
包阅导读总结
1.
关键词:GPT-4o mini、中国大模型、DeepSeek、面壁智能、开源生态
2.
总结:OpenAI 推出的 GPT-4o mini 引发关注,中国的 DeepSeek 率先打响大模型价格战,面壁智能提出面壁定律并在轻量化高效大模型上领先。GPT-4o mini 虽有优势但冲击国内市场,破局需科研创新、押注端侧 AI 和坚信开源生态。
3.
主要内容:
– 介绍 GPT-4o mini 推出,价格更便宜、效率更高
– DeepSeek 把大模型价格战的火烧到 OpenAI
– DeepSeek-V2 模型架构创新,打响国内大模型价格战第一枪
– 面壁智能把轻量化高效大模型的火烧到 OpenAI
– 提出面壁定律,模型知识密度不断提升
– 发布轻量化高效模型,早于 OpenAI 约半年
– GPT-4o mini 对国内大模型 API 市场造成冲击
– 破局方法
– 持续科研创新和提前赛道部署,如寄希望于 DeepSeek 创新和看好面壁智能的端侧 AI
– 坚信开源生态的力量,以 DeepSeek 和面壁智能为例
– 对中国大模型未来充满期待
思维导图: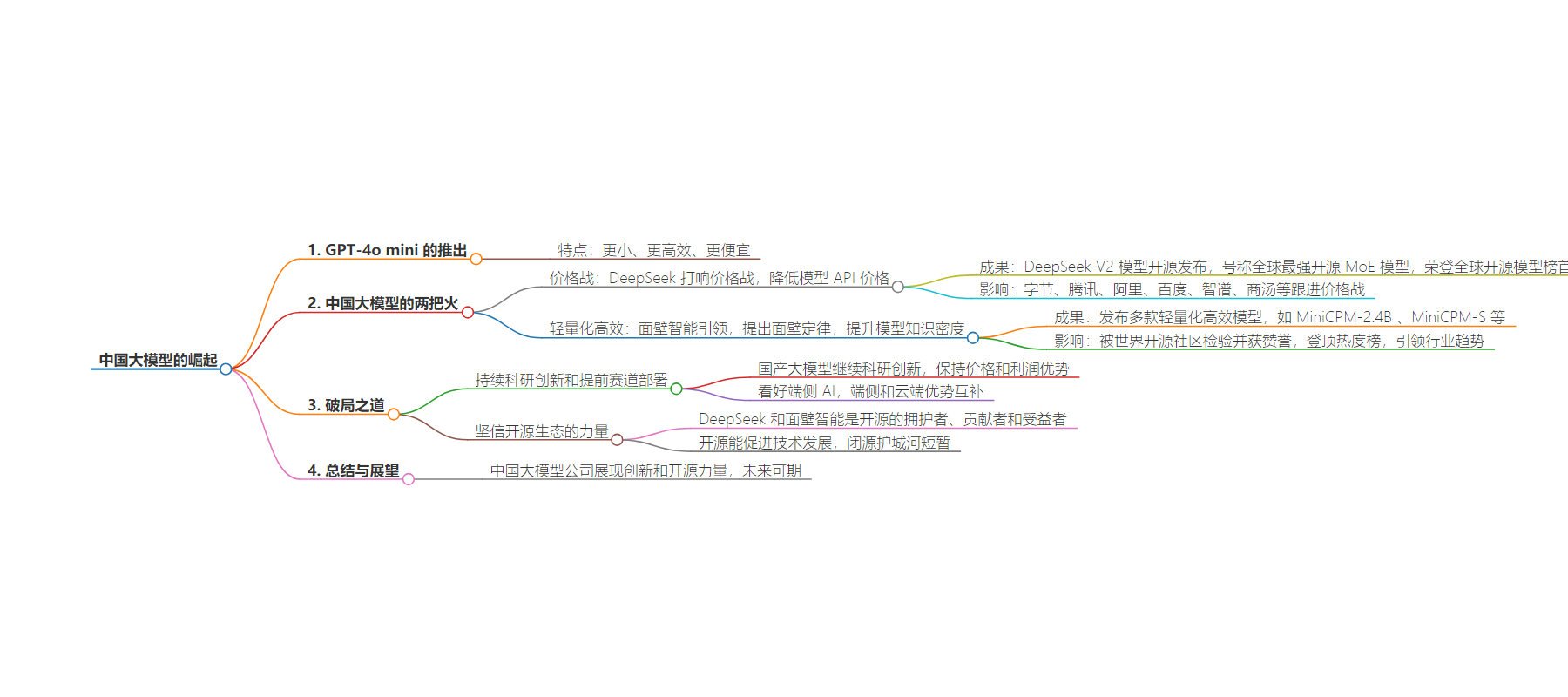
文章地址:https://mp.weixin.qq.com/s/nYmkTgfbN27nkKKvKUzo_A
文章来源:mp.weixin.qq.com
作者:夕小瑶科技说
发布时间:2024/7/19 10:53
语言:中文
总字数:2757字
预计阅读时间:12分钟
评分:88分
标签:大模型,OpenAI,DeepSeek,面壁智能,价格战
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

夕小瑶科技说 分享
OpenAI 今天最新推出的 GPT-4o mini 又火了,一句话总结就是更小、更高效、更便宜。
圈内很多朋友转发并对 OpenAI 再次膜拜—— OpenAI 果然是大模型一哥、 OpenAI YYDS!
