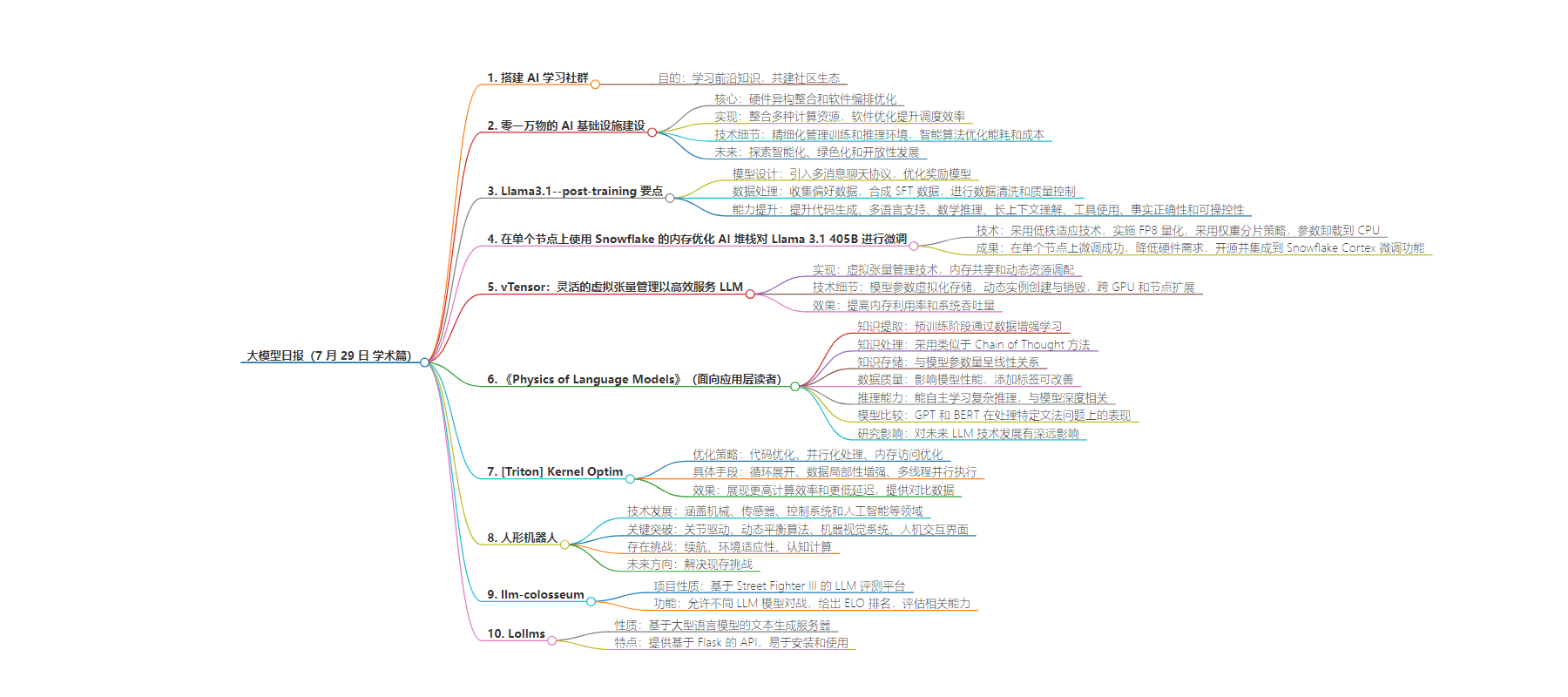
文章地址:https://mp.weixin.qq.com/s/_xvXl54r6IyNW5_sWNmF8w
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/7/29 11:29
语言:中文
总字数:2413字
预计阅读时间:10分钟
评分:88分
标签:AI技术,大模型,AI基础设施,模型优化,应用场景
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

学习
零一万物面向万卡集群的AI基础设施建设
零一万物针对万卡集群的 AI 基础设施建设,提出了一套以硬件异构整合和软件编排优化为核心的解决方案。该方案通过将 CPU、GPU 等多种计算资源整合,实现了资源的高效利用,并通过软件层面的优化,提升了任务调度的灵活性和效率。在技术细节上,文章强调了对 AI 模型训练和推理环境的精细化管理,以及通过智能算法优化能源消耗和成本。未来,零一万物将继续探索 AI 基础设施的智能化、绿色化和开放性发展,以适应不断变化的 AI 计算需求。
Llama3.1–post-training要点一览
在模型设计上,Llama3.1 引入了 multi-message chat protocol 以支持更复杂的对话场景,并优化了奖励模型(RM),移除了 margin term 以提高训练效率。数据处理方面,通过偏好数据的收集、SFT 数据的合成以及数据清洗和质量控制,确保了训练数据的高质量。在能力提升上,Llama3.1 通过代码专用的 system prompt 和执行反馈机制提升了代码生成能力;通过多语言专家模型和多语言数据收集增强了多语言支持;采用了步骤推理、自我验证和工具调用等策略来提升数学推理能力;通过长文本关键场景数据的加入提升了长上下文理解能力;通过 core tools 的使用和 zero-shot 工具调用能力的训练,扩展了模型的工具使用能力;通过生成与预训练数据一致的微调数据,提高了事实正确性;最 ließlich,通过设计不同的 system prompt,提升了模型的可操控性。这些技术细节的精心设计和实施,使得 Llama3.1 成为了一个性能强大、多任务适应的大型语言模型。
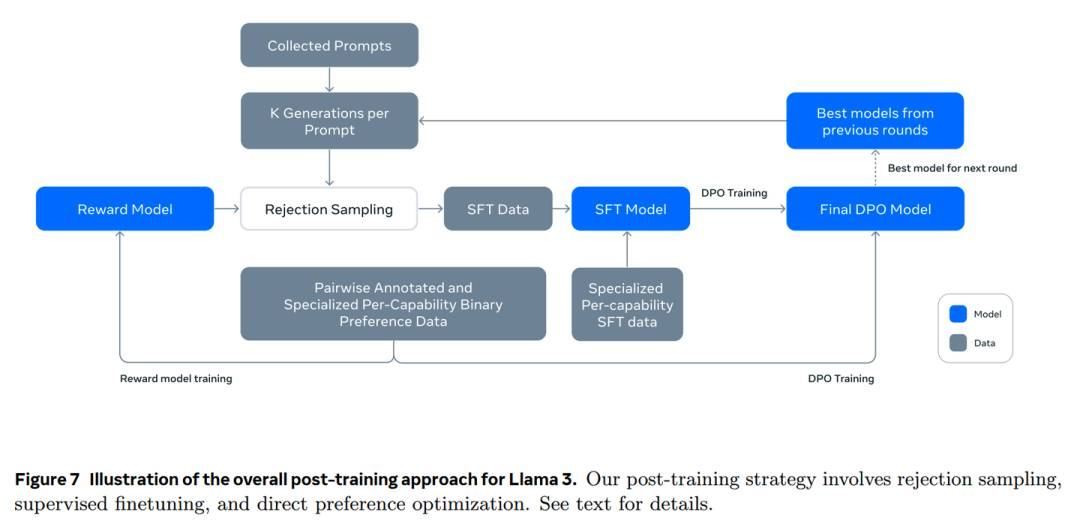 https://zhuanlan.zhihu.com/p/711295334?utm_psn=1801036979611254784
https://zhuanlan.zhihu.com/p/711295334?utm_psn=1801036979611254784
在单个节点上使用Snowflake的内存优化AI堆栈对Llama 3.1 405B进行微调
