我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
Arctic-TILT:处理Sub-Billion规模的商业文档理解
摘要:绝大部分使用LLM的工作负载涉及回答基于PDF或扫描内容的问题。我们引入了Arctic-TILT,其在这些用例中的准确性与其1000倍大小的模型相当。它可以在单个24GB GPU上进行微调和部署,降低运营成本,同时处理高达400k个token的视觉丰富文档。该模型在七个不同的文档理解基准测试中建立了最先进的结果,还提供可靠的置信度分数和快速推理,这对于在大规模或时间紧迫的企业环境中处理文件至关重要。
 http://arxiv.org/abs/2408.04632v1
http://arxiv.org/abs/2408.04632v1
学习细粒度的基础引文,为带属性的大语言模型
尽管大语言模型(LLMs)在信息检索任务上表现出色,但仍然存在幻觉问题。归因于LLMs的方法通过内联引用在生成的文本中增加参考信息,已显示出在减轻幻觉和提高可验证性方面的潜力。然而,由于依赖上下文学习,当前方法的引用质量不佳。此外,仅引用粗略文档标识的做法使用户难以进行细粒度验证。在这项工作中,我们介绍了FRONT,一个旨在教导LLMs生成精细级引用的训练框架。通过将模型输出置于细粒度支持引用中,这些引用引导生成根据事实的一致性回复,并不仅提高引用质量,还促进细粒度验证。ALCE基准测试上的实验证明了FRONT在生成优质事实支持的回复和引用方面的有效性。LLaMA-2-7B模型框架明显胜过所有基线,所有数据集上引用质量平均提升14.21%,甚至超过ChatGPT。
 http://arxiv.org/abs/2408.04568v1
http://arxiv.org/abs/2408.04568v1
对话提示工程
