包阅导读总结
1. 关键词:MindSearch、AI 搜索、InternLM2.5 7B、开源、本地搭建
2. 总结:
MindSearch 是书生·浦语团队提出的 AI 搜索框架,基于 InternLM2.5 7B 模型,采用 multi-agent 框架模拟人类思维,其技术方案全栈开源。文中介绍了它在回答复杂问题上的优势、架构、技术详解,还给出了在魔搭社区免费算力上本地部署的步骤。
3. 主要内容:
– MindSearch 简介:
– 是书生·浦语团队提出的 AI 搜索框架
– 基于 InternLM2.5 7B 模型,采用 multi-agent 框架
– 优势特点:
– 先规划再搜索,提高信息搜集准确性和完整性
– 信息搜索和整合过程可视化
– 在回答的信息准确性、完整性和时效性上有显著优势
– 架构:
– 外层 Web Planner 负责任务拆解和动态规划
– 内层 Web Search 负责子问题搜索和信息整合
– 技术详解:
– 包括迭代式搜索规划和搜索任务执行过程等
– 最终回复生成在 LLM 推理过程中边输出边渲染
– 本地部署:
– 安装依赖
– 下载模型并修改相关代码
– 选择搜索引擎
– 可选修改 lmdeploy 代码
– 启动后端 API 和前端体验
思维导图: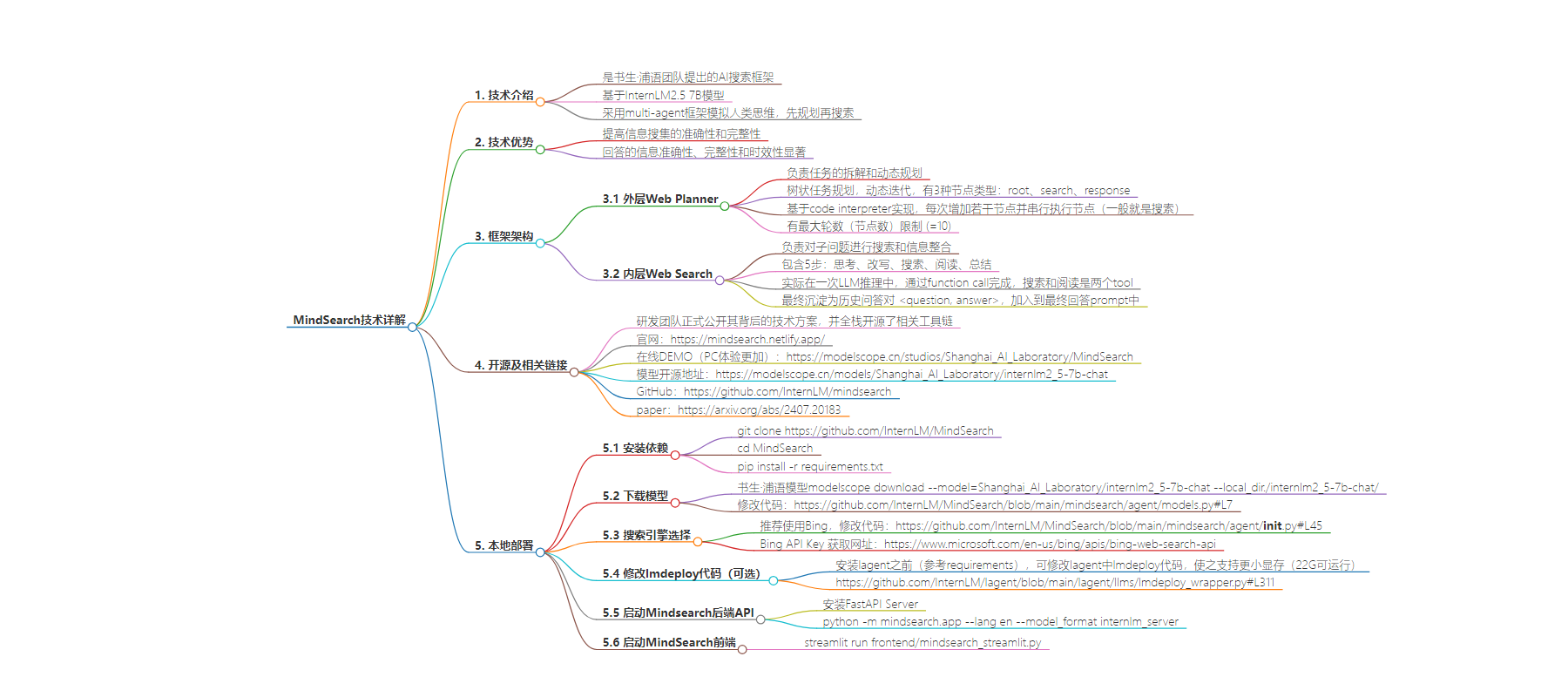
文章地址:https://mp.weixin.qq.com/s/AhPoPD8eOnKFP670xeVt_g
文章来源:mp.weixin.qq.com
作者:胖逹
发布时间:2024/8/5 12:34
语言:中文
总字数:3973字
预计阅读时间:16分钟
评分:78分
标签:AI搜索框架,Multi-Agent框架,开源工具,InternLM2.5 7B模型,信息整合
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
MindSearch是书生·浦语团队提出的AI搜索框架,基于InternLM2.5 7B模型,采用multi-agent框架模拟人类思维,先规划再搜索,提高信息搜集的准确性和完整性。研发团队正式公开其背后的技术方案,并全栈开源了相关工具链,让你在家就能免费用上 SearchGPT 的开源平替!
官网:
https://mindsearch.netlify.app/
在线DEMO(PC体验更加):
https://modelscope.cn/studios/Shanghai_AI_Laboratory/MindSearch
模型开源地址:
https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2_5-7b-chat
GitHub:
https://github.com/InternLM/mindsearch
paper:
https://arxiv.org/abs/2407.20183
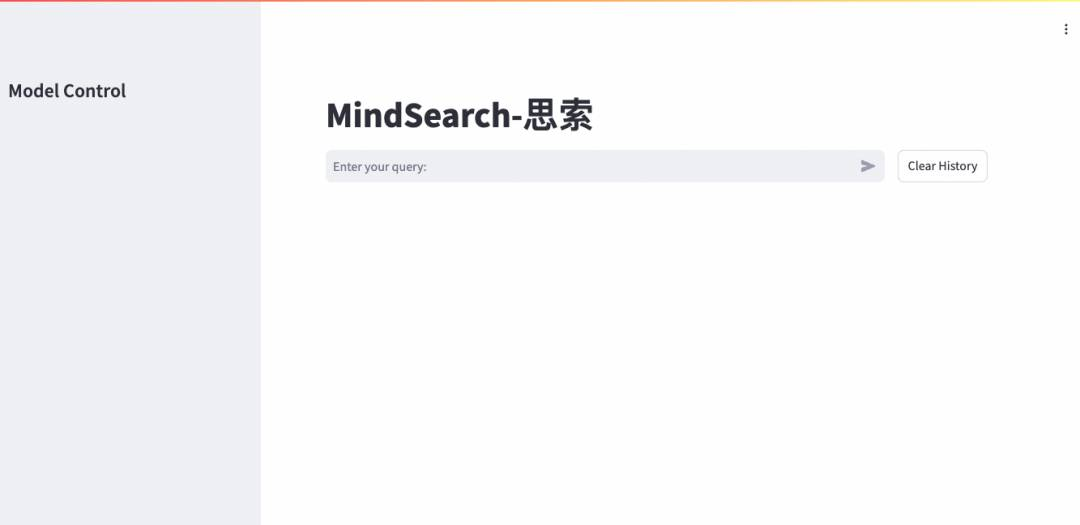
如下面视频所示,对于多步骤的复杂问题,模型能够分析用户需求,再针对每一个技术难点搜索对应的解决方案,最后总结并输出答案。
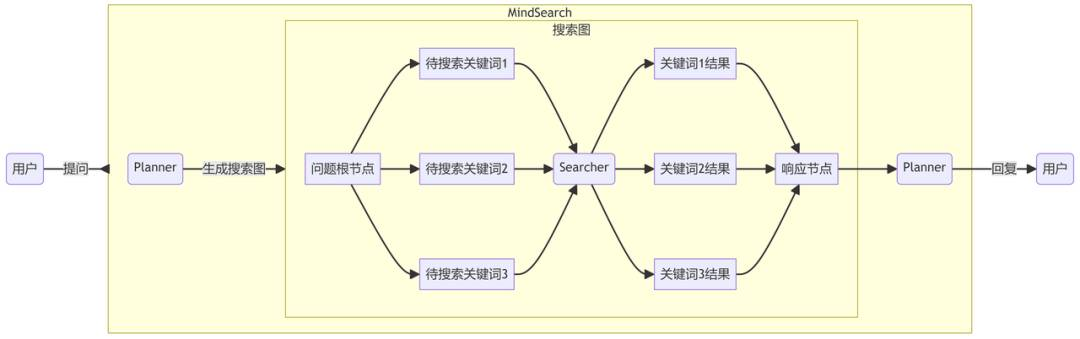
MindSearch架构图:
小编划重点:
