我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
语言模型的物理学:部分2.1,小学数学和隐藏的推理过程
近期语言模型的进展展示了它们解决数学推理问题的能力,在GSM8K等小学级数学基准测试中几乎达到完美的准确率。本文正式研究了语言模型如何解决这些问题。我们设计了一系列控制实验来回答几个基本问题:(1)语言模型是否真正可以发展推理能力,还是仅仅记住模板?(2)模型的隐藏(思维)推理过程是什么?(3)模型是否使用与人类类似或不同的技能来解决数学问题?(4)在GSM8K等数据集上训练的模型是否发展了超出解决GSM8K问题所需的推理能力?(5)是什么心理过程导致模型犯推理错误?(6)一个模型必须有多大或多深才能有效解决GSM8K级别的数学问题? 我们的研究揭示了语言模型解决数学问题的许多隐含机制,提供了超出当前对LLM的理解范围的见解。
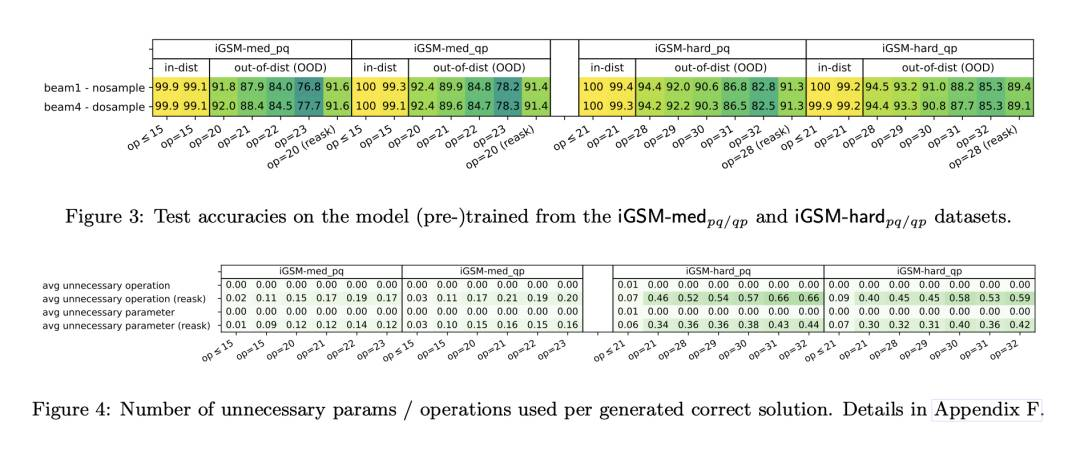 http://arxiv.org/abs/2407.20311v1
http://arxiv.org/abs/2407.20311v1
扩散增强智能体:高效探索与迁移学习框架
我们介绍了Diffusion Augmented Agents(DAAG),这是一个新颖的框架,利用大型语言模型、视觉语言模型和扩散模型来提高在具身智能体强化学习中的样本效率和迁移学习。DAAG通过使用扩散模型将视频进行转换,以一种时间上和几何上一致的方式重新标记智能体的过去经验,以符合目标指令,这项技术称为Hindsight Experience Augmentation。