
包阅导读总结
1. 关键词:智谱 AI、清影、视频生成、多模态、AI 普惠
2. 总结:智谱 AI 上线视频生成功能“清影”,支持文生视频、图生视频,推理速度提升 6 倍,可控性强、画面连贯,基于多模态能力推动技术发展,主打人人可用,推动 AI 普惠。
3. 主要内容:
– 智谱 AI 上线“清影”视频生成功能
– 被评为可能成为“中国 OpenAI”的企业之一
– 清影支持文生视频、图生视频,人人可用,有免费和付费使用模式
– API 同步上线,接口调用 0.5 元一次
– 清影的优势
– 推理速度提升 6 倍,生成 6s 视频理论时间 30s
– 自研技术使其可控性更强,内容更连贯,理解物理世界更好
– 能驾驭多种风格,画面质量高
– 技术支撑
– 全自研架构,从数据到算法全方位自研
– 多模态能力做底层支撑,融合文本和视频信息
– 推动 AI 普惠
– 清言+清影形成合力,提供一站式服务
– 降低非专业创作者视频创作门槛,形成生产力工具
思维导图: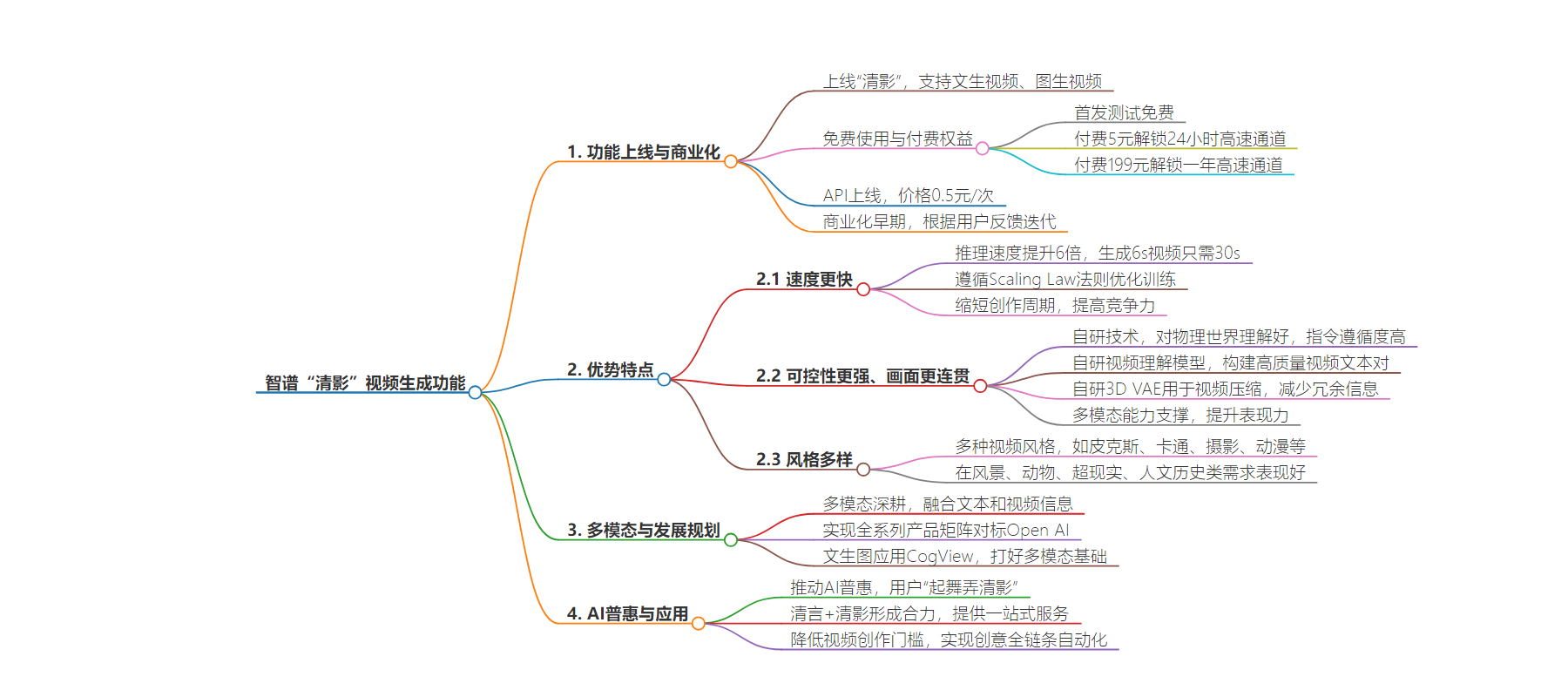
文章地址:https://mp.weixin.qq.com/s/WNRQq5vxA-Zyf6ogRm8gsg
文章来源:mp.weixin.qq.com
作者:冰拿铁
发布时间:2024/7/26 7:15
语言:中文
总字数:4525字
预计阅读时间:19分钟
评分:87分
标签:视频生成,智谱AI,多模态,商业化应用,大模型
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com


作者|冰拿铁
编辑|方奇
媒体|AI大模型工场
智谱AI再次放大招,上线AI视频生成功能“清影”——曾被国际科技媒体The Information评为最有可能成为“中国OpenAI”5家企业之一的智谱AI,如今在视频生成领域再下一城。
不同于至今没有对公众开放、“犹抱琵琶半遮面”的Sora,清影则以“人人可用”的亲民姿态,在落地应用领域“起舞弄清影”。
据悉,作为智谱清言打造的视频创作智能体,清影依托于智谱大模型团队自研打造的视频生成大模型CogVideoX,现已支持文生视频、图生视频多个能力,让用户“自助式”地完成艺术视频创作,首发测试期间,所有用户均可免费使用。同时,付费5元,可以解锁24小时的高速通道权益,付费199元,可以解锁一年的高速通道权益。
智谱AI CEO张鹏表示,现在的商业化仍处于非常早期的阶段,而且成本实际上也非常高,后面会根据市场的反馈做逐步迭代:“到时候看看用户的反馈,大家用手投票。”
如今,在PC及APP端口,“清影”支持文生视频和图生视频功能;而在“AI 动态照片小程序”中,则可以进行图生视频操作,生成时长6s、清晰度为1440×960(3:2)的视频。清影API也同步上线智谱大模型开放平台,企业和开发者通过调用API的方式,体验和使用文生视频以及图生视频的模型能力,API接口调用的价格为0.5元一次。
