包阅导读总结
1. 关键词:Claude 爬虫、Anthropic、数据侵权、服务器攻击、版权问题
2. 总结:Anthropic 公司的 Claude 爬虫一天内上百万次访问技术网站,引发众怒。网站 CEO 指责其侵权未道歉,类似事件频发。应对措施有限,AI 发展中的版权问题待解,OpenAI 有商业合作但小网站仍艰难。
3. 主要内容:
– Claude 爬虫攻击:
– Anthropic 公司的 Claude 爬虫一天内上百万次访问 iFixit 技术网站,服务器负载剧增。
– Linux Mint Forums 等也曾遭其毒手,导致性能极差甚至访问中断。
– 网站方指责:
– iFixit 网站 CEO Kyle Wiens 指责 Anthropic 未经许可占用内容和资源。
– 未获道歉,Anthropic 给出甩锅博文。
– 应对措施:
– 通用做法是设置 robots.txt 文件,但防君子不防小人,ClaudeBot 不遵守。
– 可设假帖子追踪侵权,但胜诉难保证。
– 版权问题与合作:
– 本质问题是内容产出者版权保护,OpenAI 有商业合作,小网站合作艰难。
思维导图: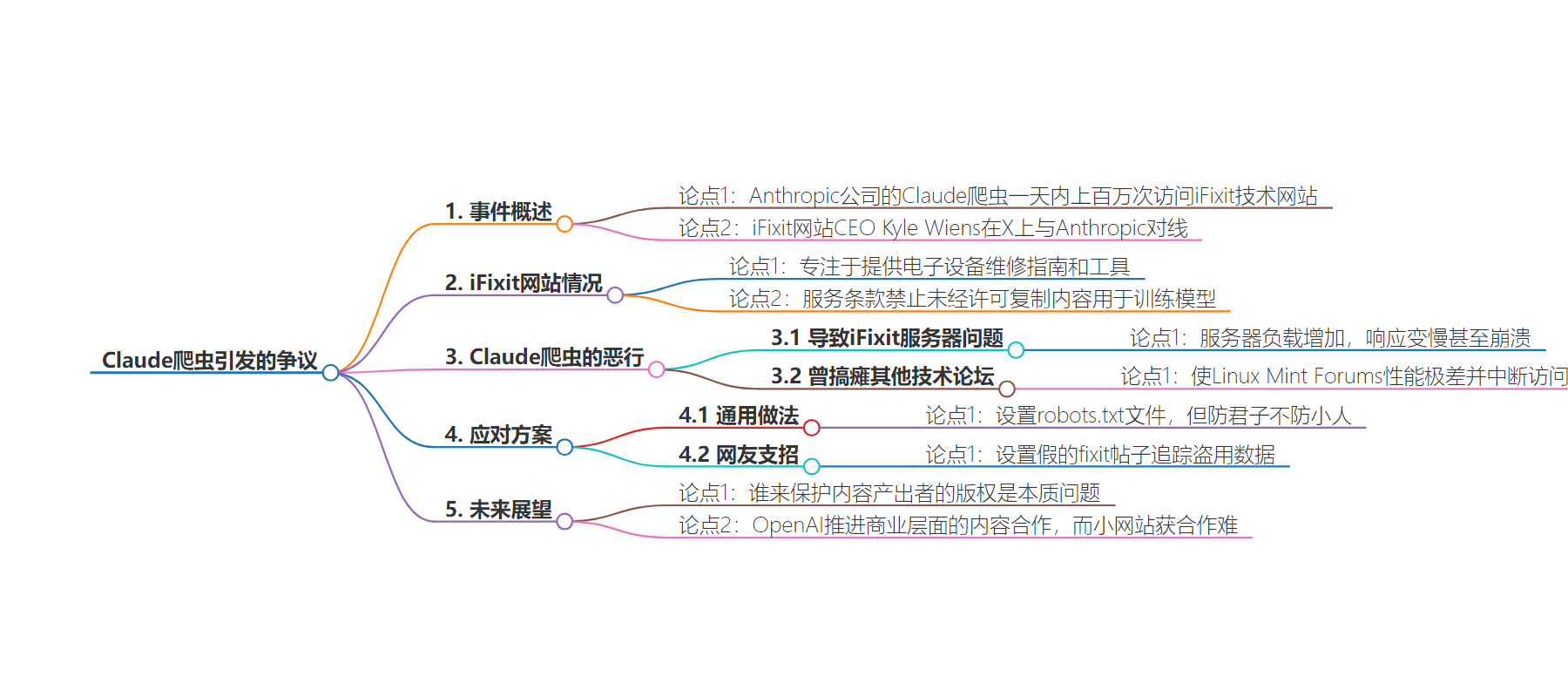
文章地址:https://mp.weixin.qq.com/s/Etoig9b75BGSNNede2qjbQ
文章来源:mp.weixin.qq.com
作者:51CTO技术栈
发布时间:2024/7/30 3:57
语言:中文
总字数:2741字
预计阅读时间:11分钟
评分:87分
标签:AI模型,网络爬虫,版权争议,数据抓取,伦理问题
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