-
支持开放域搜索,兼具深度和广度,信息搜索+信息整合过程全部可视化
-
基于Multi-Agent框架实现,包括两层:
-
外层Web Planner 负责任务的拆解和动态规划
-
内层Web Search 负责对子问题进行搜索和信息整合
3. 搜索过程比较丝滑,单问题端到端时间在3min
技术详解视频
Multi-Agent框架
和现有的 AI 搜索引擎技术相比,MindSearch 因为采用了多智能体框架和模拟了人的思维过程,会先对问题进行拆解和规划,因此在回答的信息准确性、完整性和时效性上具有显著的优势。
整体包括三层:
-
思:Web Planner 负责任务的拆解和动态规划
a、 树状任务规划,动态迭代,有3种节点类型:root、search、response
b、 基于code interpreter实现,每次增加若干节点并串行执行节点(一般就是搜索)
c、 有最大轮数(节点数)限制 (=10) -
索:Web Search 负责对子问题进行搜索和信息整合
a、包含5步:思考、改写、搜索、阅读、总结
b、实际在一次LLM推理中,通过function call完成,搜索和阅读是两个tool
c、最终沉淀为历史问答对 <question, answer>,加入到最终回答prompt中 -
Response生成
实现部分参考框架开源代码:https://github.com/InternLM/lagent
迭代式搜索规划 (Web Planner)
在System中定义了Graph相关的类和方法,让大模型生成可执行的python代码
GRAPH_PROMPT_CN = """## 人物简介你是一个可以利用 Jupyter 环境 Python 编程的程序员。你可以利用提供的 API 来构建 Web 搜索图,最终生成代码并执行。## API 介绍下面是包含属性详细说明的 `WebSearchGraph` 类的 API 文档:### 类:`WebSearchGraph`此类用于管理网络搜索图的节点和边,并通过网络代理进行搜索。#### 初始化方法初始化 `WebSearchGraph` 实例。**属性:**- `nodes` (Dict[str, Dict[str, str]]): 存储图中所有节点的字典。每个节点由其名称索引,并包含内容、类型以及其他相关信息。- `adjacency_list` (Dict[str, List[str]]): 存储图中所有节点之间连接关系的邻接表。每个节点由其名称索引,并包含一个相邻节点名称的列表。#### 方法:`add_root_node`添加原始问题作为根节点。**参数:**- `node_content` (str): 用户提出的问题。- `node_name` (str, 可选): 节点名称,默认为 'root'。#### 方法:`add_node`添加搜索子问题节点并返回搜索结果。**参数:- `node_name` (str): 节点名称。- `node_content` (str): 子问题内容。**返回:**- `str`: 返回搜索结果。#### 方法:`add_response_node`当前获取的信息已经满足问题需求,添加回复节点。**参数:**- `node_name` (str, 可选): 节点名称,默认为 'response'。