包阅导读总结
思维导图:![]()
文章地址:https://mp.weixin.qq.com/s/k7ZWPYEkrSCshYDhjhMJkQ
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/8/4 13:49
语言:中文
总字数:2171字
预计阅读时间:9分钟
评分:80分
标签:大模型,AI 研究,技术改进,模型优化,性能提升
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
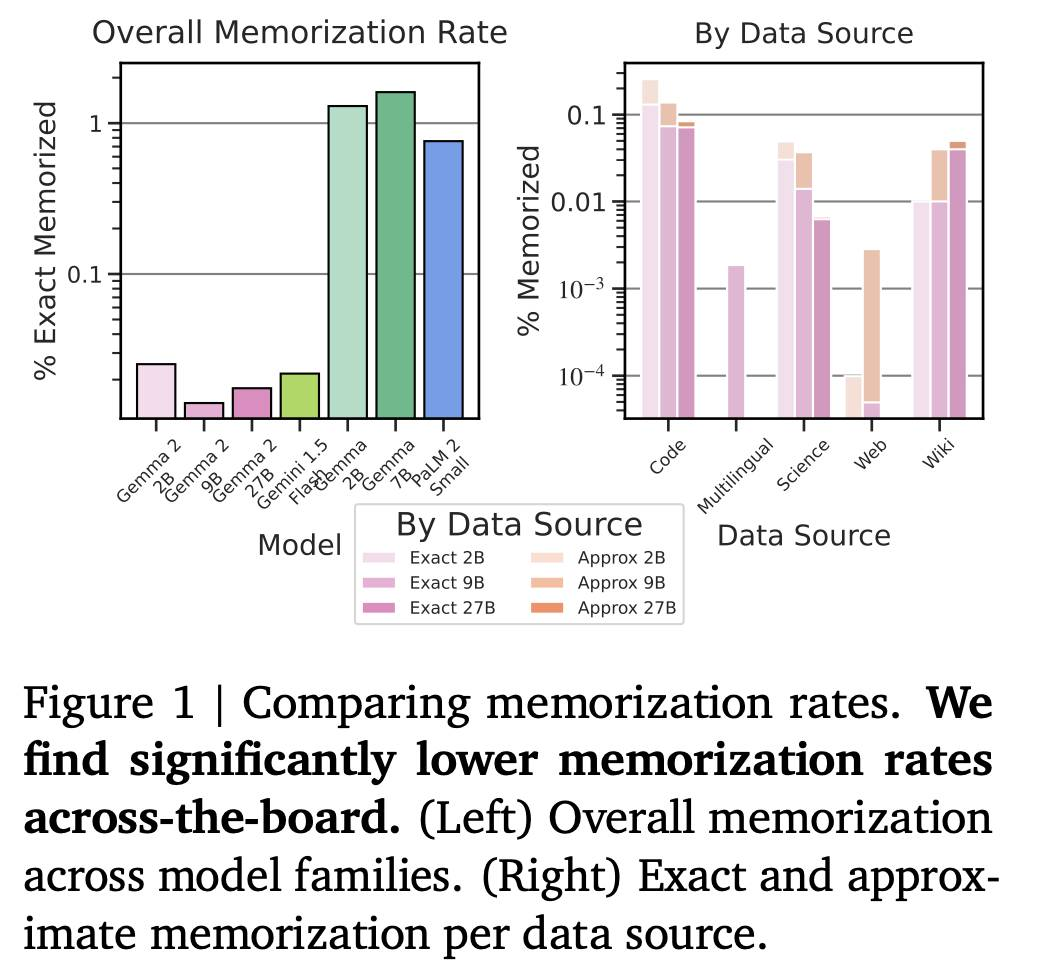
Gemma 2:在实用大小上改进开放语言模型
在这项工作中,我们介绍了 Gemma 家族的新成员 Gemma 2,它是一种轻量级的最先进的开放模型,参数规模从 20 亿到 270 亿不等。在这个新版本中,我们对 Transformer 架构应用了几种已知的技术修改,比如交错局部-全局注意力和组查询注意力。我们还使用了知识蒸馏来训练 20 亿和 90 亿模型,而不是下一个 token 预测。由此产生的模型在其大小方面提供了最佳性能,并且甚至提供了与两到三倍大小的模型竞争性的选择。我们把所有模型发布给社区。
 http://arxiv.org/abs/2408.00118v1
http://arxiv.org/abs/2408.00118v1
