
包阅导读总结
1. 关键词:DeepSeek API、硬盘缓存、降低成本、服务延迟、安全性
2. 总结:DeepSeek API 创新采用硬盘缓存,降低服务延迟与使用成本,用户无需改代码,自动运行按命中计费。增加字段可查命中情况,多种应用受益,缓存考虑安全性,其率先采用得益于特定结构,API 服务不限流不限并发。
3. 主要内容:
– DeepSeek API 硬盘缓存技术
– 原理:将预计重复使用内容缓存在分布式硬盘阵列,重复部分从缓存读取,降低延迟与成本。
– 费用:命中部分 0.1 元每百万 tokens,未命中 1 元每百万 tokens。
– 使用方式与计费
– 自动运行,无需改代码换接口,按实际命中情况计费。
– API 返回的 usage 中新增字段可查命中情况。
– 应用受益与优势
– 多种应用受益,如问答助手、角色扮演、数据分析等。
– 降低服务延迟,最高节省 90%费用,即使不优化也能省超 50%。
– 缓存安全性
– 用户缓存独立,逻辑上不可见,确保数据安全隐私。
– 长时间不用的缓存自动清空。
– 率先采用原因及服务限制
– 得益于特定结构压缩上下文 KV Cache 大小。
– API 服务不限流不限并发,按每天 1 万亿容量设计。
– 缓存系统以 64 tokens 为存储单元,尽力而为,不保证 100%命中,不再使用会自动清空。
思维导图:
文章地址:https://mp.weixin.qq.com/s/zPz8U-F8PAovhG-FbAOzLA
文章来源:mp.weixin.qq.com
作者:深度求索
发布时间:2024/8/2 12:24
语言:中文
总字数:1197字
预计阅读时间:5分钟
评分:90分
标签:大模型 API,硬盘缓存,成本降低,服务优化,DeepSeek
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

在大模型 API 的使用场景中,用户的输入有相当比例是重复的。举例说,用户的 prompt 往往有一些重复引用的部分;再举例说,多轮对话中,每一轮都要将前几轮的内容重复输入。