一个大型语言模型协调这个自主过程,无需人类监督,非常适合终身学习场景。该框架减少了需要标注奖励数据的量,以便1)微调作为奖励检测器的视觉语言模型,和2)在新任务上训练RL智能体。我们在涉及操纵和导航的模拟机器人环境中展示了DAAG的样本效率提升。我们的结果表明,DAAG改善了奖励检测器的学习,转移过去的经验和获取新任务的能力 – 这是开发高效终身学习智能体的关键能力。我们的网站上提供了补充材料和可视化内容。
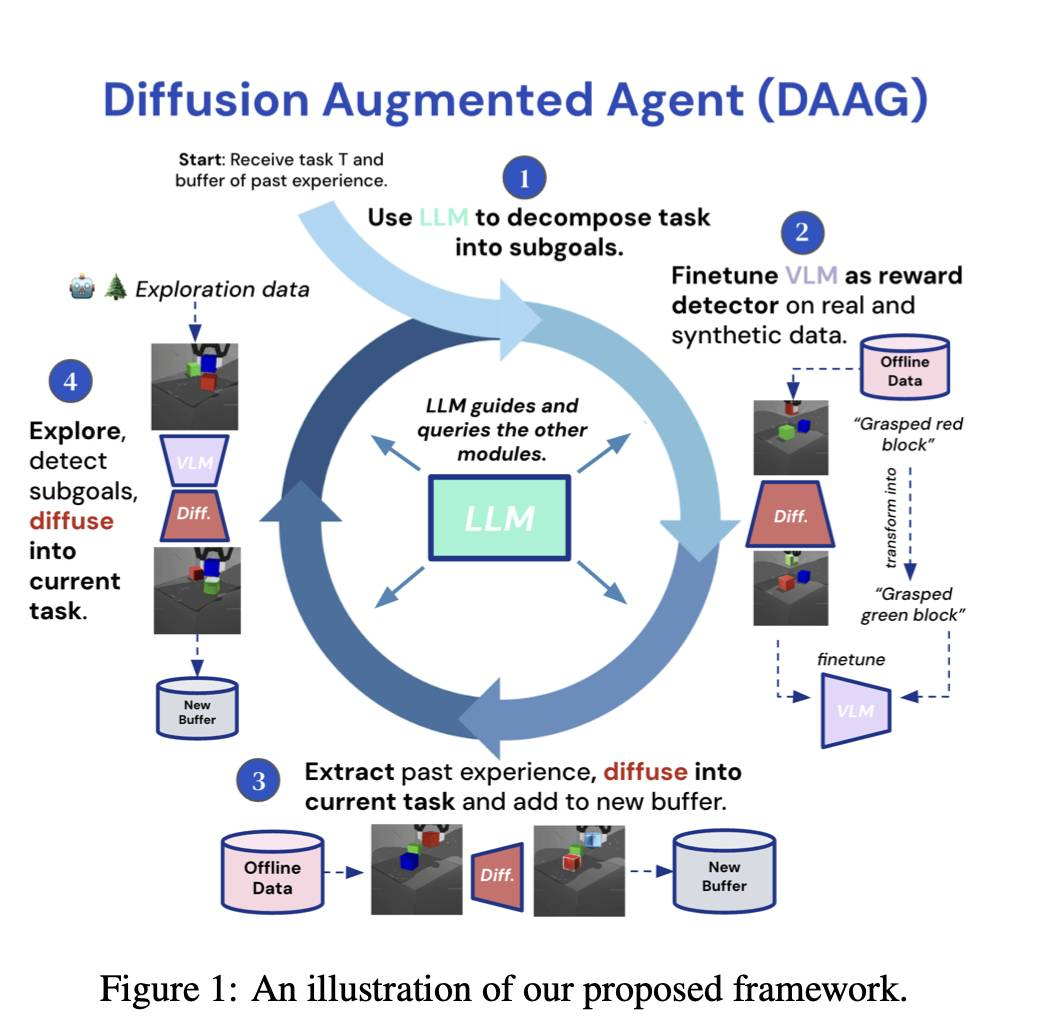 http://arxiv.org/abs/2407.20798v1
http://arxiv.org/abs/2407.20798v1
CLR-Fact: 评估LLMs在事实知识上的复杂逻辑推理能力
摘要:大语言模型(LLMs)已经展示了在各种自然语言处理任务中获取丰富事实知识的能力,但它们对于在复杂情况下综合和逻辑推理这些知识的能力尚未充分探索。本文通过一个新颖的基准测试,系统评估了最先进的LLMs在复杂逻辑推理能力上的表现,这个测试包括在通用领域和生物医学知识图上自动生成复杂推理问题。我们的广泛实验采用了多种上下文学习技术,发现LLMs在通用世界知识上具有出色的推理能力,但在专业领域特定知识方面面临重大挑战。我们发现,通过明确的“思维链”示范能明显提高LLMs在具有各种逻辑操作的复杂逻辑推理任务中的表现。有趣的是,我们控制性评估揭示了一个不对称,LLMs在集合并操作方面表现出色,但在集合交操作方面表现相当困难-这是逻辑推理的关键构建模块。为了促进更多工作,我们将公开释放我们的评估基准和代码。
