
包阅导读总结
1. 文生视频、香港大学、T2V-CompBench、组合性、模型评估
2. 香港大学发布文生视频基准 T2V-CompBench,引入“组合性”概念评估 20 个模型。虽文生视频发展迅速,但处理复杂场景仍有不足,此基准有助于模型优化,未来或有大模型生成的电影。
3.
– 文生视频发展相对滞后
– 原因包括需考虑更多维度、计算资源需求大、数据稀缺、缺乏评估标准
– 香港大学的 T2V-CompBench 基准测试
– 涵盖 7 个类别,借助 GPT-4 生成 700 个文本提示
– 经过人工验证并生成元数据
– 模型评估
– 对 13 个开源和 7 个商业模型评估
– 采用多种指标,新指标在部分类别表现优于传统指标
– 商业模型整体表现较好,所有模型处理复杂场景有挑战
– 动态属性绑定和生成数字最难,空间关系等也有难度
– 此基准有助于模型针对优化,期待大模型生成的电影
思维导图: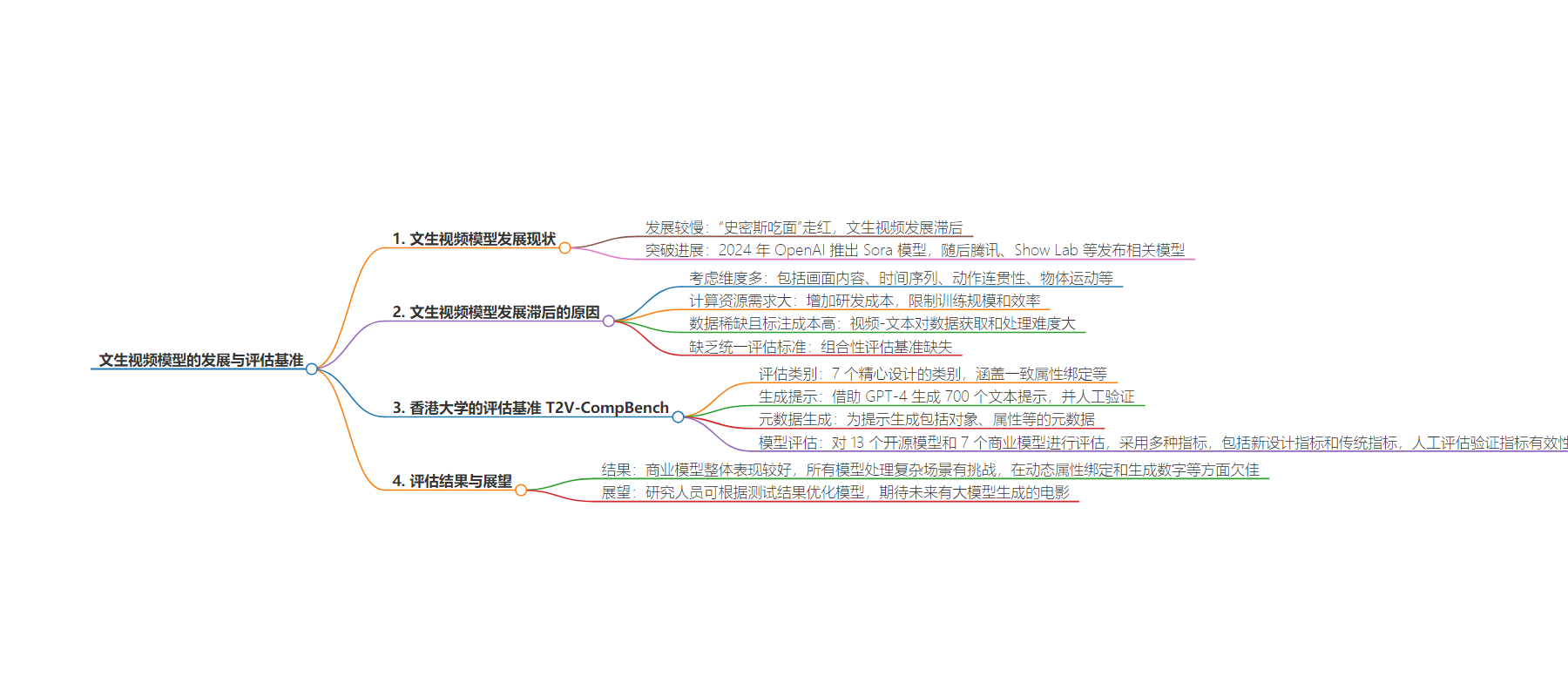
文章地址:https://mp.weixin.qq.com/s/QAN0uP3ulFFfazaE3VB2IA
文章来源:mp.weixin.qq.com
作者:Richard
发布时间:2024/8/13 6:05
语言:中文
总字数:2258字
预计阅读时间:10分钟
评分:91分
标签:文生视频,组合性评估,大模型,香港大学,视频生成
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

夕小瑶科技说 原创
作者 | Richard
相较于文本生成、文生图等领域而言,文生视频领域发展相对较慢。当年一段“史密斯吃面”的视频意外走红网络,可谓相当魔幻。

然而进入 2024 年,OpenAI 再一次给 AI界人了一个重磅炸弹 —— 文本视频大模型 Sora 横空出世,将 AI 创作的最后一块拼图也补上了。
此后,腾讯、Show Lab 等争相发布了自己的文生视频大模型。但是还没有一个基准测试全面评估这些模型的能力。
