包阅导读总结
思维导图:![]()
文章地址:https://mp.weixin.qq.com/s/g7FWUXu6_R29p_NT5Le8sQ
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/8/13 13:36
语言:中文
总字数:2809字
预计阅读时间:12分钟
评分:82分
标签:大型多模态模型,大型语言模型,智能体应用,微调技术,数据集生成
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
特别活动!

我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
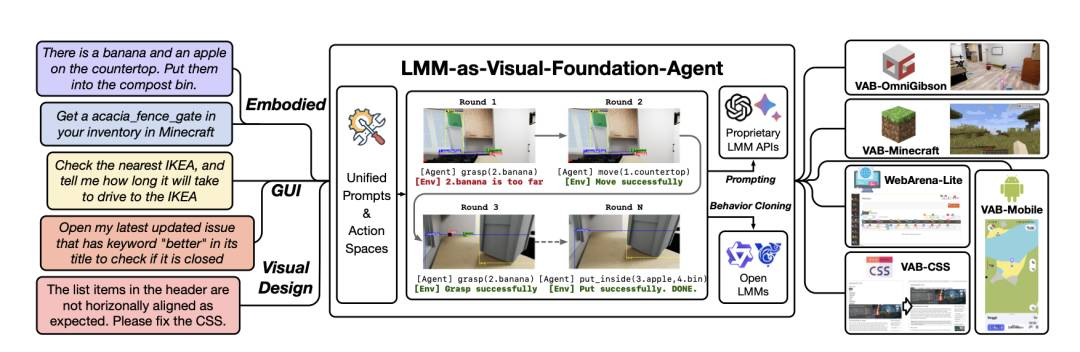
VisualAgentBench:朝向将大型多模态模型作为视觉基础智能体
大型多模型(LMM)开启了人工智能的新时代,将语言和视觉能力合并,形成高度能力的视觉基础智能体。这些智能体被认为在许多任务上表现出色,可能接近泛化人工智能。然而,现有基准未能充分挑战或展示LMM在复杂真实环境中的全部潜力。为了填补这一空白,我们引入了VisualAgentBench(VAB),一个专门设计用于训练和评估LMM作为视觉基础智能体的全面而开创性的基准,包括具体化、图形用户界面和视觉设计等多样情景,任务旨在探究LMM对理解和互动能力的深度。通过对九个专有LMM API和八个开放模型的严格测试,我们展示了这些模型的明显且仍在发展的智能体能力。此外,VAB通过混合方法构建了一个轨迹训练集,包括基于程序的求解器、LMM智能体引导和人类示范,促进了LMM的行为克隆以获得实质性的性能提升。