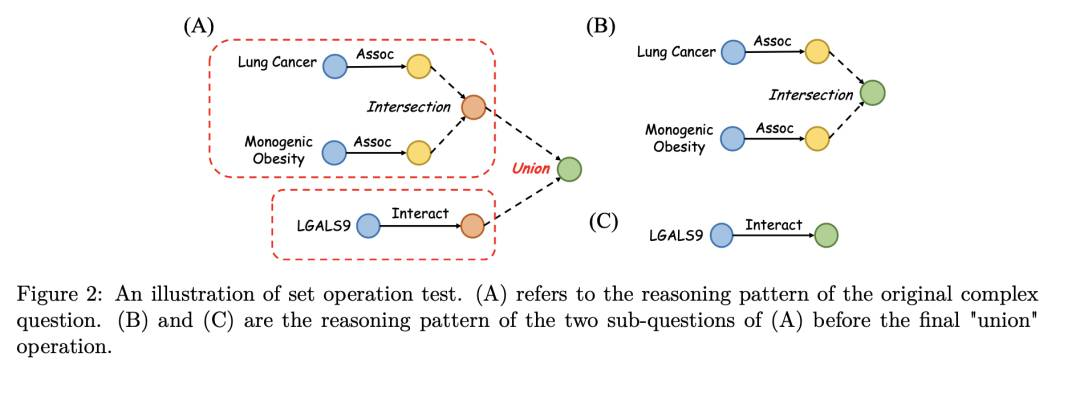 http://arxiv.org/abs/2407.20564v1
http://arxiv.org/abs/2407.20564v1
如何选择一种强化学习算法
摘要:强化学习领域提供了许多概念和方法来解决序贯决策问题。选择应用于特定任务的算法可能很具挑战性。本研究简化了选择强化学习算法和行动分布族的过程。我们提供了现有方法及其特性的结构化概述,并提供了何时选择哪种方法的准则。这些准则的互动版本可在线访问:https://rl-picker.github.io/。
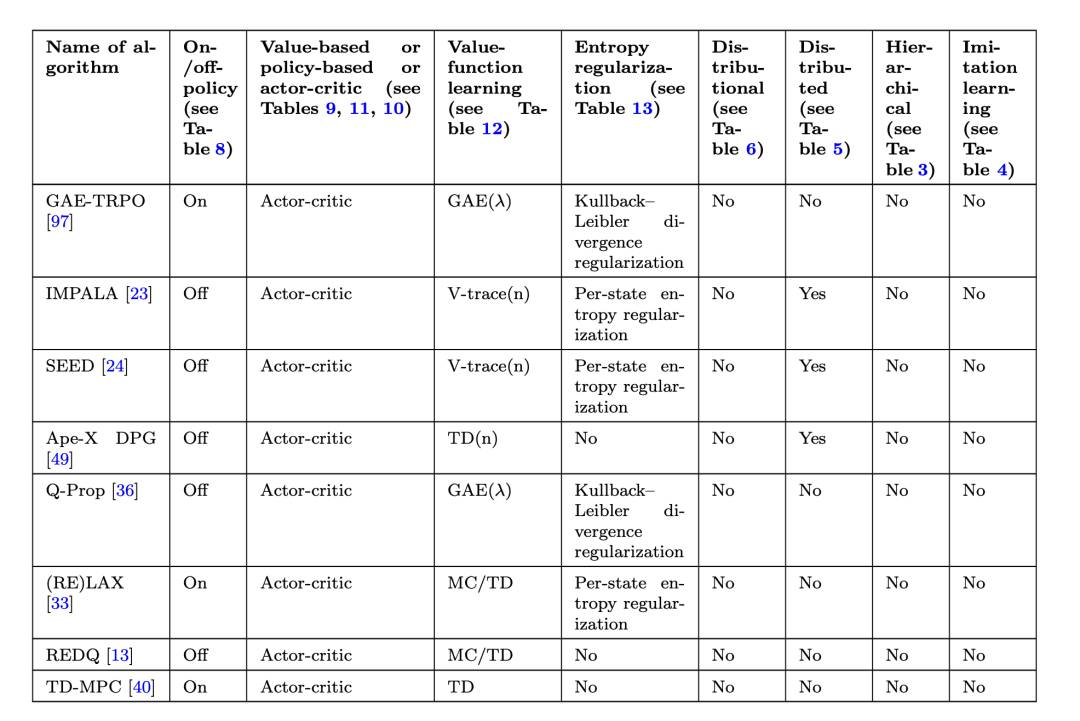 http://arxiv.org/abs/2407.20917v1
http://arxiv.org/abs/2407.20917v1
合成智能体:高效高质的视觉语言模型合成数据
最近,随着网络图像的崛起,管理和理解大规模图像数据集变得越来越重要。由于其强大的图像理解能力,视觉大语言模型(VLLMs)近年来涌现出来。然而,训练这些模型需要大量数据,对效率、有效性、数据质量和隐私提出挑战。在本文中,我们介绍了SynthVLM,一种新颖的用于VLLMs的数据合成管道。与现有方法从图像生成标题不同,SynthVLM采用先进的扩散模型和高质量的标题,自动生成并选择高分辨率图像,从而创建准确对齐的图像-文本对。