包阅导读总结
1. 关键词:音视频分割、多模态、注意力网络、特征融合、应用价值
2. 总结:英国帝国理工学院研究人员基于前人工作,提出用于音视频分割任务的渐进置信掩码注意力网络(PCMANet),能更好融合音频与视频图像信息,节省计算资源,在实验中表现出色,有广泛应用价值。
3. 主要内容:
– 背景
– 机器学习从单模态向多模态发展,多模态任务分同质和异质两类。
– 音视频多模态研究相对匮乏,此前音视频任务多基于非监督或半监督方法。
– 研究内容
– 提出针对音视频分割任务的网络结构PCMANet。
– 借鉴音源定位任务方法,提出音视频分组注意力模块进行初步融合。
– 提出选择性查询的交叉注意力机制,使用置信度引导的掩码方式加速计算。
– 用引导融合模块整合特征并输出最终分割图,采用多级监督优化。
– 研究成果
– PCMANet在实验中超过Baseline达先进水平,计算资源消耗少,推理速度快。
– 消融和可视化实验证明模块有效性。
– 应用价值
– 用于视频编辑制作、多媒体搜索管理、虚拟现实与增强现实等。
– 后续研究
– 借鉴大模型多模态融合方式,用扩散模型进行分割。
思维导图: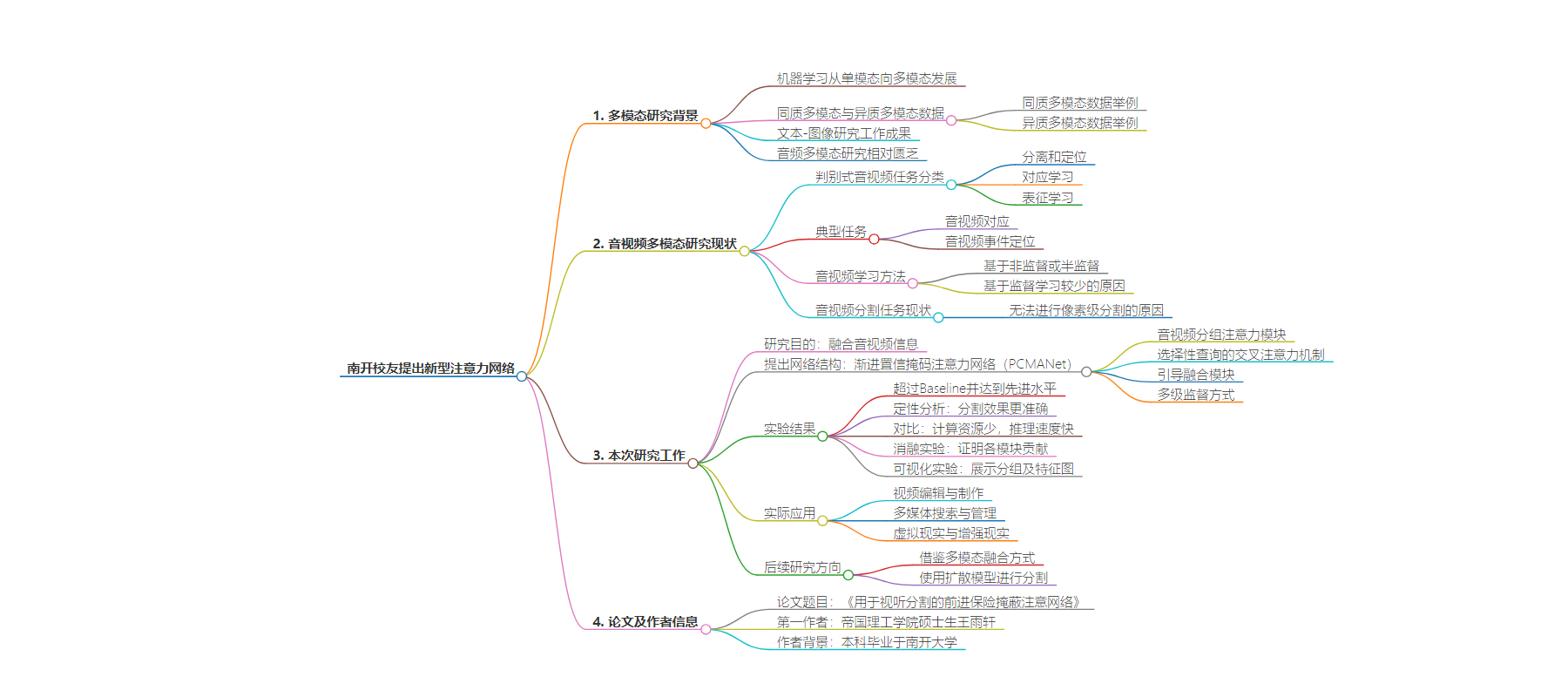
文章地址:https://mp.weixin.qq.com/s/6Y51-K2pQ0aW3o-Oz5t7Cg
文章来源:mp.weixin.qq.com
作者:DeepTech深科技
发布时间:2024/8/11 6:06
语言:中文
总字数:3124字
预计阅读时间:13分钟
评分:87分
标签:音视频分割,多模态学习,注意力网络,视频后期制作,多媒体搜索
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
南开校友提出新型注意力网络,能用于视频后期制作和多媒体搜索
众所周知,人类感知世界的方式是多维的,包括视觉、听觉、语言等多种模态。
而在目前,机器学习的研究方向也逐渐从单一模态向多模态发展。
作为现今最热门的机器学习方法,深度学习凭借强大的特征提取和处理能力,在各类多模态任务上达到了最先进水平。