Snowflake 的 AI 研究团队在单个节点上成功微调了 Meta Llama 3.1 405B 大型语言模型。为了克服内存限制,他们采用了低秩适应(LoRA)技术,通过设置 lora_r 为 64,减少了内存需求。此外,他们实施了 FP8 量化,进一步降低了内存占用。他们还采用了类似 ZeRO-3 的权重分片策略,并通过针对性的参数卸载到 CPU 来解决激活内存和其他内存开销的问题。这些技术细节的优化使得在 8 x H100-80GB 主机上进行模型微调成为可能,大大降低了对硬件资源的需求,并且这些优化已经开源,也将集成到 Snowflake Cortex 的微调功能中。
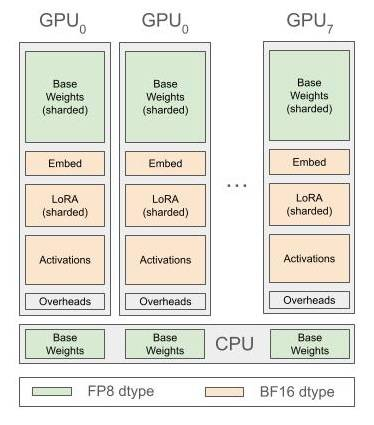 https://www.snowflake.com/engineering-blog/fine-tune-llama-single-node-snowflake/
https://www.snowflake.com/engineering-blog/fine-tune-llama-single-node-snowflake/
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
vTensor 系统通过虚拟张量管理技术,实现了大型语言模型(LLM)服务中的内存共享和动态资源调配,提高了内存利用率和系统吞吐量。技术细节包括模型参数的虚拟化存储、动态实例创建与销毁机制,以及跨多个 GPU 和节点的扩展能力。这些技术的应用使得模型服务能够更加高效和灵活地应对不同的业务需求,同时保持了较高的性能表现。
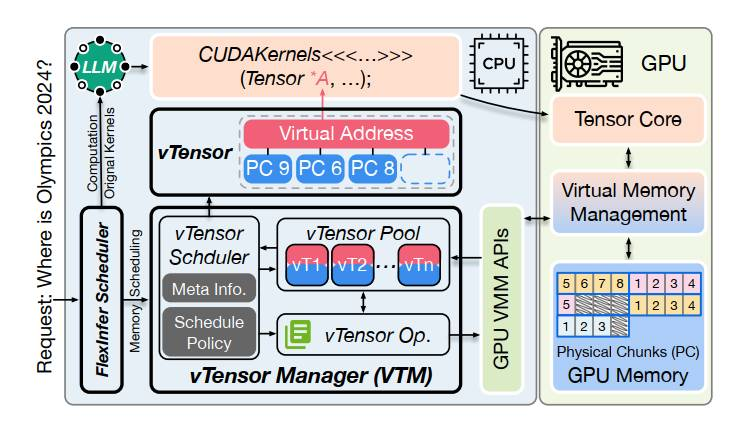 https://zhuanlan.zhihu.com/p/711174278?utm_psn=1801031207485583361
https://zhuanlan.zhihu.com/p/711174278?utm_psn=1801031207485583361
Physics of Language Models(面向应用层读者)
《Physics of Language Models》系列论文深入探讨了大型语言模型(LLM)的技术细节,特别是在知识提取、处理和容量等方面。研究指出,LLM 需要在预训练阶段通过数据增强学习正确的知识提取方法,这种能力在不同知识和数据格式之间具有可迁移性。在知识处理上,LLM 采用类似于 Chain of Thought(CoT)的方法,能够提高信息处理的准确性。此外,论文发现 LLM 的知识存储能力与模型参数量呈线性关系,符合 2 bit/param 的 Scaling Law,但这假设知识在训练中出现了至少 1000 次。数据质量对模型性能有显著影响,低质量数据会降低知识容量,而添加数据来源标签可以改善这一情况。在推理能力上,LLM 能够自主学习到复杂的推理过程,如小学数学推理,这种能力与模型深度相关。同时,LLM 能够从错误中学习,提升纠错能力。研究还比较了 GPT 和 BERT 模型,发现 GPT 在处理特定文法问题时表现更优。最后,论文强调了预训练阶段的数据增强对于 LLM 能力获取的重要性,而微调阶段在某些任务上的效果有限。作者预测这些研究成果将对未来的 LLM 技术发展产生深远影响。