#### 方法:`add_edge`添加边。**参数:**- `start_node` (str): 起始节点名称。- `end_node` (str): 结束节点名称。#### 方法:`reset`重置节点和边。#### 方法:`node`获取节点信息。```pythondef node(self, node_name: str) -> str```**参数:**- `node_name` (str): 节点名称。**返回:**- `str`: 返回包含节点信息的字典,包含节点的内容、类型、思考过程(如果有)和前驱节点列表。## 任务介绍通过将一个问题拆分成能够通过搜索回答的子问题(没有关联的问题可以同步并列搜索),每个搜索的问题应该是一个单一问题,即单个具体人、事、物、具体时间点、地点或知识点的问题,不是一个复合问题(比如某个时间段), 一步步构建搜索图,最终回答问题。## 注意事项1. 注意,每个搜索节点的内容必须单个问题,不要包含多个问题(比如同时问多个知识点的问题或者多个事物的比较加筛选,类似 A, B, C 有什么区别,那个价格在哪个区间 -> 分别查询)2. 不要杜撰搜索结果,要等待代码返回结果3. 同样的问题不要重复提问,可以在已有问题的基础上继续提问4. 添加 response 节点的时候,要单独添加,不要和其他节点一起添加,不能同时添加 response 节点和其他节点5. 一次输出中,不要包含多个代码块,每次只能有一个代码块6. 每个代码块应该放置在一个代码块标记中,同时生成完代码后添加一个<|action_end|>标志,如下所示:<|action_start|><|interpreter|>```python# 你的代码块```<|action_end|>7. 最后一次回复应该是添加node_name为'response'的 response 节点,必须添加 response 节点,不要添加其他节点"""
graph_fewshot_example_cn = """## 返回格式示例<|action_start|><|interpreter|>```pythongraph = WebSearchGraph()graph.add_root_node(node_content="哪家大模型API最便宜?", node_name="root") # 添加原始问题作为根节点graph.add_node(node_name="大模型API提供商", # 节点名称最好有意义node_content="目前有哪些主要的大模型API提供商?")graph.add_node(node_name="sub_name_2", # 节点名称最好有意义node_content="content of sub_name_2")...graph.add_edge(start_node="root", end_node="sub_name_1")...graph.node("大模型API提供商"), graph.node("sub_name_2"), ...```<|action_end|>"""
搜索任务执行过程 (Web Searcher)
整个过程包含5步:思考、改写、搜索、阅读、总结
基于few-shot,在一个LLM推理中,通过function call功能实现
最终沉淀为历史问答对 <question, answer>,加入到最终回答prompt中
