
包阅导读总结
1. 关键词:metahuman-stream、开源、数字人、实时交互、流式
2. 总结:metahuman-stream 是开源的实时交互流式数字人项目,实现音视频同步对话,达商用效果。介绍了特色功能、安装指南、使用方法、性能分析及待办事项等。涵盖模型选择、传输模式、视频编排等,还提及 Docker 运行等内容。
3. 主要内容:
– 项目介绍:
– metahuman-stream 是开源实时交互流式数字人项目,音视频同步对话达商用效果。
– 特色功能:
– 支持多种数字人模型。
– 支持声音克隆等多种功能。
– 支持多种传输模式和视频编排。
– 安装指南:
– 需在特定环境上安装依赖。
– 安装常见问题及 CUDA 环境搭建可参考相关链接。
– 快速开始:
– 采用默认模型,通过 WebRTC 推流到 SRS。
– 运行 SRS 并启动数字人,注意端口开放。
– 更多用法:
– 数字人模型选择及配置。
– 传输模式选择及配置。
– TTS 模型选择及服务部署。
– 视频编排方法。
– 使用 LLM 模型进行数字人对话。
– 更多功能集成。
– Docker 运行:
– 无需前面安装,直接运行,代码位置及操作步骤。
– 数字人模型文件:
– 可替换成自己训练的模型。
– 性能分析:
– 测试帧率及延时情况。
– 提出优化方向。
– 待办事项:
– 添加 ChatGPT 实现数字人对话等。
思维导图: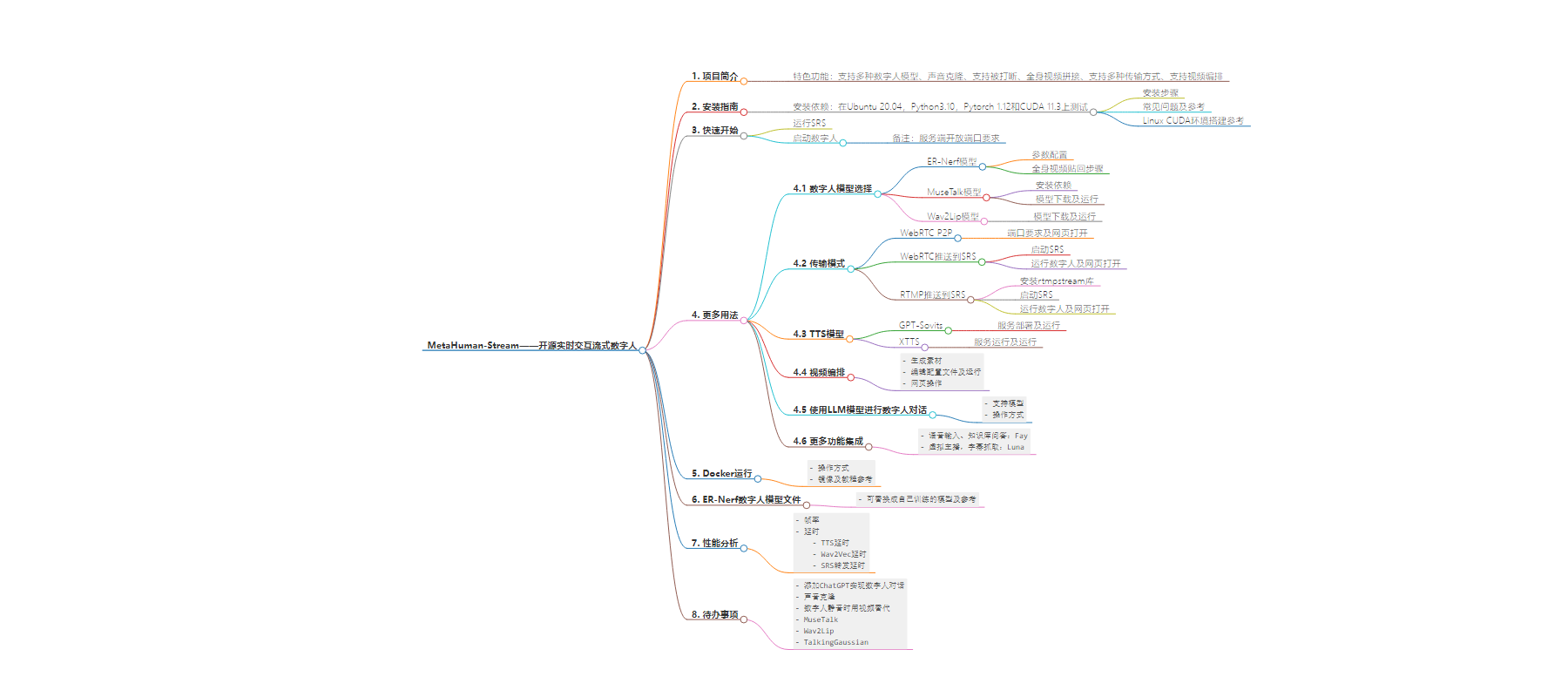
文章地址:https://mp.weixin.qq.com/s/GecCyL-uH-Sh6RodR9rlsw
文章来源:mp.weixin.qq.com
作者:山行AI
发布时间:2024/8/12 10:52
语言:中文
总字数:2455字
预计阅读时间:10分钟
评分:91分
标签:数字人技术,实时交互,开源项目,音视频处理,模型选择
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
前言
metahuman-stream是一款开源的实时交互流式数字人项目,实时交互流式数字人技术实现了音视频同步对话,并基本达到了商用效果。以下是对该技术的功能、安装指南、使用方法及性能分析的整理。通过本文,你除了可以收获开源的数字人处理技术外,还能收获到常见的音视频处理如声音克隆、视频编排等开源技术。
特色功能
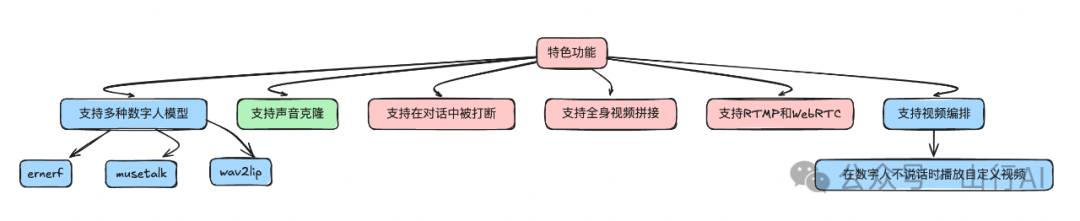
•支持多种数字人模型:ernerf、musetalk、wav2lip。•支持声音克隆。•支持在对话中被打断。•支持全身视频拼接。•支持RTMP和WebRTC。•支持视频编排:在数字人不说话时播放自定义视频。
1. 安装指南
1.1 安装依赖
在Ubuntu 20.04,Python3.10,Pytorch 1.12和CUDA 11.3上测试。
conda create -n nerfstream python=3.10conda activate nerfstreamconda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorchpip install -r requirements.txt# 如果只用musetalk或者wav2lip模型,不需要安装下面的库pip install "git+https://github.com/facebookresearch/pytorch3d.git"pip install tensorflow-gpu==2.8.0pip install --upgrade "protobuf<=3.20.1"
安装常见问题可以参考FAQ[1]。Linux CUDA环境搭建可以参考这篇文章:链接[2]。
2. 快速开始
默认采用ernerf模型,通过WebRTC推流到SRS。
2.1 运行SRS
export CANDIDATE='<服务器外网IP>'docker run --rm --env CANDIDATE=$CANDIDATE \-p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp \registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 \objs/srs -c conf/rtc.conf
2.2 启动数字人
如果无法访问Huggingface,在运行前执行:
export HF_ENDPOINT=https://hf-mirror.com用浏览器打开http://serverip:8010/rtcpushapi.html,在文本框输入任意文字并提交,数字人将播报该段文字。
备注:服务端需要开放端口TCP:8000,8010,1985;UDP:8000。
3. 更多用法
3.1 数字人模型选择
支持3种模型:ernerf、musetalk、wav2lip,默认使用ernerf。
3.1.1 ER-Nerf模型
python app.py --model ernerf可以使用以下参数进行配置:
•音频特征用Hubert:
python app.py --asr_model facebook/hubert-large-ls960-ft•设置头部背景图片:
python app.py --bg_img bc.jpg•全身视频贴回:
1.切割训练用的视频:
ffmpeg -i fullbody.mp4 -vf crop="400:400:100:5" train.mp4
2.提取全身图片:
ffmpeg -i fullbody.mp4 -vf fps=25 -qmin 1 -q:v 1 -start_number 0 data/fullbody/img/%d.jpg3.启动数字人:
python app.py --fullbody --fullbody_img data/fullbody/img --fullbody_offset_x 100 --fullbody_offset_y 5 --fullbody_width 580 --fullbody_height 1080 --W 400 --H 4003.1.2 MuseTalk模型
不支持RTMP推送。
•安装依赖:
conda install ffmpegpip install --no-cache-dir -U openmimmim install mmenginemim install "mmcv>=2.0.1"mim install "mmdet>=3.1.0"mim install "mmpose>=1.1.0"
•下载MuseTalk所需模型,参考链接[3](提取码:qdg2)和数字人模型,参考链接[4](提取码:3mkt),并将文件拷贝到指定目录。•运行:
python app.py --model musetalk --transport webrtc浏览器打开http://serverip:8010/webrtcapi.html。
3.1.3 Wav2Lip模型
不支持RTMP推送。
•下载模型,参考百度网盘[5](密码:ltua)。•运行:
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip_avatar1浏览器打开http://serverip:8010/webrtcapi.html。
3.2 传输模式
支持WebRTC、RTCPush、RTMP,默认使用RTCPush。
3.2.1 WebRTC P2P
无需SRS。
python app.py --transport webrtc服务器需开放端口TCP:8010;UDP:50000~60000。
浏览器打开http://serverip:8010/webrtcapi.html。
3.2.2 WebRTC推送到SRS
•启动SRS:
export CANDIDATE='<服务器外网IP>'docker run --rm --env CANDIDATE=$CANDIDATE \-p 1935:1935 -p 8080:8080 -p 1985:1985 -p 8000:8000/udp \registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5 \objs/srs -c conf/rtc.conf
•运行数字人:
python app.py --transport rtcpush --push_url 'http://localhost:1985/rtc/v1/whip/?app=live&stream=livestream'浏览器打开http://serverip:8010/rtcpushapi.html。
3.2.3 RTMP推送到SRS
•安装rtmpstream库,参考GitHub[6]。•启动SRS:
docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8080:8080 registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5•运行数字人:
python app.py --transport rtmp --push_url 'rtmp://localhost/live/livestream'浏览器打开http://serverip:8010/echoapi.html。
3.3 TTS模型
支持edgetts、gpt-sovits、xtts,默认使用edgetts。
3.3.1 GPT-Sovits
服务部署参考gpt-sovits[7]。
python app.py --tts gpt-sovits --TTS_SERVER http://127.0.0.1:9880 --REF_FILE data/ref.wav --REF_TEXT xxx3.3.2 XTTS
运行XTTS服务,参考GitHub[8]。
docker run --gpus=all -e COQUI_TOS_AGREED=1 --rm -p 9000:80 ghcr.io/coqui-ai/xtts-streaming-server:latest然后运行:
