包阅导读总结
1.
关键词:Meta、Llama 3.1、开源 AI 模型、英伟达 H100 GPU、性能提升
2.
总结:Meta 于当地时间 7 月 23 号发布开源 AI 模型 Llama 3.1,其规模庞大、性能强大,在多项测试中表现出色,训练使用大量英伟达 H100 GPU,成本高昂但坚持开源,并推动了开源策略与生态系统的发展。
3.
主要内容:
– Meta 发布开源 AI 模型 Llama 3.1
– 模型有三个版本,最大的 405B 参数版本是近年来最大开源模型
– 总下载量超 3 亿次
– 模型评估
– 多方面能力提升,在多项基准测试中表现出色
– 小型模型性能有竞争力
– 模型能力与应用
– 上下文窗口达 128K,多语言支持
– 能集成搜索引擎 API 及调用工具,暂不支持多模态
– 可在云平台下载使用,已用于 Meta 相关产品
– 模型规模与训练
– 使用超 1.6 万个英伟达 H100 GPU 训练
– 对训练堆栈优化,选择标准模型架构,改进数据处理
– 开源策略与生态系统
– 坚持开源,与 20 多家公司合作
– 解决许可条款问题,进行“红队测试”,但训练数据来源有争议
思维导图: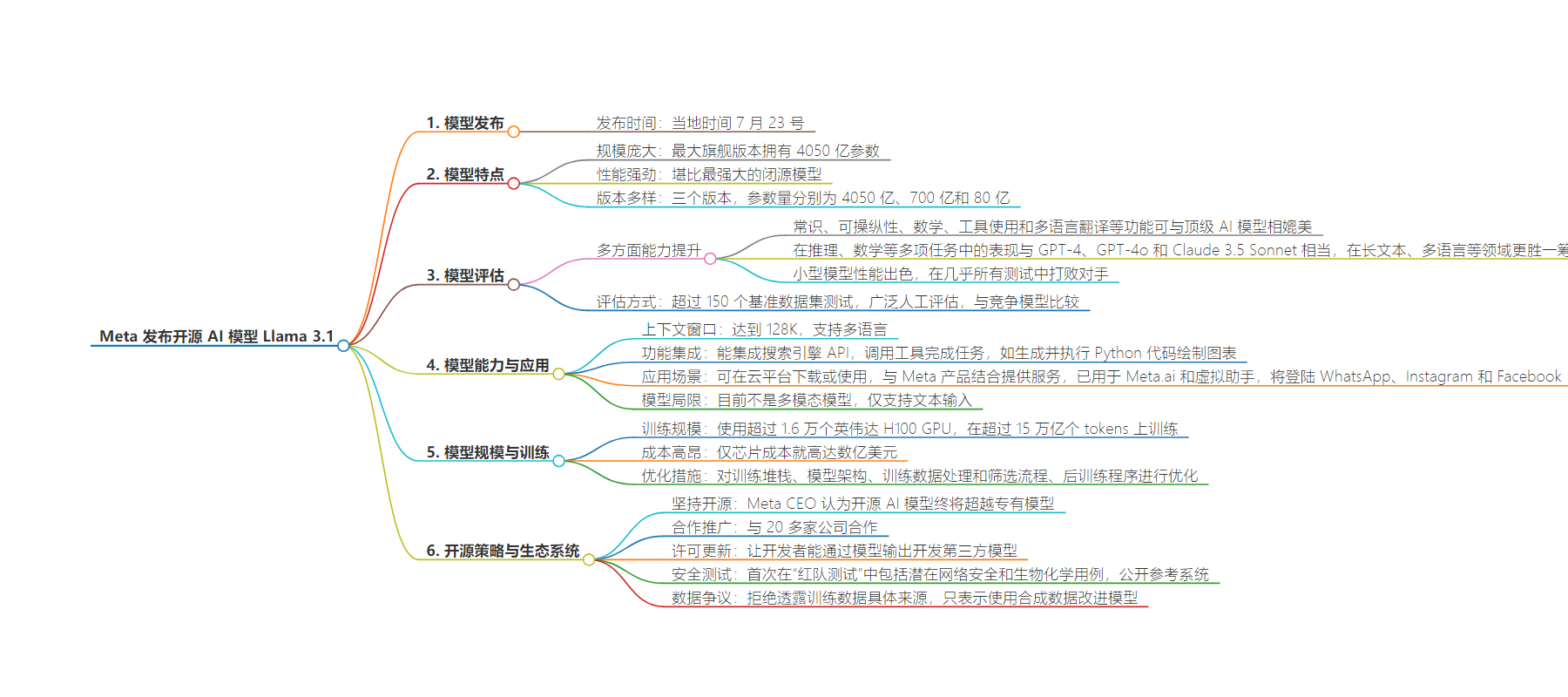
文章地址:https://mp.weixin.qq.com/s/qGQkb0QCmf8M3KOdhafjwQ
文章来源:mp.weixin.qq.com
作者:Ren
发布时间:2024/7/24 7:39
语言:中文
总字数:2290字
预计阅读时间:10分钟
评分:87分
标签:开源AI模型,Meta,Llama 3.1,GPT-4,Claude 3.5 Sonnet
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Meta发布开源AI模型Llama 3.1,训练期间大约使用1.6万个英伟达H100 GPU