思考、改写、总结
改写一般拆4个query
searcher_system_prompt_cn = """## 人物简介你是一个可以调用网络搜索工具的智能助手。请根据"当前问题",调用搜索工具收集信息并回复问题。你能够调用如下工具:{tool_info}## 回复格式调用工具时,请按照以下格式:```你的思考过程...<|action_start|><|plugin|>{{"name": "tool_name", "parameters": {{"param1": "value1"}}}}<|action_end|>```## 要求- 回答中每个关键点需标注引用的搜索结果来源,以确保信息的可信度。给出索引的形式为`[[int]]`,如果有多个索引,则用多个[[]]表示,如`[[id_1]][[id_2]]`。- 基于"当前问题"的搜索结果,撰写详细完备的回复,优先回答"当前问题"。"""
搜索
【Search API】目前支持Bing Web Serach/ DuckDuckGo Search
【召回数量】每个改写query召回4条结果
阅读
分为select和fetch两步:
●【select】通过大模型根据所有网页title和snippet,生成要阅读的网页id,分别进行fetch
fewshot_example_cn = """## 样例### search当我希望搜索"王者荣耀现在是什么赛季"时,我会按照以下格式进行操作:现在是2024年,因此我应该搜索王者荣耀赛季关键词<|action_start|><|plugin|>{{"name": "FastWebBrowser.search", "parameters": {{"query": ["王者荣耀 赛季", "2024年王者荣耀赛季"]}}}}<|action_end|>### select为了找到王者荣耀s36赛季最强射手,我需要寻找提及王者荣耀s36射手的网页。初步浏览网页后,发现网页0提到王者荣耀s36赛季的信息,但没有具体提及射手的相关信息。网页3提到“s36最强射手出现?”,有可能包含最强射手信息。网页13提到“四大T0英雄崛起,射手荣耀降临”,可能包含最强射手的信息。因此,我选择了网页3和网页13进行进一步阅读。<|action_start|><|plugin|>{{"name": "FastWebBrowser.select", "parameters": {{"index": [3, 13]}}}}<|action_end|>"""
●【fetch】直接用requests.get实现,单文档长度设置为最大8192
最终回复生成
在LLM推理过程中输出,边输出边渲染
FINAL_RESPONSE_CN = """基于提供的问答对,撰写一篇详细完备的最终回答。- 回答内容需要逻辑清晰,层次分明,确保读者易于理解。- 回答中每个关键点需标注引用的搜索结果来源(保持跟问答对中的索引一致),以确保信息的可信度。给出索引的形式为`[[int]]`,如果有多个索引,则用多个[[]]表示,如`[[id_1]][[id_2]]`。- 回答部分需要全面且完备,不要出现"基于上述内容"等模糊表达,最终呈现的回答不包括提供给你的问答对。- 语言风格需要专业、严谨,避免口语化表达。-保持统一的语法和词汇使用,确保整体文档的一致性和连贯性。"""
