
包阅导读总结
1. 关键词:大模型、AI 学习社群、技术优化、推荐技术、新评测集
2. 总结:本文涵盖了大模型相关的多方面内容,包括搭建 AI 学习社群,RISC-V 向量指令模拟优化、推理引擎加速、搜索推荐技术探索、新评测集等,还介绍了一些新的工具和框架。
3. 主要内容:
– AI 学习社群:
– 希望搭建 AI 学习社群,共建更好社区生态,可订阅飞书接收《大模型日报》。
– 技术优化:
– 优化 NEMU 模拟器提升 RISC-V 向量指令模拟速度。
– MInference 1.0 实现单卡 Million-context 推理 10 倍加速。
– 京东广告对稀疏大模型训练与推理的 GPU 优化实践。
– 搜索推荐技术:
– 阿里巴巴专家分享搜索推荐技术进展及大模型应用。
– 新工具和框架:
– Flash Attention 注意力机制及 CUDA 实现。
– FPX-NIC 用于硬件编码的 FPGA 加速框架。
– 新评测集 LiveBench 和 CoverBench。
– GPTMe 基于命令行的 LLM 助手。
– Merlinn 开源的 AI 驱动工程师。
思维导图: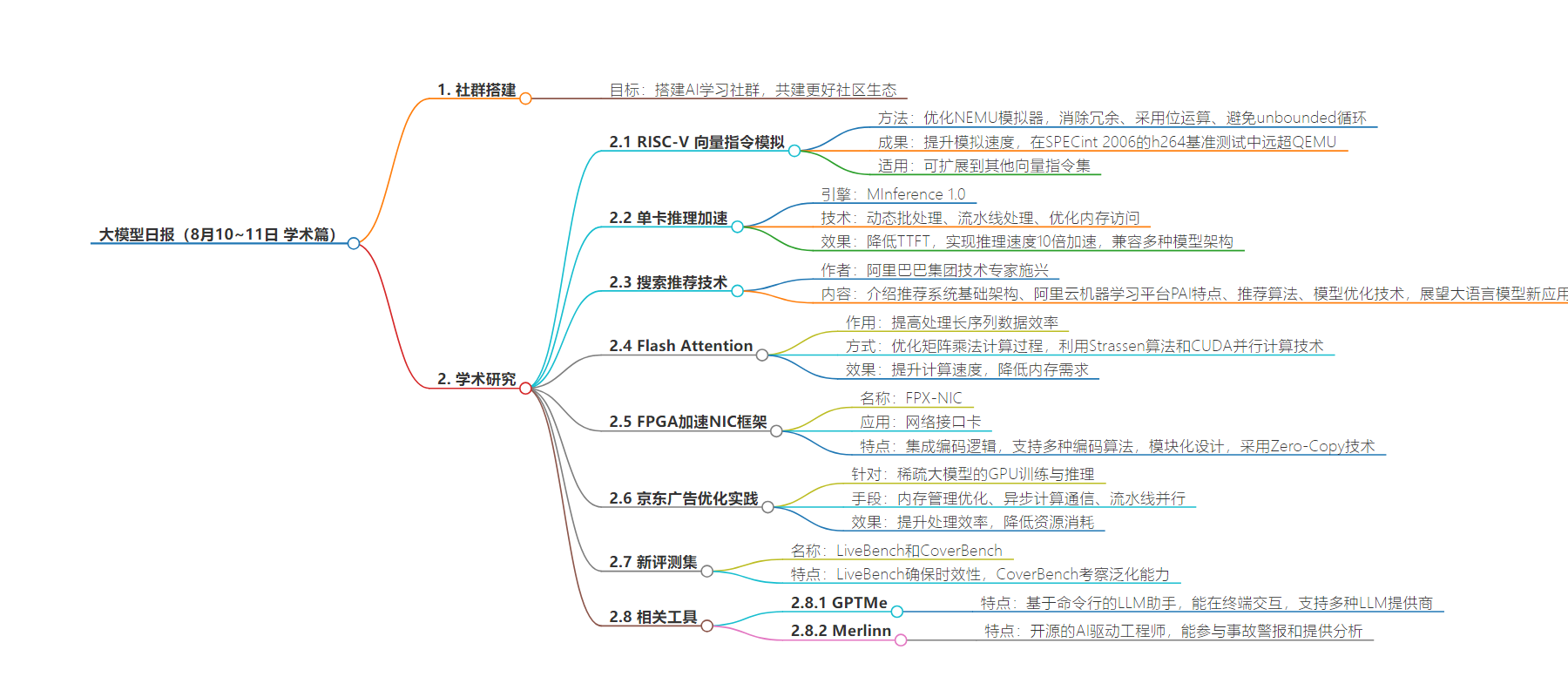
文章地址:https://mp.weixin.qq.com/s/uKXedzggFDIPeR0phal3KQ
