
包阅导读总结
1. 关键词:Mistral AI、GPT、预训练、Fine-tuning、Transformer
2. 总结:文本介绍了 Mistral AI 的情况,并重点阐述了 GPT 的相关内容,包括其含义、两阶段过程、与 ELMO 的不同,如特征抽取器和预训练所采用的模型。
3.
– Mistral AI
– 7B 数学推理专用
– Mamba2 架构代码大模型
– GPT
– 简称“Generative Pre-Training”,意为生成式预训练
– 采用两阶段过程
– 第一阶段利用语言模型预训练
– 第二阶段通过 Fine-tuning 解决下游任务
– 与 ELMO 的不同
– 特征抽取器用 Transformer 而非 RNN
– 预训练采用单向语言模型
思维导图: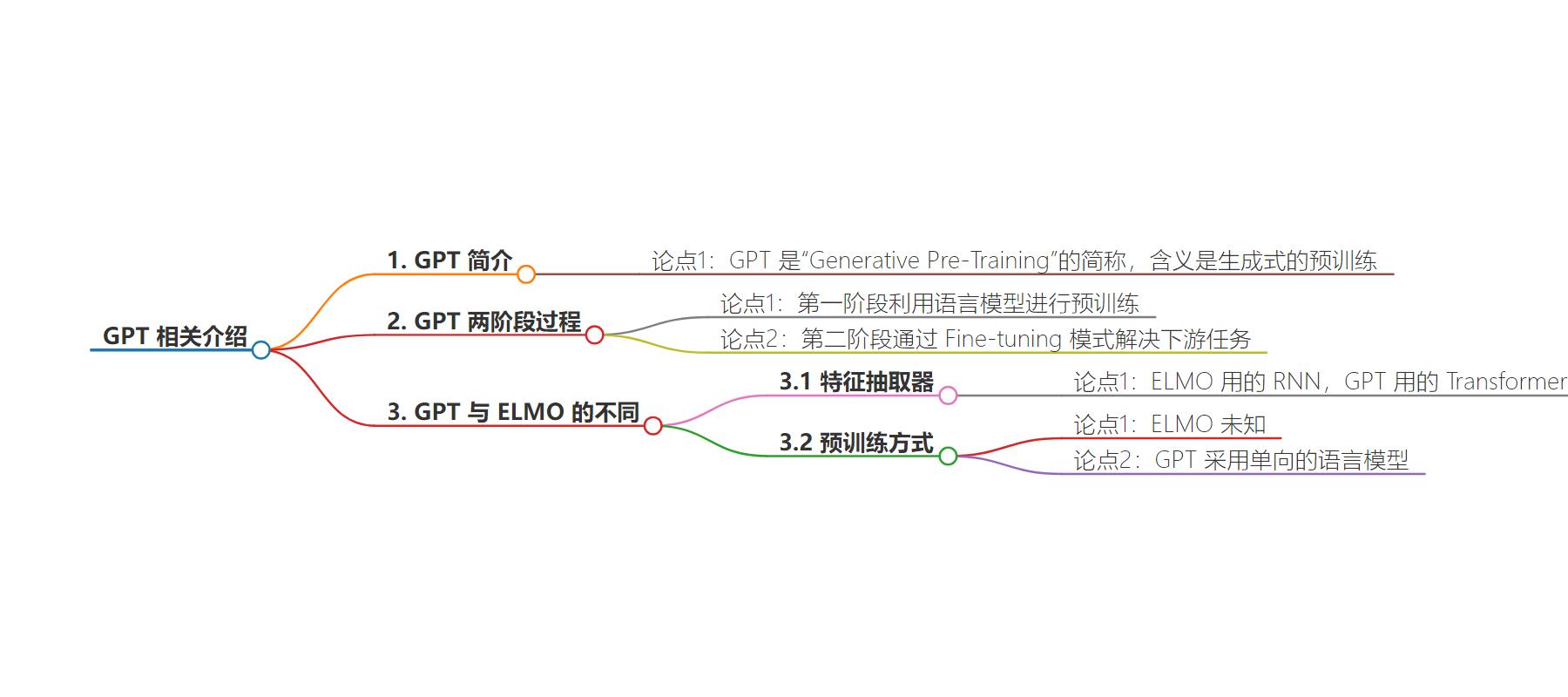
文章地址:https://www.jiqizhixin.com/articles/2024-07-17-3
文章来源:jiqizhixin.com
作者:机器之心
发布时间:2024/7/17 6:57
语言:中文
总字数:1193字
预计阅读时间:5分钟
评分:89分
标签:AI 模型,数学推理,代码生成,Mistral AI,Mamba2 架构
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
GPT 是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT 也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过 Fine-tuning 的模式解决下游任务。它与ELMO 主要不同在于两点:特征抽取器不是用的 RNN,而是用的 Transformer;GPT 的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型。