
包阅导读总结
1.
“`
OpenAI、GPT-4o、结构化输出、JSON 模式、准确率
“`
2.
OpenAI 的 GPT-4o 模型升级,带来结构化输出新功能,实现 JSON 输出 100%准确率,但存在一些缺陷和限制,同时模型更新后进行了降价处理,然而 OpenAI 近期人事变动频繁。
3.
– OpenAI 之前的 JSON 模式功能饱受诟病
– 模型不遵循指令,不按指定格式输出
– 处理结构化数据困难
– GPT-4o 模型的新变化
– 升级到 2024-08-06 版本
– 引入结构化输出,准确率达 100%
– 接入方式:函数调用设置 strict:true 或新增 response_format 参数选项
– 实现 100%准确率的方法
– 专项培训,准确率提到 93%
– 采用约束解码技术,限制输出 token
– 新功能的缺陷和限制
– 请求新 JSON Schema 时变慢
– 仅支持部分 JSON 模式,字段和参数有限制,对象有嵌套和大小限制
– 不能防止所有模型错误
– 新功能推出后的情况
– 遵守安全政策,设置检测拒绝生成的字符串值
– 模型更新后降价处理
– 引发网友对挤牙膏式更新的不满
– 近期人事变动频繁
思维导图: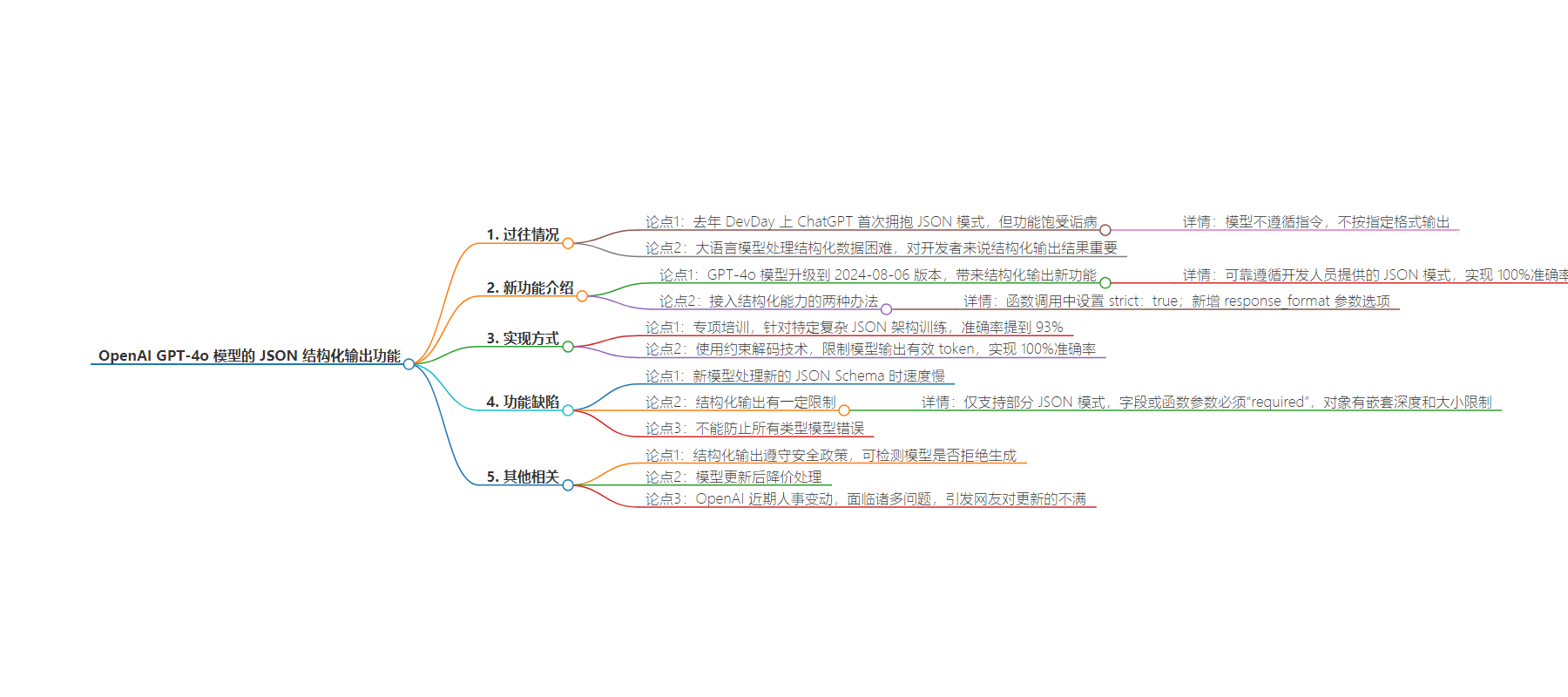
