
包阅导读总结
1. 关键词:OpenAI、语言模型、自然语言处理、资料稀疏、近似模型
2. 总结:OpenAI 超级对齐团队相关,提到语言模型在自然语言处理多方面应用,存在资料稀疏问题导致估算字串机率困难,因此使用近似的平滑 n 元语法模型。
3. 主要内容:
– 语言模型常用于自然语言处理的多个应用,如语音识别、机器翻译等。
– 字词与句子任意组合,训练的语言模型会出现未见过的字串,产生资料稀疏问题。
– 资料稀疏使得在语料库中估算字串机率困难。
– 正因如此,要使用近似的平滑 n 元语法(N-gram)模型。
思维导图: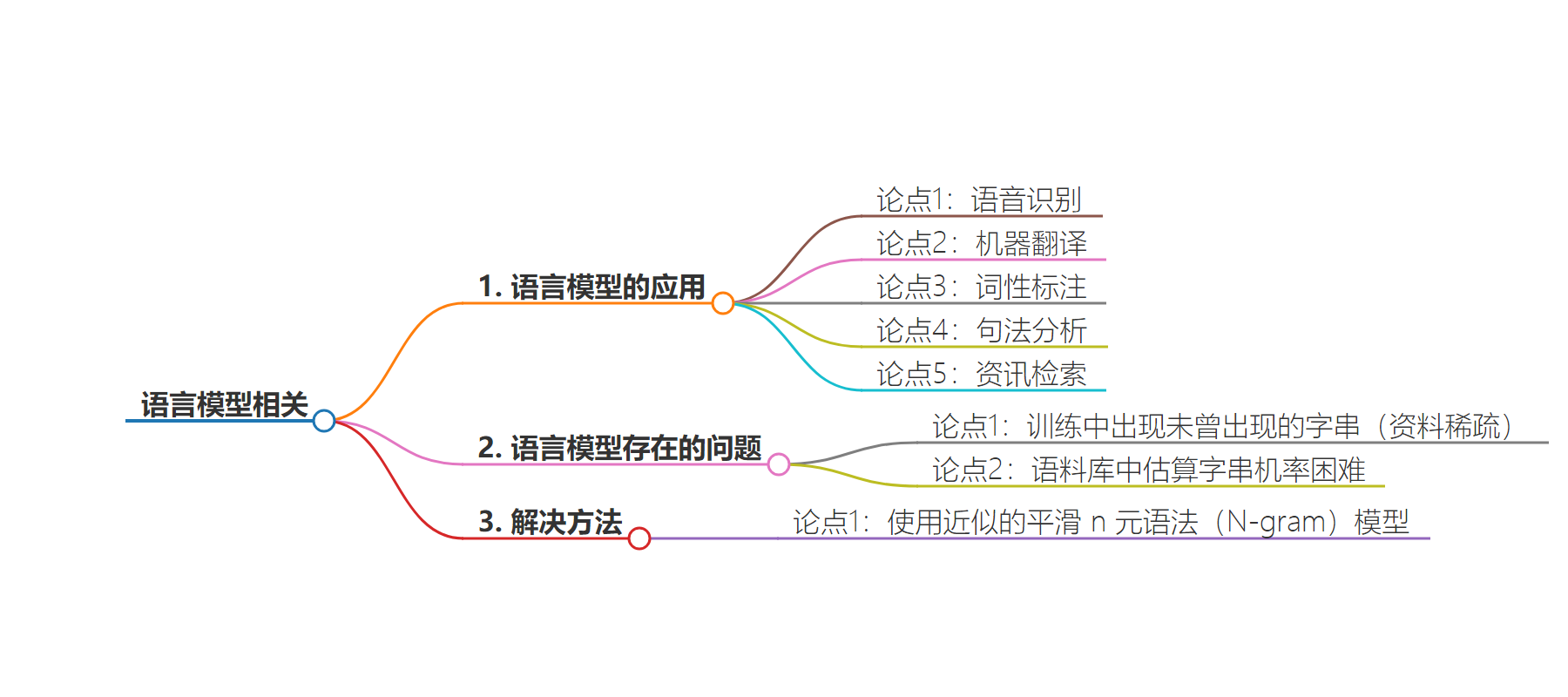
文章地址:https://www.jiqizhixin.com/articles/2024-07-18-6
文章来源:jiqizhixin.com
作者:机器之心
发布时间:2024/7/18 6:36
语言:中文
总字数:2636字
预计阅读时间:11分钟
评分:91分
标签:大型语言模型,可读性,AI 透明度,验证者-证明者博弈,OpenAI
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
语言模型经常使用在许多自然语言处理方面的应用,如语音识别,机器翻译,词性标注,句法分析和资讯检索。由于字词与句子都是任意组合的长度,因此在训练过的语言模型中会出现未曾出现的字串(资料稀疏的问题),也使得在语料库中估算字串的机率变得很困难,这也是要使用近似的平滑n元语法(N-gram)模型之原因。