
包阅导读总结
1. 关键词:苹果、开源 7B 模型、训练数据集、小模型、模型性能
2. 总结:苹果开源 7B 大模型及训练过程数据集,其效果与 Llama 3 8B 相当。研究团队提出新基准 DCLM 构建数据集,小模型成新趋势,因成本低,多家公司推出小模型,竞争激烈。
3.
– 苹果开源 7B 大模型
– 效果与 Llama 3 8B 相当,一次性开源全部训练过程和资源
– 数据管理对训练或微调模型重要
– 新基准 DCLM 与模型表现
– 提出新基准 DCLM 以构建高质量数据集提高模型性能
– DCLM-7B 在 MMLU 基准上表现出色,与 Mistral-7B、Llama 3 8B 相媲美
– 新数据集效果测试中 DCLM-Baseline 表现更好
– 小模型成新趋势
– HuggingFace 推出小模型家族“SmolLM”
– OpenAI 发布 GPT-4o mini,Mistral AI 联合英伟达发布 12B 参数小模型
– 小模型成本低,能力相近时更具优势
思维导图: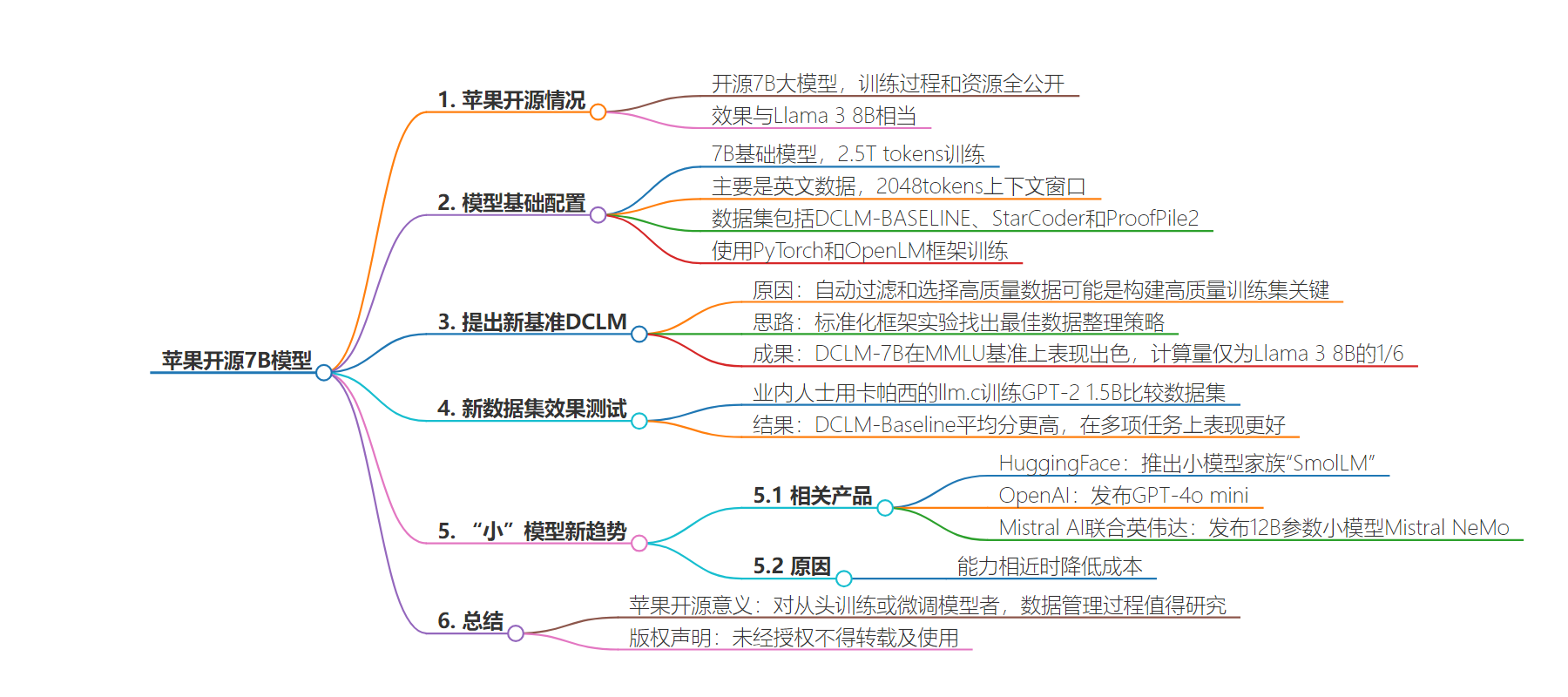
文章地址:https://www.qbitai.com/2024/07/169338.html
文章来源:qbitai.com
作者:一水
发布时间:2024/7/22 8:26
语言:中文
总字数:1536字
预计阅读时间:7分钟
评分:83分
标签:开源模型,大语言模型,数据集透明度,多模态领域,苹果公司
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
苹果开源7B大模型,训练过程数据集一口气全给了,网友:开放得不像苹果
 一水2024-07-2216:26:04 来源:量子位
一水2024-07-2216:26:04 来源:量子位 苹果最新杀入开源大模型战场,而且比其他公司更开放。
推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。
要知道,不久前Nature杂志编辑Elizabeth Gibney还撰文批评:
许多声称开源的AI模型,实际上在数据和训练方法上并不透明,无法满足真正的科学研究需求。
而苹果这次竟然来真的!!