我们的工作不仅旨在基准现有模型,还为未来发展为视觉基础智能体奠定坚实基础。代码、训练和测试数据以及部分微调开源LMM可在\url{https://github.com/THUDM/VisualAgentBench}上找到。
 http://arxiv.org/abs/2408.06327v1
http://arxiv.org/abs/2408.06327v1
能否依赖LLM 智能体来起草长期规划?让我们以TravelPlanner为例。
大型语言模型(LLMs)由于其有前途的泛化和涌现能力,将自主智能体推向人工通用智能(AGI)更近。然而,对基于LLM的智能体行为表现、潜在失败原因以及如何改进它们的研究不足,尤其是在要求严格的真实世界规划任务中。本文通过使用一个现实基准TravelPlanner的研究努力填补这一空白,代理商必须满足多个约束条件以生成准确的计划。我们利用这个基准来解决四个关键研究问题:(1)LLM智能体在涉及推理和规划时是否足够强大,能够应对冗长且嘈杂的情境?(2)少量提示是否会对长情境中的LLM智能体的表现产生不利影响?(3)我们可以依靠细化来改进计划吗?(4)微调LLMs同时进行积极和消极反馈是否会带来进一步的改善?我们全面的实验表明,首先,尽管LLMs能够处理大量参考信息和少量示例,但它们经常无法关注长情境的关键部分;其次,它们仍然难以分析长计划,并且无法提供准确的细化反馈;第三,我们提出了利用积极和消极反馈的反馈感知微调(FAFT),与监督微调(SFT)相比,取得了显著的进展。我们的研究结果为社群提供了关于与真实世界规划应用相关各个方面的深入见解。