为此,香港大学的研究团队发布了名为 T2V-CompBench 的基准测试,并且首次将“组合性”这个概念引入视频生成评估中。
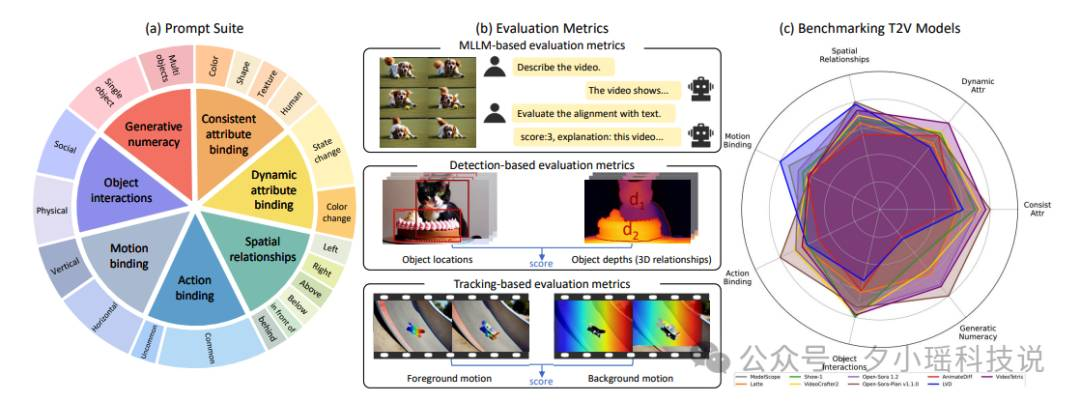
T2V-CompBench 通过 7 个精心设计的类别全面评估文生视频模型的组合性能力,包括一致属性绑定、动态属性绑定、空间关系、动作绑定、运动绑定、对象交互和生成数字。每个类别都针对视频生成中的特定组合性挑战,从静态属性的一致性到复杂的动态交互。
研究使用 T2V-CompBench 对 20 个主流视频生成模型进行全面测评。结果显示虽然文生视频技术突飞猛进,但是在处理复杂动态场景时仍然“力不从心”。
有了这个基准,文生视频可以针对现如今的一些缺陷进行优化,从而提升生成视频的质量。
如此发展下去,在 2025 年或许会出现大模型生成的电影!期待捏~
论文标题:
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation
论文链接:
https://arxiv.org/pdf/2407.14505
从“史密斯吃面”到“奥斯卡之夜”
近年来,人工智能在文生文和文生图领域取得了惊人的进展。然而,文生视频技术的发展却相对滞后,“史密斯吃面”的场景还历历在目(手动狗头)。

究其原因,小编总结如下:
-
与文生文和文生图相比,视频生成需要考虑更多维度。除了画面内容,还要处理时间序列、动作连贯性、物体运动等复杂因素。 -
生成高质量视频需要海量的计算资源。这不仅增加了研发成本,也限制了模型的训练规模和效率。 -
高质量的视频-文本对数据相对稀缺,而且标注成本高昂。相比之下,文本和图像数据更容易获取和处理。 -
缺乏统一的评估标准使得模型优化方向不明确。特别是在组合性方面,之前几乎没有专门的评估基准。
由于以上因素的限制,文生视频领域一直不温不火,直到 2024 年初,OpenAI 才退出了质量较高的文生视频大模型 —— Sora。
此后,文生视频领域大模型如雨后春笋般出现,例如港中文的 VideoTetris 以及 Pika 等。

