
包阅导读总结
1.
关键词:PaddleNLP 3.0、大语言模型、一站式解决方案、性能优化、多硬件适配
2.
总结:PaddleNLP 3.0 重磅发布,基于飞桨框架 3.0 打造,提供从组网开发到推理部署的一站式方案。通过全流程优化,简化组网开发,提升精调对齐性能,支持多硬件适配,具备自动并行和训推一体等特性。
3.
主要内容:
– PaddleNLP 3.0 重磅发布
– 基于飞桨框架 3.0 版本,提供一站式解决方案
– 全流程优化,简化组网开发复杂性
– 分布式核心代码量减少 50%以上
– 支持 Llama 3.1 405B 模型开箱即用
– 预置 80 多个主流模型全流程方案
– 性能优化
– 减少无效数据填充,提升精调对齐性能
– 借助飞桨训推一体特性,提升训练吞吐
– 多硬件适配
– 仅需适配 30 余个接口
– 支持多款芯片的训练和推理
– 实现软硬协同的性能优化
– 相关活动
– 百度高级研发工程师将解读一站式解决方案
思维导图: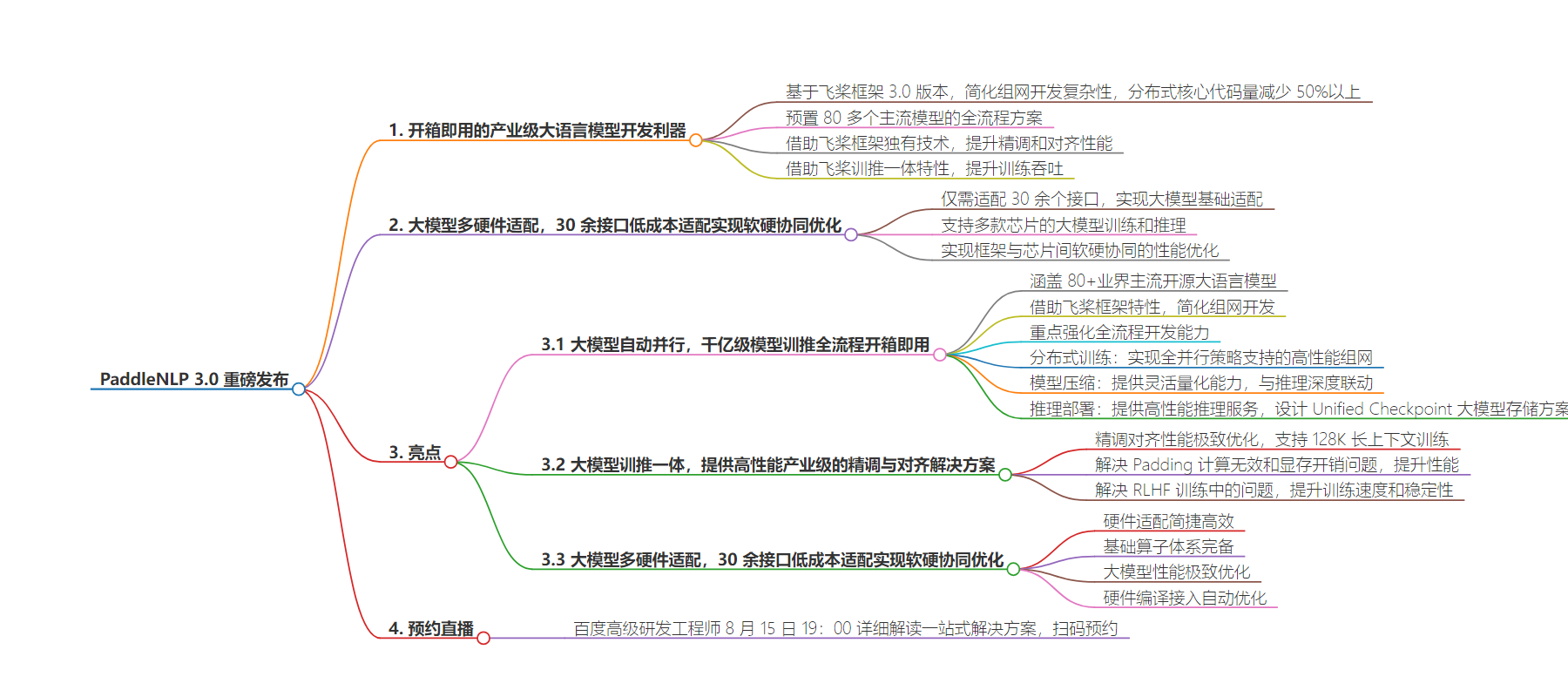
文章地址:https://mp.weixin.qq.com/s/1rs3go-WEk-Xh4jQe9F4gA
文章来源:mp.weixin.qq.com
作者:全栈布局的
发布时间:2024/8/9 10:36
语言:中文
总字数:3085字
预计阅读时间:13分钟
评分:91分
标签:大语言模型,PaddleNLP,飞桨框架,自动并行,训推一体
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
大语言模型的快速发展对训练和推理技术带来了更高的要求,基于飞桨框架3.0版本打造的 PaddleNLP 大语言模型套件,通过极致的全流程优化,为开发者提供从组网开发、预训练、精调对齐、模型压缩以及推理部署的一站式解决方案。
基于飞桨框架3.0版本,通过统一的分布式表示结合自动并行技术,大幅简化了组网开发的复杂性,分布式核心代码量减少50%以上,全分布式策略支持的组网支持 Llama 3.1 405B 模型开箱即用,同时预置了80多个主流模型的训练-压缩-推理的全流程方案,以满足不同场景需求。
基于飞桨框架独有的 FlashMask 高性能变长注意力掩码计算机制,结合 Zero Padding 零填充数据流优化技术,可最大程度减少无效数据填充带来计算资源浪费,显著提升精调和对齐性能。以 Llama 3.1 8B 模型为例,相比 LLaMA-Factory 方案,性能提升了1.2倍,单机即可完成128K长文的 SFT/DPO。借助飞桨训推一体特性,提供产业级的 RLHF 方案,PPO 采样可复用推理加速算子,训练吞吐提升达2.1倍。
▎大模型多硬件适配,30余接口低成本适配实现软硬协同优化
基于飞桨插件式松耦合统一硬件适配方案(CustomDevice),仅需适配30余个接口,即可实现大模型的基础适配,低成本完成训练-压缩-推理全流程;PaddleNLP 目前一站式支持英伟达 GPU、昆仑芯 XPU、昇腾 NPU、燧原 GCU 和海光 DCU 等多款芯片的大模型训练和推理,依托框架多种算子接入模式和自动并行调优等技术,便捷实现框架与芯片间软硬协同的性能优化。