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/8/11 14:41
语言:中文
总字数:2066字
预计阅读时间:9分钟
评分:89分
标签:大模型,AI技术,硬件加速,推荐系统,深度学习
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

学习
以向量化的方式进行 RISC-V 向量指令模拟
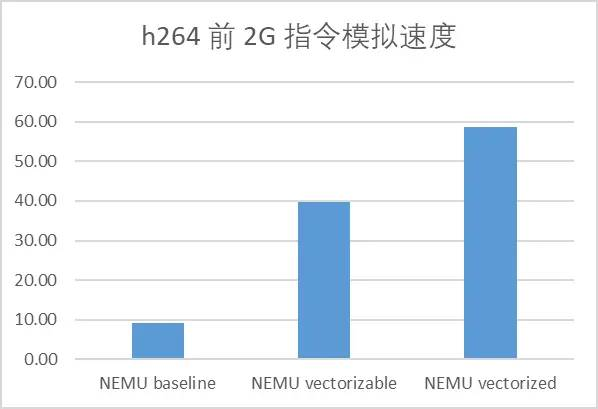 https://zhuanlan.zhihu.com/p/713732958?utm_psn=1805606654663860225
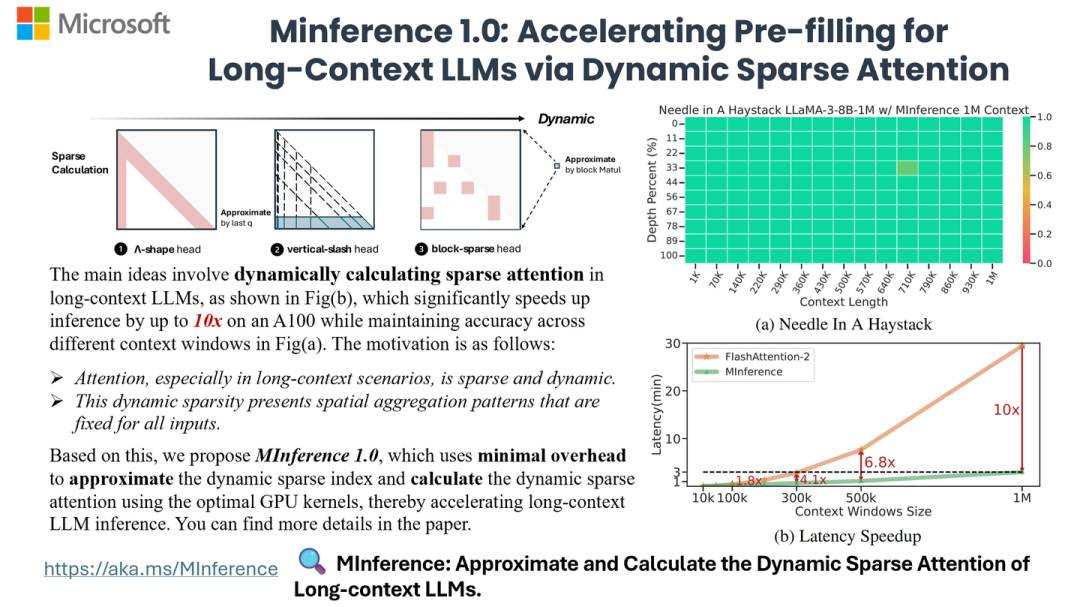
https://zhuanlan.zhihu.com/p/713732958?utm_psn=1805606654663860225单卡可Million-context推理TTFT 10倍加速 – MInference 1.0
 https://zhuanlan.zhihu.com/p/707815545?utm_psn=1805605787671863296
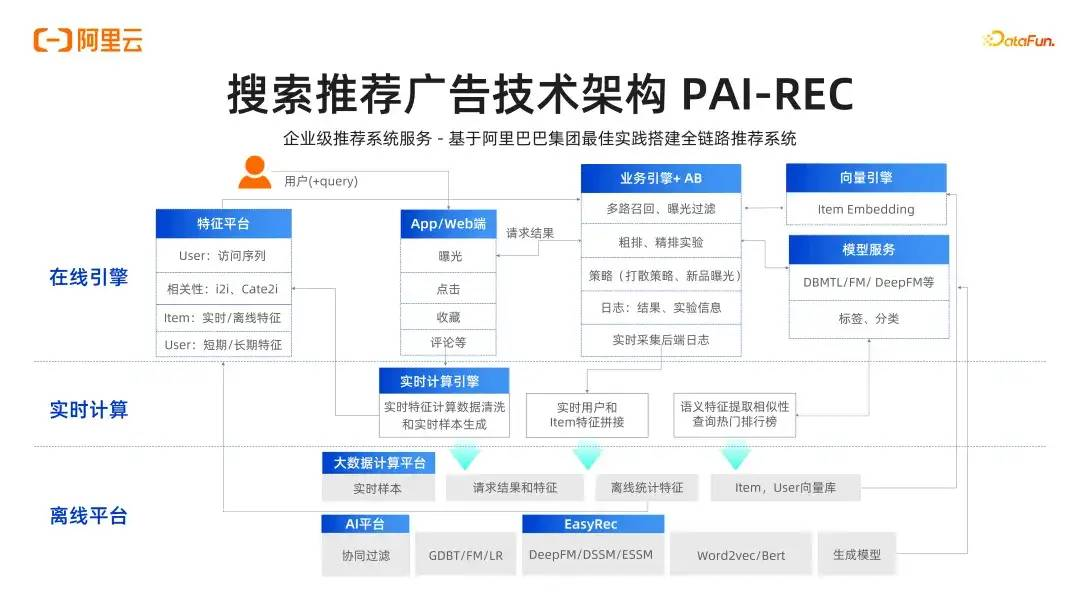