文章地址:https://mp.weixin.qq.com/s/E0z9wTy2G6NWd7fB8hikvw
文章来源:mp.weixin.qq.com
作者:海野
发布时间:2024/8/7 6:40
语言:中文
总字数:2255字
预计阅读时间:10分钟
评分:92分
标签:大模型,JSON输出,结构化数据,OpenAI,开发者体验
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

夕小瑶科技说 原创
作者 | 海野
OpenAI上次提到JSON模式的概念,还是在去年的DevDay上。那是ChatGPT第一次拥抱JSON模式。

但这个功能可以说是饱受诟病。
经常遇到模型不遵循指令,不按照你想要的格式输出,即使在 prompt 中明确说了要按照指定格式(比如Json、XML)返回结果,但是它就是不听话。
因为大语言模型在处理结构化数据时比想象中要困难得多。
很多人说,为什么非要纠结 JSON 格式的输出,我用的挺好的,啥 JSON 格式都没见过,这种要么就是用的不多,要么就不是做开发的!
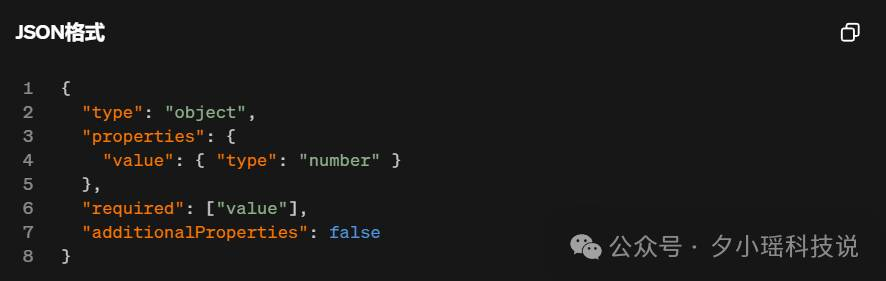
要知道!对于开发者来说,模型的结构化输出结果是很重要的!比如你想要一些抽取好的关键信息,这时候怎么给你?肯定是结构化的字段信息,简洁明了。比如:
非结构化的结果:
小明今年18岁,是一名高三学生。他身高175cm,体重65kg。小明喜欢打篮球,每周都会和朋友一起打球。他的梦想是成为一名软件工程师。
结构化结果 (JSON格式):
{
"name":"小明",
"age":18,
"education":{
"grade":"高三",
"status":"在读"
},
"physicalAttributes":{
"height":175,
"weight":65
},
"hobbies":["打篮球"],
"frequency":"每周",
"careerAspiration":"软件工程师"
}
今天,OpenAI就给它的GPT-4o模型翻了个新,升级到2024-08-06版本,并带来了一个全新升级后的功能:
在 API 中引入了结构化输出(Structured Outputs)
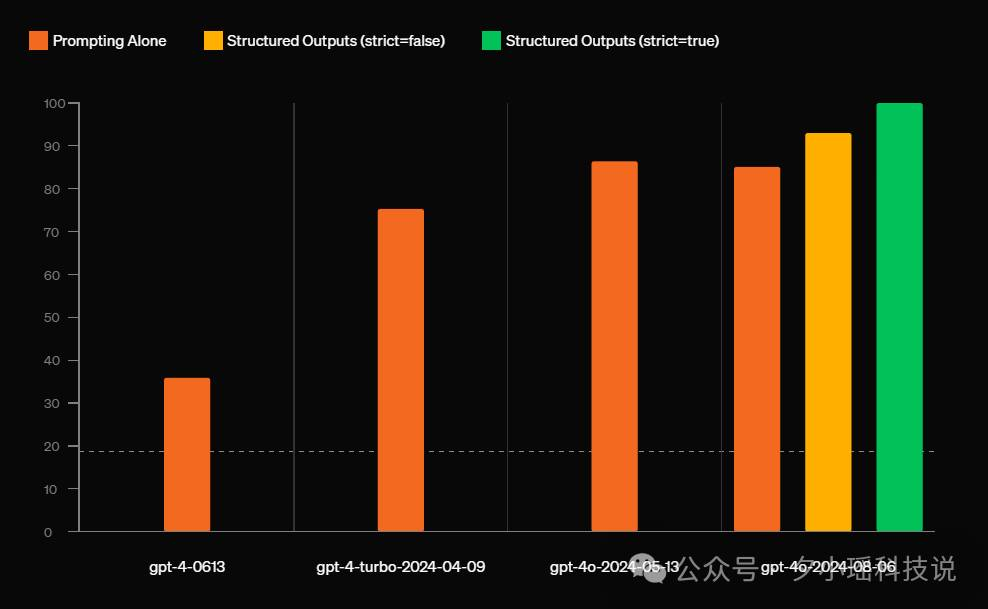
模型输出现在可靠地遵循开发人员提供的 JSON 模式。它可以实现输出JSON的100%准确率!
在此之前,开发者一直通过第三方开源工具,或者在 prompt 上面做功夫,让大模型遵循你的命令,再或者反复重试请求来绕过LLMs在结构化处理的缺陷,现在都不需要了。
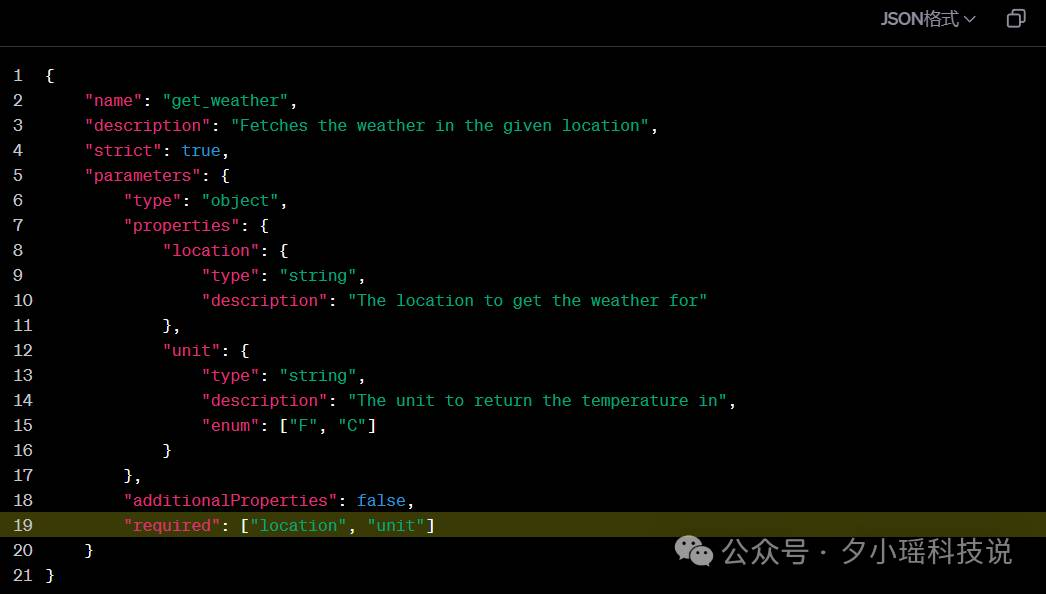