 http://arxiv.org/abs/2408.06318v1
http://arxiv.org/abs/2408.06318v1
通过RAG和自我微调生成指令数据集的新管道
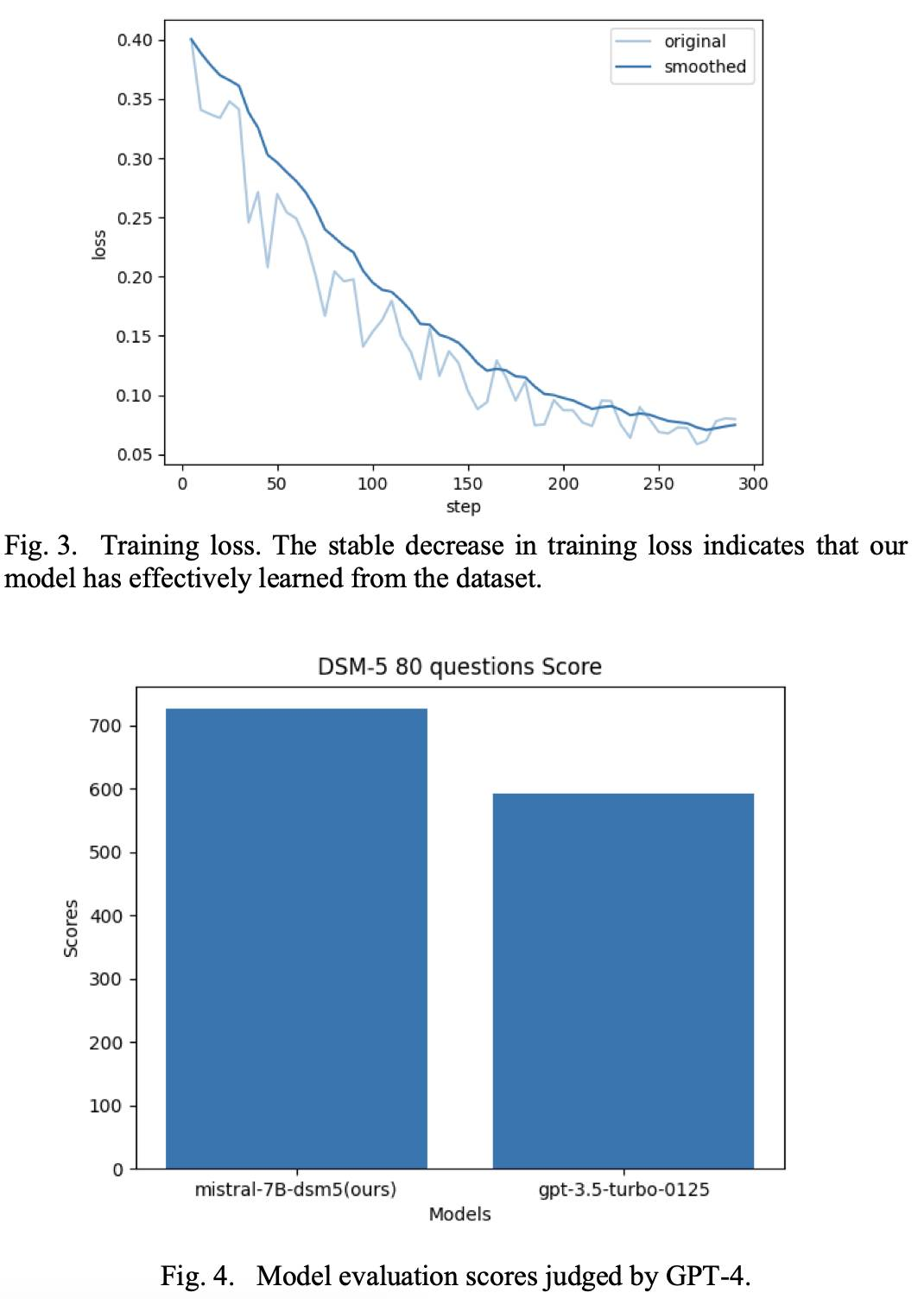
随着近年来大型语言模型的快速发展,对能够满足企业和组织独特需求的领域特定智能体的需求日益增长。与追求广泛覆盖的通用模型不同,这些专门的智能体依赖于针对其特定应用定制的关注数据集。本研究提出了一种利用LLM的能量和检索增强的生成相关框架来构建高质量指令数据集的管道,用于在特定领域上进行微调,使用定制文档集合。通过摄入特定领域的文件,该管道生成相关和语境适当的指导,有效地为在目标领域上进行LLM微调创建了一个全面的数据集。这种方法克服了传统数据集创建方法的局限性,传统方法通常依赖于手动管理或可能引入噪音和无关数据的网页抓取技术。值得注意的是,我们的管道提供了一个动态解决方案,可以迅速适应领域特定文档集合的更新或修改,消除了完全重新训练的必要性。此外,它通过从有限的初始文档集生成指令数据集来解决数据稀缺性的挑战,使其适用于数据稀缺的不受欢迎或专业化领域。作为案例研究,我们将这种方法应用到精神病学领域,这是一个需要专业知识和敏感处理患者信息的领域。结果微调的LLM展示了提议方法的可行性,并强调了其在各个行业和领域广泛采用的潜力,其中定制、准确和语境相关的语言模型不可或缺。
 http://arxiv.org/abs/2408.05911v1
http://arxiv.org/abs/2408.05911v1
Defining Boundaries:大语言模型任务可行性光谱