忍无可忍了!
OpenAI最大的竞争对手Anthropic公司,为了让自家大模型Claude获得更多数据,直接用网络爬虫在一天内以百万次的速度访问了名为iFixit的技术网站。
直接把iFixit网站的CEO Kyle Wiens逼得在X上跟Anthropic对线!
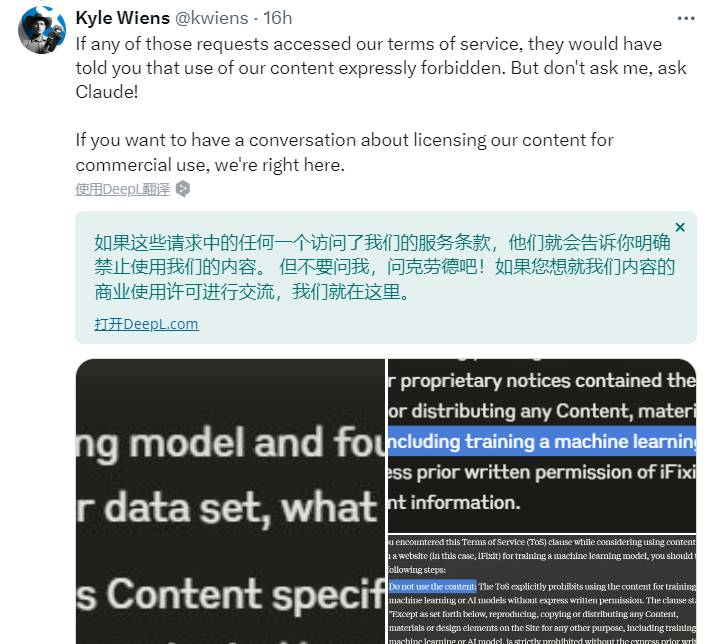
Kyle Wiens毫不客气地戳Anthropic脊梁骨:嘿,@AnthropicAl,我知道你想要数据。Claude确实很聪明!但你真的需要在24 小时内对我们的服务器进行上百万次的攻击吗?
你不仅白嫖占用了我们的内容,还占用了我们的开发资源。这可不酷。
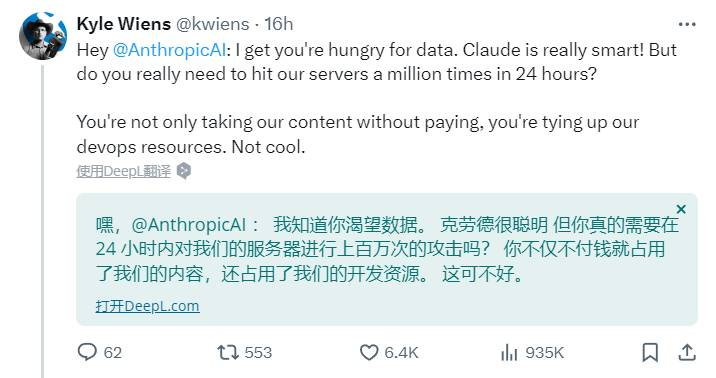
Kyle Wiens还阴阳了一把Anthropic说,“难道Claude的爬虫没有爬到我们网站的声明吗?”
因为在iFixit的服务条款里已经明确写了:“未经iFixit事先书面许可,严禁复制、复制或分发站点上的任何内容、材料或设计元素,包括用于训练机器学习或AI模型。”
令人愤怒的是,Anthropic并未向iFixit道歉,而是给了他一篇有甩锅意味的博文。博文里写道:
“根据行业标准,Anthropic使用各种数据源进行模型开发,如通过网络爬虫收集的公开可用数据。”“我们的爬取不应具有侵入性或干扰性。我们通过考虑在相同域中爬取速度和尊重适当的Crawl-delay来实现最小化的干扰。”

