
包阅导读总结
1. 关键词:
– AI 模型
– 图像生成
– 视频分割
– 语言模型
– 技术发展
2. 总结:
7.30 – 8.04 这周 AI 领域有诸多新进展。Google 发布 Gemma 2 2B 和 Gemini 1.5 Pro 模型,FLUX 成为开源图像新标杆,Meta 发布 SAM 2 分割模型。同时还有其他动态,如多家公司的新产品、融资、收购等,以及相关的精选文章和重点研究。
3. 主要内容:
– Google 发布
– Gemma 2 2B 和 Gemini 1.5 Pro
– Gemini 1.5 Pro 多模态能力强大,支持音频和视频
– Gemma 2 2B 可在设备端运行,内置安全分类器
– FLUX 开源图像
– Robin Rombach 创立新公司并获融资
– 发布系列图像生成模型,包括 FLUX.1[pro]、FLUX.1[dev]、FLUX.1[schnell]
– 测试效果接近 Midjourney,存在微调效果问题
– Meta 发布
– SAM 2 分割模型,用于图像和视频对象分割
– 发布最大的视频分割数据集 SA-V
– 其他动态
– Meta 发布 Playground 测试 AI 功能
– Stability AI 推出 Stable Fast 3D
– Figure 即将发布新机器人
– Hedra 获 1000 万美元融资
– Runway 发布 Gen3 的 Turbo 版本,推出图生视频功能
– Leonardo 被 Canva 收购
– Character AI 被谷歌收购
– Midjourney V6.1 版本更新
– Open AI 推出 GPT-40 长输出版本
– Vidu 上线
– 苹果 AI 功能上线
– 快手 LivePortrait 支持表情迁移
– Cohere 推出 Prompt Tuner 提示词优化工具
– 精选文章
– 生成式人工智能对在线知识社区的影响
– Llama 3.1 论文精读
– LLM 幻觉指数特别报告
– 量化的视觉指南
– 为什么人工智能将改变下一代销售技术
– 一个 AI 能制作基于数据的视觉故事吗
– 你应该如何实现 AI 功能的货币化
– 重点研究
– Fotographer ai Fuzer v0.1
– Apple Intelligence Foundation Language Models
– HoloDreamer
– HumanVid
– Anthropic:解释性研究中新的五大挑战
– Tora:面向轨迹的 DIT 用于视频生成
思维导图: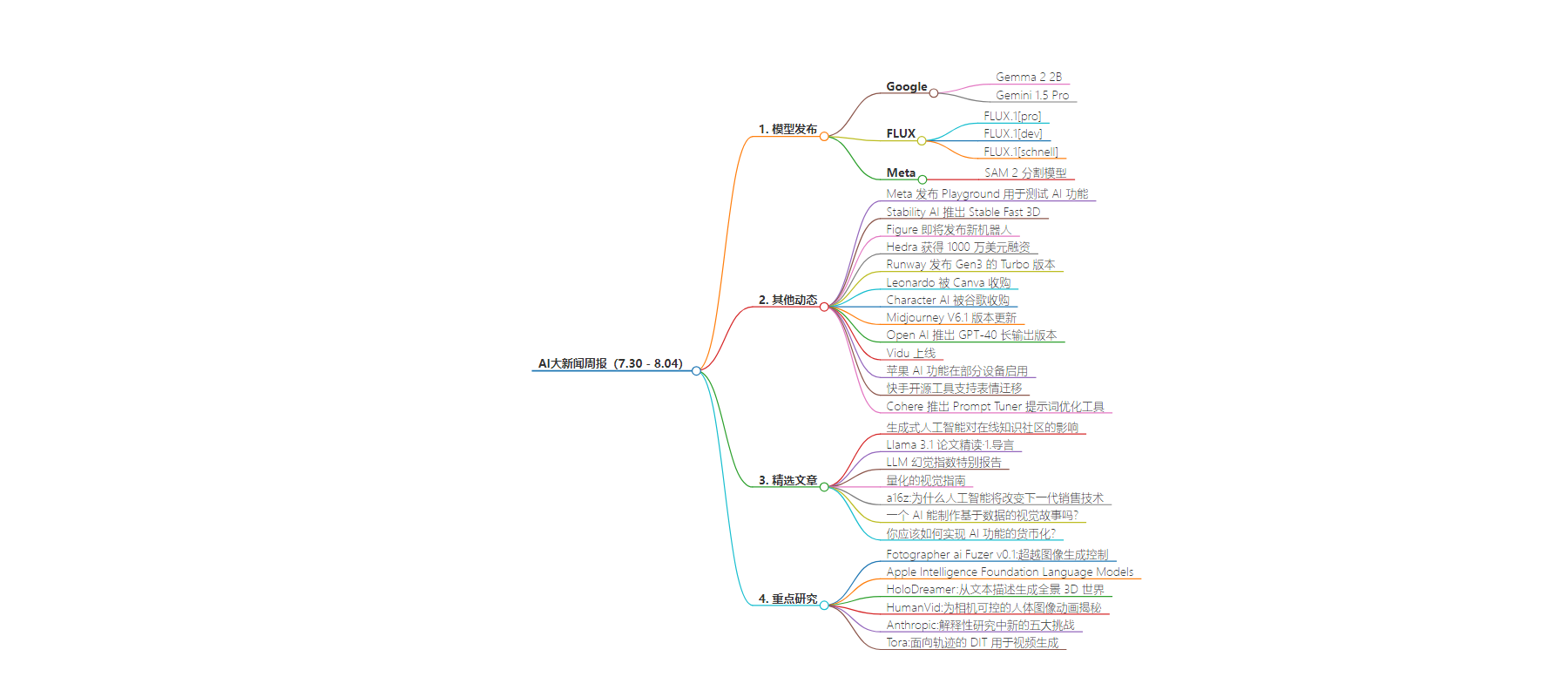
文章地址:https://mp.weixin.qq.com/s/zyH9_kTlRVP2iDey2ticQw
文章来源:mp.weixin.qq.com
作者:歸藏的??AI??工具箱
发布时间:2024/8/4 11:26
语言:中文
总字数:7059字
预计阅读时间:29分钟
评分:90分
标签:AI技术,图像生成,开源模型,多模态AI,技术创新
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
7.30~8.04,又是刺激的一周。
这周的AI大事件,就都在这里啦。
1.Google 发布 Gemma 2 2B和 Gemini 1.5 Pro
