
包阅导读总结
思维导图:
文章地址:https://mp.weixin.qq.com/s/9gPydt8Suuhc-zS-FvqdaA
文章来源:mp.weixin.qq.com
作者:新智元
发布时间:2024/8/13 4:42
语言:中文
总字数:3014字
预计阅读时间:13分钟
评分:90分
标签:大型语言模型,CPU推理优化,混合精度矩阵乘法,查找表计算,边缘设备部署
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
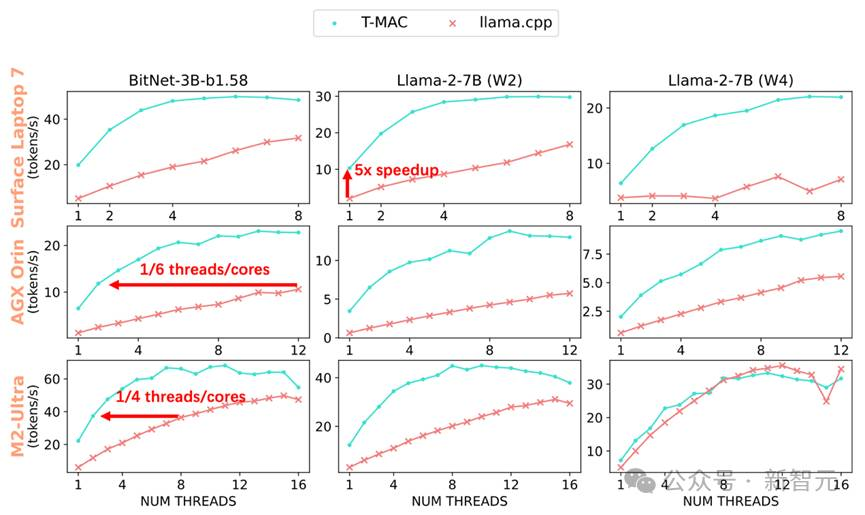
图2 在不同端侧设备CPU(Surface Laptop 7, NVIDIA AGX Orin, Apple M2-Ultra)的各核数下T-MAC和llama.cpp的token生成速度可达llama.cpp的4-5倍。达到相同的生成速率,T-MAC所需的核心数仅为原始llama.cpp的1/4至1/6
对于低比特参数 (weights),T-MAC将每一个比特单独进行分组(例如,一组4个比特),这些比特与激活向量相乘,预先计算所有可能的部分和,然后使用LUT进行存储。
之后,T-MAC采用移位和累加操作来支持从1到4的可扩展位数。通过这种方法,T-MAC抛弃了CPU上效率不高的FMA(乘加)指令,转而使用功耗更低效率也更高的TBL/PSHUF(查表)指令。
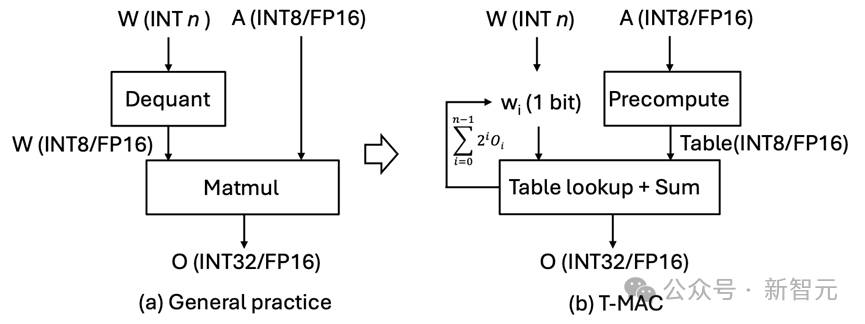
图3 混合精度GEMV基于现有反量化的实现范式vs T-MAC基于查找表的新范式
传统的基于反量化的计算,实际上是以数据类型为核心的计算,这种方式需要对每一种不同的数据类型单独定制。
每种激活和权重的位宽组合,如W4A16(权重int4激活float16) 和W2A8,都需要特定的权重布局和计算内核。
举个例子,W3的布局需要将2位和另外1位分开打包,并利用不同的交错或混洗方法进行内存对齐或快速解码。然后,相应的计算内核需要将这种特定布局解包到硬件支持的数据类型进行执行。
而T-MAC通过从比特的视角观察低比特矩阵乘计算,只需为单独的一个比特设计最优的数据结构,然后通过堆叠的方式扩展到更高的2/3/4比特。
同时,对于不同精度的激活向量(float16/float32/int8),仅有构建表的过程需要发生变化,在查表的时候不再需要考虑不同的数据结构。
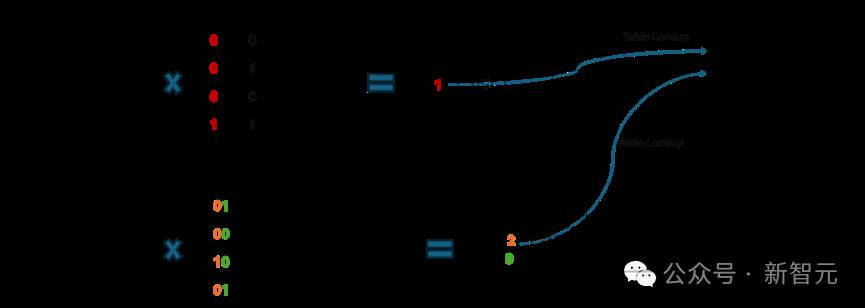
