包阅导读总结
1. 关键词:英伟达、数据窃取、视频模型、训练数据、版权问题
2. 总结:英伟达被曝未经授权抓取大量视频数据用于训练未公布的 AI 视频模型,包括来自 YouTube、Netflix 等平台,甚至滥用北大学术数据集,引发版权和伦理质疑。
3. 主要内容:
– 英伟达近期多事,最强 AI 芯片量产延期且市值蒸发。
– 被曝未经授权从 YouTube、Netflix 等抓取视频用于训练未公布的 AI 视频模型。
– 内部对话显示员工对合法性和伦理有质疑,管理层称已获高层批准。
– 用开源下载器结合虚拟机避免被阻止,每天下载量巨大。
– 英伟达高管提议滥用北大学术数据集,员工讨论相关法律和伦理问题。
– 法律灰色地带被利用,版权诉讼堆积,内部讨论多种数据来源和训练进展。
– 模型旨在商业用途,行业需更多透明度和法律规范。
思维导图: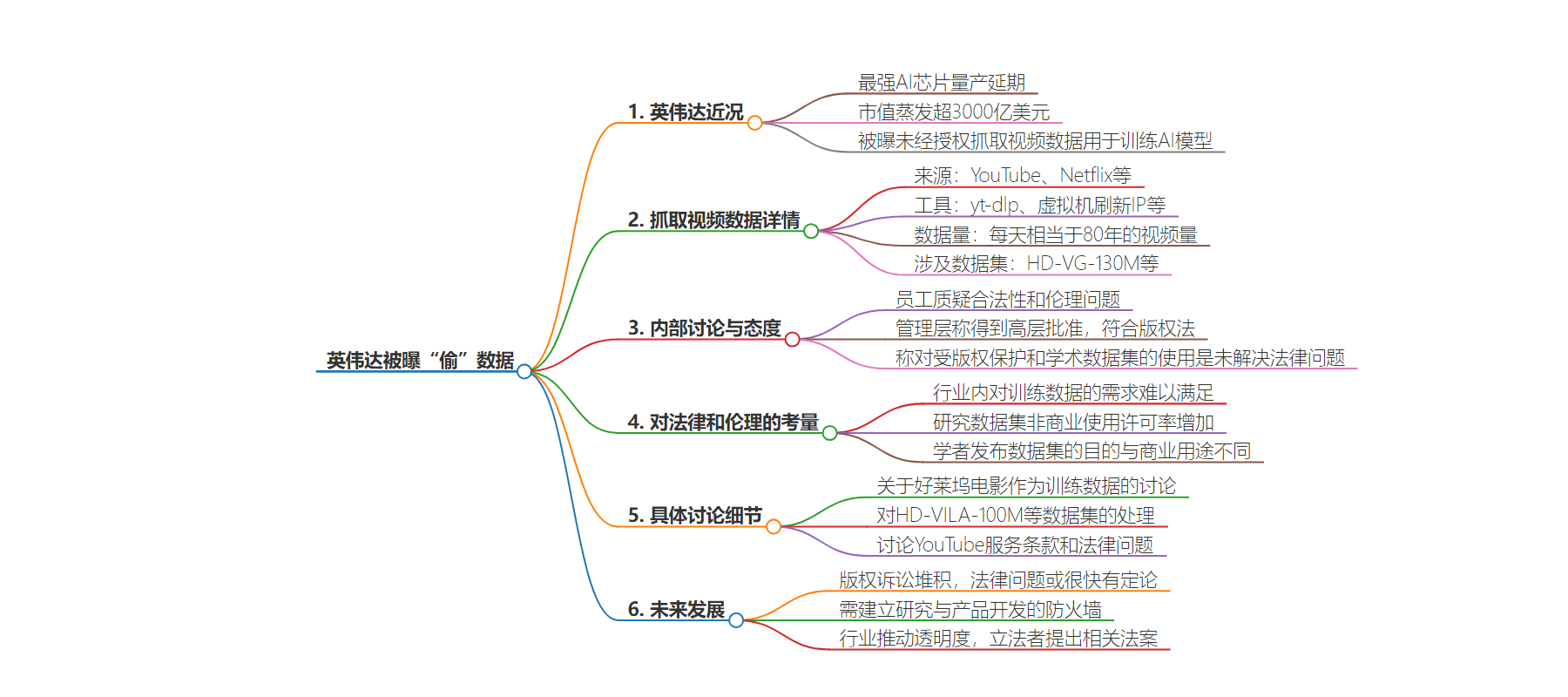
文章地址:https://mp.weixin.qq.com/s/SflvhqESwsszLJybNqDIww
文章来源:mp.weixin.qq.com
作者:发现明日产品的
发布时间:2024/8/6 10:45
语言:中文
总字数:8182字
预计阅读时间:33分钟
评分:78分
标签:AI 数据伦理,英伟达,数据抓取,学术数据集使用,版权争议
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
英伟达被曝「偷」数据,每天爬取超 80 年视频数据量,北大学术数据集也遭殃

继其最强 AI 芯片被曝量产延期、市值蒸发超 3000 亿美元之后,英伟达又被 404 Media 曝出,在未经授权的情况下,从 YouTube、Netflix 等平台抓取视频内容,用于训练其尚未对外公布的 AI 视频模型。
内部邮件和 Slack 聊天记录显示,尽管英伟达员工对使用这些数据集的合法性和伦理问题提出了质疑,但公司管理层表示这些行为已得到高层批准,并辩称其行为符合版权法。
值得一提的是,在 2 月末的内部讨论中,英伟达提及了其正在使用的多个数据集,其中就包括 HD-VG-130M。
后者是一个包含 1.3 亿个 YouTube 视频的数据集,由北京大学的研究人员构建而成,而其使用许可证明确规定仅限于学术研究。
英伟达的做法更像是当下大多数 AI 公司的一个缩影。
当用户已经被视作「数据提款机」,除非内部人士曝光,否则外界实在是难以知晓你我的作品是否已经沦为 AI 训练的养料。
简言之,人类依旧是食物链顶端的消费者,但我们也不可避免成为了 AI 发展供应链中的一员。
以下为外媒 404 Media 的爆料原文,由 GPT-4o 翻译,enjoy it~
用 YouTube 视频喂养模型,每天下载相当于 80 年的视频量
404 Media 获得的内部 Slack 聊天记录、电子邮件和文件显示,英伟达从 YouTube 和其他多个来源抓取视频,以为其 AI 产品编译训练数据。当被问及使用受版权保护内容训练 AI 模型的法律和伦理问题时,英伟达辩称其做法「完全符合版权法的字面和精神。」
404 Media 查看过的英伟达内部对话显示,当员工对使用由学者为研究目的编制的数据集和 YouTube 视频可能带来的法律问题提出疑问时,经理告诉他们,公司高层已批准使用这些内容。