链接:https://developers.googleblog.com/en/smaller-safer-more-transparent-advancing-responsible-ai-with-gemma/?_bhlid=5811c5dce25719cc96adfd54bc6818d0aa07cc11
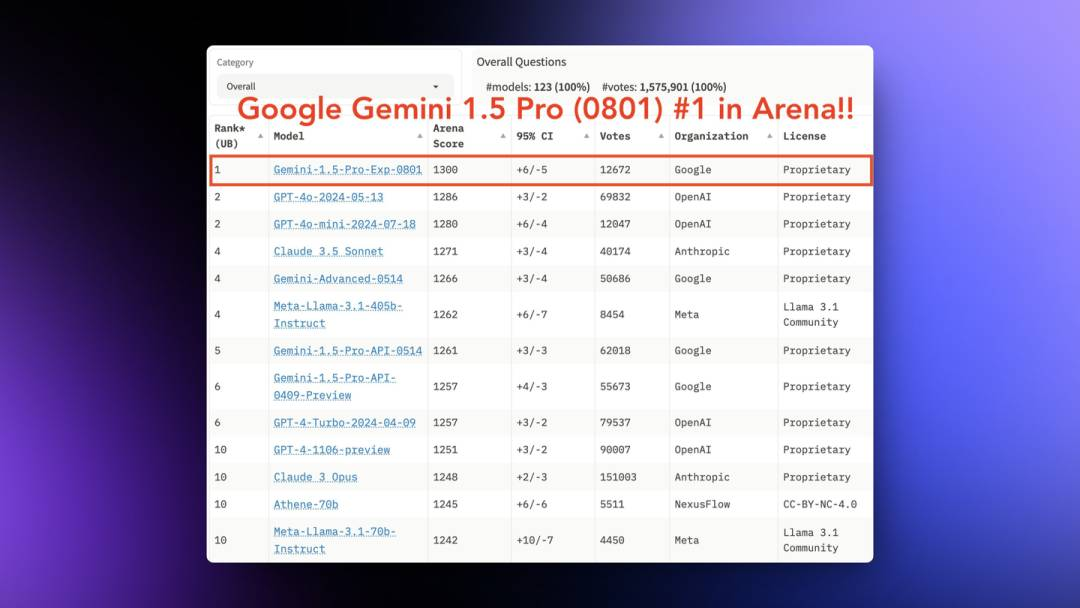
Google上周也开始发力了,先后发布了Gemini 1.5 Pro和Gemma 2 2B 模型。
其中Gemini 1.5 Pro 0801在LLM竞技场的综合排名超过了GPT-4o mini变成了第一位。谷歌说这是一个实验版本还不算正式版本,所以只在AI Studio中提供。
但是从测试来看Gemini 1.5Pro 0801的多模态能力非常强大,基本超过了GPT-40和Claude 3.5,而且它支持音频以及视频,我用一个一个多小时的播客文件试了一下,十几秒就总结好了。
另外Google还发布了Gemma 2 2B这个可以在设备端运行的模型,这个模型在LLM竞技场上的得分也超过了一众比它大很多的LLM。
这是量化过的Gemma 2 2B再加上MLX之后在iPhone 15pro上的运行效果。
而且这个模型还内置了谷歌新发布的安全分类器ShieldGemma,这个分类器可以有效检测仇恨言论、骚扰、性暗示内容以及危险内容。
2.FLUX开源图像的新标杆
链接:https://blackforestlabs.ai/announcing-black-forest-labs/
开源图像领域在SD3模型出现问题之后就有一蹶不振的趋势,新玩意和玩法越来越少,大家急需一个足够强大的图像模型来保证社区发展。
刚好这个模型就来了,前Stability AI核心成员Robin Rombach 创立了一个新的公司并且获得了3200万美元的融资。同时他们直接发布了一个系列的图像生成模型,其中两个还是开源的。
从我自己的测试和这几天各种测试来看,这个模型在各种意义上真的接近了Midjourney的质量。
他们发布的FLUX系列模型包括:
-
FLUX.1[pro]:FLUX.1的最佳版,提供最先进的性能图像生成,拥有一流的提示跟随、视觉品质、图像细节和输出多样性。
-
FLUX.1[dev]:FLUX.1[dev]是用于非商业应用的一个开放权重的导向精馏模型。直接从FLUX.1[pro]精馏而来,FLUX.1[dev]获得了类似的质量和提示词依从能力,同时比相同尺寸的标准模型更高效。可以非商业使用。
-
FLUX.1[schnell]:最快型号专为本地开发和个人使用而设计。FLUX.1[schnell]在Apache 2.0许可下公开可用。同时已经获得了ComfyUl的支持,可以直接使用。
而且他们正在训练类似Sora的DiT视频生成模型,可能也会开源,官网上放的视频可能是他们视频生成模型的样片。
不过他们的负责人好像表示由于Dev和Schnell都是从Pro 模型蒸馏来的所有两个模型的微调效果都不会很好,希望有大神可以解决这个问题。
另外使用Fp8版本的Dev模型可以稳定在4090上本地运行,也有可以在16G或者12G显存上运行的方法,就是有点麻烦。
你可以在这里快速体验FLUX系列模型:
https://replicate.com/collections/flux
这里下载模型:
https://huggingface.co/black-forest-labs
这里是ComfyUl的工作流:
https://comfyanonymous.github.io/ComfyUl_examples/flux/

3.Meta 发布 SAM 2 分割模型