https://zhuanlan.zhihu.com/p/707815545?utm_psn=1805605787671863296从大数据到大模型:搜索推荐技术的前沿探索
 https://zhuanlan.zhihu.com/p/713026917?utm_psn=1805606498140815360
https://zhuanlan.zhihu.com/p/713026917?utm_psn=1805606498140815360flash attention完全解析和CUDA零基础实现
 https://zhuanlan.zhihu.com/p/658947627?utm_psn=1805607416940867586
https://zhuanlan.zhihu.com/p/658947627?utm_psn=1805607416940867586FPX-NIC:用于硬件编码的FPGA加速NIC框架
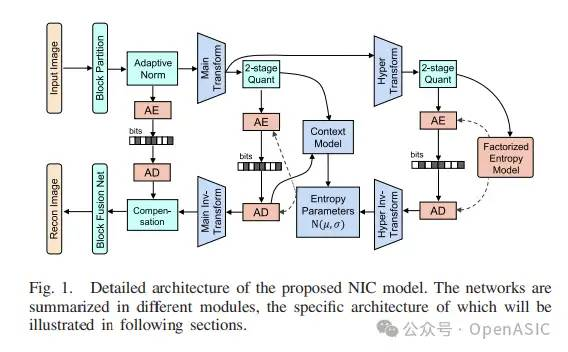 https://zhuanlan.zhihu.com/p/713707898?utm_psn=1805609150048251906
https://zhuanlan.zhihu.com/p/713707898?utm_psn=1805609150048251906京东广告稀疏大模型训练与推理 GPU 优化实践