就连NLP科学家、AutoAWQ创建者也发出惊叹:
Apple发布了一个击败Mistral 7B的模型,但更棒的是他们完全开源了所有内容,包括预训练数据集!
也引来网友在线调侃:
至于这次开源的意义,有热心网友也帮忙总结了:
对于任何想要从头开始训练模型或微调现有模型的人来说,数据管理过程是必须研究的。
当然,除了OpenAI和苹果,上周Mistral AI联合英伟达也发布了一个12B参数小模型。
HuggingFace创始人表示,「小模型周」来了!
卷!继续卷!所以苹果这次发布的小模型究竟有多能打?
效果直逼Llama 3 8B
有多能打先不说,先来看Hugging Face技术主管刚“拆箱”的模型基础配置。
总结下来就是:
- 7B基础模型,在开放数据集上使用2.5T tokens进行训练
- 主要是英文数据,拥有2048tokens上下文窗口
- 数据集包括DCLM-BASELINE、StarCoder和ProofPile2
- MMLU得分接近Llama 3 8B
- 使用PyTorch和OpenLM框架进行训练
具体而言,研究团队先是提出了一个语言模型数据比较新基准——DCLM。
之所以提出这一基准,是因为团队发现:
由机器学习 (ML) 模型从较大的数据集中自动过滤和选择高质量数据,可能是构建高质量训练集的关键。
因此,团队使用DCLM来设计高质量数据集从而提高模型性能,尤其是在多模态领域。
其思路很简单:使用一个标准化的框架来进行实验,包括固定的模型架构、训练代码、超参数和评估,最终找出哪种数据整理策略最适合训练出高性能的模型。
基于上述思路,团队构建了一个高质量数据集DCLM-BASELINE,并用它从头训练了一个7B参数模型——DCLM-7B。
DCLM-7B具体表现如何呢?
结果显示,它在MMLU基准上5-shot准确率达64%,可与Mistral-7B-v0.3(63%)和Llama 3 8B(66%)相媲美;并且在53个自然语言理解任务上的平均表现也可与Llama 3 8B相媲美,而所需计算量仅为后者的1/6。
与其他同等大小模型相比,DCLM-7B的MMLU得分超越Mistral-7B,接近Llama 3 8B。
最后,为了测试新数据集效果,有业内人士用卡帕西的llm.c训练了GPT-2 1.5B,来比较DCLM-Baseline与FineWeb-Edu这两个数据集。
结果显示DCLM-Baseline取得了更高的平均分,且在ARC(小学生科学问题推理)、HellaSwag(常识推理)、MMLU等任务上表现更好。
“小”模型成新趋势
回到开头,“小”模型最近已成新趋势。
先是HuggingFace推出了小模型家族“SmolLM”,其中包含135M、360M和1.7B型号模型。
它们在广泛的推理和常识基准上优于类似大小的模型。
然后OpenAI突然发布了GPT-4o mini,不仅能力接近GPT-4,而且价格大幅下降。
就在GPT-4o mini发布同日,Mistral AI联合英伟达发布了12B参数小模型——Mistral NeMo。
从整体性能上看,Mistral NeMo在多项基准测试中,击败了Gemma 2 9B和Llama 3 8B。
所以,为啥大家都开始卷小模型了?
原因嘛可能正如smol AI创始人提醒的,虽然模型变小了,但在能力相近的情况下,小模型大大降低了成本。
就像他提供的这张图,以GPT-4o mini为代表的小模型整体比右侧价格更低。
对此,我等吃瓜群众be like:
所以,你更看好哪家呢?
版权所有,未经授权不得以任何形式转载及使用,违者必究。