
包阅导读总结
1.
关键词:Agent 、POAD 、强化学习、通才 Agent 、语言智能体
2.
总结:本文介绍了上海交通大学温颖教授关于大模型时代 Agent 的研究,包括提出将大模型视为 Agent 及 POAD 策略优化方法,阐述其开发初衷、算法结构、评测结果,还探讨了未来研究方向及大模型对 Agent 研究的影响、AI 与人的协作方式。
3.
主要内容:
– 温颖教授在大模型时代的 Agent 研究,提出“将大模型视为一个 Agent,Prompt 是在线强化学习”的观点。
– 团队提出创新策略优化方法 POAD,应用于多智能体强化学习框架,推动“通才”Agent 研究。
– 解决语言智能体动作优化中存在的问题,如预定义动作集合和 Token 细粒度信用分配问题。
– 介绍 POAD 的模型架构,带有动作分解的贝尔曼备份(BAD),保证优化结果一致性。
– 展示 POAD 在不同场景下优化后的 Agent 性能对比结果。
– 开发 POAD 的初衷是对前一工作中 Token Level 策略优化部分的深入探索,提升策略优化效率,解决不一致性和性能损失问题。
– 解释 POAD 的算法结构,消除 Token Level 与 Action Level 贝尔曼方程更新过程的差距。
– 阐述 POAD 的评测结果,如更快的收敛速度、稳定性和在开放空间的优势,精准的信用分配。
– 介绍未来研究方向,包括结合强化学习优化策略、扩展到多语言智能体合作场景、利用非量化反馈等。
– 探讨大模型对 Agent 及多 Agent 研究的变化。
– 思考 AI 与人未来的协作方式。
思维导图:
文章地址:https://mp.weixin.qq.com/s/Z9bvD1xmEdlIfys7-0OyLA
文章来源:mp.weixin.qq.com
作者:参赞生命力
发布时间:2024/7/25 11:35
语言:中文
总字数:4758字
预计阅读时间:20分钟
评分:87分
标签:大模型,Agent,策略优化,强化学习,多智能体系统
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

时隔一年,我们再次访谈了上海交通大学人工智能学院/约翰·霍普克罗夫特计算机科学中心的长聘教轨副教授温颖。温教授在大模型之前的 Agent 研究基础上,持续深入探讨了大模型时代的 Agent 研究,提出了许多跨 AI 时代的重要观点。他在此次访谈中分享了一个新颖的见解,即“将大模型视为一个 Agent,Prompt 就是让 Agent 进行一整套在线强化学习”。他和团队提出了一种创新的策略优化方法——POAD,应用于多智能体强化学习框架中,能够推动“通才”Agent 的研究,今天的文章将聚焦在他的最新研究 POAD 上。Enjoy

《Reinforcing Language Agents via Policy Optimization with Action Decomposition》
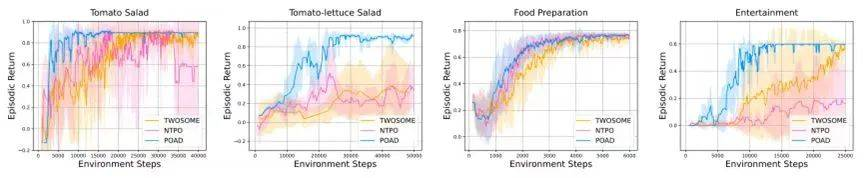
经过 POAD 优化后的 Agent 性能对比
经朴素的 Token 层策略优化 NTPO 后的 Agent 性能
*上海交大温睦宁同学是本文的第一作者,同时也参与了该篇讲稿的校对
绿洲:请帮我们简单介绍一下您在 Agent 的研究方向?
温老师:我过去研究多智能体强化学习,其基础是深度强化学习,需要 Agent 自主感知环境并采取相应的动作完成特定目标。之前我们在强化学习里看到的多智能体更多是“专才”Agent,给定任务的动作、空间,转移函数和奖励函数,Agent 需要通过和环境的不断交互,学习最优策略。在多智能体场景下,Agent 除了与环境交互还需要和其他智能体做交互,最终学会一个能与任意智能体合作或竞争的策略。
但“专才”存在一些样本效率和泛化性的问题,就比如一个 Agent 学会了下围棋就很难再学会打星际争霸。这样的情况持续到 2022 年底大模型爆发之前,我们发现大规模数据进行预训练-微调可以有效提升模型泛化能力,我们便开始了“通才”Agent 的研究,包括在大量决策轨迹数据上从头训练决策(动作)大模型,或在预训练好的语言或多模态大模型之上,加上工具使用、记忆模块等模块设立好框架,构建语言/多模态智能体,并通过强化学习等方法,让智能体不断与环境、其他智能体及人交互,通过各类反馈信号进行持续的学习。
绿洲:请帮我们解释一下开发 POAD 的初衷?