摘要:智能体与LLM之间的交互方式通常通过提示来实现。然而,有效的提示对指导LLM生成期望的输出至关重要。我们提出了对话式提示工程(CPE),这是一种用户友好的工具,帮助用户为特定任务创建个性化提示。CPE利用聊天模型与用户交互,帮助他们表达输出偏好,并将其整合到提示中。用户研究表明,CPE在创建个性化、高性能提示方面具有价值。结果表明,零-shot提示与其较长的few-shot对照组相当,可在涉及大文本量的重复任务中节省大量时间。
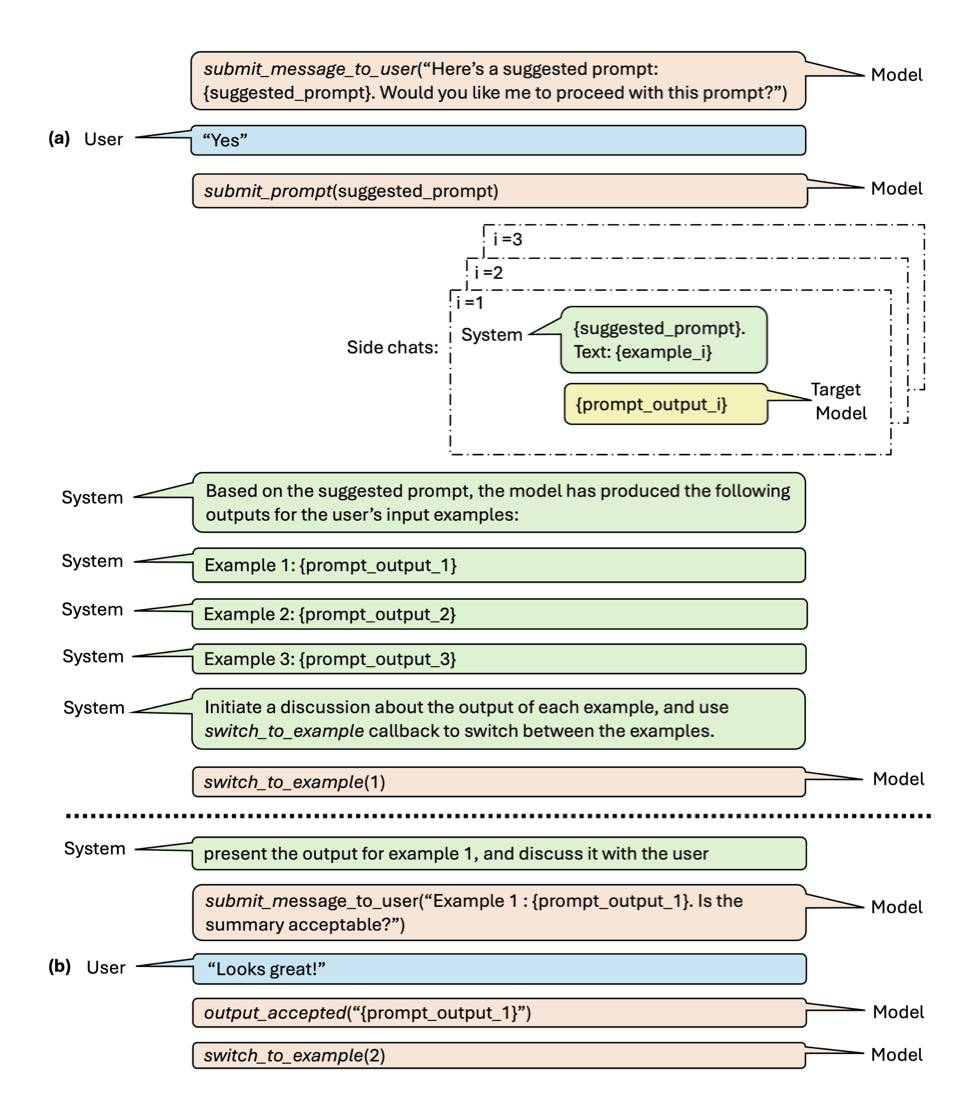 http://arxiv.org/abs/2408.04560v1
http://arxiv.org/abs/2408.04560v1
大语言模型生成的开放领域隐式格式控制
摘要:控制大语言模型(LLMs)生成的输出格式在各种应用中至关重要。目前的方法通常采用受限解码、基于规则的自动机或微调手工制作的格式指令,但在开放域格式要求方面存在困难。为解决这一局限,我们提出了一个新的框架,用于在LLMs中进行控制生成,利用用户提供的一次性问答对。本研究调查了LLMs遵循开放领域一次性约束的能力,并复制示例答案的格式。我们观察到,这对当前的LLMs来说是一个非常困难的问题。我们还开发了一种数据集收集方法,用于监督微调,增强LLMs的开放领域格式控制能力而不降低输出质量,以及一个基准测试,用于评估LLMs输出的帮助性和格式正确性。生成的数据集OIFC-SFT,以及相关代码,将在https://github.com/cofe-ai/OIFC上公开。
 http://arxiv.org/abs/2408.04392v1
http://arxiv.org/abs/2408.04392v1
EfficientRAG:多跳问答的高效检索器