图4以比特为核心的查表计算混合精度GEMV
同时,传统基于反量化的方法,从4-比特降低到3/2/1-比特时,尽管内存占用更少,但是计算量并未减小,而且由于反量化的开销不减反增,性能反而可能会更差。
但T-MAC的计算量随着比特数降低能够线性减少,从而在更低比特带来更好加速,为最新的工作BitNet,EfficientQAT等发布的1-比特/2-比特模型提供了高效率的部署方案。
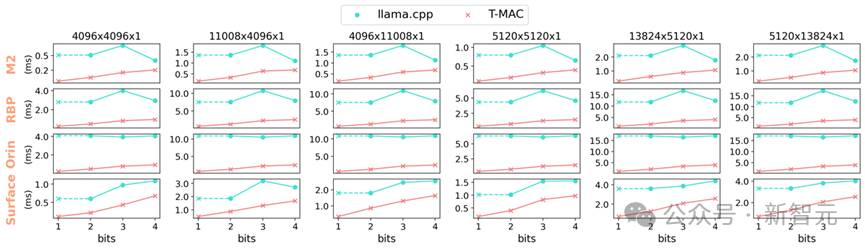
图5 使用不同端侧设备CPU的单核,T-MAC在4到1比特的混合精度GEMV算子相较llama.cpp加速3-11倍。T-MAC的GEMM耗时能随着比特数减少线性减少,而基于反量化的llama.cpp无法做到(1比特llama.cpp的算子性能由其2比特实现推算得到)
基于比特为核心的计算具有许多优势,但将其实现在CPU上仍具有不小的挑战:
(1)与激活和权重的连续数据访问相比,表的访问是随机的。表在快速片上内存中的驻留对于最终的推理性能尤为重要;
(2)然而,片上内存是有限的,查找表(LUT)方法相比传统的mpGEMV增大了片上内存的使用。这是因为查找表需要保存激活向量与所有可能的位模式相乘的结果。这比激活本身要多得多。
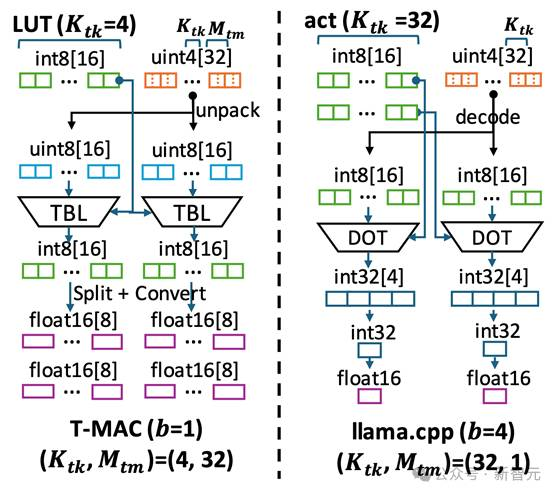
图6 T-MAC与llama.cpp在计算数据流上的不同
为此,微软亚洲研究院的研究员们深入探究了基于查表的计算数据流,为这种计算范式设计了高效的数据结构和计算流程,其中包括:
1. 将LUT存入片上内存,以利用CPU上的查表向量指令(TBL/PSHUF)提升随机访存性能。
2. 改变矩阵axis计算顺序,以尽可能提升放入片上内存的有限LUT的数据重用率。
3. 为查表单独设计最优矩阵分块(Tiling)方式,结合autotvm搜索最优分块参数
4. 参数weights的布局优化
a)weights重排,以尽可能连续访问并提升缓存命中率
b)weights交错,以提升解码效率
5.对Intel/ARM CPU 做针对性优化,包括
a)寄存器重排以快速建立查找表
b)通过取平均数指令做快速8-比特累加
研究员们在一个基础实现上,一步步应用各种优化,最终相对于SOTA低比特算子获得显著加速:
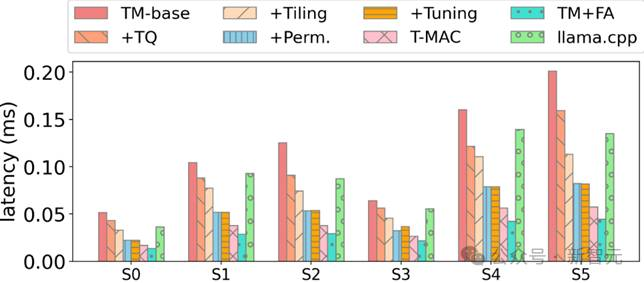
图7:在实现各种优化后,T-MAC 4-比特算子最终相对于llama.cpp 获得显著加速