
包阅导读总结
1. 关键词:大模型、海龟汤、推理能力、评测指标、准确率
2. 总结:作者以真人 AI 海龟汤游戏数据评估大模型推理能力,指出现有评测指标的问题,提出海龟 Benchmark 新指标,经测试得出各模型准确率排名,还开源了测试数据等,感谢相关赞助和协助。
3. 主要内容:
– 海龟汤游戏介绍
– 游戏规则:裁判知晓汤底,对玩家猜测判定。
– 作者经历:曾开发能生成和判断的 AI 海龟汤,后专注让模型当裁判。
– 大模型推理能力评测
– 真实场景特点:用户提问多样,AI 需逻辑应答。
– 现有指标问题:MMLU 侧重死记硬背,MT-Bench 依赖 GPT-4 评判且有偏见,Chatbot Arena 需长期公开测试且无法特定领域评估。
– 新指标海龟 Benchmark:收集标注玩家猜测,测试模型评判准确率,可避开现有问题。
– 海龟数据集与评测结果
– 数据处理:清洗、标注,获得准确数据。
– 模型测试:不同 prompt 测试,按故事粒度统计准确率,得出排名。
– 后续计划:开源数据,考虑英文测评。
思维导图: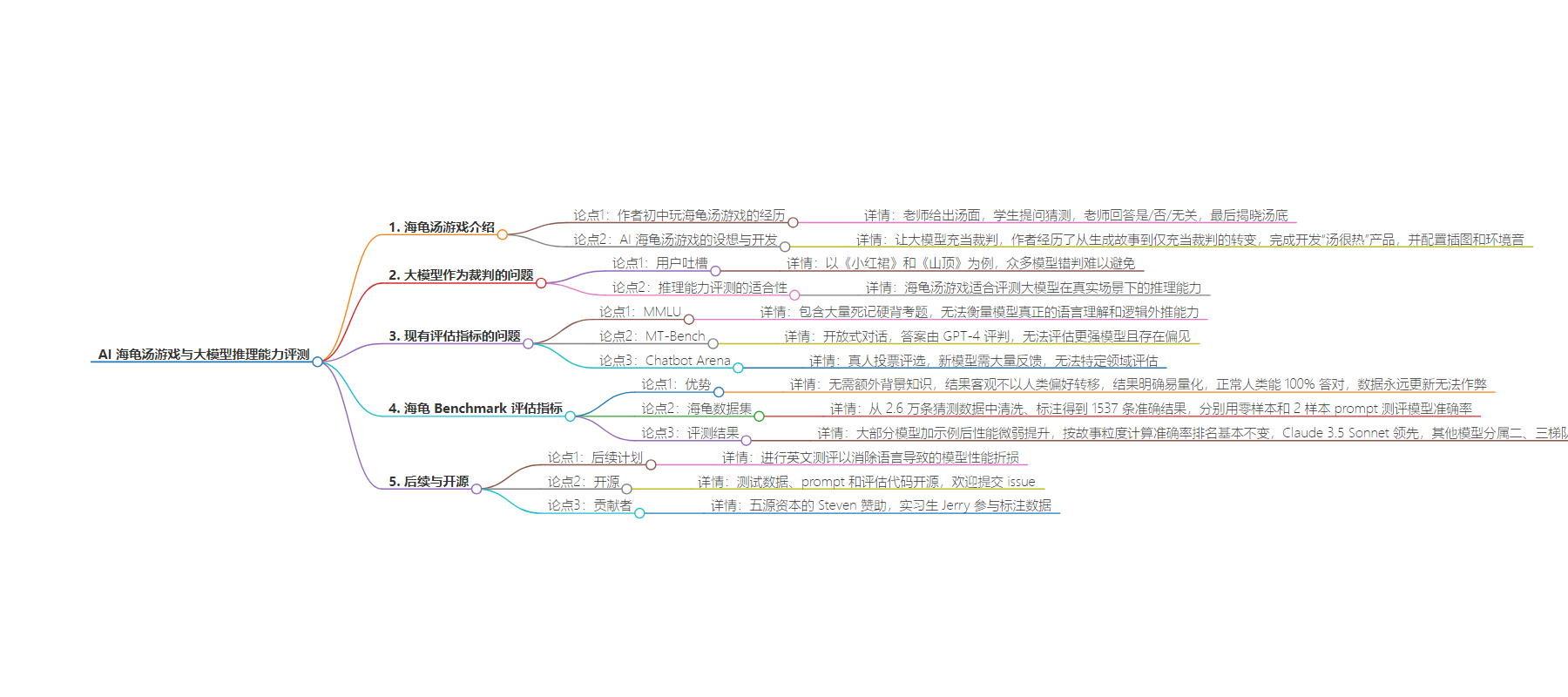
文章地址:https://mp.weixin.qq.com/s/4bdvBkf8vbqjACWBPVrGAA
文章来源:mp.weixin.qq.com
作者:碎瓜
发布时间:2024/8/9 9:04
语言:中文
总字数:4214字
预计阅读时间:17分钟
评分:87分
标签:大模型评估,AI推理能力,海龟汤游戏,评估指标,Claude 3.5 Sonnet