温老师:我们在投入 POAD 工作之前还有另外一篇工作《Entropy-Regularized Token-Level Policy Optimization for Large Language Models》,当时我们想建立起语言智能体在预训练(离线模仿学习)与强化学习在线策略优化阶段统一的学习目标,实现智能体专业任务与通用世界认识的持续提升(注:类似“行万里路”的同时“读万卷书”)。但这个工作暂时还没特别完善,所以和组里博士生温睦宁讨论之后,我们把其中的 Token Level 策略优化部分进行了更深入的探索,形成了 POAD 这篇工作。
我们发现语言 Agent 的动作空间巨大,一个动作由 3-5 个 Token 到上千个 Token 组成都有可能,而且动作空间大小是 Token 规模(Token Size)和组成动作 Token 数量的幂次方。之前的相关工作主要考虑已知合法动作空间的情况下对动作进行归一化(Normalization)处理。而睦宁同学的主要方向是对序列建模,之前一个工作 MADT(Multi-Agent Decision Transformer)就是把多智能体问题建模成一个序列。因此,在这个问题上,我们也想到从 Token Level 对语言智能体的动作进行分解,进行序列建模(Sequence Modeling),从而提升策略优化效率。但在这个时候我们又遇到了一个新的问题,即朴素地将动作分解为 Token 序列直接进行策略优化,实际上是在优化一个新的马尔可夫决策过程,从而导致其解决的优化问题与原先要解决的动作层马尔可夫决策过程优化问题是不一致的,并且这种不一致性会带来最终收敛策略的性能损失。于是我们开始尝试从理论上去量化这个差距,进而探索消除它的方法,最终得到了 BAD 与 POAD。
绿洲:您和睦宁前一份工作主要是做什么?
温老师:其实前面那份工作我们的目标还要更大一些。我们当时思考大模型的训练从强化学习来说是专家模仿学习方式,所有的文本、字符、数据都是人产生出来的,然后用下一个单词预测(Next Word Prediction)的方式做基础的预训练。那如果我们把大模型本身当作一个 Agent,然后它在环境中做交互的时候进行在线学习(Online Learning),这是一种交互式的强化学习,需要不断地在模型中探索采样策略,根据这些采样出来的轨迹或者数据评估大模型 Agent 的每一个状态、动作的结果,再用强化学习去进行策略提升,最终达到最优的策略,这是和模仿学习截然不同的学习目标,我们这篇文章最开始就是想做大模型两种学习方式的整合。
在整合过程中,我们并没有把学习目标统一流程设计得特别好,在优化过程中我们用到了一些 Token Level 的优化方法,因此引发出了 POAD 这篇工作,我们想持续优化这一种 Token Level 优化过程,结果我们发现这种优化方式确实特别高效,因此我们单独出了一篇 POAD 论文。
绿洲:请帮我们解释一下 POAD 的算法结构?
温老师:在 POAD 的算法主要是消除了 Token Level 与 Action Level 的贝尔曼方程更新过程的差距,以实现在 Token Level 对原始 Action Level 的 MDP 一致的策略优化。贝尔曼备份需要根据当前的奖励与未来状态下折扣值进行计算。当我们从 Action Level 的贝尔曼备份直接切换为 Token Level 的贝尔曼备份时,会从单个 Action 的折扣估计变为多个 Tokens 的折扣估计,导致和原始贝尔曼最优迭代的不一致。我们通过区分动作间折扣因子与动作内 Token 折扣因子来消除这种不一致性,保证 Token Level 和 Action Level 策略优化的一致性。
绿洲:请帮我们解释一下 POAD 的评测结果?
温老师:我们主要的评测都和传统的语言 Agent(GLAM 和 TWOSOME)进行对比,我们发现:
第一,POAD 能够提供更快的收敛速度和稳定性,这本质上意味着 POAD 更高的学习效率;
第二,传统强化学习优化方式受限于预设好的动作,我们需要做任何动作 Agent 都预先知道,因此在开放空间里进行一些优化的时候,POAD 会更有优势。类似于在数据科学等场景,需要进行很长很开放的代码编写时,POAD 会取得更好的效果。
在强化领域研究一个很重要的点就是信用分配,因为奖励很多情况都是延迟的,如何更好地估计动作对未来的影响,对策略学习效率很重要。我们把原先的动作拆分到更细的层面,更精准的信用分配方法,我们希望未来我们在给出任务关键词的时候,能够让 Agent 更准确地完成,不让细分的动作 Token“吃太多亏”,不让特定动作 Token 受到别的 Token 反馈影响。
POAD 本身是通用的优化策略,做 Token Level 的优化的优势是在奖励比较稀疏的场景中,或者动作序列比较长的场景中,或者无法预定义的开放场景中,POAD 能够更准确地解决策略优化问题。之后我们也会尝试在具身场景进行机器人大脑层面的策略优化,机器人大脑本质上是做任务的分解和规划,每一个子任务都能看做一个动作任务,我们准备尝试在这些任务中精准调一调完成目标。
绿洲:您下一步准备做什么?
