
包阅导读总结
1. `Rust`、`Java`、`编程语言`、`内存安全`、`代码正确性`
2. 本文探讨了开发者在学习 Rust 语言时容易带入旧语言习惯,以作者自身经历为例,对比了 Rust 和 Java 的特点,强调要接受 Rust 的本质,放下过往习惯,发挥其独特魅力。
3.
– Rust 语言强调内存安全、高性能及独特所有权模型。
– 作者因对其好奇开始学习,但过程并非一帆风顺。
– 相比 Java,Rust 不是 Java,不应强行让 Rust 变得像 Java。
– Java 有编译时检查功能,大规模重构时较安心,但也非完美,存在空引用错误等问题。
– Rust 有类似 Java 接口的 Traits,但处理方式不同。
– 解决内存安全有代价,如无法轻易注入实现 Trait 的对象。
– 解决所有权问题的方法效果不太好,函数有时更适用。
– 作者强调学习 Rust 要接受其本质,转变思维方式。
思维导图: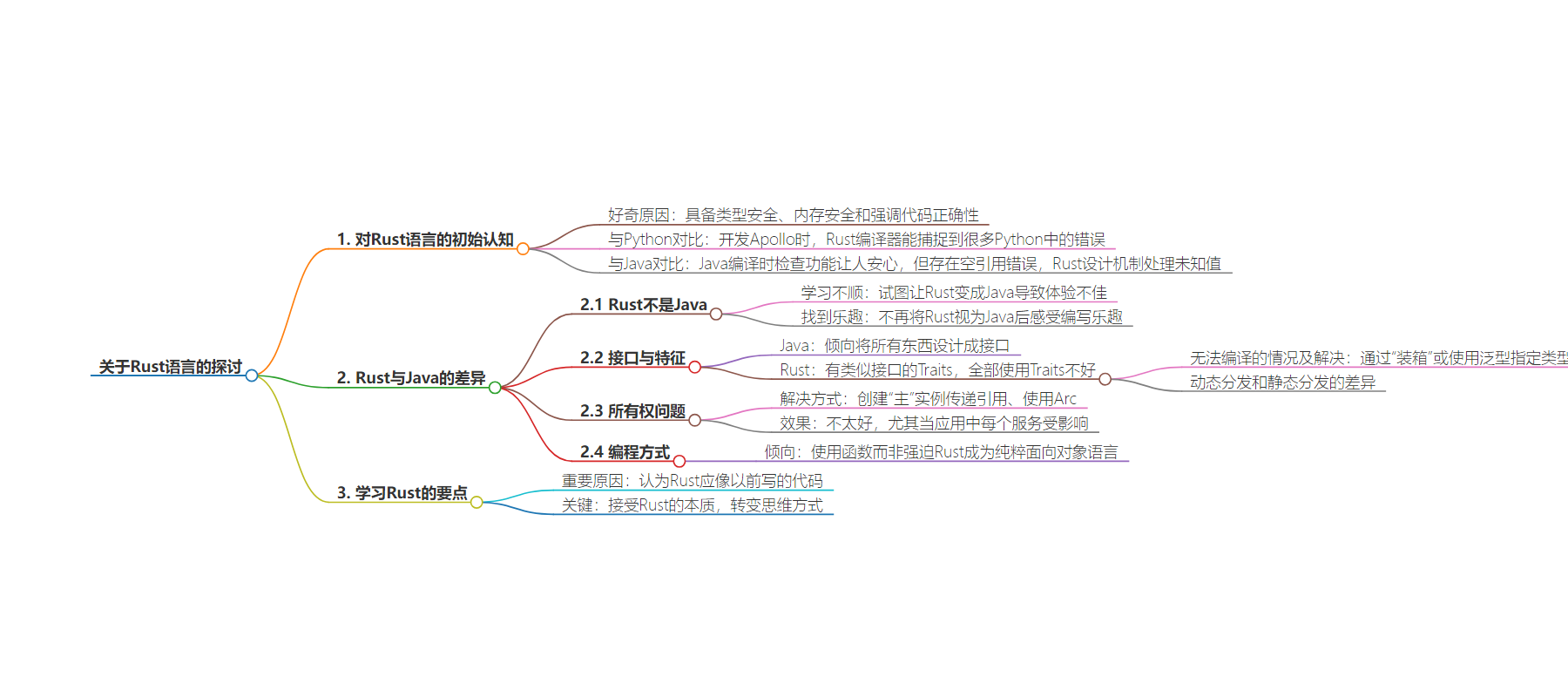
文章地址:https://mp.weixin.qq.com/s/1tgyHoHnAABiEWUjqr7b3g
文章来源:mp.weixin.qq.com
作者:CSDN
发布时间:2024/8/9 9:49
语言:中文
总字数:2255字
预计阅读时间:10分钟
评分:87分
标签:Rust,编程语言,内存安全,所有权模型,编程范式
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