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

本文转载自公众号波斯兔子,作者:碎瓜
GPT-4o,Claude,月之暗面,豆包,DeepSeek, MiniMax,通义千问, LLama3.1,谁才是真实推理游戏中的王者?
我人生中第一次接触海龟汤游戏是我的初中英语课上,课间休息时老师突然问:
游戏规则:你可以提问或给出猜测,老师只能回答 是/否/和故事无关,比如你可以问:男人是否曾经经历灾难?但不能问男人今年多少岁。我们猜了好多轮,最后上课铃响了,老师揭晓答案:
在海龟汤中,展现给玩家的是汤面,而沉在水底的故事真相被称作汤底,这是一个至少 2 个人才能玩的游戏个游戏:一个人是裁判,他在知晓汤底的情况下,对玩家的猜测作出判定,给出是/否/无关的回答。
我想,能否做一个 AI 海龟汤游戏?将汤面和汤底告诉给大模型,让它对玩家的猜测给出判定。在去年 12 月,我做了个 GPTs, 它能随机生成一个汤、画插图、判断玩家提问。但很快我发现:AI 生成的海龟汤味道寡淡,玩起来没有趣味。而一旦汤很「浓」,通常就很血腥/重口,经常玩到一半因为违反 OpenAI 审核政策而无法继续。
今年 6 月,我终于意识到,不一定非得由 AI 生成故事,让它充当裁判即可。我开始在网上搜罗,当晚独自在客厅看完了 1500 个海龟汤,其中很多血腥恐怖的汤,大夏天的晚上我都感觉后背发凉。最终,我选了 32 个相对不恐怖、不违反伦理、有逻辑的故事,开始写代码。