链接:https://ai.meta.com/blog/segment-anything-2/
上周Meta 在图像领域也继续发力,发布了Meta Segment AnythingModel 2(SAM 2)图像分割模型。
用于实时、可提示的图像和视频对象分割,实现了视频分割体验的飞跃,实现了图像和视频应用之间的无缝使用。SAM 2在图像分割准确性方面超越了以前的能力,并且与现有作品相比,实现了更好的视频分割性能,同时需要三分之一的交互时间。
SAM 2还可以分割任何视频或图像中的任何对象(通常描述为0-shot泛化),这意味着它可以应用于以前未见过的视觉内容,无需自定义适应。
同时发布的还有一个SA-V:最大的视频分割数据集,SA-V数据集包含的注释数量多出一个数量级,视频对象分割数据集中的视频数量大约是现有数据集的4.5倍。
SA-V的主要特点有:大约51000个视频上有超过600,000个遮罩注释。展示地理多样性、真实场景的视频,搜集自47个国家。覆盖整个对象、对象部分以及具有挑战性的情况的注释,例如对象被遮挡、消失和重新出现。
这个演示就很离谱,SAM2可以从一个非常模糊,画面非常负责的航拍视频中稳定跟踪和分割指定人物。
这里下载模型:
https://github.com/facebookresearch/segment-anything-2
这里体验SAM2:
https://sam2.metademolab.com/

其他动态 ✦
1.Meta发布了一个Playground用来测试他们的AI功能,目前支持四个工具Segment Anything 2, lllustration Animation,Audiobox和一个语音翻译工具。
https://sam2.metademolab.com/demo
2.Stability AI 推出了Stable Fast 3D,这是一种新的3D生成模型,可在短短0.5秒内将单个图像转换为详细的3D资产。
https://stability.ai/news/introducing-stable-fast-3d
3.Figure即将在0806发布他们的新机器人,预告的预告拍的很好,机器人很精致完全不像工程机。
https://x.com/Figure_robot/status/1819388819638309286
4.Hedra 宣布了1000万美元的融资,用于打造下一代故事讲述技术,为内容创作者赋能。
https://www.hedra.com/blog/announcement
5.Runway发布了Gen3的Turbo版本,推理成本和生成速度大幅下降。生成速度比原始模型快了7倍,未来也会免费提供给用户,费用也大幅降低。同时发布了图生视频功能也已经上线。
https://x.com/runwayml/status/1818685167948435968
6.著名的AI绘画产品Leonardo宣布自己被Canva收购,未来原始的站点依然会更新和运营。
https://leonardo.ai/news/supercharging-leonardo-with-canva/
7.著名的AI陪伴型应用Character AI被谷歌收购,核心研发团队加入谷歌,公司谷歌注资继续独立运营。
https://blog.character.ai/our-next-phase-of-growth/
8.Midjourney V6.1版本更新。最大的变化是更丰富的画面细节和清晰度,即使远处的人脸也不容易崩了。新增 — q2模式,生成图片会有更多纹理。