天降横祸:iFixit承受爬虫围攻
iFixit是一家专注于提供电子设备维修指南和工具的技术论坛。
iFixit的主要通过提供详细的拆解和维修指南,帮助用户自己动手维修设备,从而延长电子产品的使用寿命。
Kyle Wiens在接受外媒采访时讽刺地说,“我们只是世界上最大的维修信息库而已,他们未经许可偷走我们所有的数据并且在这个过程中把我们的服务器淹没,这也没什么大不了的。”
他补充说,iFixit的网站有数百万个页面,包括修理指南、这些指南的修订历史、博客、新闻帖子和研究、论坛、社区贡献的修理指南和问答部分等。
Wiens向媒体展示了网站的服务器日志,根据日志内容,Claudebot在几个小时的时间中,每分钟数千次的请求访问。
显然,爬虫过境会使得激增的访问量不断增加服务器负载,导致服务器响应时间变慢,甚至崩溃。
然而,这不是Claudebot的第一次惹祸,很可能也不是最后一次。

恶名在外:Claudebot罪行累累
搜索一下Claudebot,就会发现它已经是个惯犯了。
Claudebot疯狂起来直接将技术论坛搞到瘫痪数个小时。专注于Linux Mint操作系统讨论的Linux Mint Forums就曾惨遭毒手。
在ClaudeBot开始搜索和访问论坛后,导致该论坛在几个小时内性能极差,并最终导致了访问的中断。直到爬虫被防火墙阻止后,论坛性能才恢复正常。

Linux Mint Forums恢复后在声明中说:Anthropic正在通过免费搜索网站来训练AI。他们这样做会给网站带来大量额外负载,这实际上是一种 DDos 攻击。
因此,有人直接评价Claudebot为“近年来,在我的服务器上遇到的最惹人烦的爬虫机器人”。并说将屏蔽一切与Claude有关的内容。