当地时间 7 月 23 号,Meta 公司发布了迄今为止最强大的开源 AI 模型 Llama 3.1。该模型不仅规模庞大,性能也堪比最强大的闭源模型。这称得上是开源 AI 领域的一个重要里程碑。
Llama 3.1 模型家族总共有三个版本,规模最大的旗舰版本拥有 405B(4050 亿)参数,是近年来最大的开源 AI 模型。其余两个较小版本的参数量分别是 700 亿和 80 亿。
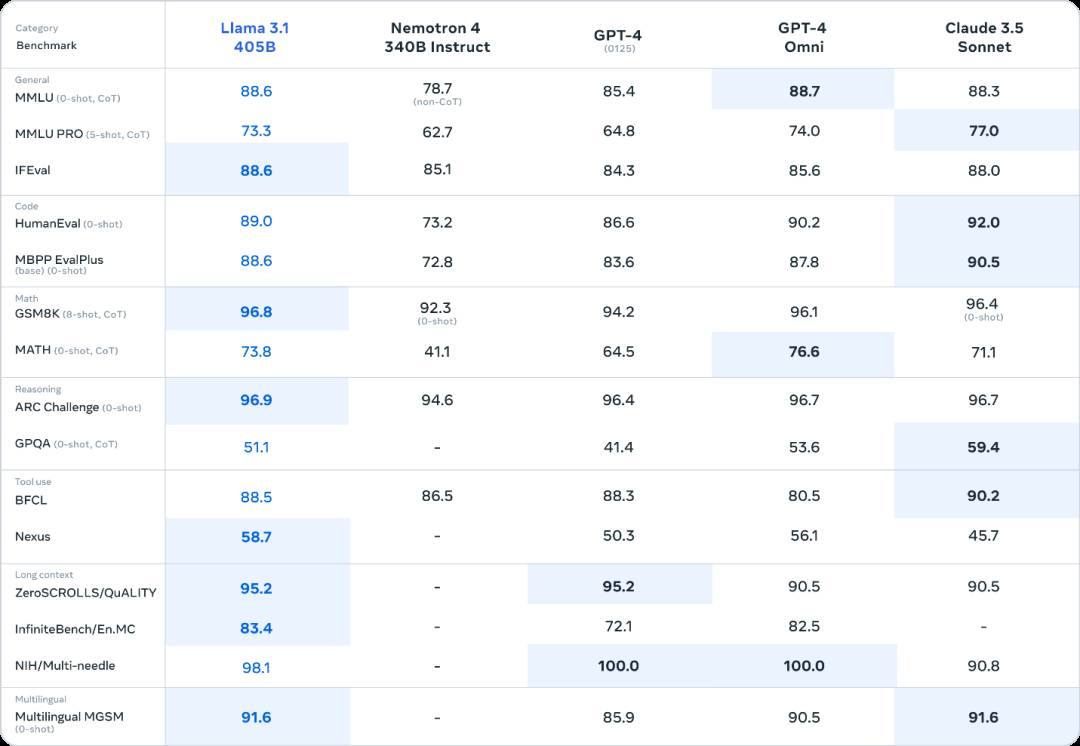
Meta声称,Llama 3.1 405B 模型在多项基准测试中的表现超过了 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet。
“到目前为止,开源大型语言模型在功能和性能方面大多落后于闭源模型。现在,我们正迎来一个由开源引领的新时代。”
Meta在官方博客中写道,“迄今为止,所有 Llama 版本的总下载量已超过 3 亿次,而这仅仅是个开始。”
据介绍,Llama 3.1 系列模型展现了多方面的能力提升,在常识、可操纵性、数学、工具使用和多语言翻译等功能方面可与顶级 AI 模型相媲美。
Meta对 Llama 3.1 进行了全面的评估,包括超过 150 个基准数据集的测试,涵盖多种语言和任务类型。
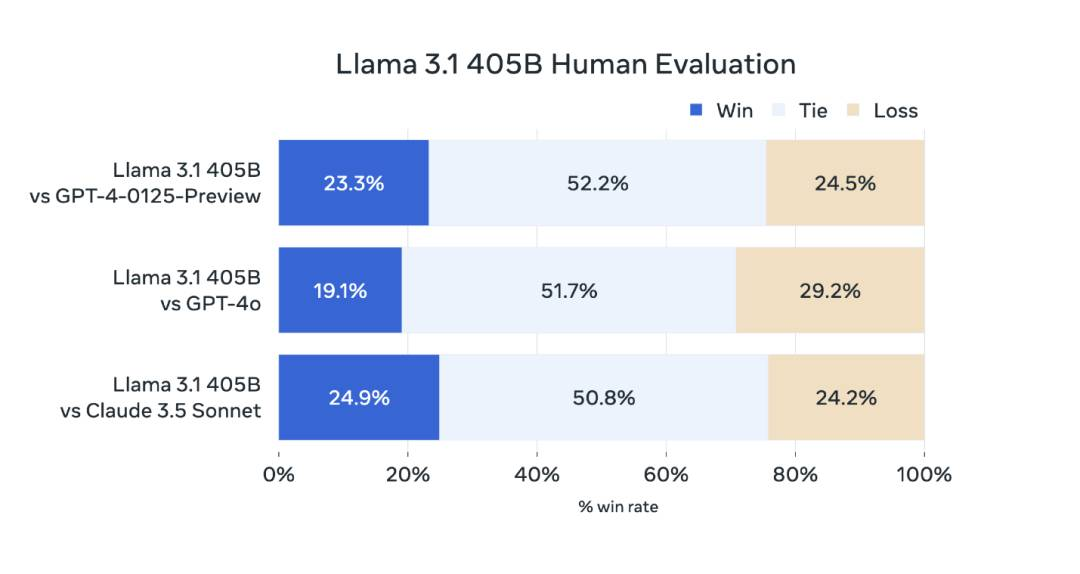
此外,该模型还经过了广泛的人工评估,与竞争模型在真实应用场景中进行比较。
总体而言,Llama 3.1 405B 模型在推理、数学等多项任务中的表现与 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 相当,在长文本、多语言等领域甚至更胜一筹。
不过在代码基准测试中,Llama 3.1 405B 模型的表现不如 Claude 3.5 Sonnet。