一位前英伟达员工(404 Media 授予匿名权以讨论英伟达内部流程)表示,员工被要求从 Netflix、YouTube 和其他来源抓取视频,以训练英伟达的 Omniverse 3D 世界生成器、自动驾驶汽车系统和「数字人」产品的 AI 模型。
该项目内部名称为 Cosmos(但与公司现有的 Cosmos 深度学习产品不同),尚未公开发布。
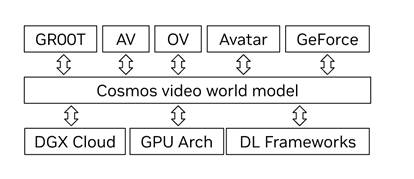
来自项目领导的电子邮件显示,Cosmos 的目标是构建一个最先进的视频基础模型,「将光传输、物理和智能的模拟汇集于一处,以开发对英伟达关键的各种下游应用。」
一张通过 404 Media 获得的电子邮件展示的图表显示,Cosmos 模型如何应用于不同的英伟达产品。
公司为该项目设置的频道内的 Slack 消息显示,员工使用一种名为 yt-dlp 的开源 YouTube 视频下载器,结合虚拟机刷新 IP 地址,以避免被 YouTube 阻止。
据消息显示,他们尝试从包括 Netflix 在内的多个来源下载完整的视频,但主要集中在 YouTube 视频。
404 Media 查看过的电子邮件显示,项目经理讨论使用 20 到 30 台 Amazon Web Services 的虚拟机每天下载相当于 80 年的视频量。
英伟达研究副总裁兼 Cosmos 项目负责人刘洺堉在 5 月的一封电子邮件中表示:「我们正在完成 v1 数据管道的最后定稿,并确保足够的计算资源,以构建一个视频数据工厂,每天生成相当于人类一生视觉体验的数据量。」
英伟达内部的对话和指令显示,员工讨论了公司在设计芯片和 API 时的法律和伦理考量,这些芯片和 API 推动了生成式 AI 的兴起,使其成为世界上最有价值的上市公司之一。
这也突显了行业内最大的公司,如 Runway 和 OpenAI,对作为训练 AI 模型数据的内容有着难以满足的需求。
英伟达的一位发言人在给 404 Media 的一封电子邮件中表示:
我们尊重所有内容创作者的权利,并坚信我们的模型和研究工作完全符合版权法的字面要求和精神。版权法保护特定的表达方式,但不保护事实、观点、数据或信息。任何人都可以从其他来源学习事实、观点、数据或信息,并用它们来创造自己的表达。合理使用也保护将作品用于变革性目的的权利,例如模型训练。
当被问及英伟达使用 YouTube 视频作为模型的训练数据时,Google 的一位发言人告诉 404 Media,该公司的「此前的评论仍然适用」。
其中 YouTube 首席执行官 Neal Mohan 表示,如果 OpenAI 使用 YouTube 视频来优化其 AI 视频生成器 Sora,这将明确违反 YouTube 的使用条款。
Netflix 的一位发言人告诉 404 Media,Netflix 与英伟达没有关于内容获取的协议,并且该平台的服务条款不允许抓取数据。
参与该项目的员工提出的有关法律问题的疑问通常被项目经理驳回,他们表示在未经许可的情况下抓取视频的决定是「高层决定」,员工无需担心,关于什么构成对受版权保护内容和学术、非商业用途数据集的公平、伦理使用的话题被视为一个「未解决的法律问题」,他们会在未来解决。
我们的调查突显了这些科技公司在将大量受版权保护的内容抓取到数据集中,用于训练世界上最有价值的 AI 模型时的「不问自取」态度。