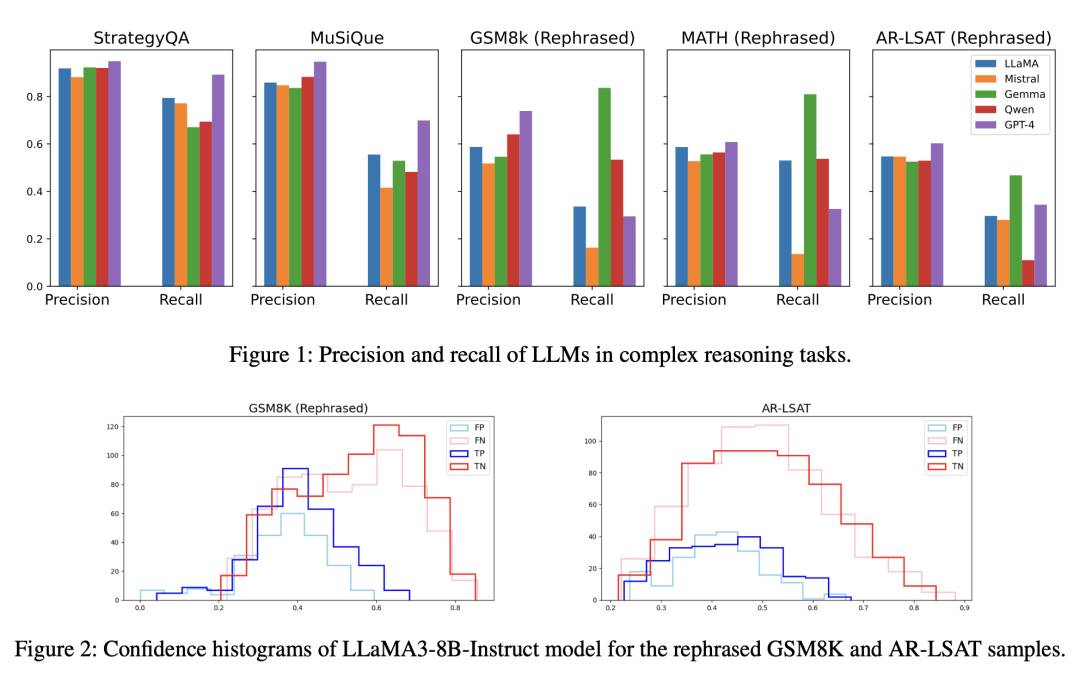
纠正大语言模型中的负偏见通过负注意力分数对齐
摘要:在二元决策任务中,如是非问题或答案验证,反映了用户在特定问题上寻求确定性的情况。我们观察到语言模型在复杂推理任务的二元决策中呈现负面偏倚。基于此,我们提出了负注意力分数(NAS)来系统地量化负偏倚。在NAS的基础上,我们确定了关注负面令牌的注意力头,验证了它们与负偏倚的关联。此外,我们提出了负注意力分数对齐(NASA)方法,这是一种参数高效的微调技术,用于处理提取的具有负偏倚的注意力头。实验结果表明,NASA显著减少了负偏倚引起的精度和召回之间的差距,同时保持了它们的泛化能力。我们的代码可在\url{https://github.com/ysw1021/NASA}上找到。
 http://arxiv.org/abs/2408.00137v1
http://arxiv.org/abs/2408.00137v1
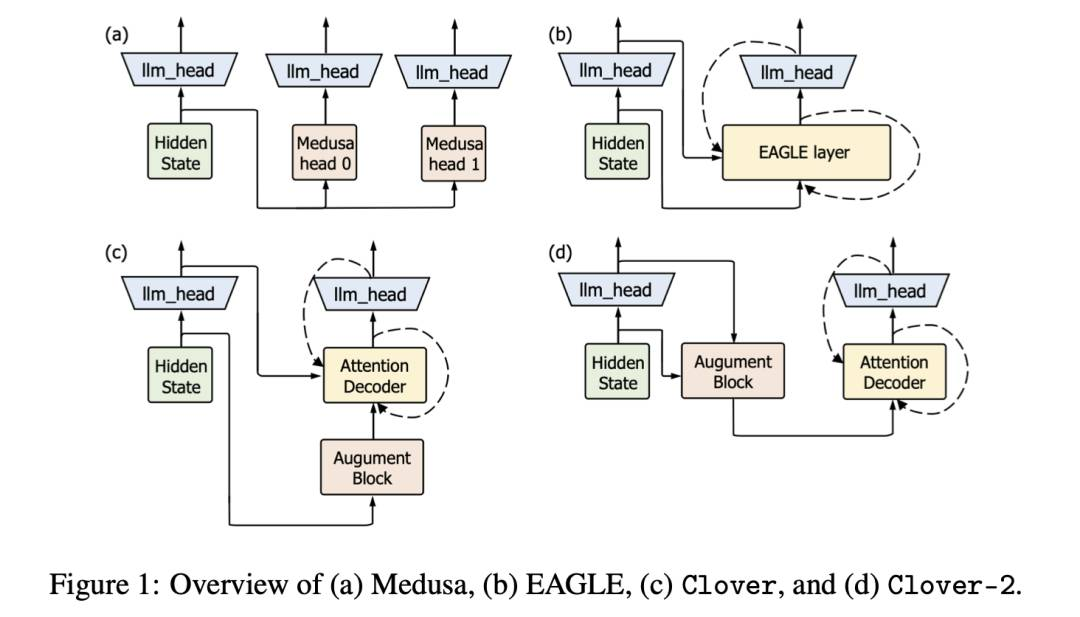
Clover-2: 精准推断用于轻量级规范解码
大型语言模型(LLMs)经常因自回归解码的要求与当代GPU架构之间的不一致而效率低下。最近,逆向轻量级推测解码因其在文本生成任务中显著提高效率而受到关注。本文提出Clover-2,Clover的高级版本,一个基于RNN的草稿模型,旨在实现与注意力解码器层模型相当的精度,同时保持最低的计算开销。