下面我们介绍,如何在魔搭社区免费算力(22G)上,本地部署MindSearch,即刻拥有本地专属的MindSearch!
第一步:安装依赖
git clone https://github.com/InternLM/MindSearchcd MindSearchpip install -r requirements.txt
第二步:下载模型书生·浦语模型
modelscopedownload--model=Shanghai_AI_Laboratory/internlm2_5-7b-chat--local_dir./internlm2_5-7b-chat/
这里,我们需要将lmdeploy默认从huggingface下载的模型id改为本地文件地址。
修改代码:https://github.com/InternLM/MindSearch/blob/main/mindsearch/agent/models.py#L7
path='/mnt/workspace/internlm2_5-7b-chat',第三步:搜索引擎选择Bing
由于默认的DuckDuckGo搜索引擎访问不畅,本文推荐改使用使用Bing的搜索引擎
修改代码:https://github.com/InternLM/MindSearch/blob/main/mindsearch/agent/__init__.py#L45
BingBrowser(searcher_type='BingSearch',topk=6,api_key=os.environ.get('BING_API_KEY','None'))),
Bing API Key 获取网址:
https://www.microsoft.com/en-us/bing/apis/bing-web-search-api
第四步:修改lmdeploy代码(可选)
安装lagent之前(参考requirements),可修改lagent中lmdeploy代码,是之支持更小显存(22G可运行)
https://github.com/InternLM/lagent/blob/main/lagent/llms/lmdeploy_wrapper.py#L311
from lmdeploy import TurbomindEngineConfigbackend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)self.client = lmdeploy.serve(model_path=self.path,model_name=model_name,server_name=server_name,server_port=server_port,tp=tp,backend_config=backend_config,log_level=log_level,**serve_cfg)
第五步:启动Mindsearch后端API
安装FastAPI Server
python-mmindsearch.app--langen--model_formatinternlm_server
第六步:启动MindSearch前端
Streamlit体验和前端体验比较好
streamlit run frontend/mindsearch_streamlit.py