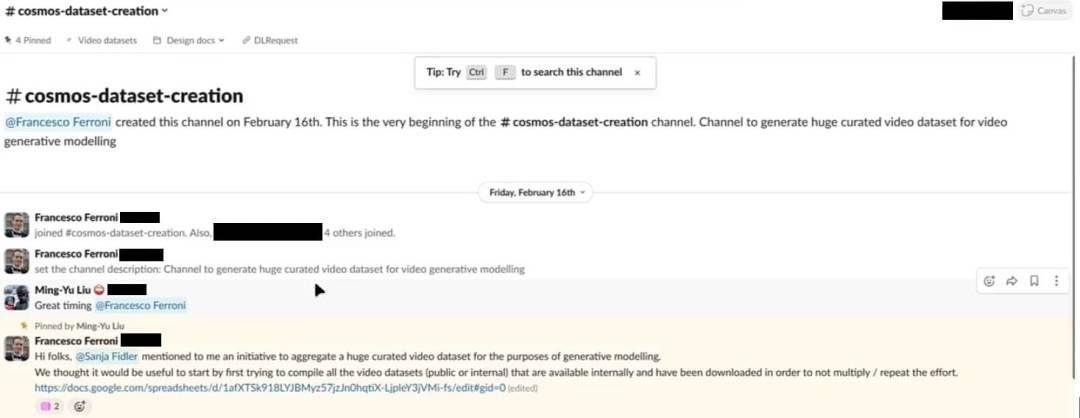
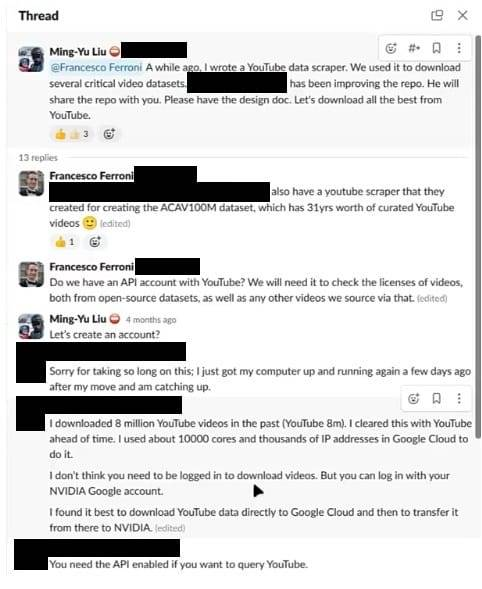
2024 年 2 月,英伟达的首席科学家 Francesco Ferroni 在名为 #cosmos-dataset-creation 的英伟达公司 Slack 频道中写道:
「大家好,@Sanja Fidler 向我提到了一个聚合大量精选视频数据集以进行生成建模的倡议。我们认为,首先汇总所有内部可用的(公开或内部下载)的视频数据集,以避免重复劳动,是很有意义的。」
(注释:Sanja Fidler 是英伟达的 AI 研究副总裁。)
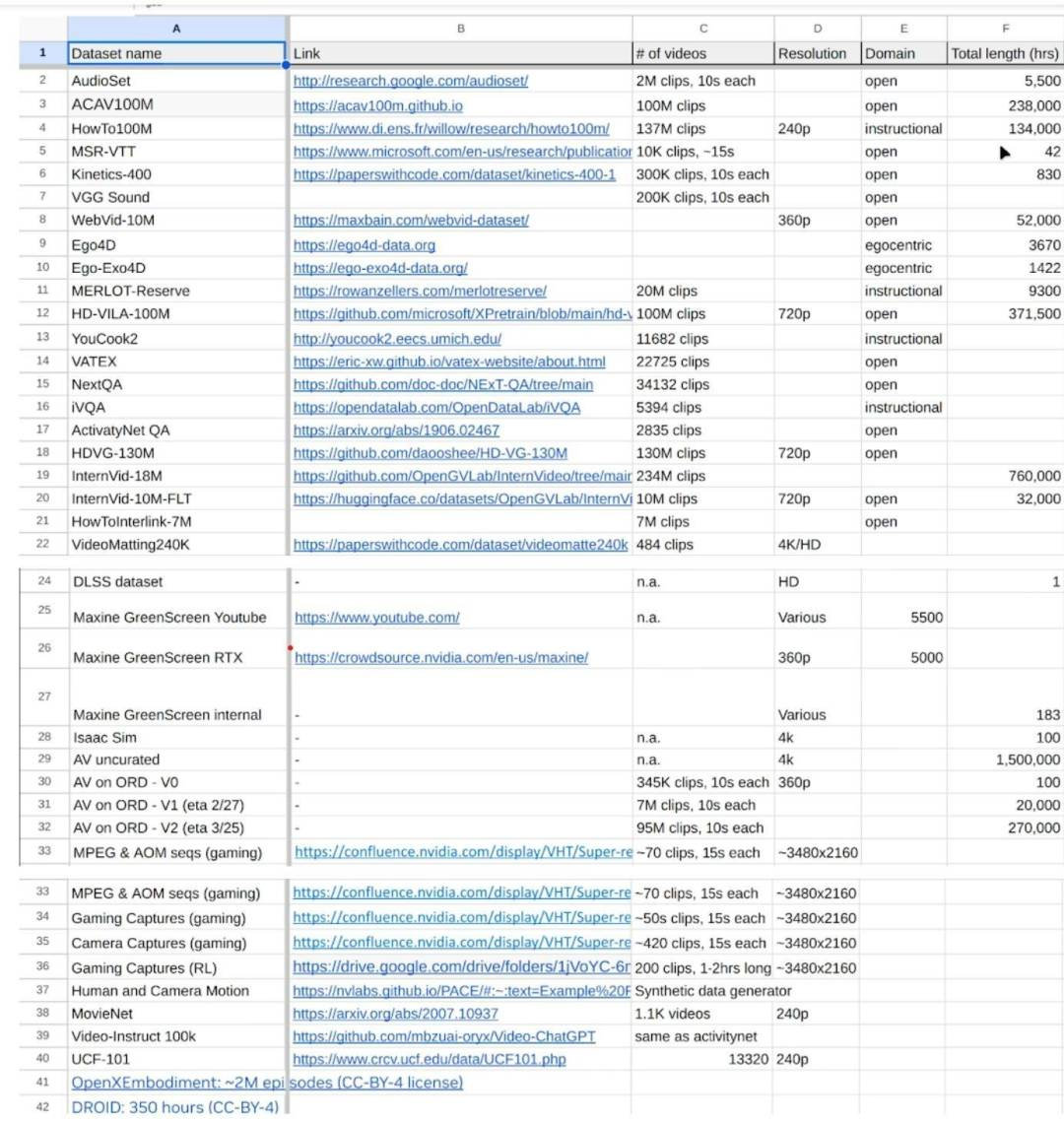
随后,Ferroni 链接了一个包含数据集链接的电子表格,其中包括 MovieNet(一个包含 6 万个电影预告片的数据库)、WebVid(一个由 Github 上的素材图片编译的视频数据集,后来因 Shutterstock 的停止通知而被其创建者删除)、InternVid-10M(一个在 Github 上的包含 1000 万个 YouTube 视频 ID 的数据集),以及几个内部捕获的视频游戏画面数据集。404 Media 已经从 Slack 对话的截图中删除了低级员工的姓名。
我们包括了几位参与该项目的高级工程师和高管的名字,因为他们在 AI 行业中以领导者身份享有公开知名度。
Ferroni 链接的电子表格展示了项目使用的数据集
在二月份的后续讨论中,工程师们谈到他们获取的数据集时,其中包括 HD-VG-130M,这是一套包含 1.3 亿个 YouTube 视频的数据集。该数据集由中国北京大学的研究人员创建,其使用许可声明指出只能用于学术用途。
该数据集的 Github 页面上写道:「通过下载或使用数据,您理解、承认并同意以下协议中的所有条款。」
该页面强调「只能用于学术用途。HD-VG-130M 数据集中的任何内容仅供学术研究使用。您同意不复制、交易或用于任何商业目的。禁止分发。尊重原始来源个人信息的隐私。未经版权拥有者的许可,不得对数据集内容进行任何形式的广播、修改或任何其他类似行为。」
在整个项目过程中,由研究人员和学者编制并公开的数据集被视为可以自由使用于英伟达的模型。AI 研究人员越来越关注他们公开的数据集的适当使用,包括伦理和法律方面的使用。
麻省理工学院数据溯源倡议的 Robert Mahari 告诉 404 Media,在过去的一年中,他们看到研究数据集的非商业使用许可的使用率显著增加,这表明学者们试图限制他们工作的商业使用。为研究用途编制的数据集与商业用途的数据集在目的上有显著不同。
「当学者发布公共数据集,尤其是针对特定任务的数据集时,我们可能不会特别检查这些数据是否存在某些类型的偏见或西方中心主义之类的问题。如果这些不是研究的重点,那么就不会进行检查,」Mahari 说。「因此,如果一位学者在许可中注明『仅供学术使用』或『请不要以非预期方式使用这些数据』,遵守这些规定是有充分理由的。因为这些数据可能不具备商业用途的质量,也可能在其他类型的环境中表现不佳。」