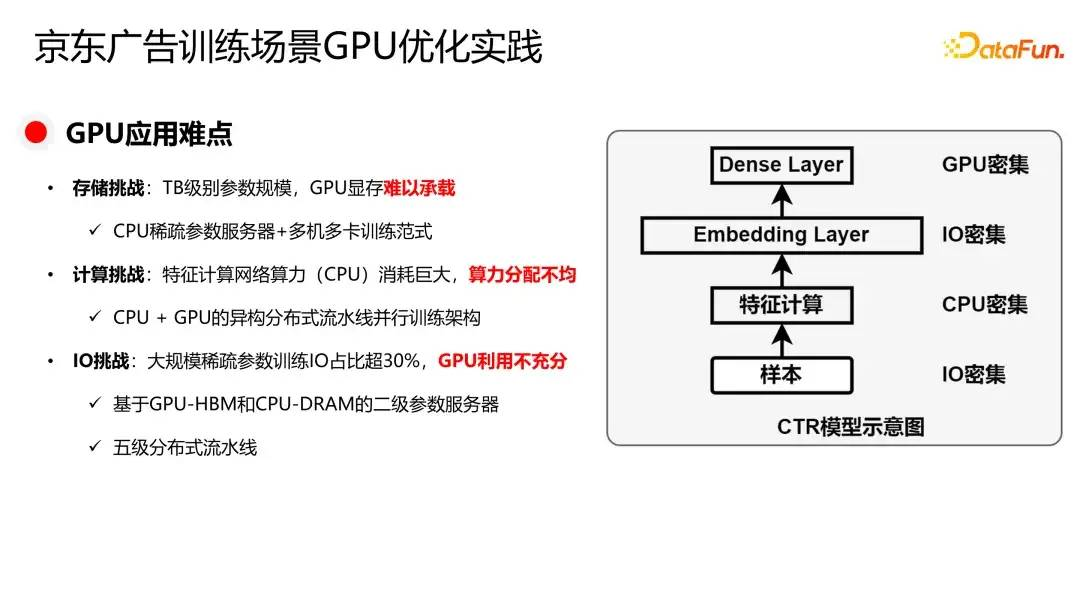 https://zhuanlan.zhihu.com/p/713692019?utm_psn=1805609351852990464
https://zhuanlan.zhihu.com/p/713692019?utm_psn=1805609351852990464新评测集 LiveBench & CoverBench
 https://zhuanlan.zhihu.com/p/713593419?utm_psn=180560924821172633
https://zhuanlan.zhihu.com/p/713593419?utm_psn=180560924821172633GPTMe
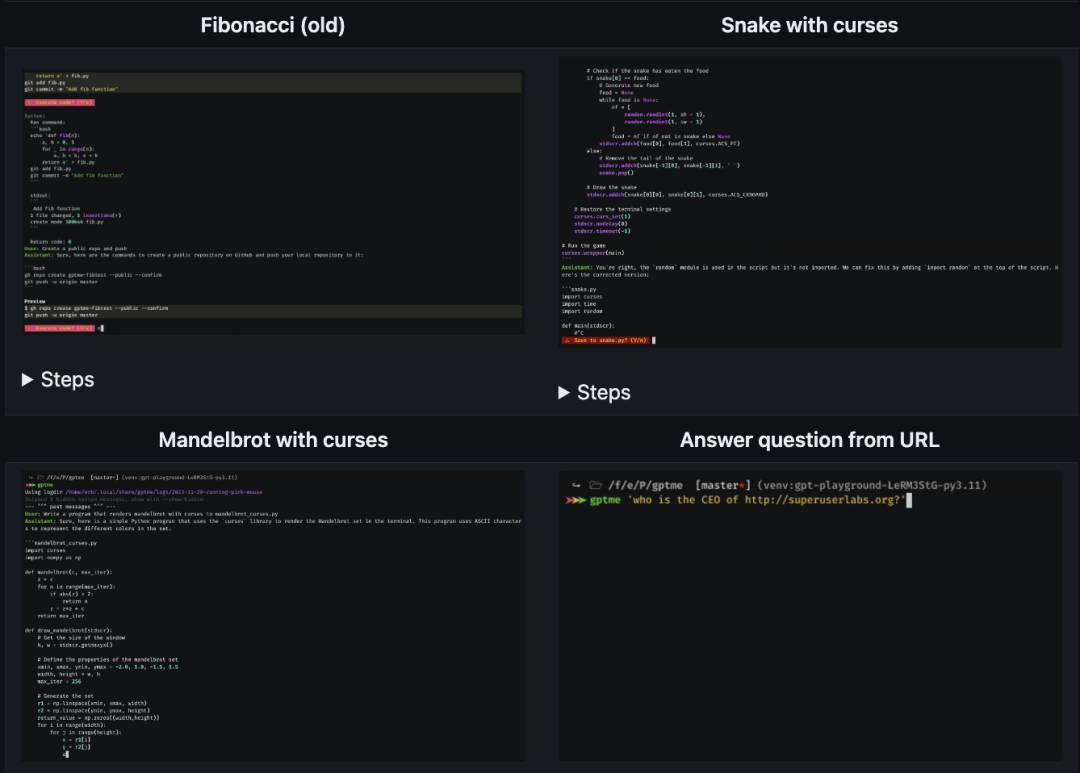 https://github.com/ErikBjare/gptme
https://github.com/ErikBjare/gptmemerlinn
 https://github.com/merlinn-co/merlinn
https://github.com/merlinn-co/merlinn-
— END —