https://x.com/midjourney/status/1818342703618482265
9.Open Al推出了GPT-40长输出版本,最多可以输出64K Token。这个模型每百万 Token 18美元。
https://openai.com/gpt-4o-long-output/
10.又一个DiT视频生成模型,生数科技的Vidu上线了,目前来看处于第二梯队。
https://www.vidu.studio/create
11.苹果的AI功能终于上了,iOS Beta 18.1 更新之后的15pro和Max可以启用,国行手机无法绕过限制启用。
12.快手的开源表情视频生成工具LivePortrait,现在支持将人类表情迁移到动物面部上去。
https://poe.com/LivePortrait
13.Cohere推出Prompt Tuner提示词优化工具,使用可定制的优化和评估循环来改进生成语言用例的提示。
https://cohere.com/blog/intro-prompt-tuner
精选文章 ✦
1.生成式人工智能对在线知识社区的影响
链接:https://www.nature.com/articles/s41598-024-61221-0
探讨了大型语言模型(LLMs)如ChatGPT对在线知识社区的影响,特别是在Stack Overflow 和Reddit开发者社区的用户参与度和内容创作方面。
-
通过对 Stack Overflow和Reddit开发者社区的分析,研究发现ChatGPT 的推出导致Stack Overflow的网站访问量和问题提交量显著减少,尤其是在ChatGPT领域能力强的话题中。而Reddit的开发者社区却没有显示出类似的下降,这可能是因为Reddit社区的社会结构更为紧密,能够缓冲LLMs的负面影响。
-
研究表明,在ChatGPT发布后,Stack Overflow上的用户活动中,新用户更有可能退出社区,而且提出的问题变得更加复杂和高级。这表明初学者可能更依赖于ChatGPT而不是人类同行,同时社交较少的用户更容易受到LLMs的影响。
-
研究强调,社区结构和用户间的社交联系对于维持社区活力和吸引力至关重要。管理者应该鼓励社交化活动,作为补充纯粹的信息交换,以对抗LLMs可能带来的社区退化。
2.Llama 3.1论文精读·1.导言【论文精读·54】
链接:https://www.bilibili.com/video/BV1WM4m1y7Uh/vd_source=e99f85042059f2864f5cca20d71575f0
断更许久的AI大神李沐的B站账号终于恢复了更新,讲的是Llama 3.1的论文的第一部分导言部分。
-
Meta发布了Llama 3.1系列新模型,最大参数规模达405B,支持多语言和工具使用。这一系列模型采用128K的上下文长度和稠密架构,进一步巩固了Llama在开源模型领域的领先地位。Llama团队规模已扩大至数百人,他们强调简化模型设计,使用15T多语言数据进行训练,在数据量和质量间寻求平衡。
-
Llama模型采用预训练和后训练两个阶段。预训练阶段简单预测下一个词,而后训练阶段则按照指示执行任务或提升能力。Llama团队采用简单直接的后训练过程,强调使用朴实的算法来维持低复杂度。在评估中,团队探讨了不同规模模型的表现、考试解法、模型记忆能力以及各种答题方式对模型调教的影响。
-