利用这些对齐的对,我们在各种视觉问题回答任务中实现了最先进的性能,保持高对齐质量并保留先进的语言能力。此外,SynthVLM在性能上超越了传统的基于GPT-4 Vision的标题生成方法,同时显著减少了计算开销。至关重要的是,我们的方法完全依赖于生成的数据,确保隐私得以保护,仅使用10万数据点就实现了最先进的性能(仅为官方数据集大小的18%)。
 http://arxiv.org/abs/2407.20756v1
http://arxiv.org/abs/2407.20756v1
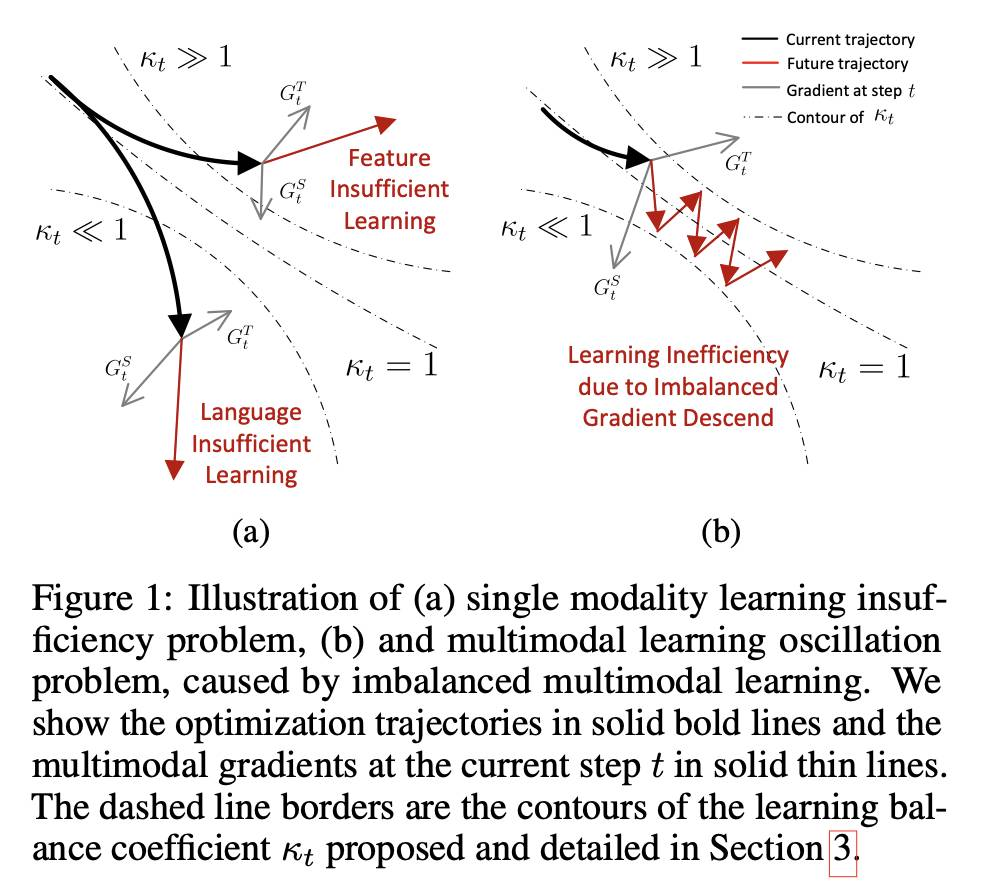
CoMMIT:用于多模态大语言模型的协调指令微调
摘要:在多模态大语言模型(MLLMs)中进行指导调整旨在将骨干LLM与预训练的特征编码器平滑地整合到下游任务中。主要挑战是如何通过合作学习有效地找到协同效应,其中LLMs在下游任务中调整其推理能力,而特征编码器调整其编码以提供更相关的模态信息。我们从理论和实证的角度分析了MLLM指导调整,发现两个组件之间的学习不平衡,即特征编码器和LLM,可能会导致学习梯度减弱,减缓模型收敛,常常导致由于学习不足而产生次优结果。受到我们发现的启发,我们提出了一个测量方法来定量评估学习平衡,基于此进一步设计了一个动态学习调度程序,更好地协调学习。此外,我们引入了一个辅助损失正则化方法,促进更新MLLM的生成分布以考虑每个模型组件的学习状态,这可能防止每个组件梯度减弱,并实现对学习平衡系数的更准确估计。