目前的文生视频在处理复杂场景时仍然面临不少挑战,例如如何准确地将多个物体、属性和动作组合到一个连贯的视频中?这就涉及到了“组合性”的问题。
虽然组合性在文生图领域已经被广泛研究,但是在文生视频领域却鲜有人关注。现有的视频生成评估方法主要集中在视频质量和文本-视频对齐度上,忽视了组合性这一重要维度。
为此,香港大学的研究团队开发了 T2V-CompBench,专门用于评估文生视频模型组合性能力的基准测试。
通过这个基准测试,可以全面了解当前文生视频模型的优缺点,并且可以对模型的缺点针对性改进。
或许在不久将来可以看到大模型生成的影片登上奥斯卡的舞台。
T2V-CompBench 和它的 700 个Prompts
为了评估各文生图大模型的表现,香港大学研究人员设计了 T2V-CompBench。他们巧妙借助 GPT-4,生成了 700 个包罗万象的文本提示,涵盖了从“一致属性绑定”到“生成数字”等 7 大类别。
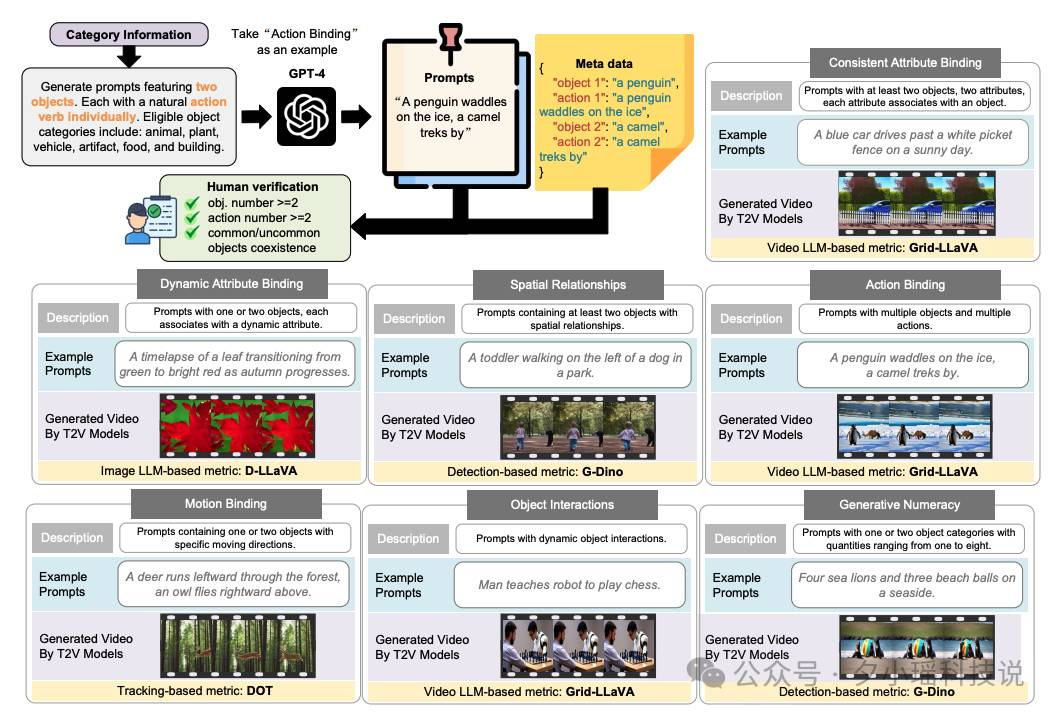
具体而言,研究团队采用一种结构化的方法生成这些提示。
首先,他们定义了每个类别的提示结构和要求,然后利用 GPT-4 生成初始提示。例如,对于动作绑定类别, GPT-4 会生成两个对象,没个对象有一个独特动作的提示。
所有生成的提示都经过人工验证,确保质量和适用性。
为了便于评估,研究人员为每个提示生成了相应的元数据。这些元数据包括提示中的关键信息,例如对象、属性、空间关系等,为后续的自动评估提供了基础。
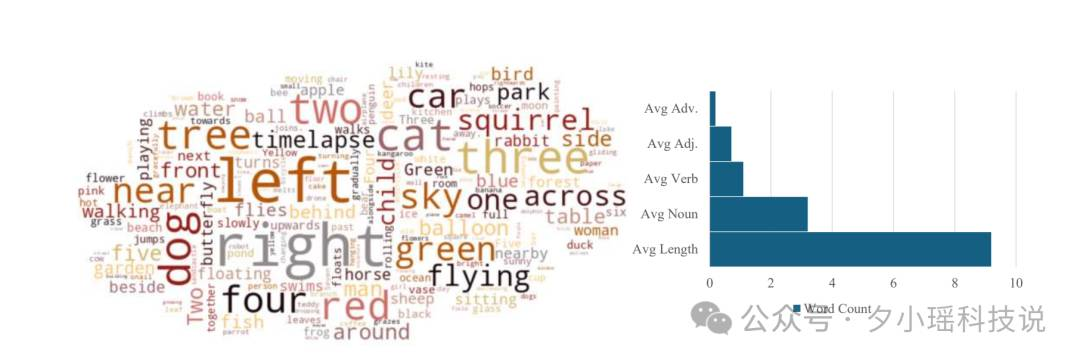
下图展示了T2V-CompBench的统计特征。词云可视化直观地展示了提示中常用词汇的分布。柱状图则详细显示了每个提示的平均组成:包括副词、形容词、动词、名词的数量以及提示的平均长度。
全方位测试文生视频模型性能
研究团队基于 T2V-CompBench 对 13 个开源模型和 7 个商业模型进行一系列评估,包括 ModelScope、ZeroScope、Latte、Show-1 等开源模型以及 Pika、Gen-2、Gen-3 等商业模型。