 https://zhuanlan.zhihu.com/p/711391378?utm_psn=1801032178664103936
https://zhuanlan.zhihu.com/p/711391378?utm_psn=1801032178664103936
[Triton] Kernel Optim
文章深入探讨了 Triton 内核的优化策略,重点分析了如何通过代码优化、并行化处理、内存访问优化等技术手段提升内核性能。具体包括对热点函数进行循环展开、数据局部性增强、多线程并行执行等。通过这些细节优化,Triton 内核在实际应用中展现出更高的计算效率和更低的延迟。文章还提供了优化前后的对比数据,证明了所采取措施的有效性,并指出在优化过程中需要注意的问题和挑战。
https://zhuanlan.zhihu.com/p/711302973?utm_psn=1801033341094461441
人形机器人:历史回顾,进展梳理(技术&应用&挑战)和未来展望
人形机器人的技术发展历程涵盖了机械、传感器、控制系统和人工智能等多个领域。机械设计追求轻量化和高效率,以提升机器人的运动灵活性和载重能力。传感器技术的进步,尤其是在视觉和触觉感知方面,使得机器人能够更准确地感知环境。控制系统则通过先进的算法,实现精确的运动控制和稳定的动态平衡。人工智能的融合,赋予了机器人学习、决策和自适应的能力,使其能够执行更复杂的任务。在技术细节上,人形机器人的关节驱动技术、动态平衡算法、机器视觉系统和人机交互界面等方面的突破,是其能够在各类应用场景中得到广泛应用的关键。尽管如此,人形机器人在续航能力、环境适应性和认知计算等方面仍然存在挑战,这些都是当前研究的热点和未来发展的方向。
llm-colosseum
这个项目是一个基于 Street Fighter III 的 LLM 评测平台。它允许不同的 LLM 模型在游戏中进行实时对战,并根据他们的表现给出 ELO 排名。这个项目希望评估 LLM 在理解环境、做出决策和适应变化等方面的能力。
https://github.com/OpenGenerativeAI/llm-colosseum
Lollms
LoLLMs (Lord of Large Language Models) 是一个基于大型语言模型的文本生成服务器。它提供了一个基于 Flask 的 API,用于使用各种预训练的语言模型生成文本。这个服务器易于安装和使用,允许开发人员将强大的文本生成功能集成到他们的应用程序中。
 https://github.com/ParisNeo/lollms
https://github.com/ParisNeo/lollms
-
-
-
— END —