Clover-2增强了模型架构,并结合了知识蒸馏来提高精度并改进整体效率。我们使用开源Vicuna 7B和LLaMA3-Instruct 8B模型进行实验,结果表明Clover-2在各种模型架构上超越了现有方法,展示了其有效性和稳健性。
 http://arxiv.org/abs/2408.00264v1
http://arxiv.org/abs/2408.00264v1
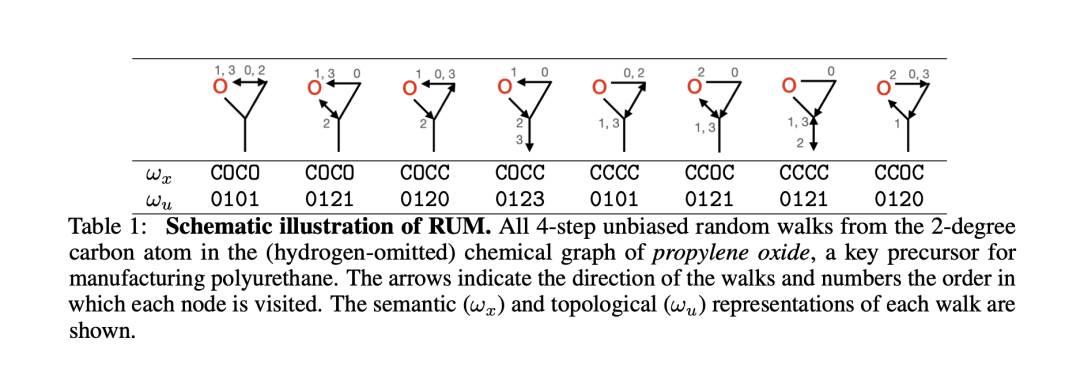
非卷积图神经网络
重新思考基于卷积的图神经网络(GNN)-它们在表达能力上受限、过度平滑和过度压缩,需要专门的稀疏内核来进行高效计算。在这里,我们设计了一个简单的图学习模块,完全不包含卷积算子,被称为\textit{带有统一内存的随机游走}(RUM)神经网络,其中一个RNN合并了随机游走终止于每个节点的拓扑和语义图特征。通过关联RNN行为和图拓扑的丰富文献,我们理论上表明并在实验中验证了RUM减弱了上述症状,并且比Weisfeiler-Lehman(WL)同构性测试更具表现力。在各种节点和图层分类和回归任务中,RUM不仅取得了竞争性表现,而且具有鲁棒性、内存效率、可扩展性,并且比最简单的卷积GNN更快。
 http://arxiv.org/abs/2408.00165v1
http://arxiv.org/abs/2408.00165v1