Reddit上也有篇帖子吐槽Claudebot太过积极,更加不讲理的是Claudebot似乎直接开大绕过了他的robots.txt文件。
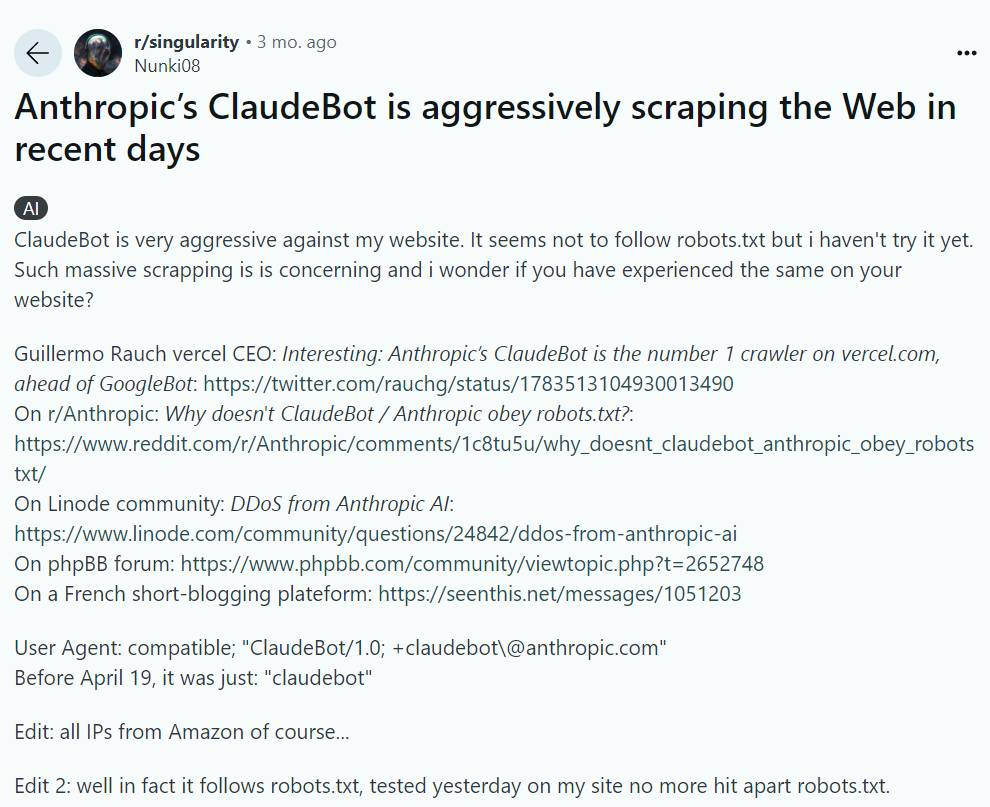
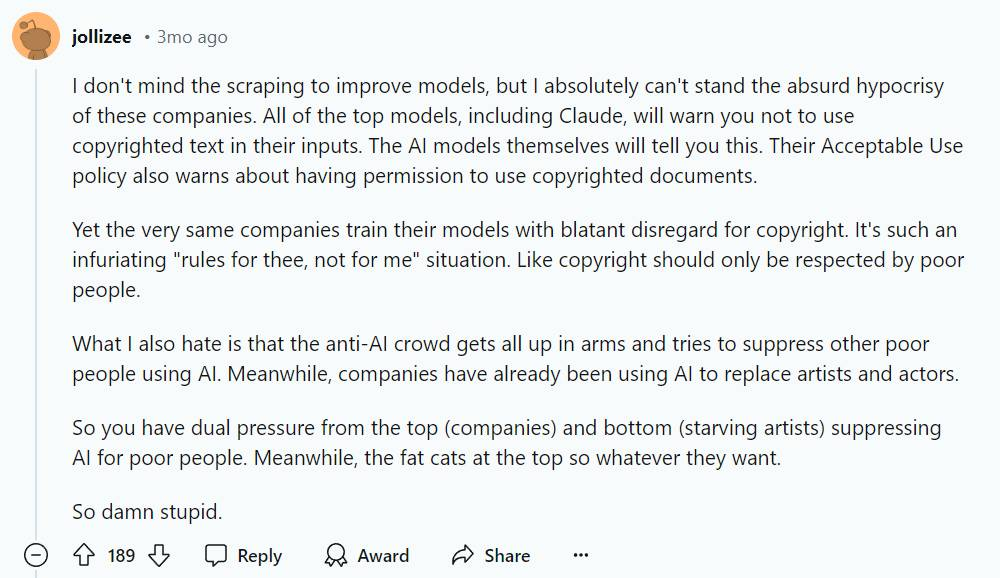
这篇帖子引起了广泛的共鸣,有人回应说,“我不介意通过爬虫获取数据来改进模型,但我绝对无法忍受这些公司荒谬的虚伪行为。
包括Claude在内的所有顶级模型都会警告你不要在输入中使用受版权保护的文字。人工智能模型本身也会告诉你这一点。
然而,这些公司在训练它们的模型时,却公然无视版权。这种 “只许州官放火,不许百姓点灯 “的情况实在令人恼火。
我还讨厌的是,反人工智能的人群大动干戈,试图压制其他穷人使用人工智能。因此,来自上层(公司)和下层(饥饿的艺术家)的双重压力都在压制其他穷人使用人工智能。这太愚蠢了。”

应对方案:有是有,但不完美
几乎所有的AI公司都不会遵守网站的服务条款。
就像Anthropic硬气声明自己是遵从“行业标准”那样,通过网络爬虫收集的公开可用数据是通用做法。所以,即使网站已要求其服务条款中的内容不得被抓取,但通常没有任何作用。
一个对抗LLM爬虫的通用做法是设置robots.txt文件。
这是一个放置在你网站根目录中的文件,用于告诉网络爬虫和机器人哪些部分可以访问。
以下是一个robots.txt的设置(部分),感兴趣的朋友可以移步查看代码解析:
https://neil-clarke.com/block-the-bots-that-feed-ai-models-by-scraping-your-website/

然而,这是一种防君子不防小人的应对策略——只有行为良好的爬虫会遵守这些指令,而ClaudeBot显然不在此列。
Reddit上有网友证实了这一点“我听出版商说,ClaudeBot 会忽略 robots.txt 说明。在 Anthropic 被亚马逊或其他担心诉讼的大公司收购之前,你能做的不多。”