评估采用了多种指标,包括传统的 CLIPScore 和 BLIP-CLIP,研究人员还为本研究专门设计了新指标,这些指标分为三类:
-
基于多模态大语言模型的评估,例如 LLaVA、ImageGrid-LLaVA 等模型 -
基于目标检测的评估,例如 GroundingDINO
研究团队采用人工评估实验验证评估指标的有效性。他们随机选择了每个类别中的15个提示,并使用不同模型生成了共656个视频。这些视频由人工标注者进行评分。研究者计算了自动评估指标与人工评分之间的相关性,结果显示新设计的指标在多个类别中表现优于传统指标。
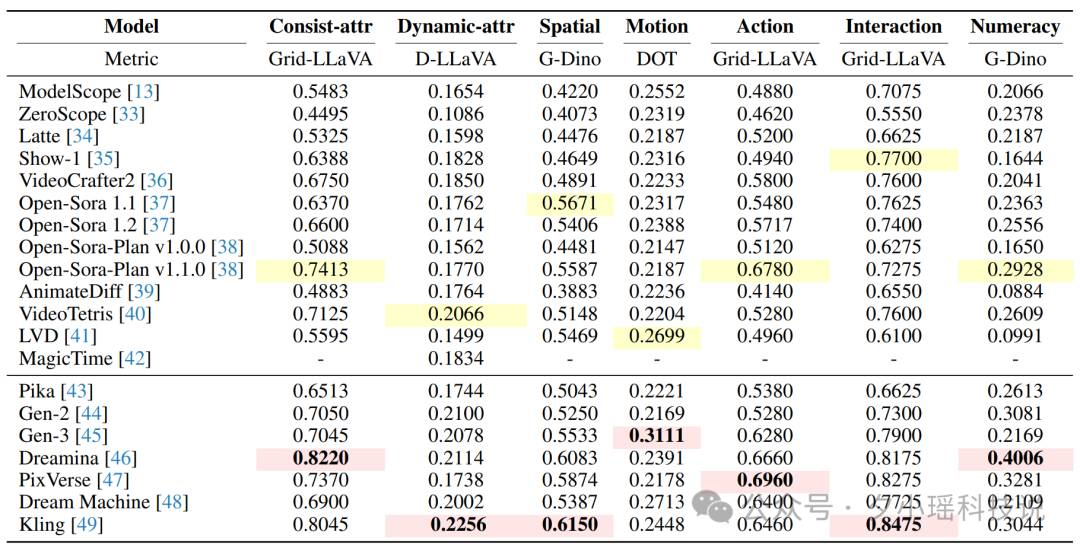
上图展示了不同模型在 7 个类别上的表现。总体而言,商业模型的表现优于开源模型。
在开源模型中,Show-1、VideoCrafter2、VideoTetris 和 Open-Sora 系列模型表现较为出色,Open-Sora-Plan v1.1.0 在多个类别中取得了最好的表现。
下图展示了不同模型在处理具有挑战性的提示时的表现。


从实验结果可以看出,动态属性绑定和生成数字是最具挑战性的任务,模型往往难以准确捕捉属性变化或生成正确数量的对象。空间关系、运动绑定和动作绑定也存在一定难度,模型经常混淆方向或无法正确关联动作与对象。
总结与展望
香港大学研究团队发布的 T2V-CompBench 对 20 个文生视频大模型进行测试,其包含 7 类 700 个文本提示。
结果显示,虽然商业模型整体表现较好,但所有模型在处理复杂场景时仍面临挑战。模型在动态属性绑定和生成数字方面表现欠佳,难以准确捕捉属性变化或生成正确数量的对象。同时,在处理空间关系、运动和动作绑定时也常出现混淆,显示出当前技术在复杂场景处理上的不足。
研究人员可以根据 T2V-CompBench 测试结果对文生视频模型针对优化,或许有一天我们可以看到由大模型生成的电影呢。