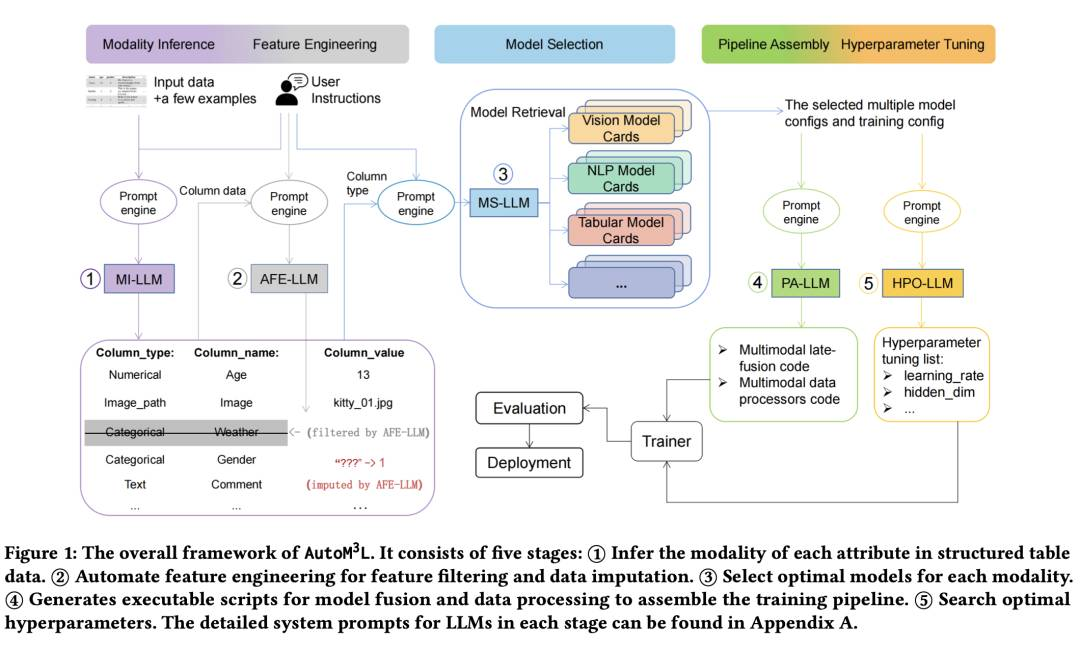
自动M3L:具有大型语言模型的自动多模式机器学习框架
自动机器学习(AutoML)提供了简化机器学习模型训练的可行途径。然而,现有的AutoML框架往往局限于单模态场景,并需要大量手动配置。最近大型语言模型(LLMs)的进展展示了它们在推理、互动和代码生成方面的出色能力,为开发更自动化和用户友好的框架提供了机会。为此,我们介绍了AutoM3L,这是一个创新的自动多模态机器学习框架,利用LLMs作为控制器自动构建多模态训练流程。AutoM3L理解数据模态,根据用户需求选择适当的模型,提供自动化和交互性。通过消除手动特征工程和超参数优化的需求,我们的框架简化了用户参与,并通过指令实现了定制化,解决了之前基于规则的AutoML方法的局限性。我们在涵盖分类、回归、检索任务的六个不同多模态数据集以及一套全面的单模态数据集上评估了AutoM3L的性能。结果表明,与传统基于规则的AutoML方法相比,AutoM3L实现了竞争性或优越的性能。此外,用户研究突显了我们框架的用户友好性和可用性,与基于规则的AutoML方法相比。
 http://arxiv.org/abs/2408.00665v1
http://arxiv.org/abs/2408.00665v1
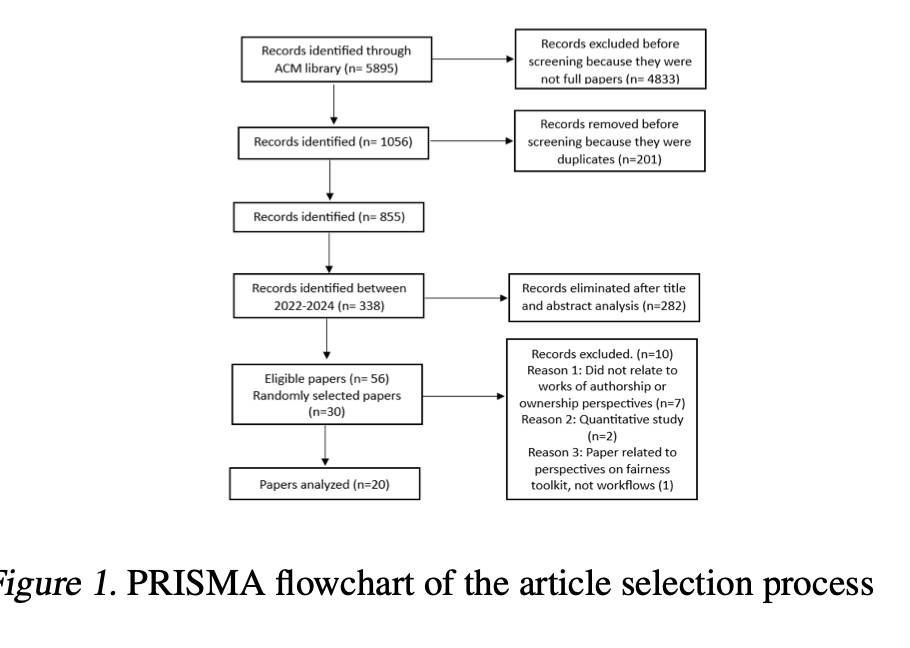
在生成AI供应链中解锁公平使用:系统化文献综述
本文通过系统化生成式人工智能(GenAI)利益相关者的目标和期望,试图揭示不同利益相关者在其对GenAI供应链的贡献中看到的价值。这种评估使我们能够了解GenAI公司倡导的公平使用是否推进了版权法促进科学和艺术的目标。在评估公平使用论点的有效性和效力的同时,我们发现了研究空白和未来研究和政策制定者可以解决的潜在途径。
 http://arxiv.org/abs/2408.00613v1
http://arxiv.org/abs/2408.00613v1
Tora
Tora 是一个基于 DiT 的视频生成框架,能够同时利用文本、视觉和轨迹条件生成高质量的视频内容。它由轨迹提取器、时空扩散变换器和运动引导融合器组成,可以精确控制视频内容的动态特性,如持续时间、宽高比和分辨率。
 https://github.com/ali-videoai/Tora
https://github.com/ali-videoai/Tora
Torchchat
torchchat 是一个小型代码库,展示了运行大型语言模型(LLM)的能力。使用 torchchat,可以使用 Python、自己的(C/C++)应用程序(桌面或服务器)以及 iOS 和 Android 运行 LLM。
https://github.com/pytorch/torchchat
-
-
-
— END —