与其他许多科技巨头一样,英伟达雇佣了从事并发表学术研究的人员。然而,404 Media 查看过的英伟达内部对话表明,Cosmos 的目标是为公司在竞争激烈的 AI 行业中强化其商业产品的努力提供支持。
公开发布的研究数据集通常以 URL 或 YouTube ID 的形式分发,原因有二:一是出于实际考虑——分享数百万个完整的视频或图像文件过于繁琐;二是出于法律和伦理考虑。例如,如果有人删除了他们的 YouTube 视频或推文,副本不会在未经所有者知情或许可的情况下继续存在于数据集中。
「这有点像通过不分发数据集给外界来绕过法律约束,」华盛顿大学计算语言学实验室教授兼主任 Emily Bender 告诉 404 Media。「其他人可以构建数据集,然后用于自己的目的。」
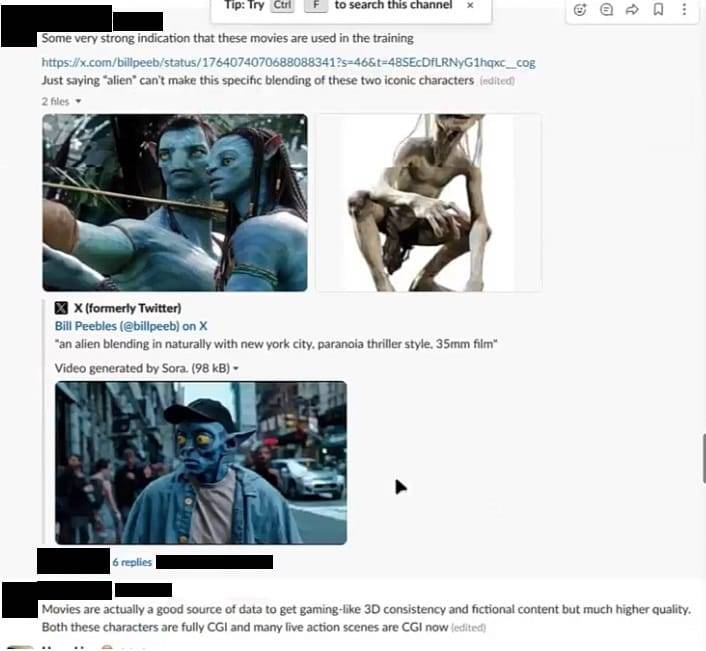
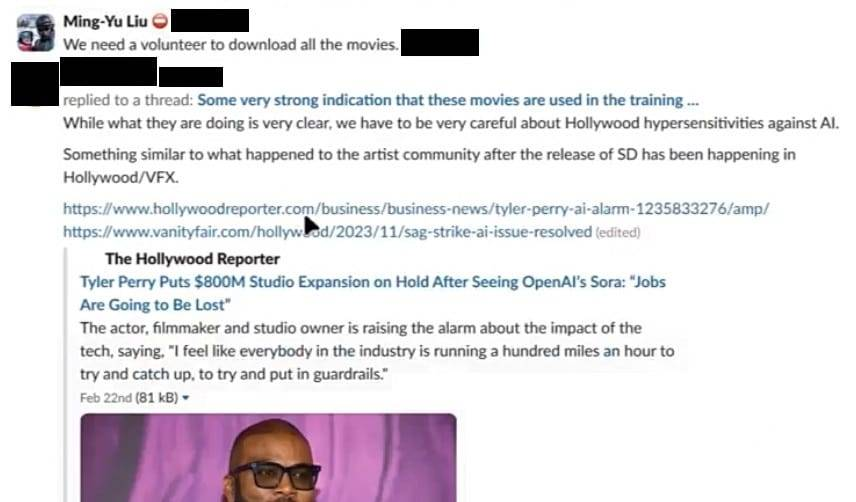
三月份,一位研究科学家在 Slack 上发起了关于 OpenAI 的 Sora 视频生成器可能使用《阿凡达》和《指环王》等好莱坞电影作为训练数据的讨论。
「电影实际上是获取游戏般的 3D 连贯性和虚构内容的良好数据来源,而且质量更高。这些角色都是完全的 CGI,现在许多真人场景也已经是 CGI,」他们说。有人回复说,团队应该训练 Discovery Channel 的电影数据集。
最初提出电影的研究科学家补充道:「虽然他们正在做的事情非常明确,但我们必须非常小心好莱坞对 AI 的高度敏感,就像 SD [Stable Diffusion] 发布后发生在艺术家社区的情况一样,现在正在好莱坞中发生。」
随后,他们在聊天中贴了两个链接:一个是 Hollywood Reporter 关于泰勒·佩里在看到 OpenAI 的 Sora 后暂停了8亿美元的工作室扩展的文章,另一个是 Vanity Fair 关于 2023 年 SAG-AFTRA 罢工导致工作室合同中包含 AI 语言的文章。
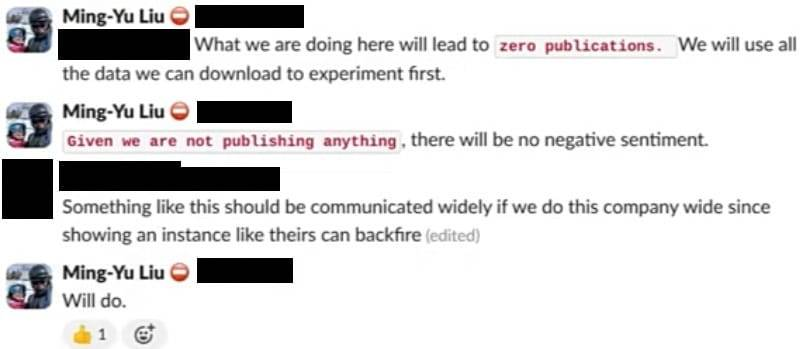
刘洺堉强调道:「我们在这里做的事情不会发表任何研究成果。我们将使用所有可下载的数据进行实验。鉴于我们不会发表任何内容,所以不会有负面情绪。」与 404 Media 交谈的前员工解释说,「发表」是指研究出版物。
提出「高度敏感性」的那个人回复说:「如果我们在公司范围内开展这样的项目,应当广泛沟通,因为展示类似的实例可能会引起反作用。」刘洺堉回复道:「会的。」
三月份,Ferroni 在另一个与项目相关的 Slack 频道中写道:「发现了一些高优先级的文件需要下载。结果发现我们拥有的 HDVILA [高分辨率视频语言] 数据集中缺少 230 万个原始视频!」他们指的是微软的 HD-VILA-100M,这是一个大规模、高分辨率和多样化的视频语言数据集。他们发送了一个 Google Drive 文档链接,说:「这里是缺少的 YouTube 链接」,然后说:「让我们把这个放进下载流程中!」
HD-VILA-100M 的使用许可声明这样写道:
「您同意仅将数据用于非商业研究的计算目的。此限制意味着您可以从事非商业研究活动(包括由商业实体进行的或资助的非商业研究),但不得将数据或任何结果用于任何商业产品,包括作为您使用或提供给他人的产品或服务的一部分(或用于改进任何产品或服务)。」