同质多模态数据,拥有相同的分布。例如视觉中的“深度”或“热成像”,以及医学中的计算机断层扫描(CT,Computed Tomography)与核磁共振(MR,Magnetic Resonance)等。
异质多模态数据,其呈现出不同的分布规律,典型的例子便是文本-图像。
在已有的文本-图像研究工作中,包含有特征学习、图像描述、文本引导的语义分割、以及 Stable Diffusion 等生成模型。
然而,音频作为另一大重要的模态,针对它的多模态研究则相对匮乏。
在此背景下,英国帝国理工学院的研究人员开展了一项研究,旨在探索音视频的多模态分割任务。
在自然界中,视觉信号和音频信号往往是同时出现的。对于人类而言,我们的大脑能将图像信号和音频信号联系和同步起来。
例如,当我们听到吉他声,我们会认为是有人拿着吉他、而不是坐在钢琴前。
对于计算机来说,要想实现这种功能则需要特殊的模型和训练。此前,有学者将判别式的音视频任务分为 3 类:分离和定位、对应学习、表征学习[1]。
其中一个典型的任务是音视频对应,它能判断一段音频与一段视频帧是否是对应的。
另一个典型任务是音视频事件定位,即定位某一个事件在视频中的时间与空间位置。
在互联网上,每天都有许多视频被上传到各个平台,这些视频数据大多都是天然同步的。也就是说,这些视频的每一帧的图像和每一段音频往往是对应的。
因此,目前的音视频学习主要基于非监督或半监督的方法。相反,基于监督学习的方法相对较少。
主要原因在于:网络视频质量参差不齐,当进行标注时需要较高的时间成本和人力成本。
正是由于缺少标注数据集、以及缺少相应的监督学习模型,目前的音视频任务只能做到区域级的定位,无法进行像素级的分割。
2022 年,有学者提出音视频分割任务和音视频语义分割任务的方法[2][3],并发布了第一个音视频分割的基准监督数据集和音视频分割的基线模型。
音视频分割与音视频语义分割任务的主要目的,在于分割场景中的发声物体。
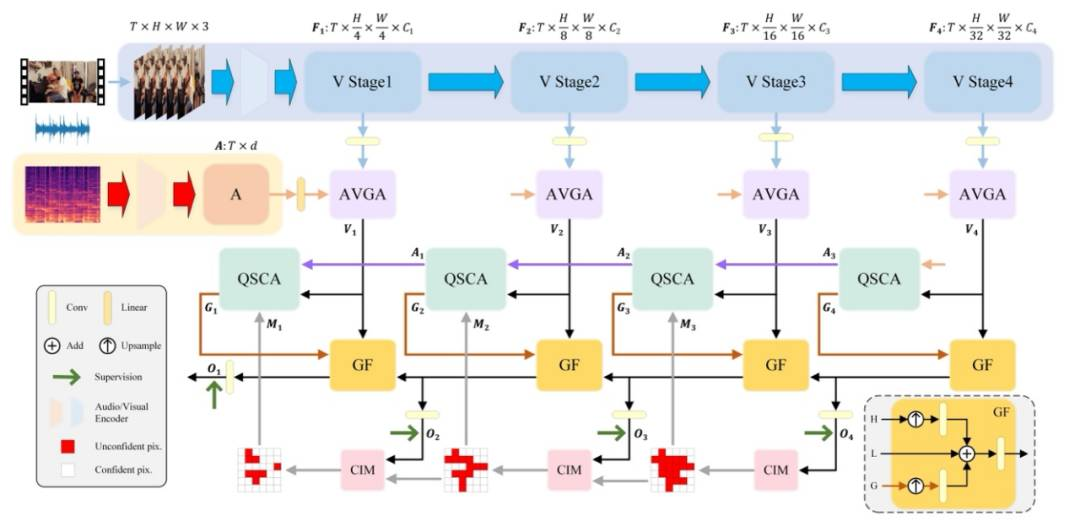
而本次研究则基于上述前人工作,提出了针对音视频分割任务的网络结构,从而能够更好地融合音频与视频图像信息。
进而可以节省更多的计算资源,并能更充分地利用多层级的特征。
研究人员表示,音视频任务的关键在于——如何有效融合两种不同模态的信息。