值得一提的是,在此前的用户吐槽视频大模型“生成速度慢得怀疑人生”、厂商纷纷卷速度的当下,通过优化技术,智谱生成式视频模型的推理速度提升了6倍。目前,生成6s视频,模型花费的理论时间是30s,解放用户的等待时间。
在此前,智谱CEO张鹏曾公开表示,在AGI的一致目标下,智谱AI与OpenAI等厂商有着相似的技术积累阶段。而在Sora刚刚面世,技惊四座的年初,张鹏则表示,对于Sora的出现,他并不吃惊,因为立足多模态领域的深耕,智谱也正在做这件事。
如今,“清影”面世,让外界看到了智谱在视频生成领域的阶段性成果。而“人人可用”的开放姿态,也让没有视频制作基础的小白用户及内容创作者借用大模型能力实现视频创作,也进一步推动AI普惠风。
智谱“清影”上线:
速度更快、更为可控、画面更连贯
速度上,智谱生成式视频模型的推理速度提升了6倍,生成6s视频只需花费30s,这意味着更快的创作周期、更高的实时性、更流畅的生成,以及即时反馈下用户体验的大幅提升。
速度更快的背后,是Sora验证了Scalling Law的可行性后,智谱遵循Scaling Law法则,不断在训练阶段优化,通过不断增加数据量、提升模型容量、增强算力支持,在速度上卷出新高度。
这在大模型落地成为最终向度的当下,为清影日后推向更广泛的应用场景打好了地基。正如中信证券在研报中指出,在生成式AI的诸多发展方向中,文生图、文生视频有望率先迎来商业化落地。
而在影视制作、广告制作、游戏开发等需要生成大量视频内容的场景,推理速度的提升意味着创作者可以更快地看到生成结果,从而缩短整个创作周期,有助于加快产品上市速度,提高市场竞争力。
与此同时,基于自研技术,智谱AI可控性更强,生成内容更连贯,对物理世界的理解更好,能够更准确地响应和遵循用户的指令、要求和偏好。这意味着智谱AI画面质量更高、能驾驭的风格更广,可以满足用户对场景、角色、动作、情感等多方的细节期望。
如何实现这一点?这离不开智谱全自研架构的底色——从创立之初,智谱就“自研以明志”,从数据到训练集群运维再到核心算法,都实现了全方位的自研。
在视频生成领域,智谱自研的视频理解模型用于为视频数据生成高度吻合的文本描述,进而构建了海量的高质量视频文本对,使得训练出的模型指令遵循度高。
比如,输入指令“猴子打工”,可以看到智谱对“猴子”主体和“打工”行为理解都十分到位,生成了让打工人心酸的一幕,带有超现实色彩又符合“细节真实”宗旨:
此外,高质量的视频文本对还能够帮助模型学习到更丰富的视频内容和文本描述之间的关联关系,从而提升模型的泛化能力。也就是说,模型在面对未知或复杂的视频数据时,也能够生成较为准确的文本描述或视频内容。
比如,让卡皮巴拉喝可乐,大模型“虽不理解但能完美执行”,生成的卡比巴拉煞有介事地喝着可乐,丝毫没有违和感:
这也让清影能够驾驭多种复杂风格及具备一定理解难度的细节。具体而言,清影在风景、动物、超现实、人文历史类需求上表现更好,且能驾驭皮克斯风格、卡通风格、摄影风格、动漫风格等多种视频风格,上演视频生成领域的“百变大咖秀”。