【CSDN 编者按】在当今多语言并存的世界里,开发者们常常会在学习一门新语言时,不自觉地带入他们对现有语言的理解和习惯。当转向 Rust 这样一门强调内存安全、高性能且拥有独特所有权模型的语言时,这种倾向尤其明显。本文作者以自身经历出发,提出:要想真正发挥 Rust 的潜力,必须学会放下过往的习惯,拥抱 Rust 的独特魅力。
原文链接:https://jgayfer.com/dont-write-rust-like-java
我对 Rust 这门语言好奇好几年——具备类型安全、内存安全,并强调代码正确性,这样的语言怎能不让人喜爱呢?
在我开发 Apollo(一个用 Python 编写的应用)时,遇到的错误中有很大一部分是可以通过 Rust 编译器捕捉到的(虽然不能说是 100%,但也非常接近)。通常来说,编译器能捕捉到很多使用动态语言(如 Python 或 Ruby)时可能遗漏的问题,可并非所有编译器都一样出色。类型安全固然很好,但 Rust 对于代码正确性的重视才是最吸引我的地方。
最近我在工作中写了不少 Java 代码,虽然它不是我最喜欢的编程语言,但它的编译时检查功能确实让人感到安心。在 Java 中进行大规模重构时,不会像在 Python 或 Ruby 中那样令人胆战心惊,因为还有编译器会帮你。一个错误或缺失的导入语句,并不会导致程序在运行时突然崩溃,我们也通常会用测试来捕捉这类问题,但我还是要说:能把这些检查直接内置到语言中,真的非常好!
不过,Java 编译器也并非完美无缺。它无法防止某些类别的错误,其中最烦人的就是空引用错误。在 Java 中,几乎所有东西都可能为 null,而你只有在运行时才能发现这一点。相比之下,Rust 设计了一套机制来引导你处理未知的值。当然,你也可以选择忽略这些引导,但编译器还是会迫使你去那样做。
那么,Rust 会是一种更好的 Java 吗?总体来说,Rust 所承诺的一切都让我感到非常兴奋,但我的 Rust 学习之旅并非一路顺风顺水。尽管 Rust 和 Java 有些许相似之处,但它始终不是 Java——直到我不再试图让 Rust 变成 Java 之后,我才真正体验到了编写 Rust 代码的乐趣。