我们在多个LLM骨干和特征编码器上进行实验,我们的技术不依赖于具体模型,并可以与各种MLLM骨干通用集成。在多个视觉和音频模态的多个下游任务上的实验结果表明,所提出的方法在MLLM指导调整中具有更好的效率和有效性。
 http://arxiv.org/abs/2407.20454v1
http://arxiv.org/abs/2407.20454v1
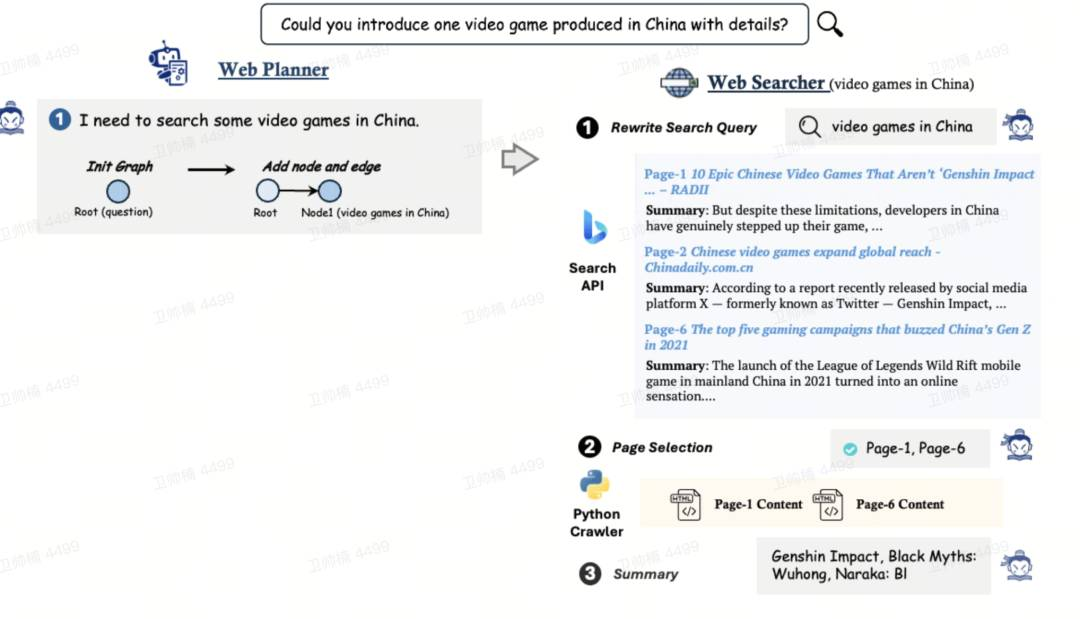
MindSearch
MindSearch 是一个开源的 AI 搜索引擎框架,具有与 Perplexity.ai Pro 相当的性能。它可以使用自己的 Perplexity.ai 风格的搜索引擎轻松部署,支持使用闭源 LLMs (GPT, Claude) 或开源 LLMs (InternLM2.5-7b-chat)。
 https://github.com/InternLM/MindSearch
https://github.com/InternLM/MindSearch
ktransformers
KTransformers 是一个灵活的 Python 框架,通过先进的内核优化和部署/并行策略来增强 Transformers 的体验。它提供了一个易于扩展的平台,用于试验创新的大语言模型推理优化。
 https://github.com/kvcache-ai/ktransformers
https://github.com/kvcache-ai/ktransformers
-
-
-
— END —