比如,阳光森林中超自然的光线与风景实感:
媲美皮克斯大片的粉红怪物卡通形象:
让人魂穿哈利波特世界的魔法少女,精致到发丝、眼神和超绝氛围感:
一键生成“瞬息全宇宙”的好莱坞大片:
与此同时,智谱AI自研了一个重建保真度高、画面流程度高的3D VAE,用于训练时的视频压缩,大幅减少冗余信息,使其生成内容连贯性更强。
比如,输入“蘑菇变小熊”指令,这一过程无比丝滑:
作为是一种深度学习模型,3D VAE在传统VAE的基础上进行了扩展,以处理三维数据。值得一提的是,3D VAE特别适用于处理如三维图像、点云等三维数据,能够更有效地捕捉三维数据的复杂性和空间结构,这也最终让其生成的内容有“行云流水,一气呵成”之感。
而再往深处剖析,清影多方面强大的表现力背后,是智谱多模态能力做底层支撑。
此前,智谱AI在行业已然秀出多模态肌肉,其扩展的多模态模型GLM-4V-9B能够很好地融合文本和视觉模态,性能比肩GPT-4V。如今,在视频生成领域,智谱立足多模态能力,再次实现“一举爆破”,推动技术天花板升维。
立足多模态能力,智谱补齐视频生成版图
智谱在多模态领域深耕已久。实现全系列产品矩阵对标 Open AI 是智谱大模型系列产品布局的一贯目标,而多模态在其中扮演着重要角色。
拿此次模型结构来说,智谱设计了一个高效利用模型参数将文本信息和视频信息进行混合的transformer架构。通过深度融合文本和视频信息,模型能够更准确地理解用户的意图和需求,从而生成与用户期望一致性更高的视频内容,对在实操中满足用户个性化需求、提高用户满意度具有重要意义,促进艺术与AI技术的融合。
同时,这一架构的设计意味着模型参数在融合文本和视频信息时的高效利用,在保证生成质量的同时,提高模型的运行效率和可扩展性。
这让行业想起,Sora面世时,张鹏曾分析道,Sora本身是多模态模型一个非常顶尖的成果。它不仅仅是一个独立的模型和产品,更值得思考的是,它背后代表的意义到底是什么。
大语言模型的飞速发展,代表着人类从语言层面上突破了认知能力的极限。在语言层面上,它已经非常接近甚至在某些方面已经超过了人。但是在现实世界,语言之下还有一些叫做low level的数据,比如视觉信号、声音信号、机器人控制信号等——大模型本质上解决的是打通高度抽象的知识和low level的信号。
“多模态是AGI的起点,如果要走上AGI这条路,只停留在语言这个层面是不够的,一定要以高度抽象的认知能力为核心,把视觉、听觉等一系列模态的认知能力融合在一起。“我们仍然会按照我们的步调、我们对这件事情的认知,一步步地去实现AGI。”张鹏如是说。
正因如此,面向AGI目标,智谱对整体的发展规划非常清晰,并有条不紊地推进多模态产品矩阵全面成型。在智谱2024年1月发布的全新模型系列里面,很重要的一项就是文生图应用CogView,这在行业看来,是其打好多模态基础的重要布局。