“一切都必须是一个接口”
虽然这种说法并不完全准确,但它确实反映了一些事实:Java 开发者倾向于将所有东西都设计成接口(我就是其中之一)。在 Java 中,使用接口很有趣,它可以让应用由一个个小的工作单元组成,而每个工作单元都不必直接了解其他单元的内部运作细节。虽然在构建依赖关系树时需要做一些前期工作,但一旦完成,你就等于拥有了一支随时听候调遣的独立服务大军。
在 Rust 中,我们没有接口,但有 Traits(特征)。它在很多方面与 Java 中的接口相似,但试图在 Rust 中将所有东西都变成 Trait 并不好玩。还记得 Rust 的一个重要特点——内存安全吗?这背后是有代价的,那就是不能轻易地“注入”实现了某个 Trait 的对象。
trait Named {fn name(&self) -> String;}struct Service {named: Named}
上述代码无法编译,因为编译器无法确定 Box<T> 的大小。为了解决这个问题,我们可以使用“装箱”(boxing)的方式来指向堆上动态分配的内存(称为 Trait 对象)。这样,Box<T> 的大小就变成了已知,从而允许我们的程序通过编译。
trait Named {fn name(&self) -> String;}struct Service {named: Box<dyn Named>}
“装箱”并不是我喜欢的模式,因为它用起来有些别扭,所以一般我会尽量避免使用这种方式。相反,我们可以使用泛型来指定 Trait 类型。
trait Named {fn name(&self) -> String;}struct Service<T: Named> {named: T}
有什么不同?乍一看,结果是一样的,不同之处在于动态分发和静态分发之间的差异。使用 Trait 对象时,具体类型是在运行时确定的;而使用泛型时,具体类型则是在编译时确定的。
在实践中,这意味着只要我们可以在编译时推断出所有类型,就可以使用泛型。如果类型直到运行时才能确定,则必须使用“装箱”(boxing)。

所有权问题如何解决?
所有权问题仍然存在。假设我们的 Trait 是应用程序中其他服务的必要依赖项怎么办?我们是创建一个“主”实例,并将其引用传递给每个依赖项,从而引入生命周期管理吗?
struct Service<'a> {named: &'a dyn Named}
还是使用 Arc,让我们的依赖服务持有一个 Arc<dyn Named>,从而允许并发访问已拥有的资源?
struct Service {named: Arc<dyn Named>}
这两种方法我都试过,也都奏效,但效果并不太好,特别是当应用中的每个服务都受到影响时。

函数也是可以使用的
强迫 Rust 成为一种纯粹的面向对象语言并不好玩。虽然我仍然会像上面的例子那样编写“服务对象”,但我尽量只在必要时才使用它们,我更倾向于使用函数。
举个例子,想一个用于处理 Stripe 结账会话完成事件的函数,该函数会更新系统中的 Stripe 客户 ID。
async fn handle_session_completed(user_repo: &mut impl UserRepo,session: &CheckoutSession,) -> anyhow::Result<()> {let user_id = session.client_reference_id.clone().context("Missing client reference ID")?;let customer_id = session.customer_id.clone().context("Missing customer ID")?;user_repo.update_stripe_customer_id(user_id, &customer_id).await?;Ok(())}
虽然我们可以将其写成一个服务,并注入一个 UserRepo 值,但这样做太过复杂。实际上也没有理由将其写成服务,因为我们仍然可以轻松地注入 UserRepo 的不同实现,例如提供一个不访问实时数据库的实现。虽然这样做的缺点是函数签名可能会变得有点复杂,但这种程度的“痛苦”与其它方案相比算不上什么。

接受 Rust 的本质
我曾深陷“Rust 很难”的困境之中,其中一个重要原因是因为我坚持认为 Rust 代码应该像我以前写的代码那样。虽然从过去的经验中汲取教训是件好事,但接受现有的编程范式对掌握一门语言而言至关重要。
学习 Rust 需要一种思维方式的转变:不要因为 Rust 不是你熟悉的样子而抗拒它,慢慢去接受它的本质。
▶堪比Windows蓝屏危机!Linux被曝12年史诗级漏洞,“投毒者”是谷歌?
▶AI时代的产品增长秘籍,2024全球产品经理大会首批演讲议题公布!
▶罗永浩5000字长文回应“五宗罪”;百度首位AI架构师上岗;苹果高级AI功能月费或高达20美元 | 极客头条

能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