也有人向Kyle Wiens支招:可以故意设置一些假的 fixit帖子,这样你就能追踪到是谁盗用了你的数据。例如发一个提问贴,询问“如何更换 Dipsogenic Hampoon(编造的设备) 的电池……”
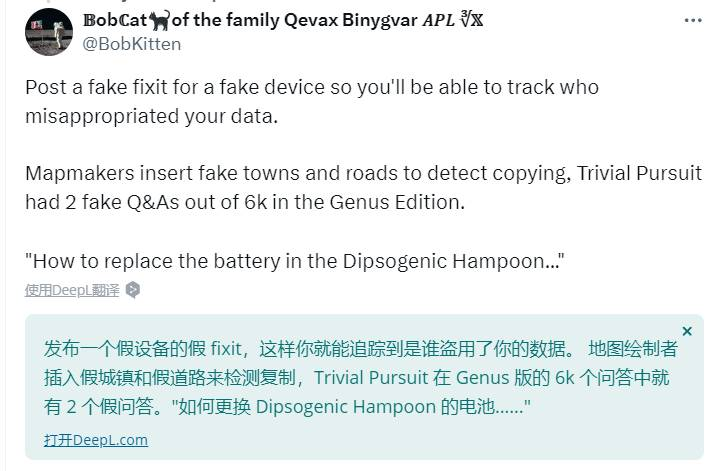
这是一个处理版权问题的常用做法,即编辑刻意添加虚假条目,作为版权陷阱,以揭露随后的抄袭或侵权行为。
然而即使能通过这种方式取证Anthropic们的侵权行为,但是否能保证胜诉呢?
目前,涉及AI公司使用爬虫侵犯网站内容的判例还不多。许多现有的案例集中在网站条款的执行、数据抓取的合理使用和版权问题上。例如,LinkedIn曾对数据抓取公司HiQ Labs提起诉讼,最终法院裁定HiQ Labs的行为部分不合法。

展望未来:艰难探索中的商业合作
显然,人工智能的爬虫滥用是一个表面问题,更加本质的问题在于,谁来保护技术论坛、新闻机构等内容产出者的版权?
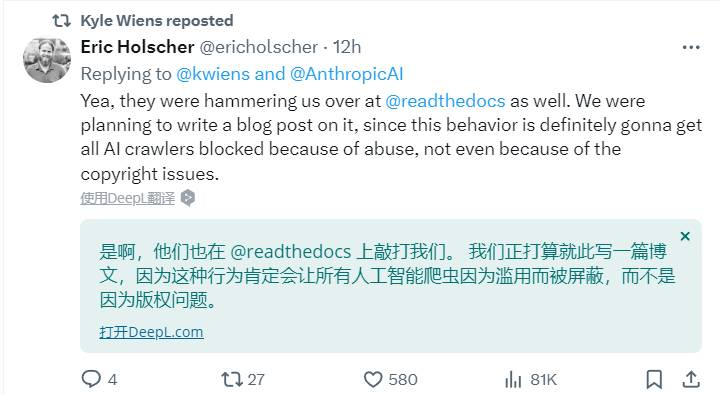
在AI广泛发展的今天,这个问题不仅出现在海外,也在国内。此前,有网友发现字节系的豆包AI不仅了解自家小说APP上的网文,连“十年前的贴吧文”、“晋江VIP文章”都可以进行阅读和提问。如果此事属实,如此大规模的涉猎很难不依靠爬虫的介入。

就像Kyle Wiens喊话Anthropic时所说的,如果AI模型如此需要数据的话,不如大大方方地付费,来获得内容的商业授权。
当然,AI在版权问题上并非毫无长进。
在收到多次诉讼之后,OpenAI已经在推进商业层面的内容合作。OpenAI与GitHub、 Reddit以及多家新闻机构签署了合作和授权协议。
今年5月,OpenAI更是 与News Corp新闻集团签署了一项具有里程碑意义的多年期协议,允许AI模型访问《华尔街日报》、《纽约邮报》、《巴伦周刊》、《市场观察》等主要出版物的内容。据估计,该协议在五年内价值超过 2.5 亿美元。

但是,那些能得到版权合作的网站注定是大的新闻机构和社区。像iFixit这样垂直的技术网站,如果要得到AI公司的内容合作,不知道还要等多久、能不能等到这一天。
参考链接:
https://www.404media.co/anthropic-ai-scraper-hits-ifixits-website-a-million-times-in-a-day/