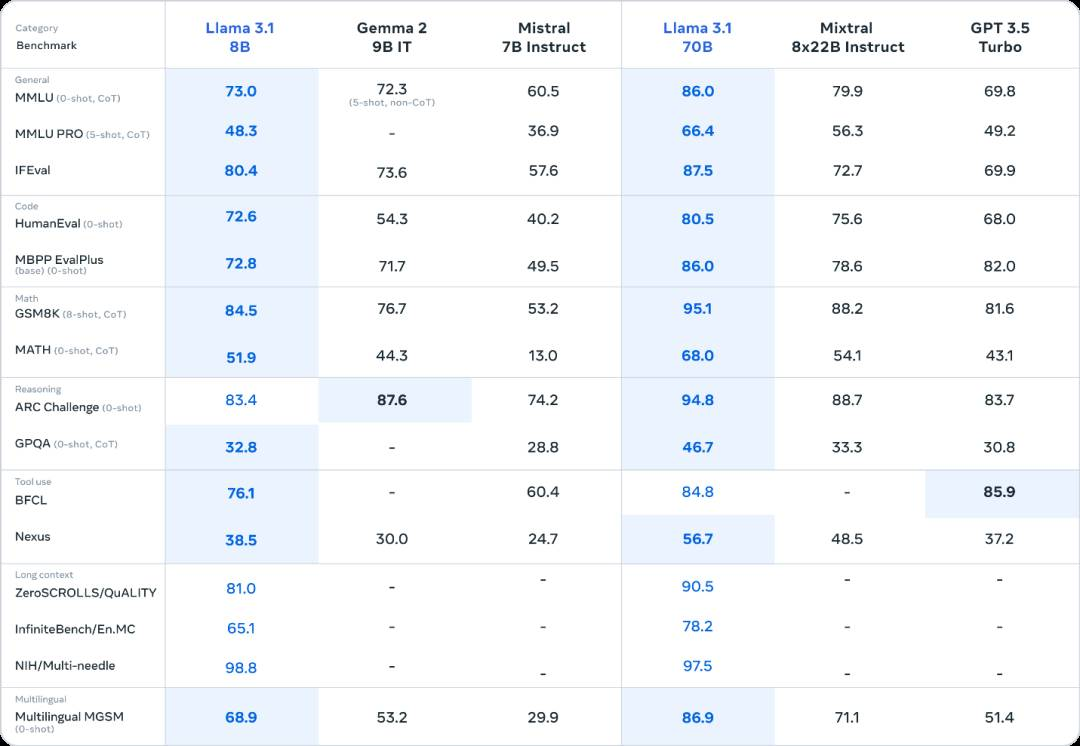
此外,在小型模型性能对比中,Llama 3.1 的 8B 和 70B 模型均表现出色,与同等规模的闭源和开源模型相比具有很强的竞争力,在几乎所有测试中都打败了对手。
Meta表示,Llama 3.1 系列模型的上下文窗口达到了 128K,相当于一本 50 页的书,并且提供英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语等多语言支持,大大提升了长文本和多语种内容的处理能力。
Meta生成式人工智能副总裁艾哈迈德·达尔(Ahmad Al-Dahle)表示,Llama 3.1 模型能够集成搜索引擎应用程序编程接口(API,Application Programming Interface),根据复杂查询从互联网检索信息,并调用多个工具完成任务。例如,它可以生成并执行 Python 代码来绘制图表。
不过,Llama 3.1 目前还不是多模态模型,仅支持文本输入。但 Meta表示,正在开发能识别图像、视频,并理解(和生成)语音的 Llama 模型。
在应用方面,与之前的 Llama 模型一样,Llama 3.1 405B 可在亚马逊 AWS、微软 Azure 和谷歌 Cloud 等云平台上下载或使用。它还会与 Meta 的产品结合,为用户提供聊天机器人和信息查询等服务。
该模型目前已经用在 Meta.ai 和 Meta AI 虚拟助手上。从本周开始,Llama 3.1 将首先登陆 WhatsApp 和美国的 Meta.ai 网站,随后几周将上线 Instagram 和 Facebook。
虽然最先进的 Llama 3.1 405B 模型可以在 Meta.ai 上免费使用,但每周提示数量有限(上限不详),超过限制则会切换到更小的 70B 模型。这似乎表明 405B 模型对于 Meta来说还是太昂贵了,无法全面运行。
Llama 3.1 405B 模型的训练规模令人惊叹。