Mistral公司发布了120B参数的Large Enough模型,声称其性能优于Llama 3。这引发了Mistral与Meta(Llama团队)之间的争议。Mistral强调其模型的性价比和优越性,而Meta对此表示不满,甚至更新了相关协议。两家公司之间的竞争和纷争引发了业内广泛关注,也为未来Al模型发展带来了更多期待。
3.LLM幻觉指数特别报告
链接:https://www.rungalileo.io/hallucinationindex
LLM Hallucination Index-RAG Special主要介绍了一个评估大型语言模型(LLM)幻觉现象的指数,涵盖了22款领先的模型,并通过不同长度的上下文测试,评估了它们的表现,特别关注了基于检索增强生成(RAG)的任务。
评估过程包括三种不同长度的上下文测试:短上下文(少于5ktokens)、中上下文(5k到25k tokens)和长上下文(40k到100k tokens)。通过这些测试,网页提供了模型在不同上下文长度下的表现数据,并总结了一些趋势,例如开源模型在性能上逐渐接近闭源模型,以及模型在长上下文测试中的表现可能不逊于短上下文测试。
4.量化的视觉指南
链接:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization
详细探讨了量化技术在大型语言模型(LLMs)中的应用。作者首先指出了LLMs参数众多且需要大量内存的问题,然后介绍了量化的目的是在不失太多精度的情况下减少参数的位宽,例如从32位浮点数减少到8位整数。
文章分为四个部分:第一部分讨论了LLMs的问题以及如何表示数值;第二部分介绍了量化的基础知识,包括对称和非对称量化,以及范围映射和裁剪;第三部分探讨了后训练量化(PTQ),包括动态和静态量化,以及4位量化的方法如GPTQ和GGUF;第四部分则介绍了量化感知训练(QAT),以及如何使用BitNet将模型权重量化到1位,并提到了1.58位量化的优势和方法。
5.a16z:为什么人工智能将改变下一代销售技术
链接:https://a16z.com/ai-transforms-sales/
主要讨论了人工智能(AI)如何彻底改变未来的销售技术,强调AI将重塑销售流程和工作流程,并可能导致现有的销售软件栈发生根本性变化。
每个初创企业与现有企业之间的竞争,实际上是看谁能在对方创新之前获得分销权。在销售技术领域,人们容易认为像Salesforce和Hubspot这样的现有企业拥有优势。然而,由于AI的到来,这些公司的核心系统记录和销售工作流程可能会被根本性地重塑。AI不仅能够从文本、图像、语音和视频等多种模式中提取客户洞察,还能够自动化销售流程,如潜在客户的研究和电话准备等。文章进一步探讨了Al如何改变销售活动,以及新兴的AI本地销售解决方案如何不仅仅是现有类别的AI增强版本,而是能够实现新的主动销售动作,并服务于多种用例。
6.一个AI能制作基于数据的视觉故事吗?
链接:https://a16z.com/ai-transforms-sales/
The Pudding 的团队对AI的能力进行了探索性的测试,通过与AI(特别是Anthropic的AI产品Claude)的互动,尝试创建一个数据驱动的故事。他们将整个过程分为四个阶段:创意生成、数据收集与分析、故事板与原型制作以及开发与写作。在每个阶段,他们都对Al的表现进行了评估和打分。
整体而言,AI在辅助完成特定任务方面表现出一定的能力,但在处理复杂的编程问题和创造性的内容创作方面存在明显的不足。The Pudding 的团队认为,尽管AI可以作为一个有用的工具,但它目前还不能完全取代人类在数据驱动故事创作方面的工作。
7.你应该如何实现AI功能的货币化?
