
包阅导读总结
1. 关键词:OpenAI、超级对齐、验证器、鲁棒性、对抗样本
2. 总结:OpenAI 发布“最后一篇”超级对齐论文,指出验证器规模过小会致训练不稳定,过大难以提高多轮训练鲁棒性,千分之一到百分之一效果最佳。恶意解法错误随训练细微和局部化,验证器促使奸诈证明器生成更接近真实解法的对抗样本,训练轮数增加时人类评估者在奸诈证明器上准确率下降。
3. 主要内容:
– OpenAI 发布超级对齐相关论文
– 探讨验证器规模的影响
– 太小导致训练不稳定
– 太大难以在多轮训练中提高鲁棒性
– 规模为千分之一到百分之一效果最佳
– 恶意解法中的错误变化
– 随训练越来越细微和局部化
– 验证器的作用
– 推动奸诈证明器生成更接近真实解法的对抗样本
– 训练轮数增加的影响
– 人类评估者在奸诈证明器上的准确率下降
思维导图: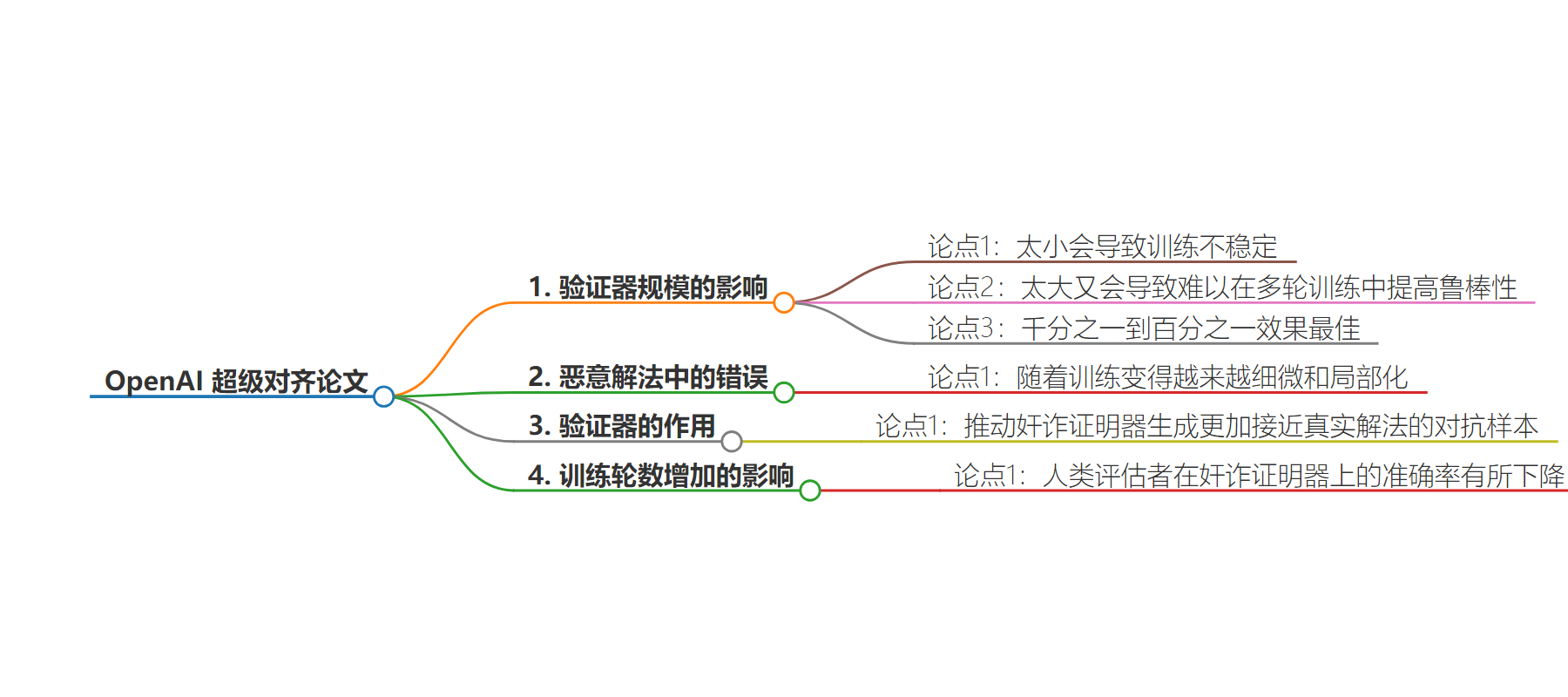
文章地址:https://mp.weixin.qq.com/s/PxV-QIZoIVc84pg0djbnig
文章来源:mp.weixin.qq.com
作者:硅星人Pro
发布时间:2024/7/19 1:59
语言:中文
总字数:2387字
预计阅读时间:10分钟
评分:91分
标签:博弈论,AI研究,模型训练,OpenAI,可理解性
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
-
验证器规模的影响:太小会导致训练不稳定,太大又会导致难以在多轮训练中提高鲁棒性,证明器的千分之一到百分之一效果最佳。
-
恶意解法中的错误随着训练变得越来越细微和局部化,说明验证器推动了奸诈证明器生成更加接近真实解法的对抗样本。
-
随着训练轮数增加,人类评估者在奸诈证明器上的准确率有所下降。