Meta使用了超过 1.6 万个英伟达 H100 GPU,在超过 15 万亿个 tokens(的数据集)上进行训练,相当于 7500 亿个单词。
尽管 Meta没有透露具体的开发成本,但仅根据其使用的英伟达芯片价格估算,成本就已高达数亿美元。
Meta对其整个训练堆栈进行了重大优化,以达到如此大规模的训练目标。
在模型架构方面,他们选择了标准的仅解码器 transformer 模型,而非混合专家模型,以最大化训练稳定性。
训练数据方面,Meta 通过改进处理和数据筛选流程,提高了训练数据的质量。
此外,他们还选取了迭代式的后训练程序,“每轮都使用监督微调和直接偏好优化,用高质量的合成数据不断提升模型性能”。
尽管开发成本高昂,Meta 仍坚持开源 Llama 模型。
Meta的 CEO 马克·扎克伯格(Mark Zuckerberg)在公开信中表示,相比专有模型,开源 AI 模型终将超越它们,并且已经在以更快的速度改进,最终和 Linux 一样,成为支持大多数手机、服务器和设备的开源操作系统。
他预测,“Llama 3.1 的发布将成为行业的一个转折点,未来大多数开发者更青睐于使用开源模型。”
为了推广 Llama 3.1,Meta 正与包括微软、亚马逊、谷歌、英伟达和 Databricks 在内的 20 多家公司合作,帮助开发者部署自己的模型。
Meta声称,Llama 3.1 在生产环境中的运行成本仅为 OpenAI的 GPT-4o 的一半左右。
与此同时,Meta 更新了 Llama 的许可条款,让开发者可以通过 Llama 3.1 模型的输出,来开发第三方 AI 模型。
这一变化解决了 AI 社区对 Meta 模型的一个主要批评,是公司积极争取 AI 领域话语权的一部分。
此外,为了确保模型的安全性和道德性,Meta 首次在 Llama 3.1 的“红队测试”(对抗性测试)中包括了潜在的网络安全和生物化学用例。