摘要:在处理复杂问题如多跳查询时,检索增强生成(RAG)方法遇到困难。虽然迭代检索方法通过收集额外信息来提高性能,但当前方法通常依赖于多次调用大语言模型(LLM)。本文介绍EfficientRAG,一个用于多跳问题回答的高效检索器。EfficientRAG在每次迭代中迭代生成新查询,而无需每次调用LLM,并过滤掉无关信息。实验结果表明EfficientRAG在三个开放领域多跳问题回答数据集上超越了现有的RAG方法。
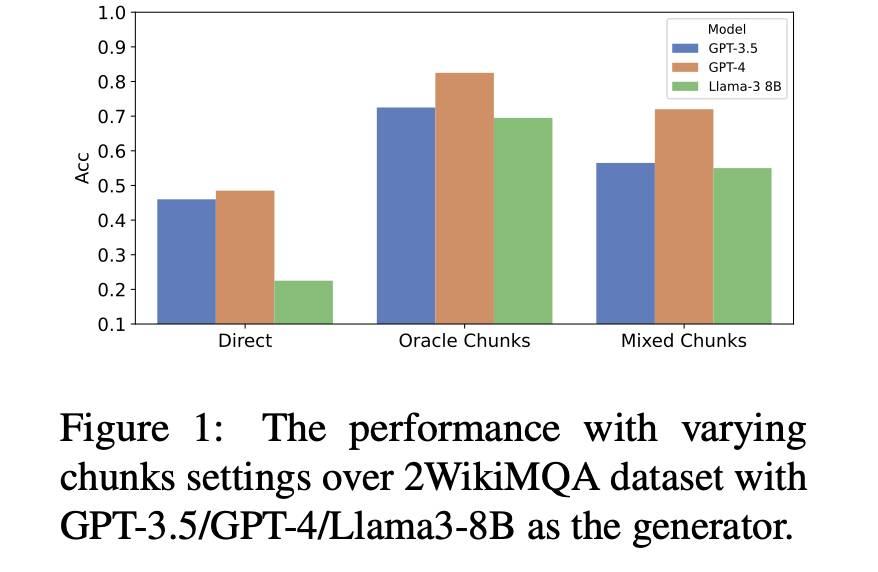 http://arxiv.org/abs/2408.04259v1
http://arxiv.org/abs/2408.04259v1
扩散引导的语言建模
当前的语言模型在文本生成方面表现出色。然而,对于许多应用程序,控制所生成语言的属性,如情感或毒性,是很有必要的,最好根据每个具体的用例和目标受众来定制。自回归语言模型,在现有的引导方法中容易出现解码错误,在生成过程中会出现级联效应,降低性能。相反,文本扩散模型可以轻松受到引导,例如简单的线性情感分类器,但它们的困惑度明显高于自回归替代方案。在本文中,我们使用引导扩散模型生成潜在提案,引导自回归语言模型生成具有所需属性的文本。我们的模型继承了自回归方法无与伦比的流畅性和扩散的即插即用灵活性。我们展示它在各种基准数据集上优于先前的即插即用引导方法。此外,在我们的框架中控制一个新的属性被简化为训练一个单一的逻辑回归分类器。
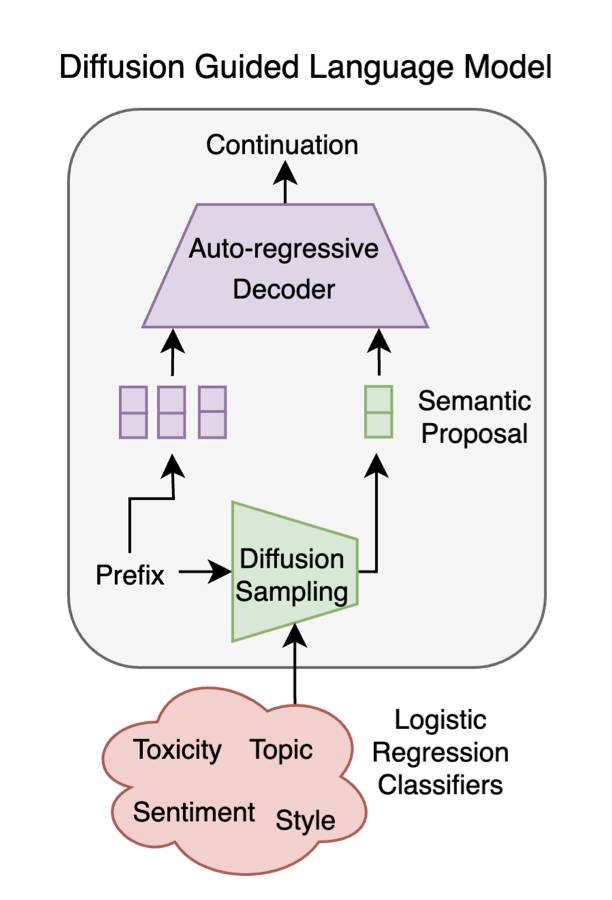 http://arxiv.org/abs/2408.04220v1
http://arxiv.org/abs/2408.04220v1
简化儿童翻译:考虑LLM年龄采集的迭代简化
近年来,神经机器翻译(NMT)已被广泛应用于日常生活。然而,目前的NMT缺乏一种机制来调整翻译的难度级别,以匹配用户的语言水平。此外,由于NMT训练数据的偏见,简单源句的翻译通常会用复杂词汇。这可能对孩子们构成问题,他们可能无法正确理解翻译的含义。