「我们创建一个已经下载的网址数据库吧,」另一位工程师回复道。「YouTube 视频有唯一的 ID,我们可以用这些 ID 作为参考(『?v=』 后面的 ID)?以后我们会多次进行 URL 对比和合并。」Ferroni 回复说:「是的,我们现在正在使用 Hive 设置基础设施,」意思是他们正在将其添加到项目管理工具 Hive 中。
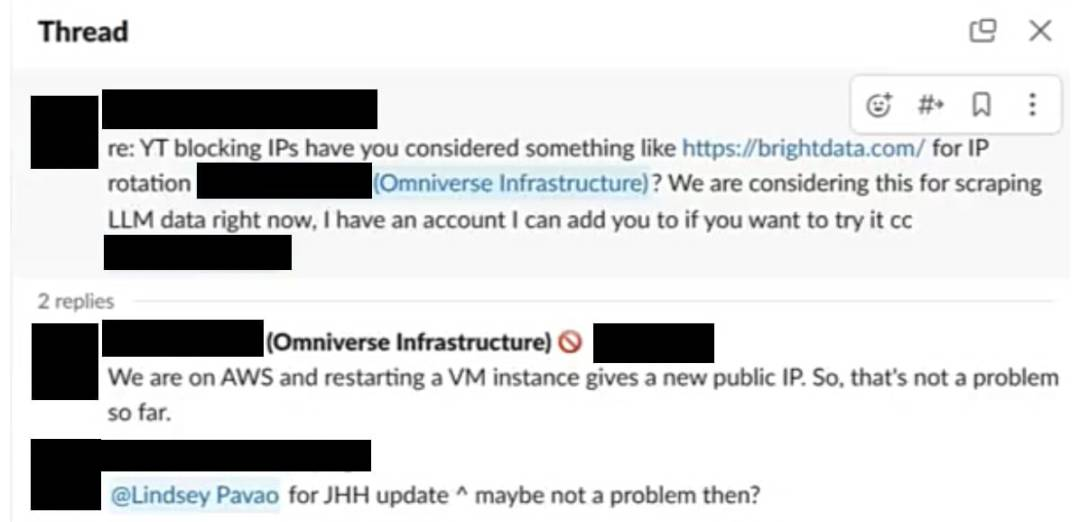
英伟达的员工还讨论了 YouTube 阻止 IP 地址的问题;如果平台检测到类似抓取工具的大量内容下载行为,它们可能会阻止单个 IP 地址的访问。有人问:「关于 YouTube 阻止 IP 的问题,你有没有考虑过类似 https://brightdata.com/ 的 IP 轮换?我们现在正在考虑用它来抓取 LLM 数据,如果你想试试,我可以把你添加到我的账户中。」
他们标记的那位 Omniverse 团队成员回复道:「我们在 AWS 上,重新启动一个 [虚拟机] 实例会给我们一个新的公共 IP,所以,目前这不是问题。」
在 #cosmos-dataset-creation 频道中关于如何寻找最佳视频的 Slack 讨论中,员工偶尔会提到他们工作的法律和伦理问题。二月份,有人提到使用 Google 编制的 YouTube-8M(一个 YouTube ID 的研究数据集)后,Ferroni 问道:「我们可能不可将 [YT8M] 用于非研究目的吧?」
YouTube-8M 的论文和项目页面没有提及版权问题,但论文中确实表明该数据集是为了推进机器学习研究而创建的:「我们期望该数据集能够为学术界研究人员提供公平竞争的环境,缩小与大规模标注视频数据集的差距,并显著加速视频理解的研究。我们希望这个数据集能成为开发新颖的视频表示学习算法,尤其是有效处理噪声或不完整标签的方法的测试平台。」
针对 Ferroni 提到的将其用于 Cosmos 项目的问题,一位此前共同创建 ACAV100M 的英伟达员工回答道:
「是的,从 Google 下载数据的成本非常高。然而,从英伟达内部调度 10000 个 cores 一直是个挑战。
此外,英伟达到云的带宽限制增加了相当大的变动性,可能会引发问题。在 Google Cloud 上下载意味着每个任务都能获得稳定、高带宽的连接到 YouTube。」
「更重要的是,下载 YouTube 视频是 YouTube 服务条款所禁止的。所以在下载 YouTube 8m 时,我们事先与 Google 和 YouTube 进行了沟通,并以使用 Google Cloud 进行下载作为诱因。毕竟,通常对于 800 万个视频,他们会获得大量的广告展示,这些广告在用于训练时下载会导致收入损失,所以他们应该从中获得一些收益。每次下载视频支付 $0.00625 仍然是一个不错的交易。」
「好的,预计这些数据只能用于研究目的?据我所知,Google 的 YouTube API 可以查询每个视频的许可条款,」 Ferroni 回应道。「你能否也评论一下 ACAV100M 和 YouTube8M 的许可条款?」
「据我所知,YouTube 的服务条款禁止下载,不论许可如何;限制是关于他们失去的广告收入,而不是许可,」另一位员工回应道。他们继续说:
「我不知道 Google 在创建数据集时过滤了哪些许可条款;我们只是下载了他们列出的包含在数据集中的内容(他们发布了特征,以及指向原始视频的链接)。我下载的 YouTube 8m 数据集带有完整的元数据,所以你可以在那里检查每个视频。我仍然需要查看 ACAV100M 数据集。一般来说,CC 或公共领域当然是最好的。然而,是否可以将受版权保护的材料用于训练目前是一个悬而未决的法律问题;大多数公司似乎认为这是合理使用。我相信我们的法律团队已经批准了这种用于训练大语言模型的做法,并可能也会批准视频训练。」
「我认为在没有某人同意的情况下商业化某物与研究基于公开发布内容的生成式 AI 能力之间存在巨大差距,」 MIT 媒体实验室的博士生 Shayne Longpre 告诉 404 Media。在 Cosmos Slack 频道中关于 YouTube 服务条款的问题并不是法律问题最后一次出现。
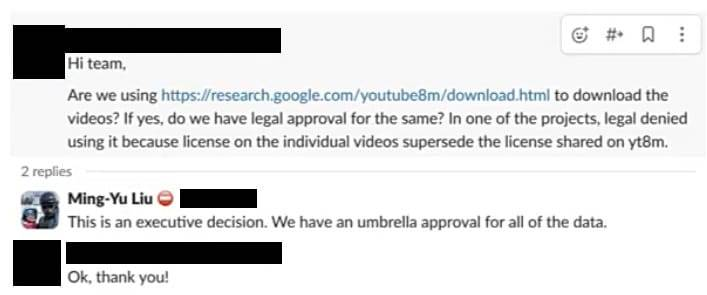
后来,另一位员工说,「团队好。我们是否使用 https://research.google.com/youtube8m/download.html 下载视频?如果是的话,我们是否有合法批准?在一个项目中,法律部门否决了使用它,因为单个视频的许可优于 yt8m 上共享的许可。」 「这是一个行政决策。我们有一个涵盖所有数据的总许可,」刘洺堉回复道。「好的,谢谢!」提问的人回复道。
Bender 告诉 404 媒体,公司正在利用当前用于训练数据的版权内容所存在的法律灰色地带。「在我看来,肯定存在一种‘如果我们能获取它,我们就能使用它’的文化,」她说。「这很大程度上是基于人们希望它成为现实,而不是基于对其合法性的仔细研究,或者深入思考它对人们的影响。」
Mahari 说,使用版权内容进行 AI 训练「绝对不是已定的法律」。法律体系尚未确定获取训练数据来开发 AI 模型是否具有足够的变革性,特别是因为模型已经显示出能够记住或回忆训练数据作为输出。「我的观点(部分总结在这篇《科学》文章中)是,训练 AI 模型可能确实构成合理使用,但这并不意味着生成与训练数据中特定项目相似的输出不是侵权。
在这种情况下,尚不清楚是基础模型的提供者还是生成输出的特定用户会构成侵权(这可能取决于具体的上下文)。」
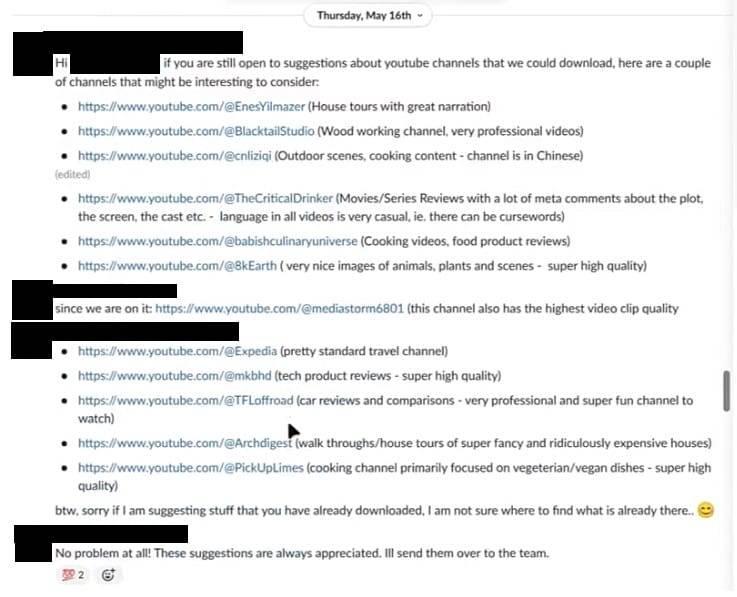
在五月,一位研究科学家在 Cosmos Slack 频道中丢了一些 YouTube 频道的链接并说,「如果你们仍然愿意接受关于可以下载的 YouTube 频道的建议,这里有几个可能值得考虑的频道。」它们包括 Expedia 和 Architectural Digest 的官方频道,还有一些个人内容创作者,如 The Critical Drinker 和 Marques Brownlee (MKBHD)。一位项目经理感谢他们的建议并表示会转达给团队,Fidler 回复道,「你也包括了教程视频了吗?天文学?医学?」
使用版权作品进行商业基础模型训练的「未决法律问题」可能不会悬而未决太久。
版权持有者对生成式 AI 公司提起的版权侵权诉讼正在堆积,包括 Getty Images 对 Stable Diffusion 创作者 Stability AI 的诉讼,纽约时报对 OpenAI 的诉讼,以及艺术家和创作者对 Stability、Midjourney、DeviantArt 和 Runway 提起的集体诉讼。Cosmos 训练数据团队还讨论了使用 Netflix 来训练生成器。