具体怎么接入结构化能力呢,有两种办法:
一种是函数调用,在函数定义中设置 strict:true进行结构化输出;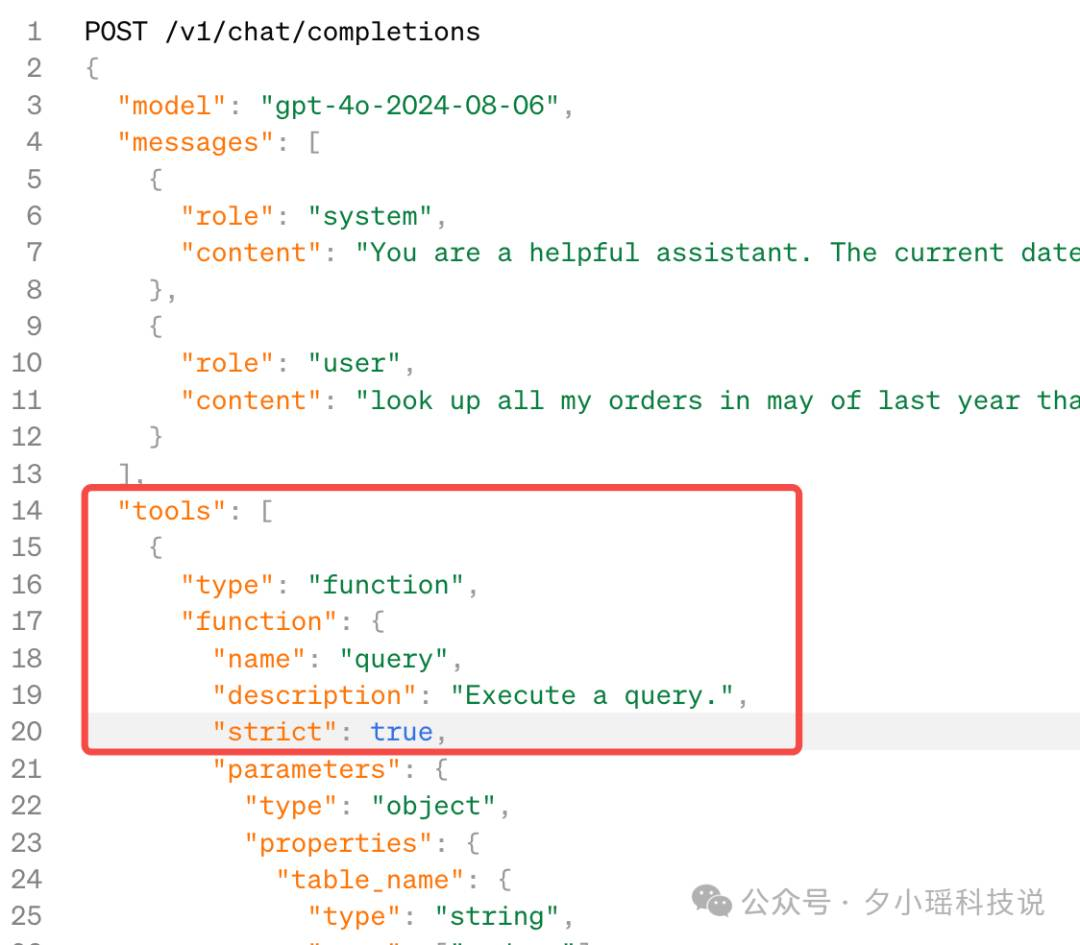
另一种是新增了一个response_format 的参数选项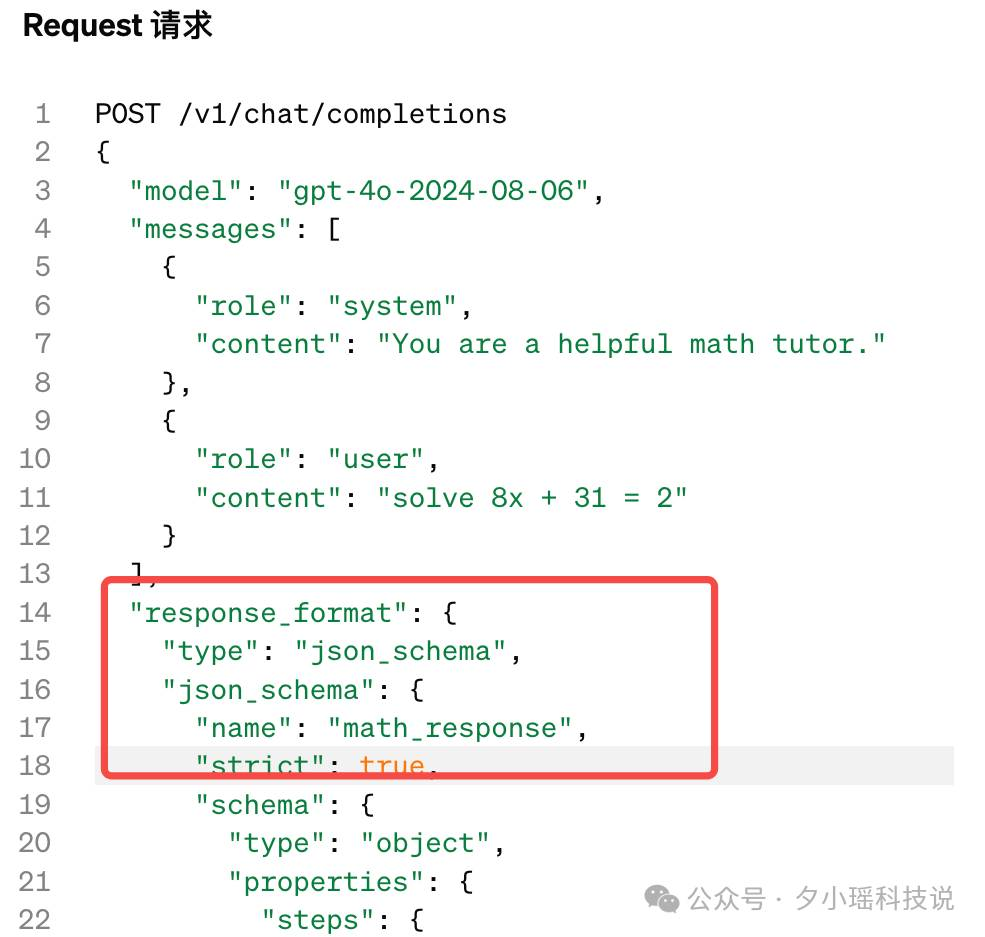
这是怎么做到的?
第一种方法比较传统,就是最经典的专项培训:对于特定的复杂的JSON架构进行针对性模型训练,Openai通过这种方法能把模型准确率提到93%。 相较于最开始带JSON模式的GPT-4的40%准确率,已经高出很多了。
尽管最新的模型gpt-4o-2024-08-06性能有所提高,但是模型本质上是非确定性的,无法保证JSON的稳定输出,所以采用了确定性的、基于工程的方法来约束模型的输出,以实现 100% 的可靠性。
但很明显,93%的准确率也就意味着7%的不可靠,对于开发人员来说,不是100%的准确就是不够用的,所以OpenAI又用了第二个方法。
而这第二种方法就有点神乎其神。OpenAI使用了约束解码(constrained decoding)技术。
默认情况下,大模型在进行token输出时,可以在词汇表中选择任意一个词汇,作为下一个输出token。而这种不可控性会让模型在输出一些固定格式的文本时犯格式错误。
