
包阅导读总结
思维导图:
文章地址:https://mp.weixin.qq.com/s/es9Z1Gh1dtvDGE1UhmI9PQ
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/8/5 6:26
语言:中文
总字数:2804字
预计阅读时间:12分钟
评分:80分
标签:大模型,长文本生成,内存优化,Transformer,MST技术
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
https://arxiv.org/abs/2407.15892
贡献者:
Cheng Luo,Jiawei Zhao,Zhuoming Chen, Beidi Chen,Anima Anandkumar
-
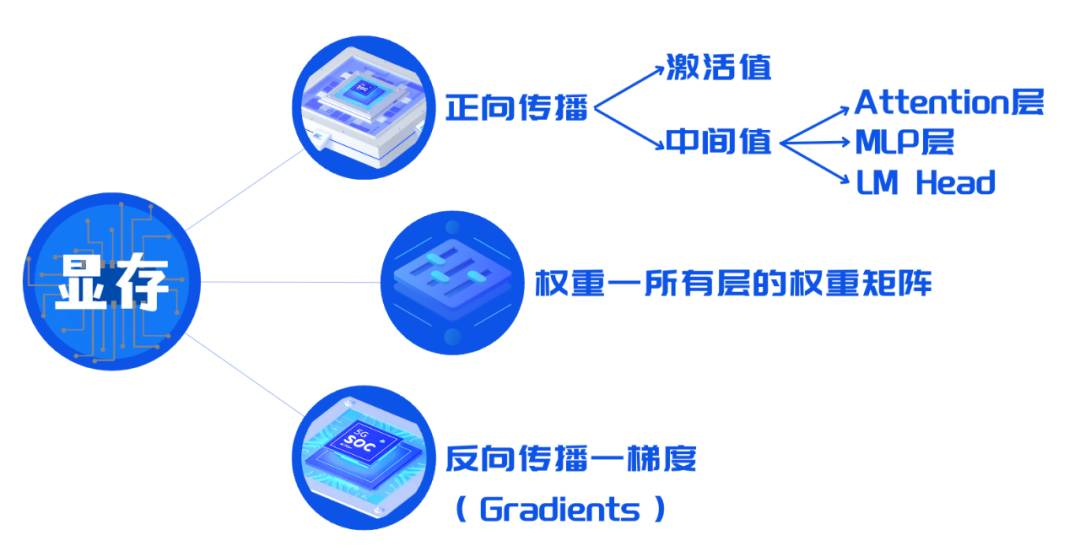
权重:模型的参数,包括所有层的权重矩阵,需要在训练前加载到显存中。 -
-
激活值(Activations):计算并存储每层的激活,这些值需要保存以便于在反向传播时计算梯度。
-
中间值(Intermediate Values)——计算时每一层时都需要储存:在模型的不同层,特别是多头自注意力(Multi-Head Attention)层和多层感知器(MLP)层中,计算过程中会产生中间值,如Q(Query)、K(Key)、V(Value)张量,以及MLP层的中间线性变换结果。
-
Transformer 中的Attention层,计算 QKV 和注意力矩阵; -
Transformer 中的MLP层,将序列嵌入维度放大再缩小; -
LM Head(Language Modeling Head)将嵌入映射为 logits,之后计算 loss / 下一个 token。
-
-
反向传播时需要计算并存储:梯度(Gradients)——在反向传播过程中计算得到的模型权重的梯度,用于更新模型参数,保持优化器的状态等等。
Innovation
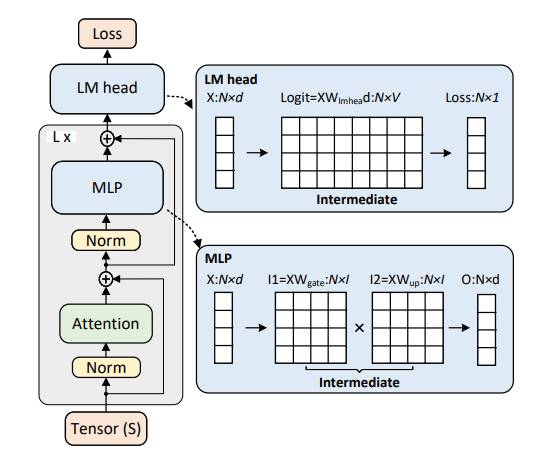
FlashAttention 其实就在使用这个技巧,因为 Attention 的中间状态太大了,随着序列长度二次方增长谁也受不了。随着 Attention 的中间状态被 FlashAttention 和 Ulysses 打下来,我们自然就盯上其他中间状态了。
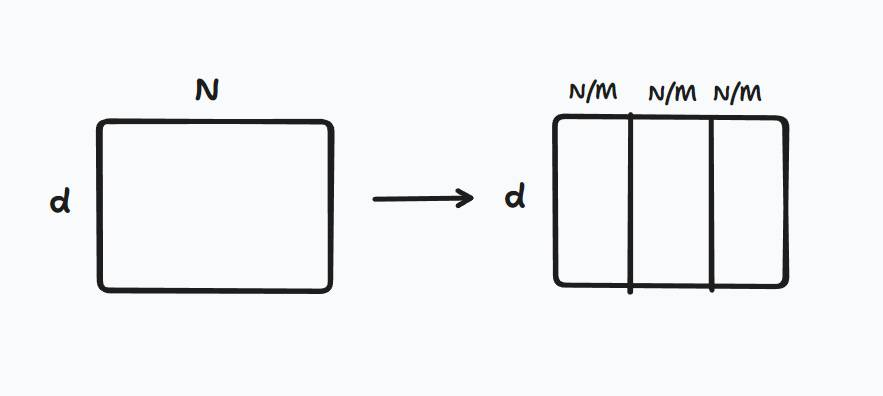
MLP层:Llama3 的 MLP 层有三个线性层 Wgate,Wup,Wdown。前向计算过程为:
• 首先将 N*d 大小的序列矩阵通过Wgate,Wup放大为两个N*l的矩阵
• 然后两个矩阵逐元素点乘,最后通过Wdown缩小为原来的 N*d 大小。
汇总的过程就很简单,直接在序列维度拼接就可以。
MST 没有改变 FLOP,但会增加 HBM 访问次数,标准 MLP 的访问次数为 Θ (Nd+NI+dI),而 MST 的访问次数为Θ (Nd+NI+dIM)。标准 LM Head 的次数是 Θ (Nd+NI+dV),而 MST 下这个数字是Θ (Nd+NI+dVM)。如果序列长度很短,中间状态占主导,dI,dV占主导,MST会降低GPU 显存的访问量。