尽管音频与视频的数据分布存在差异,它们之间仍有内在的关联。因此,通过设计网络结构以便挖掘潜在联系并进行有效融合,是本次研究的核心问题。
对于音视频分割任务来说,需要弄清楚如何让音频去引导图像生成对应发声物体的分割图。
如前所述,音视频分割与音视频语义分割,是全球第一个音视频分割的监督数据集。
为了与其结果进行对比,课题组采用了与之相同的音频和图像的特征提取方法。
在此基础上,他们针对特征融合和后续解码过程进行改进与优化,提出了渐进置信掩码注意力网络(PCMANet,Progressive Confident Mask Attention Network)。
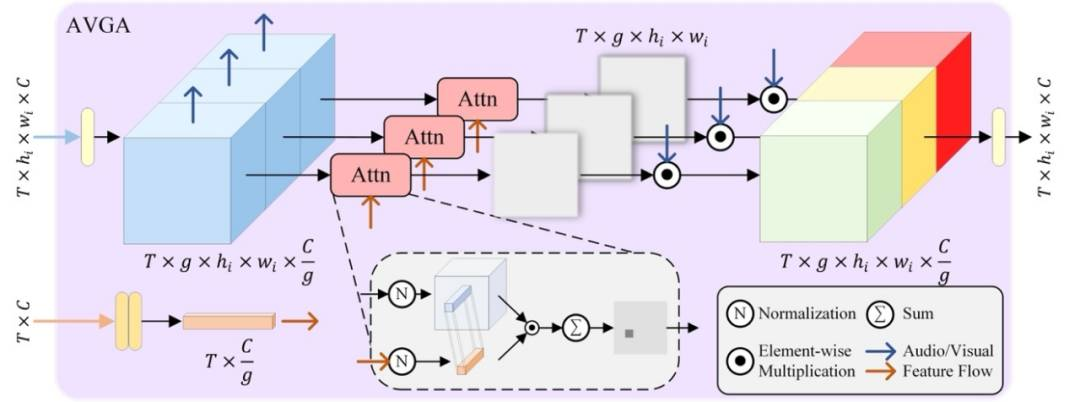
具体来说,他们借鉴了音源定位任务中的方法,提出了音视频分组注意力模块。
音源定位任务与音视频分割任务类似,区别在于音源定位是区域级的定位,通常通过热力图进行输出。
而音视频分割是像素级的分割,可以直接输出像素级的分割结果。
在音源定位中,曾有学者使用图像与音频的注意力结果,以便融合图像信息与音频信息。
本次团队在上述基础之上,进一步将图像特征分组,让图像特征与音频信息进行注意力计算,从而让网络更关注那些与音频信息匹配的部分。
而为了生成最终的分割结果,还需要进一步让音频引导图像。
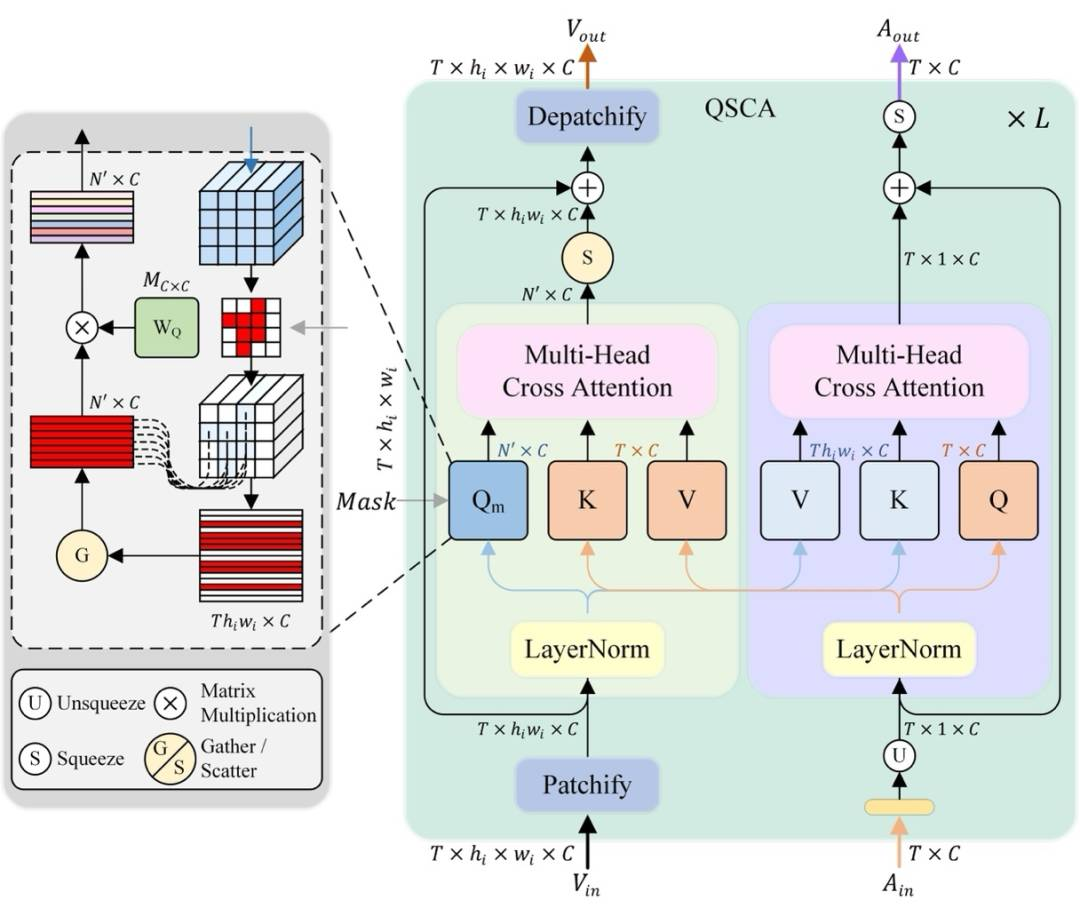
基于各类注意力机制,他们提出了选择性查询的交叉注意力机制,以用于图像和音频特征之间的交叉注意力计算。
与普通的交叉注意力机制不同的是,该团队使用了一种 Query 选择的方式,借此将不重要的 Query 去掉,进而加速了计算过程。
分割图像的置信度,是上述选择的标准。具体来说,他们设计了置信度引导的掩码方式。
通过置信度引导的掩码方式,能对所生成的 Sigmoid 分割图进行掩码处理,将置信度低于阈值的像素置为 1,其余置为 0。
这样一来就能保留不确定的像素,而置信度足够高的部分则不会生成 Query,从而能够减少计算量。
同时,这种设置可以让网络更侧重于不确定区域的优化,进而得到更好的结果。
同时,研究人员通过使用引导融合模块,来整合特征并输出最终的分割图。
