包阅导读总结
1. 关键词:AI 独角兽、模型+应用、创业公司、基础模型、价值捕获
2. 总结:谷歌等大厂收购 AI 独角兽公司,这些公司曾走模型+应用双轮驱动战略,但因训练成本高、模型贬值等原因退场,给行业带来启示,国外创业公司转向 AI 应用,而国内情况待观察。
3. 主要内容:
– 谷歌等大厂收购了 Character.AI、Inflection、Adept 等公司
– 这些公司成立早、融资多,采取模型+应用双轮驱动策略
– 早期从头预训练是唯一可行之路,ChatGPT 爆火让模型潜力凸显
– 如今模型升级成本高,模型价格下降,开源模型变强,创业公司难负担
– 国外创业公司路径清晰,转向 AI 应用,国内情况不同,仍高举产模一体大旗待观察
思维导图: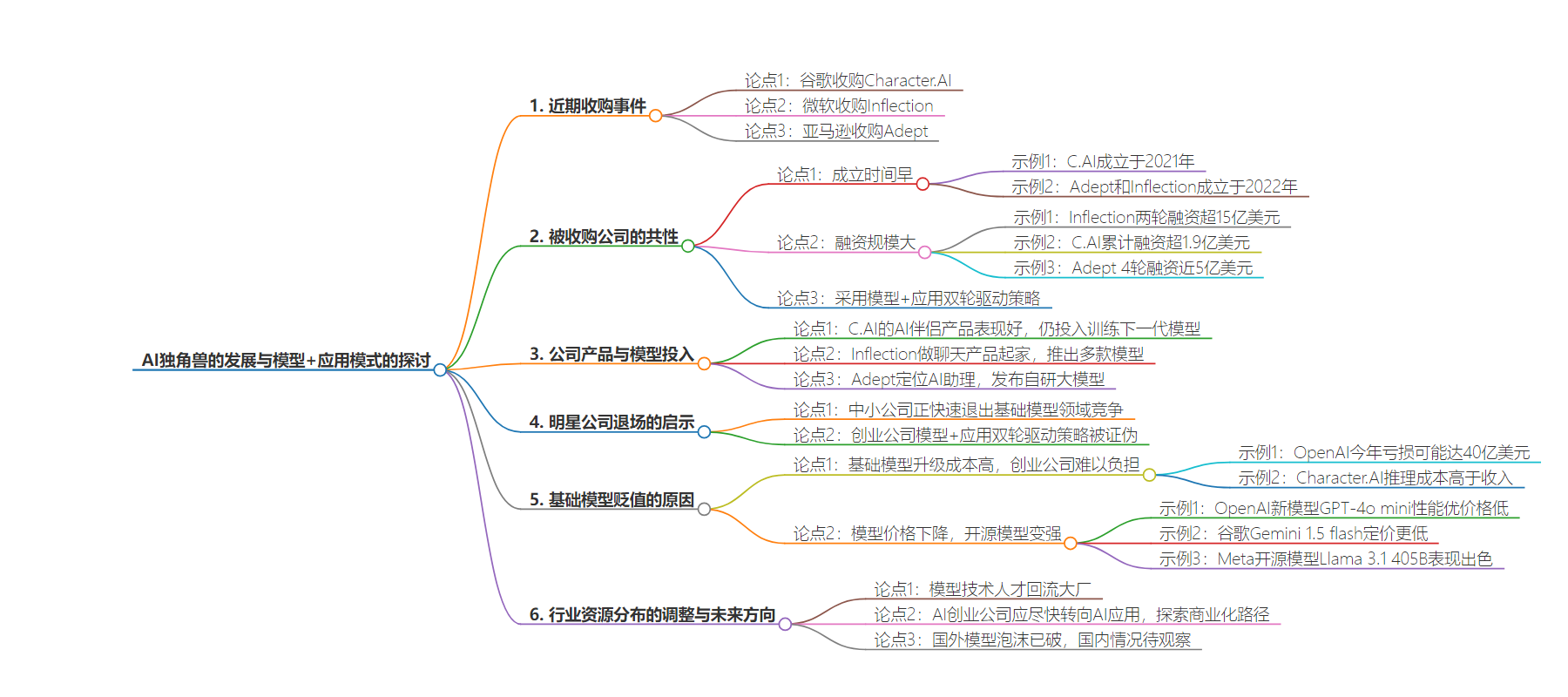
文章地址:https://mp.weixin.qq.com/s/WUPqhy09YsGIWEXOecibHw
文章来源:mp.weixin.qq.com
作者:智能乌鸦
发布时间:2024/8/10 2:54
语言:中文
总字数:2700字
预计阅读时间:11分钟
评分:86分
标签:AI初创公司,模型+应用策略,训练成本,模型贬值,开源模型
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
AI独角兽纷纷跑路,模型+应用这条路走不通了
来源丨乌鸦智能说(ID:wuyazhinengshuo)
这几天,谷歌收购Character.AI(以下简称C.AI)引发了很多讨论。
前两天,乌鸦君讲了谷歌的收购就为了买人,一个人就值1个亿。
像这样的“卖人头”式的收购,在今年上半年还有两笔,分别是:微软收购Inflection,亚马逊收购Adept。
除了人都很值钱外,这三个结局类似的公司,还有三个共同点:
他们成立的足够早,融了很多钱,走的都是模型+应用双轮驱动的战略。
这和行业当时的发展阶段有很大关系。在AI行业早期,训练成本还没那么高,市面上也没有好用的开源模型,从头预训练是唯一可行的路。加上ChatGPT的爆火,让大家看到了模型的巨大潜力。
越来越多人坚信,只有占据模型层和应用层的「全栈」公司,才有捕获最大价值的可能,也更容易拿到投资人的钱。
动辄几十亿美元的训练成本让创业公司难以负担,而模型价格下降以及开源模型的更迭,不仅让大模型迅速贬值,也让大部分押注模型的创业公司都成了先烈。
正所谓成也萧何,败也萧何。模型层的全面洗牌,也是历史的必然。随着这些创业明星的退场,也给行业带来了一个启示:
纵观C.AI、Inflection、Adept的发展,三家都有三个共性:成立的足够早,拿了很多钱,走得是模型+应用双轮驱动的策略。
先说成立时间,C.AI成立时间最早,成立于2021年,而Adept和Inflection的成立时间则都在2022年。
从融资情况看,这三家里Inflection拿的钱最多,两轮融资加起来超过15亿美元。虽然C.AI和Adept拿的钱没有Inflection多,但也在上亿美元量级,其中C.AI累计融资超过1.9亿美元,Adept 4轮融资加起来的钱接近5亿美元。
拿了这么多钱后,三家公司都选择了同一个发展策略:模型+产品双轮驱动。
C.AI、Inflection、Adept都以AI应用而为人熟知。C.AI自然不用最多说,作为AI伴侣数据跑得最好的产品,6月C.AI的访问量高居行业第四。
Inflection最早也是做聊天产品起家。2023年5月,Inflection 发布了AI聊天产品Pi。与ChatGPT相比,Pi主打一个私人、走心。Pi在X官方账号上的介绍是:Pi,你的私人AI,有什么心事吗?我们来谈谈吧!