 如何使用 DeepSeek API 的缓存服务
如何使用 DeepSeek API 的缓存服务
硬盘缓存服务已经全面上线,用户无需修改代码,无需更换接口,硬盘缓存服务将自动运行,系统自动按照实际命中情况计费。
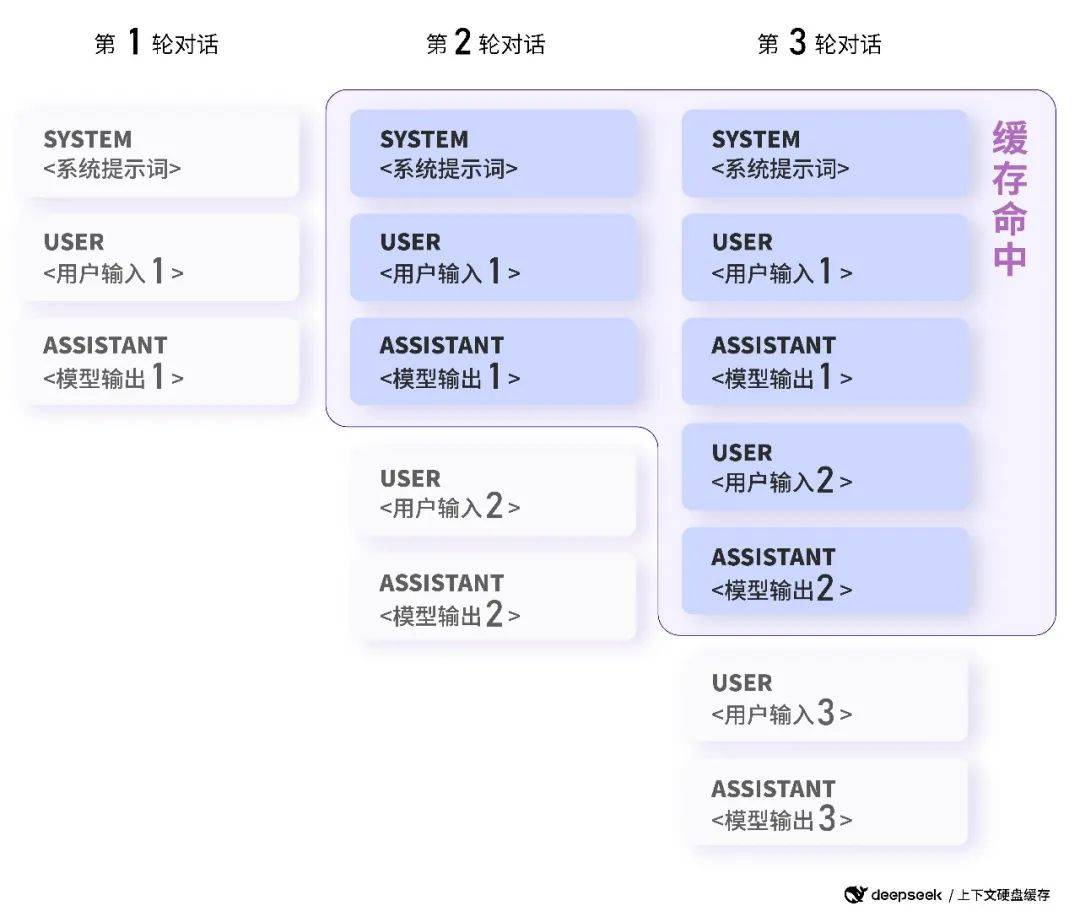
数据分析:后续具有相同前缀的请求会命中上下文缓存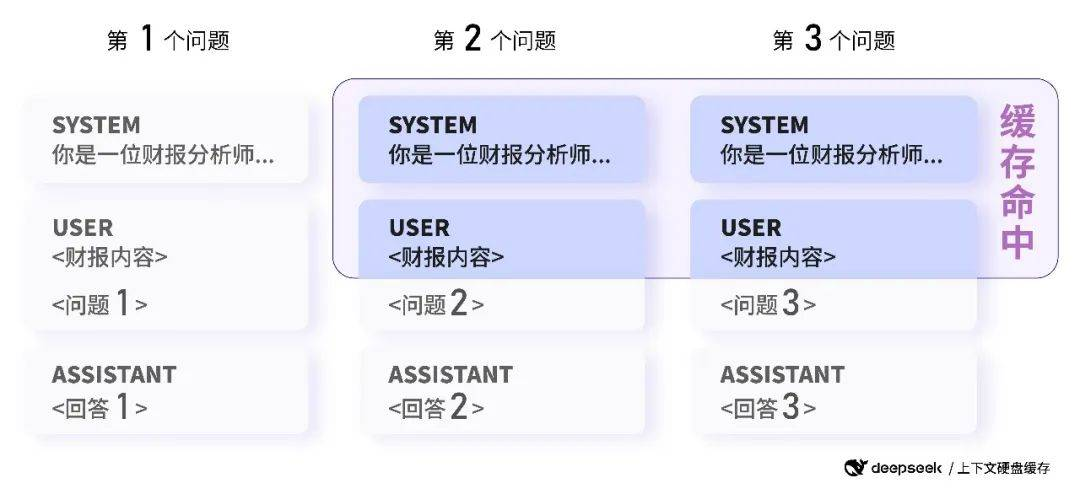
多种应用能从上下文硬盘缓存中受益:
-
具有长预设提示词的问答助手类应用
-
具有长角色设定与多轮对话的角色扮演类应用
-
针对固定文本集合进行频繁询问的数据分析类应用
-
代码仓库级别的代码分析与排障工具
-
…
 如何查询缓存命中情况
如何查询缓存命中情况
-
prompt_cache_hit_tokens:本次请求的输入中,缓存命中的 tokens 数( 0.1 元 / 百万 tokens) -
prompt_cache_miss_tokens:本次请求的输入中,缓存未命中的 tokens 数(1 元 / 百万 tokens)
 降低服务延迟
降低服务延迟
举个极端的例子,对 128K 输入且大部分重复的请求,实测首 token 延迟从 13 秒降低到 500 毫秒。
 降低整体费用
降低整体费用
缓存没有其它额外的费用,只有0.1 元每百万 tokens。缓存占用存储无需付费。
 缓存的安全性问题
缓存的安全性问题
长时间不用的缓存会自动清空,不会长期保留,且不会用于其他用途。
 为何 DeepSeek API 能率先采用硬盘缓存
为何 DeepSeek API 能率先采用硬盘缓存
这得益于 DeepSeek V2 提出的 MLA 结构,在提高模型效果的同时,大大压缩了上下文 KV Cache 的大小,使得存储所需要的传输带宽和存储容量均大幅减少,因此可以缓存到低成本的硬盘上。
 DeepSeek API 的并发和限流
DeepSeek API 的并发和限流
DeepSeek API 服务按照每天 1 万亿的容量进行设计。对所有用户均不限流、不限并发、同时保证服务质量。请放心加大并发使用。