为了更好地引导置信度引导的掩码方式掩码的生成,他们采用多级监督的方式,来对每个层级的输出进行监督和优化。
在完成网络设计之后,他们开展了音视频二分割和音视频语义分割任务的实验。
结果表明,PCMANet 在各个数据集和评价标准上都超过 Baseline 并达到了最先进水平。
在定性分析中,他们发现对比其他方法,本次方法拥有更准确的分割效果。
同时,他们还对比了模型的参数与推理速度,结果表明本次方法所消耗的计算资源更少,推理速度更快。
在消融实验中,他们证明了各个模块对于最终的结果的贡献。
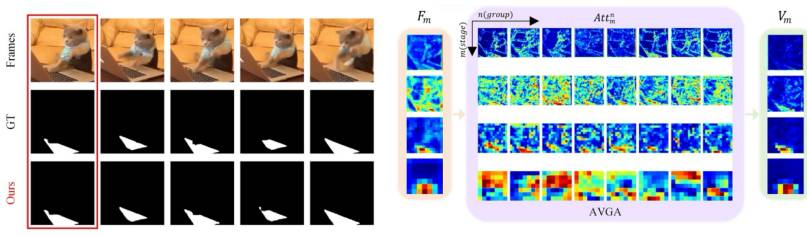
在可视化实验中,他们展示了音视频分组注意力模块中各个分组以及输入输出的特征图。
结果显示:音视频分组注意力模块能让音频信号和图像特征进行匹配,减少无关物体的权重,突出发声物体的区域,进而说明了音视频分组注意力模块的有效性。
日前,相关论文以《用于视听分割的前进保险掩蔽注意网络》(Progressive Confident Masking Attention Network for Audio-Visual Segmentation)为题发在 arXiv[4]。
总的来说,本次研究侧重于音视频分割任务,所提出的音视频特征融合的方法,能被进一步迁移到其他音视频下游任务。
此外,音视频分割模型也有广泛的实际应用价值,例如它可以用于视频的编辑与制作,利用音频引导视频中不同元素的检测与分割,从而实现识别与分离,进而简化视频的后期制作。
还可以用于多媒体搜索与管理,从而实现对视频内容进行标注与索引。
在虚拟现实(VR,Virtual Reality)与增强现实(AR,Augmented Reality)方面,音视频分割技术可以进行更精细的场景划分,进一步提升用户体验等等。
下一步,课题组一方面将借鉴各类大模型的多模态融合方式,更好地将音频信息融入到图像特征中。
另一方面将使用扩散模型(Diffusion Models)进行分割,即通过嵌入的方式将音频作为条件提示,从而引导去噪的过程。
另据悉,王雨轩本科毕业于南开大学,目前是英国帝国理工学院的一名在读研究生,主要研究多模态、扩散模型及其轻量化与加速、以及扩散模型的医学反事实图像生成等。