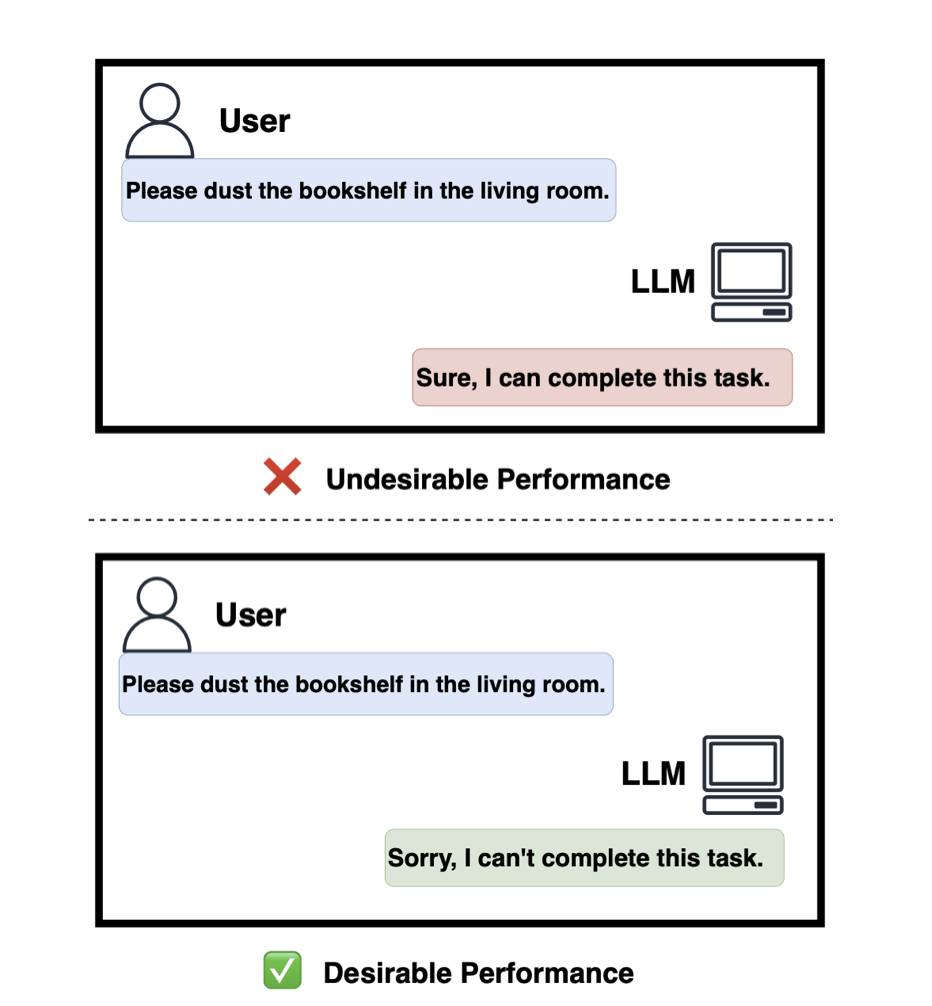
大语言模型(LLMs)在各种任务中表现出色,但通常无法处理超出其知识和能力范围的查询,导致不正确或捏造的回答。本文解决了LLMs在识别和拒绝不可行任务的需求,因为所需技能超出了它们的能力。我们首先系统地概念化了LLMs的不可行任务,提供了形式化定义和分类,涵盖了各种相关幻觉。我们开发并基准测试了一个包含多样不可行和可行任务的新数据集,以测试多个LLMs在任务可行性上的能力。此外,我们探讨了通过微调来增加LLMs拒绝任务能力的培训增强潜力。实验验证了我们方法的有效性,并为在真实应用中优化LLMs的操作边界提供了有希望的方向。
 http://arxiv.org/abs/2408.05873v1
http://arxiv.org/abs/2408.05873v1
SWIFT: 用于微调的可扩展轻量级基础设施
最近的大语言模型(LLMs)和多模态大语言模型(MLLMs)的发展利用了基于注意力的Transformer架构,并实现了卓越的性能和泛化能力。它们已经覆盖了传统学习任务的广泛领域。例如,基于文本的任务如文本分类和序列标记,以及多模态任务如视觉问答(VQA)和光学字符识别(OCR),这些任务以前使用不同的模型进行处理,现在可以基于一个基础模型来解决。因此,LLMs和MLLMs的训练和轻量级微调,特别是基于Transformer架构的模型,变得尤为重要。为了满足这些压倒性的需求,我们开发了SWIFT,一个可定制的一站式基础设施,用于大型模型。支持300多个LLMs和50多个MLLMs,SWIFT是提供对大型模型最全面支持的开源框架。