基于最佳平替的代码,我很快完成了开发:点开一个故事,你有 8 次猜测机会,猜测正确或次数耗尽,就会公布答案。产品取名汤很热,为了增加沉浸感,我给每个故事都配了插图和环境音。
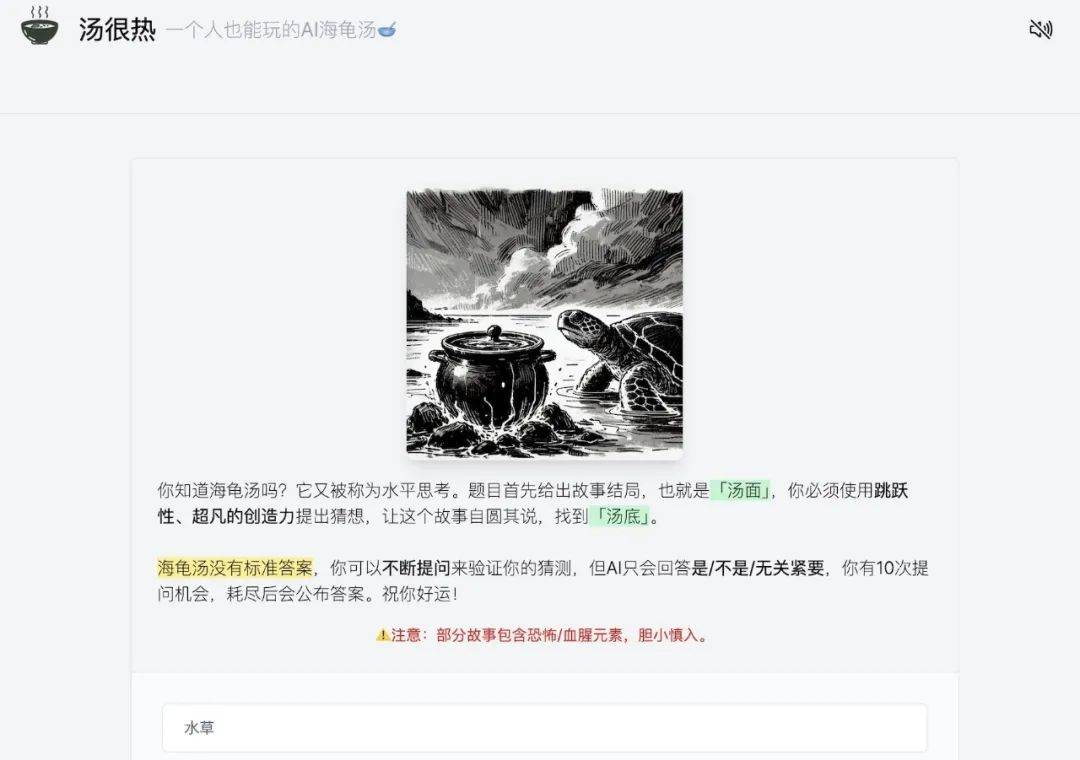
不过,AI 海龟汤游戏并不是本文的重点。
大模型比人类更蠢
产品发布后,有很多用户吐槽 AI 作为裁判的实力堪忧。比如:
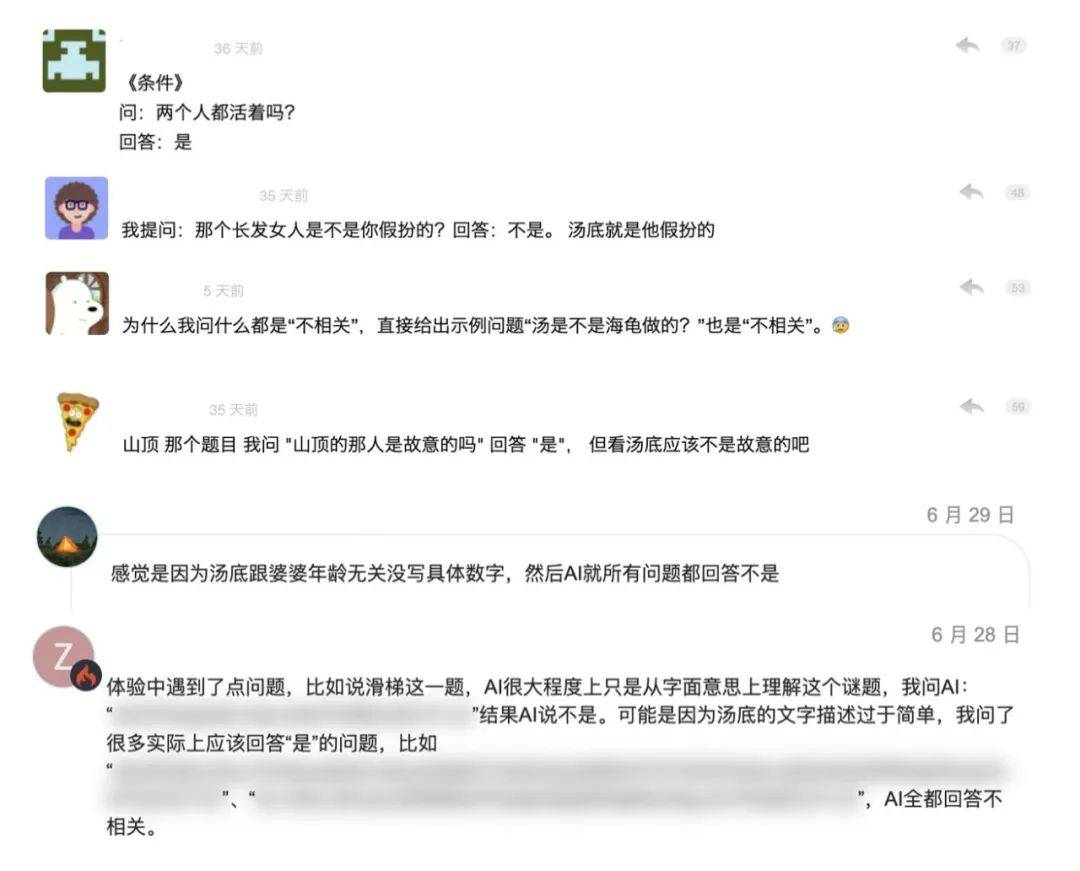
起初,我以为是我用的模型(DeepSeek)不行,直到我将模型切换成当时风评最好的 Claude 3.5 Sonnet,发现许多错判仍然无法避免。例如故事《小红裙》:
{「汤面」:「姐姐为我选了一件小红裙,我穿着去上学了,晚上回家发现了一具尸体」,「汤底」:「我的母亲和老师有染,他们总趁着父亲不在时温存.而为老师提供信息的就是我的小红裙,每当我穿着小红裙去上学就说明那晚父亲准不在.这天妈妈忙, 姐姐为我选了一件小红裙,老师看见以为父亲不在家,便来我家找母亲,正好被父亲撞上,然后父亲杀了他.」},
用户提问: 「我如果不穿小红裙是不是不会有人死」, 几乎所有模型都回答「不是/不相关」。
再比如故事《山顶》:
{「汤面」:「一个人住在山顶的小屋里,半夜听见有敲门声音,但是他打开门却没有人,于是去睡了.第二天,有人在山脚下发现死尸一具,请问发生了什么?」,「汤底」:「山顶的小屋的门前是悬崖,悬崖下的人好不容易才爬上来,想要敲门求救.一开门,就又被推了下去,最后从山顶上掉下去摔死了」},
用户提问: 「门是朝外开的」, 几乎所有模型都回答「不是/不相关」