python app.py --tts xtts --REF_FILE data/ref.wav --TTS_SERVER http://localhost:90003.4 视频编排
•生成素材:
ffmpeg -i xxx.mp4 -s 576x768 -vf fps=25 -qmin 1 -q:v 1 -start_number 0 data/customvideo/image/%08d.pngffmpeg -i xxx.mp4 -vn -acodec pcm_s16le -ac 1 -ar 16000 data/customvideo/audio.wav
•编辑data/custom_config.json,指定imgpath和audiopath,设置audiotype。•运行:
python app.py --transport webrtc --customvideo_config data/custom_config.json•打开http://:8010/webrtcapi-custom.html,填写custom_config.json中配置的audiotype,点击切换视频。
3.5 使用LLM模型进行数字人对话
支持ChatGPT、Qwen和GeminiPro。需在app.py中填入api_key。
浏览器打开http://serverip:8010/rtcpushchat.html。
3.6 更多功能集成
•语音输入、知识库问答:Fay[9]。•虚拟主播,字幕抓取:Luna[10]。
4. Docker运行
无需前面安装,直接运行:
docker run --gpus all -it --network=host --rm registry.cn-beijing.aliyuncs.com/codewithgpu2/lipku-metahuman-stream:vjo1Y6NJ3N代码位于/root/metahuman-stream,需先git pull更新代码,然后执行命令同第2、3步。
提供autodl镜像:CodeWithGPU[11],参考autodl教程[12]。
5. ER-Nerf数字人模型文件
可以替换成自己训练的模型,参考GitHub[13]。
6. 性能分析
1.帧率
在Tesla T4显卡上测试,整体fps约为18;去掉音视频编码推流后,帧率约为20;用4090显卡可达40+ fps。
优化:新开一个线程运行音视频编码推流。2.延时
整体延时约为3秒:
(1)TTS延时约1.7秒,当前使用edgetts,需将每句话转完后一次性输入,可通过改为流式输入优化。
(2)Wav2Vec延时约0.4秒,需缓存18帧音频进行计算。
(3)SRS转发延时,建议通过设置SRS服务器减少缓冲延时,具体配置参考链接[14]。
7. 待办事项
•添加ChatGPT实现数字人对话。•声音克隆。•数字人静音时用视频替代。•MuseTalk。•Wav2Lip。•TalkingGaussian。
本文由山行整理自https://github.com/lipku/metahuman-stream,如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
References
[1]FAQ:https://github.com/lipku/metahuman-stream/blob/main/assets/faq.md[2]链接:https://zhuanlan.zhihu.com/p/674972886[3]链接:https://caiyun.139.com/m/i?2eAjs2nXXnRgr[4]链接:https://caiyun.139.com/m/i?2eAjs8optksop[5]百度网盘:https://pan.baidu.com/s/1yOsQ06-RIDTJd3HFCw4wtA[6]GitHub:https://github.com/lipku/python_rtmpstream[7]gpt-sovits:https://github.com/lipku/metahuman-stream/blob/main/tts/README.md[8]GitHub:https://github.com/coqui-ai/xtts-streaming-server[9]Fay:https://github.com/xszyou/Fay[10]Luna:https://github.com/Ikaros-521/AI-Vtuber[11]CodeWithGPU:https://www.codewithgpu.com/i/lipku/metahuman-stream/base[12]autodl教程:https://github.com/lipku/metahuman-stream/blob/main/autodl/README.md[13]GitHub:https://github.com/Fictionarry/ER-NeRF[14]链接:https://ossrs.net/lts/zh-cn/docs/v5/doc/low-latency