1. Zhu H, Luo MD, Wang R, Zheng AH, He R. Deep audio-visual learning: A survey. International Journal of Automation and Computing. 2021 Jun;18(3):351-76.
2. Zhou J, Wang J, Zhang J, Sun W, Zhang J, Birchfield S, Guo D, Kong L, Wang M, Zhong Y. Audio–visual segmentation. InEuropean Conference on Computer Vision 2022 Oct 22 (pp. 386-403). Cham: Springer Nature Switzerland.
3. Zhou J, Shen X, Wang J, Zhang J, Sun W, Zhang J, Birchfield S, Guo D, Kong L, Wang M, Zhong Y. Audio-visual segmentation with semantics.arXiv:2301.13190. 2023 Jan 30.
4. Wang Y, Dong F, Zhu J. Progressive Confident Masking Attention Network for Audio-Visual Segmentation.arXiv:2406.02345. 2024 Jun 4.
排版:刘雅坤

01/将甲醇选择性提高8倍,科学家实现电催化二氧化碳还原,已着手搭建商业级反应器
02/华人学者专注空间多组学,首次实现空间表观遗传分析,或开辟一条全新的疾病治疗途径
03/突破电计算离线建模的束缚:清华团队提出新型光计算架构,光训练速度提升1个数量级
04/科学家开创丙烯高效分离新路径,揭示门控大环晶体的化学分离能力,有望替代传统低温蒸馏法
05/科学家提出新型陶瓷理论和技术,助力解决全球能源挑战
预览时标签不可点
![]()
微信扫一扫
关注该公众号
![]()
微信扫一扫
使用小程序
:,。视频小程序赞,轻点两下取消赞在看,轻点两下取消在看分享收藏