他们还公开了一个完整的参考系统,其中包括多个示例应用程序和新组件,如多语言安全模型 Llama Guard 3 和提示注入过滤器 Prompt Guard。
然而,关于训练数据的问题仍然存在争议。Meta 拒绝透露具体的数据来源,只表示使用了合成数据来改进模型。
总而言之,Llama 3.1 系列模型的发布,象征着开源 AI 模型在性能上第一次和顶级闭源模型相匹敌。这可能会对 AI 行业产生深远影响,推动更多创新和应用。
https://ai.meta.com/blog/meta-llama-3-1/
https://about.fb.com/news/2024/07/open-source-ai-is-the-path-forward/
https://www.theverge.com/2024/7/23/24204055/meta-ai-llama-3-1-open-source-assistant-openai-chatgpt
https://techcrunch.com/2024/07/23/meta-releases-its-biggest-open-ai-model-yet/
01/科学家用AI造材料,只需23个初始数据就能合成7种荧光碳量子点,并能精确控制发光机制
02/科学家研发光驱动纳米马达实现运动速度新突破,最高速可达125μm/s,或用于药物递送及精确成像
03/浙大校友实现光芯片上超快光-电子相互作用,有效补充已有光子学测量方法,实现100GHz级高重频电子束调控
04/科学家颠覆石墨烯不透性和化学惰性的传统认知,开发高精度气体跨膜输运探测技术,助力解决能源、化工等领域分离共性问题
05/聚焦端侧计算技术,这家“独角兽”量产模拟存内计算芯片,2年间让算力提升500倍
预览时标签不可点
![]()
微信扫一扫
关注该公众号
![]()
微信扫一扫
使用小程序
:,。视频小程序赞,轻点两下取消赞在看,轻点两下取消在看分享收藏