在这项研究中,我们提出了一种方法,将翻译中高获取年龄(AoA)的单词替换为更简单的单词,以匹配用户的水平。我们通过使用大型语言模型(LLMs)来实现这一目标,提供源句、翻译和待替换的目标单词的三元组。我们通过在简单英语维基百科上进行回译来创建基准数据集。从数据集中获得的实验结果显示,我们的方法有效地用低AoA单词替换高AoA单词,并且可以迭代地替换大多数高AoA单词,同时仍保持高BLEU和COMET分数。
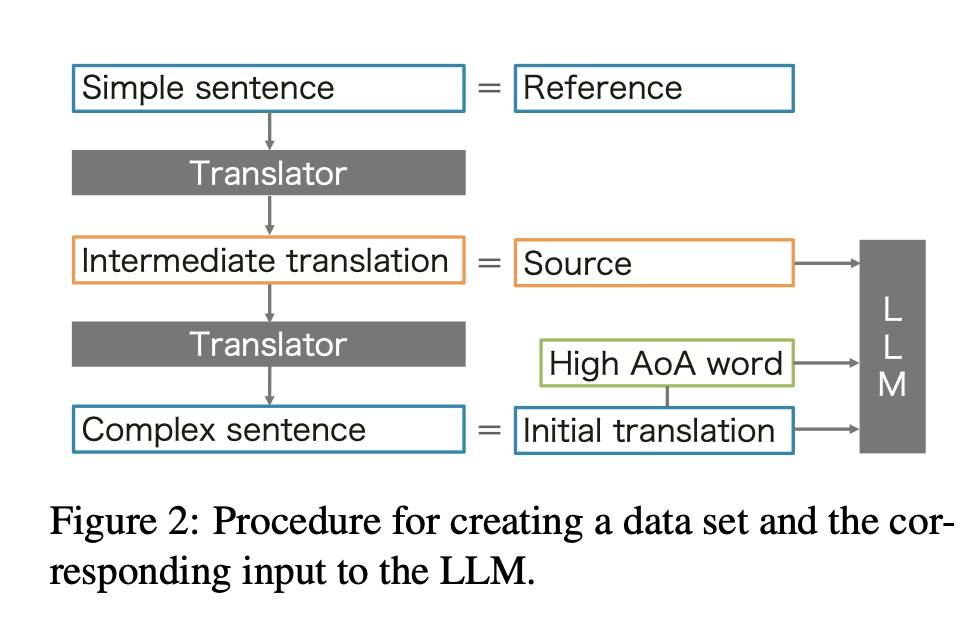 http://arxiv.org/abs/2408.04217v1
http://arxiv.org/abs/2408.04217v1
Optimus-1
Optimus-1 是一种多模态智能体,结合了混合多模态记忆模块,通过分层知识图和经验池来提升其在开放世界中完成长期任务的能力。它配备知识指导规划器和经验驱动反思器,在 Minecraft 等复杂环境中表现优异,实验结果显示其在多个任务上接近人类水平,并超越了 GPT-4V 基线,标志着向类人智能体的重要进展。
 https://cybertronagent.github.io/Optimus-1.github.io/
https://cybertronagent.github.io/Optimus-1.github.io/
Idefics3-8B-Llama3
Idefics3-8B-Llama3 是一种大型语言模型,属于 Llama 系列(LLaMA,Large Language Model Meta AI)。这些模型通常用于自然语言处理任务,如文本生成、理解和对话。Idefics3-8B-Llama3 可能是特定版本或配置的模型,具有 8 亿个参数,希望可以提高在特定任务或领域中的表现。
https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3
-
-
-
— END —
