
包阅导读总结
1. 关键词:AI 训练数据、模型崩溃、垃圾信息、困惑度分数、数据质量
2. 总结:新研究表明,AI 在自身生成的数据上训练会致质量下降和模型崩溃,以 GPT-3 为例说明问题严重性,研究通过实验和类比解释现象,强调高质量多样化训练数据重要,虽有解决思路但数据来源追踪和过滤未完全解决。
3.
– 人工智能模型通过互联网海量数据训练,但生成的垃圾信息威胁训练过程。
– 牛津大学计算机科学家 Ilia Shumailov 研究发现,AI 在自身生成的数据上训练,模型输出质量逐渐下降。
– 以拍照类比,说明反复过程会被“噪声”淹没,最终导致模型崩溃。
– 该研究对大型模型如 GPT-3 有重大影响,因它们用互联网数据。
– 研究通过特定实验衡量对性能潜在影响,用“困惑度分数”评价,结果显示后续模型分数更高。
– 以具体例子说明模型输出的荒谬。
– 未来模型训练或需合成数据,解决依赖数据规模和质量问题。
– 专家认为基础模型依赖数据规模,需精心策划控制,用合成数据解决。
– 但要避免模型崩溃需高质量多样化数据,添加合成数据而非替换现实数据。
– 确保模型给原始人类生成数据更多权重等思路可减轻负面影响,但数据来源追踪和过滤未完全解决。
思维导图: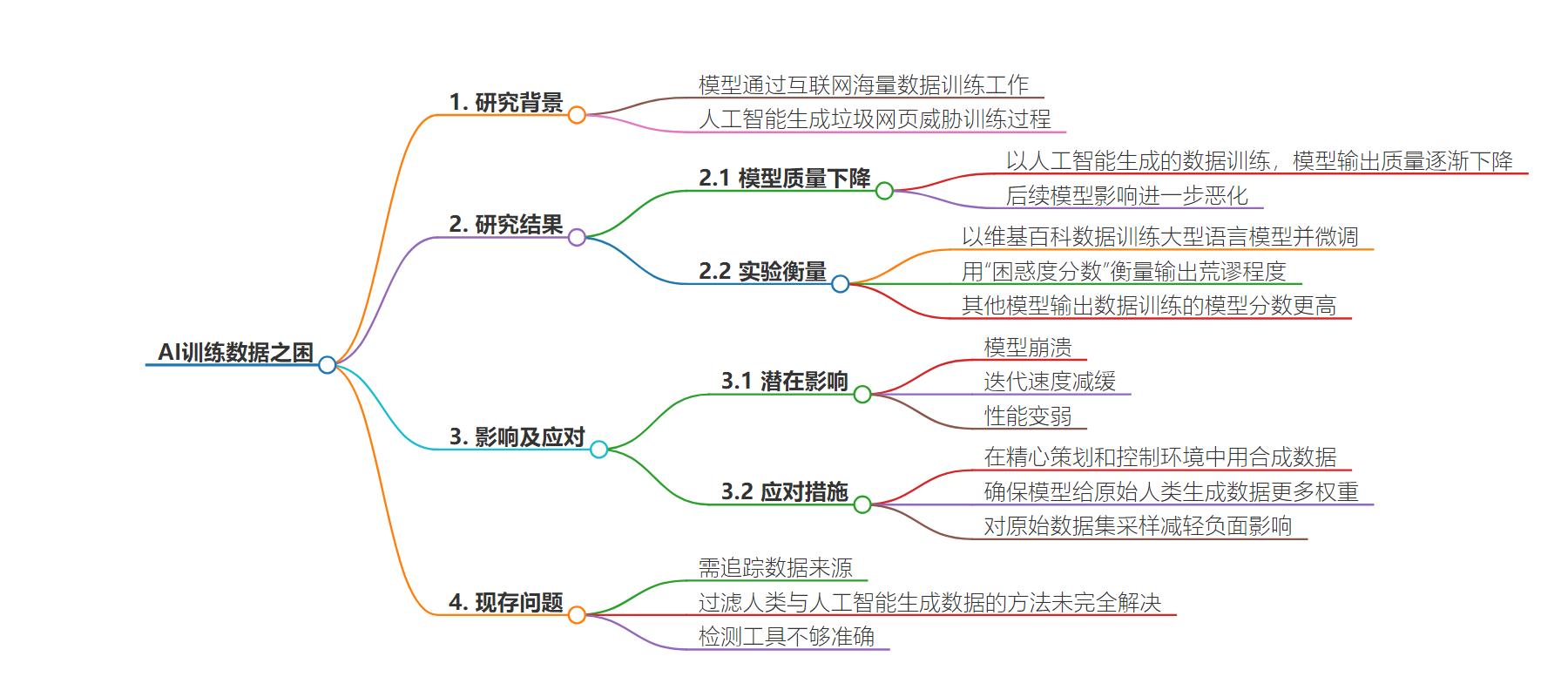
文章地址:https://mp.weixin.qq.com/s/I1eMP6cnsBZeYrgTt1xZKg
文章来源:mp.weixin.qq.com
作者:Scott??J??Mulligan
发布时间:2024/7/28 5:44
语言:中文
总字数:1913字
预计阅读时间:8分钟
评分:88分
标签:AI训练数据,模型崩溃,数据质量,人工智能生成内容,牛津大学
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。
近日,发表在 Nature 杂志上的一项新研究表明,当人工智能在人工智能生成的数据上进行训练时,模型输出的质量会逐渐下降,随着后续模型输出的数据被用作未来模型的训练数据,影响会进一步恶化。
(来源:Nature)
领导这项研究的牛津大学计算机科学家 Ilia Shumailov 将这一过程比作拍照。“如果你拍了一张照片,扫描、打印出来并再对其拍照,然后不断重复这个过程,随着时间的推移,基本上整个过程都会被‘噪声’淹没。最后,你会得到一个黑暗的方块。”他说道。在人工智能领域,黑暗方块相当于“模型崩溃”,这意味着模型只会生成不连贯的垃圾。
这项研究可能会对当今最大的人工智能模型产生重大影响,因为它们使用互联网作为数据库。例如,GPT-3 的部分训练数据来自 Common Crawl,这是一个包含超过 30 亿个网页的在线存储库。随着越来越多的人工智能生成的垃圾网页开始充斥互联网,这个问题可能会变得更糟。
Ilia Shumailov 表示,当前的人工智能模型不仅会崩溃,而且可能会带来实质性影响:迭代速度减缓,性能越来越弱。
为了衡量和确定对性能的潜在影响,Ilia Shumailov 和他的同事根据维基百科的一组数据对大型语言模型(LLM)进行训练,然后根据 9 代的输出数据对新模型进行微调。他们使用一个名为“困惑度分数”的评价标准来衡量输出的荒谬程度,“困惑度分数”反映人工智能模型对未来序列部分预测能力,分数越高,模型的准确度就越低。
最终,在其他模型的输出数据上进行训练的模型具有更高的“困惑度分数”。例如,对于每一代,团队在输入以下内容后向模型询问下一个句子:
“some started before 1360—was typically accomplished by a master mason and a small team of itinerant masons, supplemented by local parish labourers, according to Poyntz Wright. But other authors reject this model, suggesting instead that leading architects designed the parish church towers based on early examples of Perpendicular.”