视频本质上是一系列连续播放的二维图像的集合。因此,生成高质量的二维图像是制作高质量视频的基础。每一帧图像的质量直接影响到整个视频的视觉效果和观感。随着视频内容的丰富和需求的增加,对图像技术的要求也不断提高,为了制作更逼真的特效或动画,需要发展更先进的图像合成、渲染等技术。
正如张鹏指出,生成视频和生成二维图像之间是紧密不可分割的,生成更高质量的、更能够体现人的意图的图像是视频传输的第一步。智谱的布局,正体现了多模态领域由点到线、由线到面的全面开花。如今,以多模态为根基,智谱补齐视频生成版图,并通向AGI这一终极“众妙之门”。
AI普惠风吹,用户“起舞弄清影”
当下,智谱遵循Scaling Law不断卷出新高度,让外界看到了大模型技术上更多可能性:AI技术并未遭遇增长瓶颈,且依旧在突飞猛进地发展。这意味着用户可通过MaaS大模型开放平台体验智谱大模型强大能力,通过技术创新满足更多场景需求,解决成本和收益的平衡问题,实现客户价值的持续升级。
而主打人人可用,则进一步推动大模型落地,并在落地中进一步进化,推动AI普惠风吹至视频生成领域。如张鹏曾感慨:
“应该打造尽可能拓展用户想象力的产品,基于大模型的技术为用户提供优质的服务和全新的体验,把用户的想象力切实化作生产力,这是我们对想象力必答题的回答。”
在回答时代需求后,智谱“言出法随”——随着清影落地,“清言+清影”打出组合拳,将进一步成为可用性强的生产力工具。
此前,智谱AI曾展示AI创意作品《清言画册》首刊,这本主题为“清”的AI画册,展现出清言App强大的绘图能力。观众可以通过清言画册小程序观看画卷,并可一键绘制同款。
此外,GLM-4问世以来,已经有超过30万个智能体在清言的智能体中心内,其中包括了文档助手、日程安排等生产力工具;而据智谱披露,目前在MaaS平台上,日调用量已超过400亿tokens,拥有30万企业级服务客户。
如今,基于清言最齐的内容创作工具,“清言+清影”汇流,形成“1+1大于2”的合力,以提供一站式服务,打通了视频生成创意全链条:在材料收集的选题环节,可以利用AI搜索资料,而在脚本撰写环节,可以使用AI写文案……再到图片、视频创作及推广环节,都可实现“自动化生产”。
对于非专业创作者或小型团队而言,这大大降低了视频创作的门槛,并有助于其更好地把握创作节奏,即使没有专业的编剧、设计师或剪辑师,也能通过“清言+清影”创作出高质量的视频内容,真正做到在AI领域“起舞弄清影”。

■ 商汤日日新、腾讯,昆仑万维 ▍ 金融大模型案例
■ 盘古大模型,中国电信,医联▍医疗大模型案例
■阅文大模型,腾讯音乐大模型▍ 文娱大模型案例
■知乎,360大模型,火山引擎▍ 教育大模型案例
■ 网易,金山办公大模型 ▍ 更多行业大模型案例
上次介绍从“卖铲子”到“造金矿”:AI Infra成为大模型应用背后的最大赢家?


本文由大模型领域垂直媒体「AI大模型工场」
原创出品,未经许可,请勿转载。
/
欢迎提供新的大模型商业化落地思路