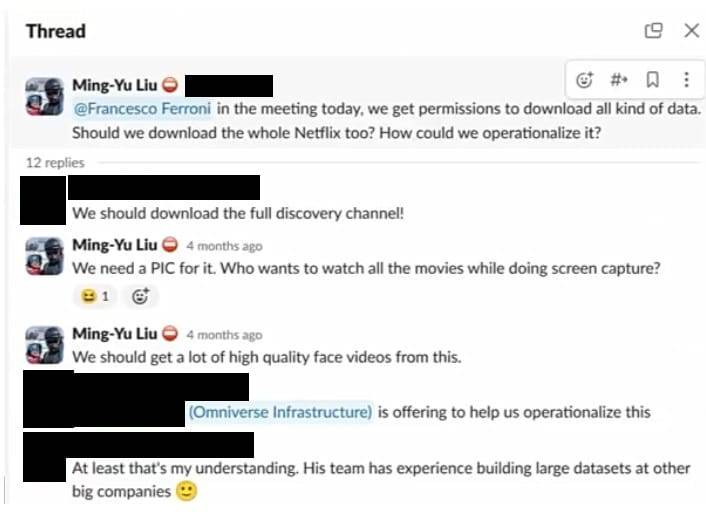
「今天的会议上,我们获得了下载各种数据的许可。我们应该下载整个 Netflix 吗?我们该如何将其操作化?」刘在 Slack 频道中说。「我们应该下载整个探索频道!」
有人回复道。「我们需要一个项目信息协调员。谁愿意在看所有电影的同时进行屏幕捕捉?」刘说。「我们应该从中获得很多高质量的人脸视频,」刘继续说道。来自 Omniverse 基础设施团队的某人在讨论串中被标记,并指出他们愿意帮助「将其操作化」,因为他们在「其他大公司构建大型数据集方面有经验。」
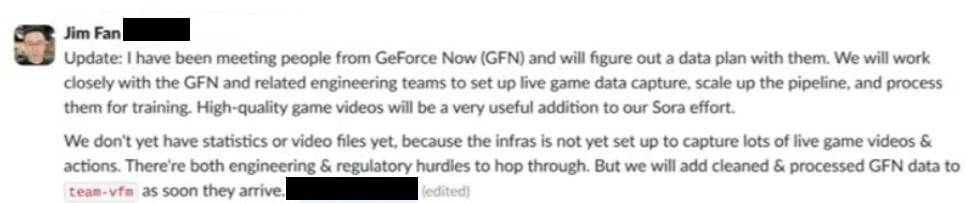
团队还考虑了如何最好地将视频游戏画面添加到训练数据中。英伟达的高级研究科学家 Jim Fan 提到,捕捉现场游戏视频时遇到了「工程和监管」方面的障碍。
「更新:我已经与 GeForce Now (GFN) 的人见过面,并将与他们一起制定数据计划。我们将与 GFN 和相关工程团队紧密合作,建立实时游戏数据捕捉,扩大管道规模,并处理这些数据以进行训练。高质量的游戏视频将是我们 Sora 项目非常有用的补充,」Fan 写道。「我们目前还没有统计数据或视频文件,因为基础设施尚未建立起来以捕捉大量的现场游戏视频和动作。我们需要克服工程和监管方面的障碍。但是,一旦清理和处理后的 GFN 数据到达,我们将尽快将其添加到 team-vfm 中。」
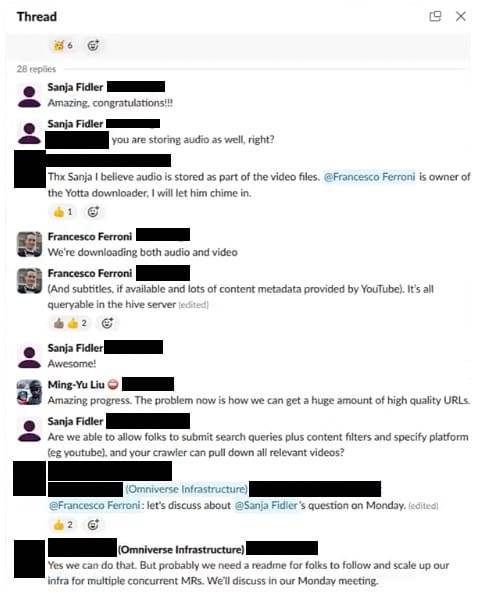
三月,该项目达到了一个里程碑:在两周内下载了 10 万个视频。一个员工在讨论这个里程碑的线程中提到,Ferroni 拥有他们正在使用的一个下载器,Ferroni 确认他们一直在下载音频和视频。「惊人的进展。现在的问题是我们如何获得大量高质量的 URL,」刘回复道。
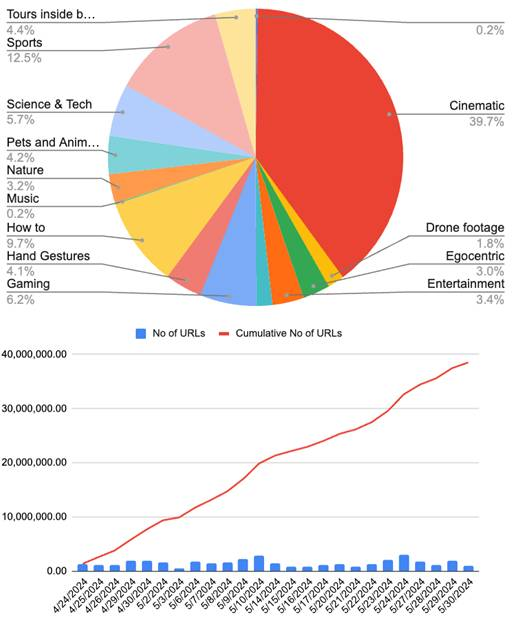
五月下旬,一封关于视频数据的数据策略的电子邮件发给了项目团队的成员,宣布他们已经编制了 3850 万个视频 URL。「根据我们的目标分布,未来一周的重点仍然专注于电影、无人机画面、第一视角视频以及一些旅游和自然视频,」电子邮件写道。邮件中还包含了一个显示他们下载的内容类型百分比的图表。
在那封电子邮件中,一位产品经理建议将另外四个数据集添加到模型的训练数据中。他们写道:
1. Ego-Exo4D:一个多样化的大规模多模态、多视角视频数据集和基准测试,由 740 位摄像机佩戴者在全球 13 个城市收集,捕捉了 1286.3 小时的熟练人类活动视频。
2. Ego4D:一个大规模的第一视角数据集和基准测试套件,在全球 74 个地点和 9 个国家收集,超过 3670 小时的日常生活活动视频。
3. HOI4D:一个大规模的四维第一视角数据集,带有丰富的注释,以促进类别级人类-物体互动的研究。
HOI4D 由清华大学、北京大学和上海期智研究院的研究人员创建,采用 CC BY-NC 4.0 许可证,不允许商业用途。
「在我看来,如果一家公司使用一个仅用于研究目的的数据集,并将其用于研究,他们仍然遵循该数据集的许可,」Bender 说。