而在使用动态的约束解码技术后,大模型在下一个token输出时,便增加了一些约束,将模型限制在有效的token内,而不是所有token。
比如:输入“{“val”后,下一个生成的文本一定不会是“{”。
通过这种方式,大模型不仅可以实现JSON的格式正确,还可以实现合适schema结构的精确。现在OpenAI已经通过这种方式实现了100%的JSON输出准确率。
这个功能一经亮相,网友们都坐不住了:


但这个功能目前还有一些缺陷。因为需要额外增加Schema预处理的时间,新模型在请求新的JSON Schema时慢了一些。此外,要使用结构化输出还有一些限制:
目前结构化仅支持输出一部分JSON模式,包括String、Number、Boolean、Object、Array、Enum和anyOf。
同时,所有的字段或者函数参数必须是“required”。
对象对嵌套深度和大小也有限制。一个架构总共最多可以有 100 个对象属性,最多有 5 个嵌套级别。
OpenAI还留了个底:结构化输出并不能防止所有类型的模型错误。 模型可能仍会在JSON对象的值中犯错误(比如在数学方程式中步骤出错),如果出现错误,需要使用者在指令提示词中提供示例,或者将任务拆分为更简单的子任务。
还有一个重中之重:安全 。结构化输出功能将遵守OpenAI现有的安全政策,并且仍会拒绝不安全的请求。甚至他们在API响应上设置了一个新的字符串值,让开发人员能以编程方式,检测模型是否拒绝生成。
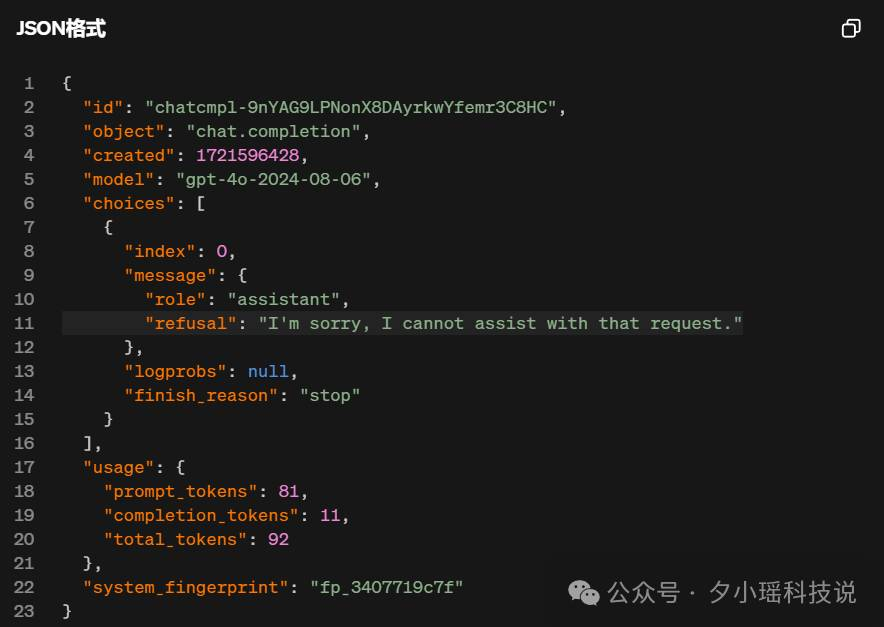
OpenAI还真是忘不了安全问题啊。
随着这个新功能的推出,OpenAI还宣布,模型在更新到GPT-4o-2024-08-06后,进行降价处理:
输入tokens降价一半,2.5美元(约合人民币17.96元)/百万个输入tokens;
输出tokens降价1/3,10美元(约合人民币71.84元)/百万个输出tokens。
但随着这个推文出现,评论区网友们也表达了对OpenAI挤牙膏式更新的不满:
一点点技术创新也能叫版本更新吗?

实际上,这项功能发布的前一天,OpenAI才刚引起不小的轰动:联创John Schulman提桶跳槽Anthropic;总裁Greg Brockman享受他的超长假期;产品副总裁Peter Deng悄然离职;马斯克也恢复了对OpenAI的起诉,而Sam Altman在OpenAI中的地位甚至尚未稳固。

也许OpenAI,真的需要制造一个大热门来解决这场宫斗闹剧了。



参考资料
[1]https://openai.com/index/introducing-structured-outputs-in-the-api/