链接:https://www.lennysnewsletter.com/p/how-should-you-monetize-your-ai-features
作者Palle Broe,曾在Uber和Templafy担任过定价策略职务,并为多家科技公司提供了货币化策略咨询。他在这篇文章中分析了44家科技公司如何对AI产品和特性进行定价,并基于这些数据和自身经验,提出了一个框架,帮助其他公司决定如何定价自己的AI产品和特性。
文章深入探讨了直接货币化的三种核心策略:增值服务、独立产品和捆绑在计划中但价格增加。文章还提供了一个决策图表,帮助公司根据Al特性的普及度和用户对其价值的认可程度来决定定价策略。
重点研究 ✦
1.Fotographer ai Fuzer v0.1:超越图像生成控制
链接:https://huggingface.co/spaces/fotographerai/Fai-Fuzer
Fotographer出了一个很牛的商品图拍摄项目。效果比只用IC light的工作流好非常多,而且玻璃之类的东西跟环境融合也很好。商标和文字也可以完全保留。
需要上传已经抠图的产品图片,输入背景提示词和前景对产品的提示词描述。
2.Apple Intelligence Foundation LanguageModels
链接:https://arxiv.org/pdf/2407.21075
苹果发布了一篇47页的论文。详细介绍了他们AI系统的全部架构。相当的坦诚了。
Apple为其智能功能开发的两个基础语言模型-AFM-on-device(约30亿参数)和AFM-server(更大的服务器模型)。详细描述了模型架构、训练数据、训练过程、推理优化和评估结果。
这对于了解下一代设备端机器学习技术的发展方向非常有帮助。期待后续会有更多相关信息发布。
这里有VB的详细总结和翻译。
https://x.com/op7418/status/1818220057354465281
3.HoloDreamer:从文本描述生成全景3D世界
链接:https://zhouhyocean.github.io/holodreamer/
HoloDreamer这个项目可以生成封闭的3D场景。
从演示来看质量高的离谱,感觉可以成为Al视频里面场景一致性的解决方案。
先生成高清全景图作为整个3D场景的整体初始化,然后用3D高斯散射技术快速重建3D场景。
从而实现视角一致且完全封闭的3D场景创建。
4.HumanVid:为相机可控的人体图像动画揭秘
链接:https://humanvid.github.io/
1CUHK和上海Al lab的论文,HumanVid可以从角色照片生成视频,同时允许用户控制人物和摄像机动作。从演示来看效果好的有点离谱,希望可以尽快放出代码和模型。
提出了HumanVid,这是为人类图像动画量身定制的第一个大规模高质量数据集,结合了精心设计的真实世界数据和合成数据。对于真实世界数据,我们从互联网编制了大量免版税的真实世界视频。通过一个精心设计的基于规则的过滤策略,我们确保包括高质量视频,结果是拥有1080P分辨率的20000个人为中心视频收集。我们使用2D姿势估计器和基于SLAM的方法进行人类和摄像机运动标注。对于合成数据,我们收集了2300个免版税的3D头像资产,以增加现有的可用3D资产。值得注意的是,我们引入了一种基于规则的摄像机轨迹生成方法,使合成流程能够融入多样化和精确的摄像机运动注释,这在现实数据中很少见。
5.Anthropic:解释性研究中新的五大挑战
链接:https://transformer-circuits.pub/2024/july-update/index.html
解释性研究中面临的五大挑战,包括特征提取的不完整性、跨层超пози问题、注意力超пози问题、干扰权重问题以及从微观到宏观的理解转换问题。作者们认为,尽管存在这些挑战,但仍然有理由乐观,因为可能存在一些尚未探索的问题,这些问题可能有较低的门槛。此外,这些问题不会像以往的超no3n问题那样相互阻碍,因此可以并行攻克。
6.Tora:面向轨迹的DIT用于视频生成
链接:https://ali-videoai.github.io/tora_video/
这是第一个面向轨迹的DiT框架,同时整合了文本、视觉和轨迹条件以用于视频生成。具体而言,Tora包括轨迹提取器(TE)、时空DiT和运动引导融合器(MGF)。TE将任意轨迹编码为具有层次结构的时空运动补丁,使用3D视频压缩网络。MGF将运动补丁整合到DiT块中,以生成遵循轨迹的一致视频。我们的设计与DiT的可扩展性完美契合,可以精确控制视频内容的动态,包括不同持续时间、宽高比和分辨率。