「但为了确保这一点,他们必须非常小心地在他们进行的研究和他们在产品开发中的工作之间建立防火墙。」
在五月的另一封更新电子邮件中,刘说,「研究团队现在正在用许多不同的配置训练一个拥有 10 亿参数的模型,每个配置有 16 个节点。这是进一步扩展前的重要调试步骤。我们计划在几周内得出结论,然后扩展到 100 亿参数的模型。」
英伟达的 CEO 黄仁勋在那封电子邮件中回复道,「很棒的更新。许多公司必须构建视频基础模型。我们可以提供一个完全加速的管道。」
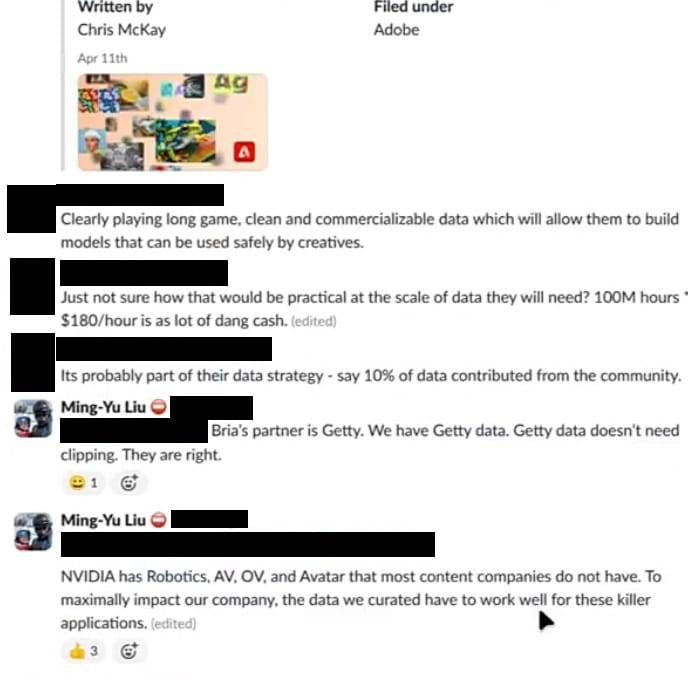
六月,员工们讨论了模型中哪些类型的内容对英伟达的产品最有用,以保持在 AI 行业中的竞争力。
「英伟达拥有大多数内容公司没有的机器人、自动驾驶汽车、Omniverse 和 Avatar。为了对公司产生最大的影响,我们策划的数据必须能够很好地应用于这些杀手级应用,」刘说。
「我了解对机器人和自动驾驶汽车有影响的数据。谁能分享对 Omniverse 和 Avatar 用例有影响的数据的详细信息?」一位产品经理回复道。「这将是关于人类如何与物体互动的视频。比如家具安装,切水果,叠衣服,」刘回答道。
虽然英伟达确实为学术研究做出贡献,但 404 Media 获得的对话和电子邮件显示,Cosmos 团队正在研究的模型旨在用于其多个产品的商业用途。
在如何编制训练数据方面设立法律先例之前,或者公司被要求对这些数据透明之前,公司将继续利用抓取版权训练数据的法律灰色地带。像这样的内部对话泄露是人们唯一能够知道他们的作品是否被用来训练模型,让英伟达或 Runway 或 OpenAI 等公司赚取数十亿美元的方式。
多年来,无论是通过政府监管还是行业标准,AI 行业一直在推动更多的透明度。
今年早些时候,MIT 的 Jack Hardinges、Elena Simperl 和 Nigel Shadbolt 写道:「了解用于训练模型的数据集中的内容及其编制方式至关重要。没有这些信息,开发人员、研究人员和伦理学家解决偏见或从数据中移除有害内容的工作将受到阻碍。
训练数据的信息对于立法者评估基础模型是否摄入了个人数据或版权材料也至关重要。在下游,如果 AI 系统的预期操作员和受其使用影响的人了解它们是如何开发的,他们更有可能信任这些系统。」
去年,立法者提出了几项法案来解决这个问题,包括在十二月提出的《AI 基础模型透明法案》,该法案要求创建基础 AI 模型的公司与联邦机构(如 FTC 和版权局)合作制定透明度标准,包括要求他们向消费者公开某些信息。
今年四月提出的《生成式 AI 版权披露法案》将要求数据集制作者向注册员提交「任何受版权保护的作品的充分详细摘要」,否则将面临罚款。
「从技术上讲,确定你的作品是否被用于训练确实很难,」Mahari 说。「在公司内部,最好的政策是不要告诉人们你用什么训练,因为任何第三方都很难真正进行审计并发现。因此,只要你不告诉任何人,就很难证明。」
附上报道原文地址:
https://www.404media.co/nvidia-ai-scraping-foundational-model-cosmos-project/

预览时标签不可点
![]()
微信扫一扫
关注该公众号
![]()
微信扫一扫
使用小程序
:,。视频小程序赞,轻点两下取消赞在看,轻点两下取消在看分享收藏