“根据 Poyntz Wright 的说法,一些教堂始建于 1360 年之前,通常由一位熟练的石匠和一小群流动的石匠完成,并辅以当地教区工人。但其他作者拒绝这个观点,而认为主要是由知名的建筑师根据早期的垂直式建筑风格设计教区教堂塔楼。”
在第 9 代(也是最后一代)中,模型返回以下内容:
“architecture. In addition to being home to some of the world’s largest populations of black @-@ tailed jackrabbits, white @-@ tailed jackrabbits, blue @-@ tailed jackrabbits, red @-@ tailed jackrabbits, yellow @-.”
“建筑。除了拥有世界上数量最多的黑 @-@ 尾兔、白 @-@ 尾兔、蓝 @-@ 尾兔、红 @-@ 尾兔、黄 @-。”
Ilia Shumailov 用这个类比解释了他认为正在发生的事情:想象一下,你要找一个学校里最不可能出现的学生名字,你可以检查每个学生的名字,但这会花很长时间。相反,你会查看 1000 个学生姓名中的 100 个。你得到了一个相当准确的预估,但这可能不是正确的答案;现在想象一下,另一个人过来根据你的 100 个名字进行预估,但只选择了 50 个,那么这个人的预估将会更加偏离正确答案。
“机器学习模型也会出现同样的情况。因此,如果第一个模型已经浏览了一半的互联网内容,那么第二个模型可能不会要求一半的互联网内容,实际上只是抓取最新的 10 万条推文,并在上面训练模型。”他说。
此外,互联网上的数据是有限的,为了满足对更多数据的需求,未来的人工智能模型可能需要在合成数据或人工智能生成的数据上进行训练。
麻省理工学院媒体实验室的研究人员、研究如何训练 LLM 的 Shayne Longpre(他没有参与这项研究)说:“基础模型依赖于数据规模才能获得更好的表现。他们希望在经过精心策划和控制的环境中使用合成数据来解决这个问题,因为如果继续在网上抓取更多数据,收益将会递减。”
斯坦福大学人工智能研究员 Matthias Gerstgrasser 在另一篇论文中研究了模型崩溃的问题。在他看来,将合成数据添加到现实世界数据中而不是替换它并不会引起任何重大问题。但他补充道:“所有关于模型崩溃的研究都得出一个结论,那就是高质量且多样化的训练数据至关重要。”
随着时间的推移,这种“退化”导致模型中的信息失真,少数样本的信息在模型中严重扭曲,因为它往往更加关注训练数据中普遍的样本。
麻省理工学院媒体实验室研究算法的 Robert Mahari(他也没有参与这项研究)表示,在当前的模型中,这可能会影响代表性不足的语言,因为它们需要更多的合成(或人工智能生成)数据集。
一个有助于避免退化的想法是,确保模型给予原始的人类生成数据更多权重。Ilia Shumailov 研究的另一个项目允许后代对原始数据集的 10% 进行采样,而这减轻了一些负面影响。
这需要从人类生成的原始数据到后代数据进行追踪,即数据来源。但这需要一种方法来过滤互联网上的人类生成数据和人工智能生成数据,但这一点目前尚未完全解决。尽管现在存在许多工具能够确定文本是否由人工智能生成,但它们往往不够准确。
“不幸的是,我们的问题比答案多。”Ilia Shumailov 说, “但很明显,了解数据来自哪里以及在多大程度上可以相信它能够捕获正在处理数据的代表性样本,这一点很重要。”
原文链接:
https://www.technologyreview.com/2024/07/24/1095263/ai-that-feeds-on-a-diet-of-ai-garbage-ends-up-spitting-out-nonsense/