欢迎开发者前往开源项目主页直接体验:
https://github.com/PaddlePaddle/PaddleNLP
亮点一:大模型自动并行,千亿级模型训推全流程开箱即用
本次 PaddleNLP 3.0升级总计涵盖了80+业界主流的开源大语言模型,参数量覆盖从0.5B 到405B 不等,能够灵活满足各种场景下的用户需求。借助飞桨3.0版本框架的最新特性,通过统一的分布式表示和自动并行技术,大幅简化了组网开发的复杂性。分布式核心代码量减少50%以上,全分布式策略支持的组网使得 Llama 3.1 405B 的 SFT 与 PEFT 功能开箱即用。
在 PaddleNLP 本次升级中重点强化大语言模型训练-压缩-推理的全流程开发能力,基于飞桨框架3.0版本全新设计的一站式开发体验,大幅降低学习和使用成本。
-
分布式训练:基于 Fleet API 实现了全并行策略支持的高性能组网,覆盖预训练、精调(SFT/PEFT)和对齐(RLHF/DPO)三个环节的主流算法,相比 HuggingFace Transformers 仅支持数据并行的组网实现,飞桨的组网原生支持张量并行和流水线并行,在低资源精调和长文训练场景中,具备更高的性能上限和可扩展性;
-
模型压缩:基于 PaddleSlim 提供的多种大语言模型 Post Training Quantization 技术,提供 WAC(权重/激活/缓存)灵活可配的量化能力,与 Paddle Inference 深度联动,保障压缩后的模型均能利用高性能低比特算子进行推理。
-
推理部署:基于 FastDeploy 全场景部署工具,提供了面向服务器场景的高性能推理服务,支持动态插入、流式输出、多硬件部署等功能。
业界方案在不同并行策略和不同结点数量下模型保存的 Checkpoint 格式不统一,模型量化和推理部署使用时需引入复杂切分和合并过程,保存和恢复时间长。针对这一系列问题,PaddleNLP 设计了 Unified Checkpoint 大模型存储方案,突破了以下三个技术瓶颈:
-
统一模型存储协议,在模型压缩、动转静、推理部署等环节中无需引入额外的参数合并流程。
-
内置参数自适应切分与合并功能,恢复训练时并行策略或者结点数量变化时可自动完成切分与合并,精准还原数据流状态。
-
支持异步保存与快速恢复,结合存储参数多进程均匀读写分配,实现秒级保存与比特稳定快速恢复。
Unified Checkpoint 模型参数存储示例图
亮点二:大模型训推一体,提供高性能产业级的精调与对齐解决方案
1. 精调对齐性能极致优化,支持128K长上下文训练
在精调和对齐训练中为业界普遍采用定长 Padding 策略解决数据长度不一的问题,该做法随着数据集长度分布差异增大,无效的 Padding 计算也会同步增加,继而导致训练时间增长。针对这一问题,飞桨框架独有 FlashMask 高性能变长注意力掩码计算结合 PaddleNLP 中 Zero Padding 零填充数据流优化技术,通过分组贪心的数据填充策略,可最大程度消除无效 Padding 的比例。
同时,ZeroPadding+FlashMask 稀疏计算的特性也大幅减少了显存开销,使精调训练代码无缝从8K 扩展到128K 的长文训练。