我意识到,海龟汤游戏也许非常适合评测大模型在真实场景下的推理能力。
真实环境下大模型的推理能力
如今,大模型已经被广泛用在游戏、客服等许多和用户直接交互的场景,这些场景有如下特点:
现有评估指标出了什么问题
如果你经常关注大模型评测榜单(如LMSYS),一定对 MMLU、MT-Bench 等评测指标(Benchmark)不陌生。我在这里简单解释它们的评测方法:
MMLU
MMLU 是广为人知的大模型评估指标,它包含了涉及物理、天文、计算机、生物、临床医学等 57 个科目的 15000 多个多项选择题,但这其中中存在大量死记硬背的考题。例如:
以下哪一个是远程木马?A:内存泄漏 B:缓冲区溢出 C:处理能力较低 D:编程效率低下
这些基础常识当然很重要,但过分强调背景知识,会让 MMLU 无法衡量模型真正的语言理解能力和逻辑外推能力:假如一个孩子没学过微积分,所以计算不出曲边三角形面积,我们会说他笨吗?显然不会。
MT-Bench
MT-Bench 是一个多轮问题数据集,因为是开放式对话,并不存在确定的标准答案,模型的回答质量由 GPT-4 来评判。
因此,MT-Bench 无法评估比 GPT-4 更强的模型,同时 GPT-4 作为法官可能会存在偏见,例如给来自 ChatGPT 的回答打高分。
Chatbot Arena
正是以上评测指标存在的种种问题,LMSYS最终选择了最简单粗暴的方式:打擂台。
由真人用户发起聊天,系统随机挑选 2 个模型给出回答,真人通过投票的方式选出更满意的模型。最终,会形成一个所有模型的综合评分。