温老师:我们本身是做强化学习研究的,强化学习不管是和其他 Agent 或是和环境做交互式学习之后获得反馈之后进行学习,从任务里面获得一些反馈,如何把反馈更好地利用起来进行策略学习是我们一直在思考的问题。
所以,针对语言智能体或者多模态智能体(注:这里指在预训练好的语言或多模态大模型的基础上构建的智能体,我们是这么思考的)。
首先,针对有量化反馈的任务,每一个任务都有一套成功与否的标准,我们想继续探索如何能结合强化学习进行更高效的策略优化。在这个基础上,我们也希望能把相关研究扩展到多个语言智能体合作的场景,比如直接对现在很多的多语言智能体框架(各自有不同的分工,需要人工设定角色和交互模式),使用合作多智能体强化学习算法进行统一优化,甚至自动化学习形成不同合作模式。
此外,我们希望能将智能体交互过程中更多的非量化的反馈利用起来,进行持续学习。因为现实世界中,例如评价、点击、停留时长这些无法用准确数字来进行量化的反馈,其实非常重要,我们需要思考如何更好地收集这些信号,并且也把这些信号做到反馈的过程当中去,这个中间转换的过程,是用奖励模型(Reward Model)还是用其他方式,都值得我们去思考,最终帮助大模型迭代学习。但反馈的方式太多样了(笑),质量也参差不齐,如何去定义和划分,我们一直在思考。今年暑假我们组内组织了一系列 AI Agent Workshop,其中一个课题就是一起探索语言智能体的自我提升及反馈提升策略,到时候也会分享有没有新的发现。
绿洲:您认为大模型的出现为 Agent 以及多 Agent 研究产生了什么变化?
温老师:大语言模型本身还是抽象层次太高了,通用性和泛化性看起来比较强,但其实很难直接解决传统需要精细控制的强化学习任务,所以我们认为专业垂直场景上,很难把已经预训练好的大模型直接用起来,还需要人为把任务进行抽象,在更高层次上把预训练好的大模型与强化学习策略结合。
不过,大模型预训练-微调的思路也对强化学习训练的范式有启发,借鉴预训练搜集大规模数据、扩大模型参数量思路进行预训练,再做一些在线的训练和学习,也能在一些任务比较相近的场景提高泛化性能。但在任务差异比较大的情况下,预训练也不能很好地学习与泛化。譬如,在机器人场景下,可以收集很多专家轨迹做预训练的路径,最后做一些在线学习的微调,考虑动作层抽象程度不同的情况下,使用不同的模型与算法。对于动作层次低的场景,我们就用以前强化学习或离线预训练的方法去学决策/动作大模型,高层次规划可以使用以语言大模型为主的方法去解决。
此外,我们也可以借助一些语言大模型或视觉语言模型的语言和场景理解能力,自动化设计一些更好的奖励函数,写一些规则判断它会达到什么状态,减少人工工作量,让强化学习更容易跑起来。
绿洲:您如何看待 AI 与人未来的协作方式?
温老师:AI 最终的目标是辅助人更好地完成任务。先不考虑 AI 完全主导的模式,当 AI 与人进行平等协作任务时,人拥有一个黑盒的主观意识,在这个过程中,我们怎么让 AI 能主动估计人的一些想法和目的,去结合 AI 的能力,达成和人更好的配合,是我们目前在研究的方向。当然,这个事情在一般性的任务上很困难,因为任务比较开放,而且每个人都有自己的不同的主观想法,很难实现通用的人类意图的推断;但在特定场景中,我们可能能够实现对不同任务特点的分析,实现高效的人机协作,比如机器协同人完成装配等类似的任务。
此外,AI 越来越渗透到我们各种服务和产品中,但 AI 不是万能的,更多场景下是 AI 辅助人的模式。我们需要同时考虑 AI 的长处和缺点,以及人的习惯和特性,并做相应的优化,以实现整体效用的最大化。例如人很难对数据块本身进行量化打分,但人很容易做数据的比较或选择题,我们可以通过这种方式进行人类偏好的标注,再建立奖励模型去训练 AI 进行对齐。