综合上述优化,相比 LLaMA-Factory,PaddleNLP 在 SFT 环节性能提升120%,DPO 环节性能提升130%~240%,大幅降低了大模型精调和对齐环节所需的计算成本。
人类反馈强化学习(RLHF)通过不断接收人类对于模型行为的直接评价或示例指导,促使模型效果逐渐逼近人类预期的行为模式。然而,多样化的样本导致待对齐模型出现奖励信号互斥和策略更新程度难以平衡的现象,进而导致模型训练时波动幅度大且收敛速度慢,多模型生成和训练容易占用显存大,训练速度慢。针对这一系列问题,PaddleNLP基于飞桨训推一体框架特性和多多种策略结合的来解决:
-
训推一体:依托飞桨框架训推一体特性,在 Policy 模型采样生成复用推理高性能融合算子,使 RLHF 训练加速 2.1 倍。
-
显存优化:基于飞桨原生的张量并行/流水线并行能力,结合 Offload 训练模式控制显存占用,单机即可完成训练百亿级别 PPO 训练。
-
策略优化:支持优势函数平滑、EMA 参数策略,提升模型训练稳定性。
综合上述优化,以 LLaMA-7B 模型为例,PaddleNLP 的 PPO 训练性能达 Beaver 框架的3.2倍。
RLHF 训练策略&RLHF PPO 训练速度对比
亮点三:大模型多硬件适配,30余接口低成本适配实现软硬协同优化
基于飞桨框架3.0发布的大模型多硬件适配技术,通过插件式软硬件松耦合的分层设计,可以低成本完成芯片的大模型基础适配和软硬协同优化,其具备以下特点:
-
硬件适配简捷高效:不同硬件仅需适配30余接口,即可全面支持大模型训压推。
-
基础算子体系完备:通过基础算子体系,减少硬件适配所需开发的算子数量。
-
大模型性能极致优化:支持算子融合、显存复用等方式实现高效算子流水编排,极致显存复用优化。
-
硬件编译接入自动优化:支持通过神经网络编译器代码后端 CodeGen 的方式接入,实现多硬件后端的算子生成与性能优化。
PaddleNLP 目前一站式支持英伟达 GPU、昆仑芯 XPU、昇腾 NPU、燧原 GCU 和海光 DCU 等多款芯片的大模型训练和推理,依托框架多种算子接入和适配模式,以及自动并行调优等技术,便捷实现框架与芯片软硬协同的性能优化。
当前 PaddleNLP 3.0在支持英特尔 CPU 和英伟达 GPU 的硬件基础上,针对 Llama 类模型结构已适配了昆仑芯 XPU、昇腾 NPU、海光 DCU 以及燧原 GCU 等国产硬件的训练和推理,只需要一行代码即可轻松切换硬件,欢迎与生态伙伴一起共建更多开源大模型的多硬件支持!
paddle.device.set_device("gpu")paddle.device.set_device("xpu")paddle.device.set_device("npu")paddle.device.set_device("gcu")paddle.device.set_device("cpu")
为了帮助您迅速且深入地了解 PaddleNLP 3.0,并熟练掌握实际操作技巧,百度高级研发工程师将在8月15日(周四)19:00,为您详细解读从组网开发、预训练、精调对齐、模型压缩以及推理部署的一站式解决方案。机会难得,立即扫描下方二维码预约吧!
https://github.com/PaddlePaddle/PaddleNLP