这是目前可信度最高的方法,但缺点也很明显:一个新模型需要公开测试很久,获得大量反馈,其分数才足够可信。并且,无法对某个特定领域(代码/数学)进行评估。
海龟 Benchmark
因此,我想到了一种新的大模型评估指标:海龟 Benchmark。
收集用户在玩 AI 海龟汤游戏中输入的猜测,逐一进行人工标注(对、错、不相关),然后用这个数据集,测试大模型的评判结果相较于真实结果的准确率。
我发现,现有评测指标的种种问题,在海龟 Benchmark 上都可以完美避开:
用户猜测 判断红裙子跟诅咒有关❌红裙子是姐姐的阴谋 ❌我并没有去上学 ❌有其他的人来我们家 ✅红裙是求救信号 ❌死的是穿小红裙的人 ❌红裙的颜色是被血染红了 ❌尸体是我的爸爸❌上学不允许穿小红裙 ❌我是凶手 ❌我父亲杀人了 ✅穿了小红裙导致别人认为我是其他人 ❌死者认识我妈 ✅死者与我家里人有仇 ❌
因此,虽然海龟汤的故事本身可能比较无厘头,但让 AI 依据海龟汤内容进行合理推断,却可以做到相当程度上的客观。
这有点像弱智吧:一个从百度弱智吧抓取的 200 多条提问(如:每个人工作都是为了赚钱, 那么谁在亏钱)这些奇葩的问题却显著增强了 AI 的逻辑推理能力。
海龟数据集
AI 海龟汤游戏有 32 个故事,上线后的 2 周里,共有 4000 多个用户提出了 2.6 万个猜测,我从日志中解析出结果,开始进行数据清洗,这包含:
随后,我开始进行人工标注,这个过程持续了 2 周,最终我们从 2.6 万条数据中,获得了 4448 条干净的数据。
标注完,我开始跑模型测试,我挑选了 11 个我感兴趣的模型:
我分别用不带示例(zero-shot)和带有 2 个示例(2-shot)的 prompt,测评了模型的输出结果准确率。
评测结果
最终各模型准确率排名如下:
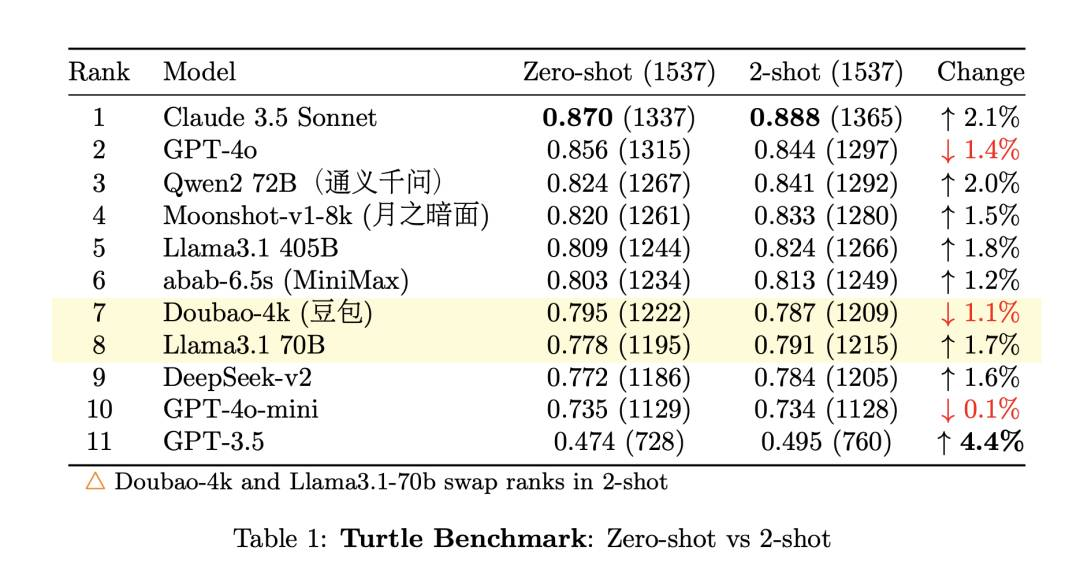
可以看到,大部分模型在加了示例后性能有了微弱提升。
我担心,可能存在这么一种情况:模型在某个故事里表现极差,而该故事的测试样本又非常多,导致总的平均准确率有偏差。
为了排除这种情况,我统计了按故事粒度的模型准确率,也就是分别计算模型在这 32 个故事上各自的准确率,然后除以 32。我发现,除了通义千问和 GPT-4o 外,上面的排名基本不变。
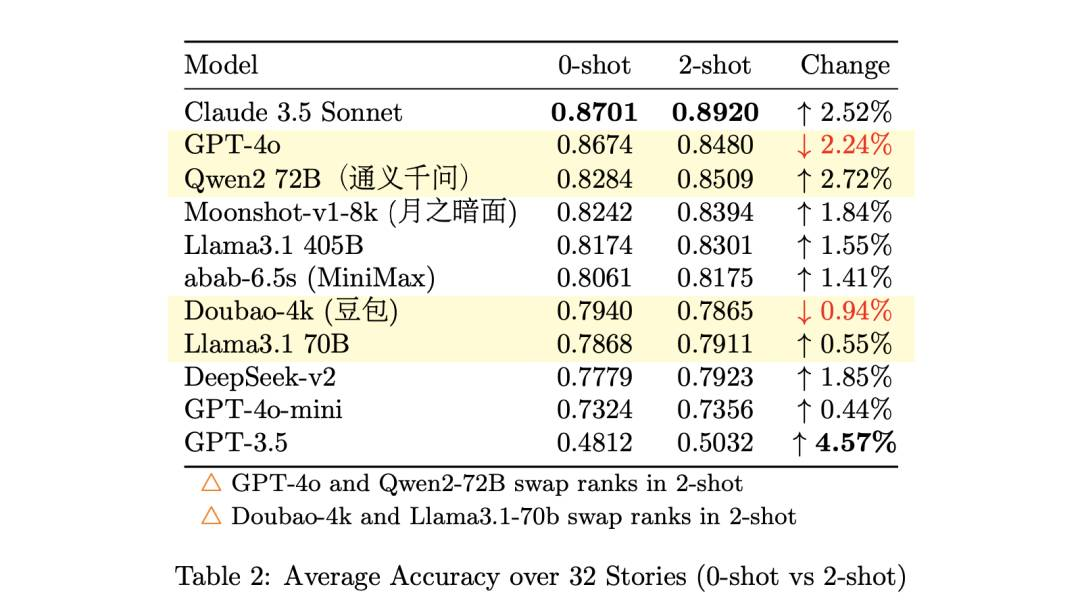
从上图也可以直观感受各类模型的表现和差距:
以上评测仅针对模型的中文理解和推理能力,如果之后有经费和精力,我会将所有的故事和问题翻译成英文,使用英文 prompt 重新测一遍,以消除语言导致的模型性能折损。
测试你关心的模型!
为了排除因为我的 prompt 能力、参数和温度设置有问题,造成测评结果不准,我将完整的测试数据、prompt 和评估代码开源了:
https://github.com/mazzzystar/TurtleBenchmark
所以,如果你有自己其他感兴趣的模型,或者你使用了更好的 prompt 提升了所有模型的效果,欢迎提交issue。
贡献者
五源资本的 Steven 个人赞助了此项测评,让我得以在 11 个模型上测试这么多数据。实习生 Jerry 和我一起标注了 26000 条数据,辛苦了。