Adept的产品定位则是AI助理。简单来说,Adept希望构建一个全新的操作系统或平台,让人们使用电脑更加“傻瓜式”,只需一个指令,其余所有步骤和事情它都可以帮忙完成,而不是像ChatGPT那样一来一回的问答。
在做AI应用的同时,他们还把大量的钱投到了模型上面。
虽然C.AI产品表现得很好,但创始人Noam仍然将C.AI 定位为一家通用模型公司,要为每个人提供个性化的超级智能。所以,C.AI花了很多资源在训练下一代模型,提升模型质量。
卖身前,Inflection也曾推出过三款模型,其中最先进的模型Inflection AI-2.5甚至接近GPT-4的性能。
2022年9月,Adept曾发布自研大模型Action Transformer(ACT-1)。2024年1月,Adept 又发布了多模态大型语言模型Fuyu-Heavy,进一步提升了在文本和图像处理上的综合分析能力。
而这些花了很多钱的模型技术,也跟着核心团队被大厂收走了。随着核心团队和模型技术的离去,也宣告了这些明星公司的退场。
中小公司正在快速退出基础模型领域的竞争,创业公司模型+应用双轮驱动的策略正在被证伪。
虽然从现在看,创业公司自研大模型并不明智。但就当时来说,这个选择也没什么问题。
一来,他们成立得足够早,彼时没有像llama这样的开源模型可供选择,训练成本也没有夸张到现在的程度,从头预训练是唯一可行的路。
二来,随着ChatGPT的爆火,OpenAI开始全面进军应用层,不仅布局了插件生态,还做上了移动端应用,把不甘于只做API提供商的野心尽数展现。不仅对Jasper等AI应用造成了不小冲击,也让大家看到了模型公司的巨大潜力。
从那时候起,大家都有一个判断:在大模型面前,AI应用的商业壁垒有限。只有占据模型层和应用层的「全栈」公司,才有捕获最大价值的可能。
除了上面被收购的三家公司外,很多应用公司也开始布局模型层,其中就包括了受到ChatGPT冲击的AI写作公司Jasper。
但是一年后,这些创业公司发现:模型+应用双轮驱动不是所有人都能玩的。
一方面,现在基础模型升级的成本越来越高。日前,The Information爆出,OpenAI今年的亏损可能达到40亿美元,不算15亿美元的员工成本,光花在训练上的成本就有30亿美元。这意味着,除了头部模型公司有大厂撑腰外,其他厂商完全跟不住。
根据此前计算,Character.AI每月的推理成本在330万美元左右,一年在4000万美元。而去年全年,Character.AI的全年收入也只有区区1520万美元。也就是说,AI应用挣的钱连推理成本都覆盖不了,更别提更高昂的训练成本。
另一方面,随着模型价格不断下降,以及开源模型越来越强,大模型正在迅速贬值。
7月,OpenAI 突然上线新模型 GPT-4o mini,在性能全面碾压GPT-3.5 Turbo的同时,价格还比GPT-3.5 Turbo便宜了60%以上。不久前,谷歌又把Gemini 1.5 flash定价降低至GPT-4o mini的一半。
在闭源模型越来越便宜的同时,开源模型的能力也在变强。7月,Meta发布了开源模型Llama 3.1 405B,这个模型在多项测试的表现都好于GPT-4o和Claude 3.5 Sonnet。
这意味着,AI应用的模型成本正在迅速下降。用Benchmark合伙人Eisenberg的话说,大模型将是历史上贬值最快的资产。他们之中,只有一两家公司会让投资人赚到钱,其他都会让投资人赔钱。
从目前看,动辄几十亿美元的训练成本、模型价格下降以及开源模型的快速发展,让这些押注模型的创业公司都成了先烈。
既然市场不需要这么多模型,那些模型搞技术的人才又开始回流大厂。从这个角度上说,卖人头式的收购,也是AI行业资源分布的一次“纠偏”。
此后,AI创业公司的路径变得更加清晰:尽快转向AI应用,好好打磨产品,探索更好的商业化路径。
现在国外的模型泡沫已经开始破了。而国内玩家们仍然高举着产模一体的大旗,理由也简单:想融资就必须这样做。
预览时标签不可点
![]()
微信扫一扫
关注该公众号
![]()
微信扫一扫
使用小程序
:,。视频小程序赞,轻点两下取消赞在看,轻点两下取消在看分享收藏