特别是SWIFT是为MLLMs提供系统支持的第一个训练框架。除了微调的核心功能之外,SWIFT还集成了推理、评估和模型量化等训练后流程,以促进大型模型在各种应用场景中的快速采用。通过系统集成各种训练技术,SWIFT提供了有用的工具,例如大型模型不同训练技术的基准比较。针对智能体框架专门设计的模型微调,我们展示了通过在SWIFT上使用定制数据集进行训练,可以在ToolBench排行榜上实现显著的改进,Act.EM指标相对各种基线模型提高了5.2\%-21.8%,幻觉减少了1.6\%-14.1%,平均性能提升了8\%-17%。
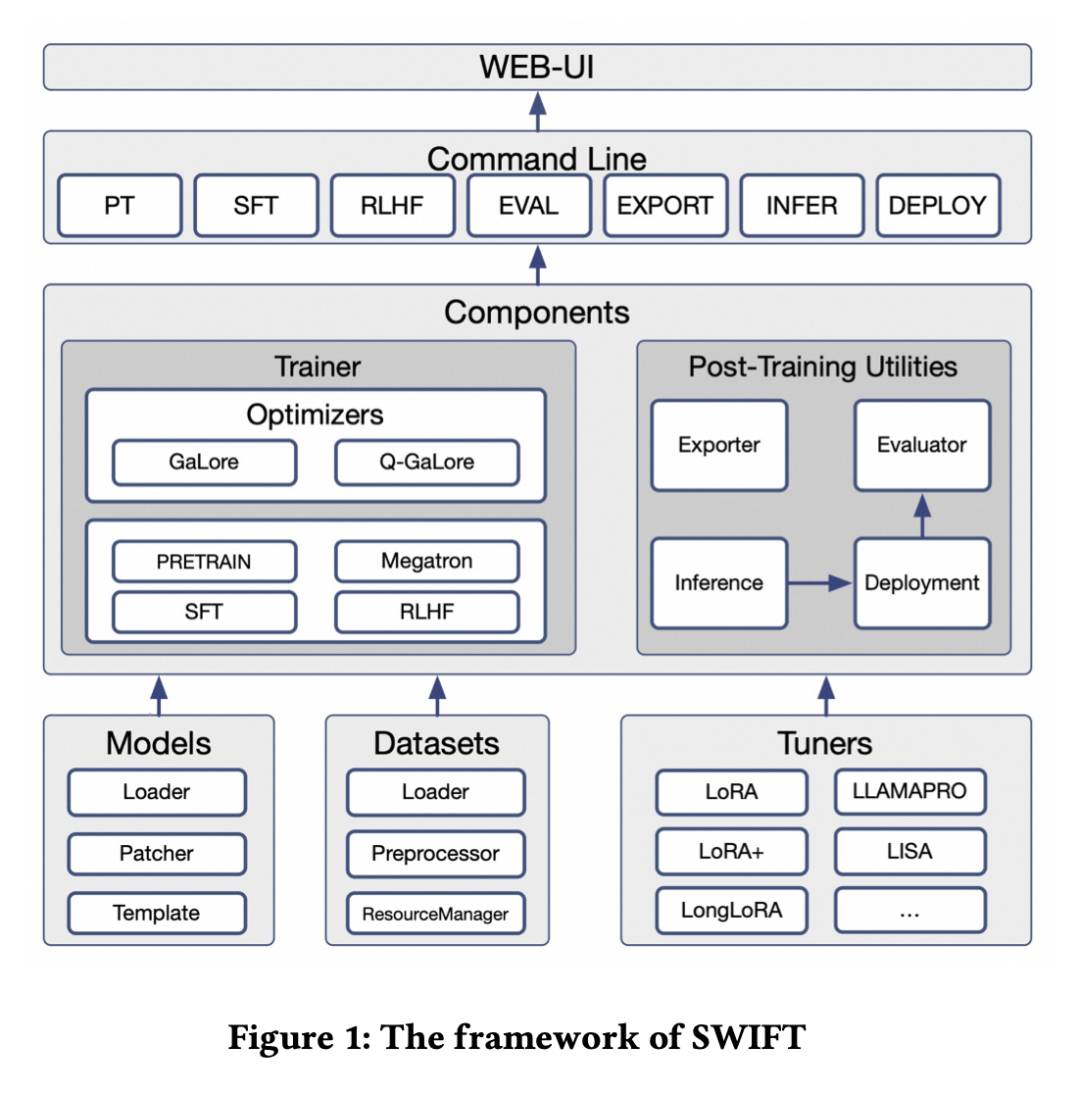 http://arxiv.org/abs/2408.05517v1
http://arxiv.org/abs/2408.05517v1
supersonic
SuperSonic融合Chat BI(powered by LLM)和Headless BI(powered by 语义层)打造新一代的BI平台。这种融合确保了Chat BI能够与传统BI一样访问统一化治理的语义数据模型。此外,两种BI新范式都从中获得收益:
-
Chat BI的Text2SQL生成通过检索语义数据模型得到增强。
-
Headless BI的查询接口通过支持自然语言API得到拓展。
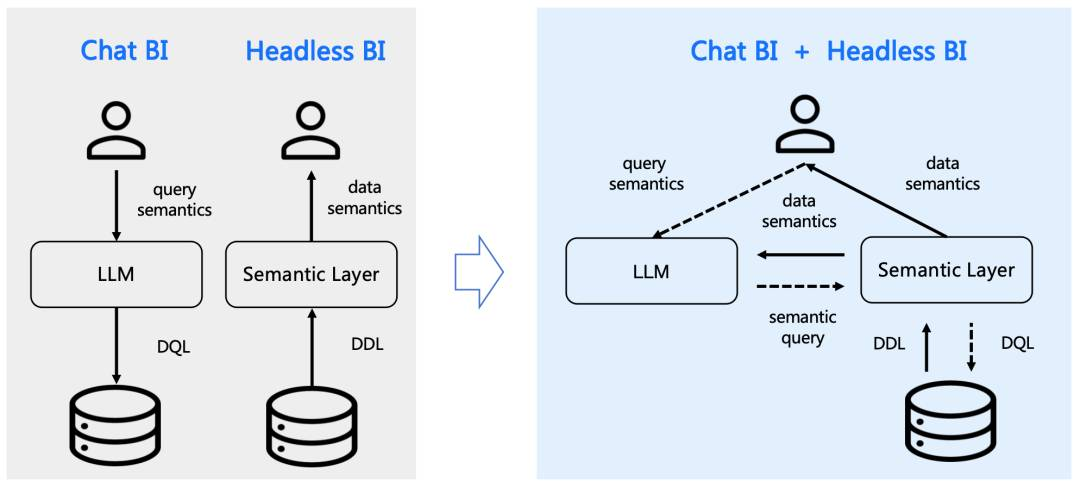 https://github.com/tencentmusic/supersonic
https://github.com/tencentmusic/supersonic
-
-
-
— END —