但笔者却想说, OpenAI 这次好像不再一如既往的“遥遥领先”,我从 GPT-4o mini 的背后看到了中国大模型新势力的崛起——中国大模型的两把火,烧到了 OpenAI 。
一把是 DeepSeek,它把大模型价格战的火烧到了OpenAI 。
另一把是面壁智能,它把轻量化高效大模型的火烧到了OpenAI。
OpenAI 全球第一梯队的研发实力当然不容置疑,但中国大模型其实在上面两个方向抢先了 OpenAI一步,甚至是半年之久。
OpenAI 这次良心大发,把 GPT-4o mini 的 API 价格降到了 15 美分/每百万输入token 和 60 美分/ 每百万输出token。折算一下,其实就相当于差不多 1元=100万输入token。
这个价格量级其实正是两个月前由DeepSeek首先打下来的,它们开源发布的DeepSeek-V2 模型凭借模型架构创新(MLA+ DeepSeekMoESparse )把计算量降到极致,把API的定价降到了每百万输入token = 1元,由此打响了国内大模型价格战第一枪。
紧随 DeepSeek 之后,字节、腾讯、阿里、百度、智谱、商汤也都打起了价格战,但相比一些大厂拿过去互联网的模型烧钱补贴不同,DeepSeek 其实是有利润的。
这次价格战背后的 DeepSeek-V2 模型,当时号称是全球最强开源 MoE 模型,拥有媲美 GPT-4 的能力。就在昨天,DeepSeek 最新发文:“在最新一期 LMSYS 组织的全球大模型竞技场(Chatbot Arena)中,DeepSeek-V2-0628 超越 Llama3-70B、Qwen2-72B、Nemotron-4-340B、Gemma2-27B 等开源模型,荣登全球开源模型榜首!”
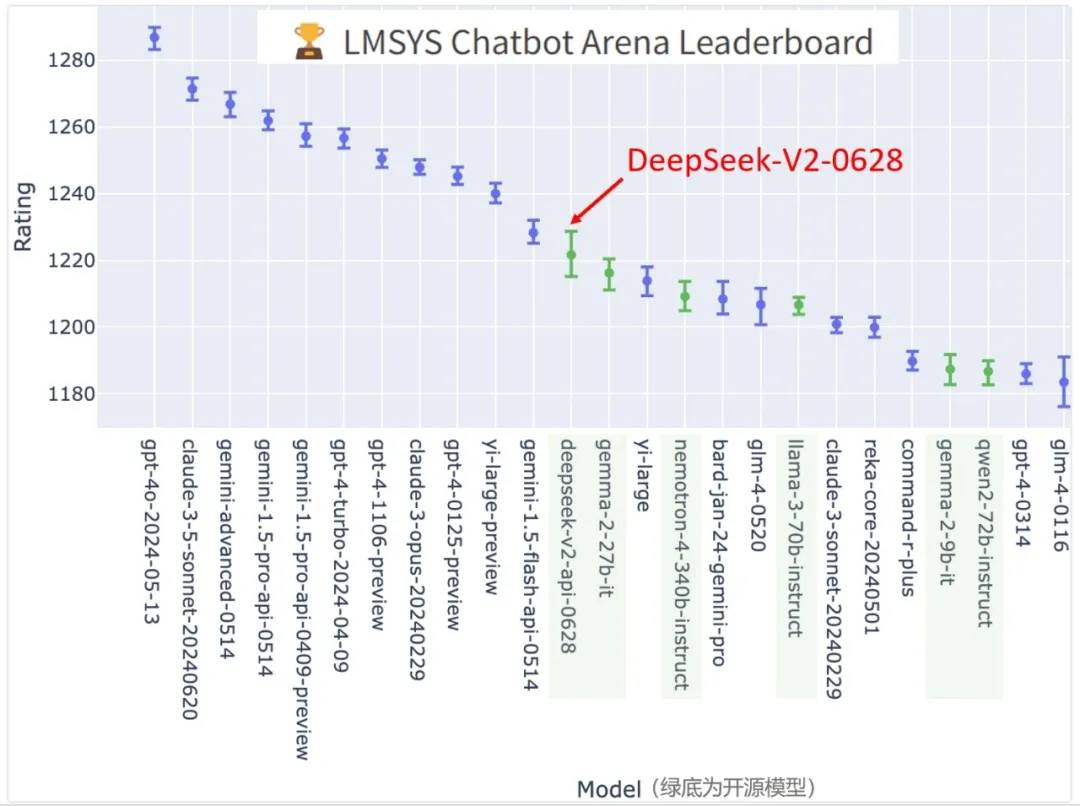
想必OpenAI最近几个月,也大概率在 GPT-4o mini 上摸索出了类似 DeepSeek-V2的MLA+ DeepSeekMoESparse的架构创新,所以才能把价格降下来。
可能很多人会好奇,DeepSeek 名不见经传,作为国内大模型公司的神秘玩家,为何这么强?
前两天,DeepSeek 背后老板梁文锋刚刚接受了 36氪的采访,讲述了一个更极致的中国技术理想主义故事,文章写的非常棒,推荐大家看一下。
我最有感触的一段对话是:
|
Q:互联网和移动互联网时代留给大部分人的惯性认知是,美国擅长搞技术创新,中国更擅长做应用。 梁文锋:我们认为随着经济发展,中国也要逐步成为贡献者,而不是一直搭便车。过去三十多年IT浪潮里,我们基本没有参与到真正的技术创新里。我们已经习惯摩尔定律从天而降,躺在家里18个月就会出来更好的硬件和软件。Scaling Law 也在被如此对待。但其实,这是西方主导的技术社区一代代孜孜不倦创造出来的,只因为之前我们没有参与这个过程,以至于忽视了它的存在。 |
是啊,摩尔定律是美国提出并主导的,它在过去几十年中给半导体和互联网行业的发展带来了科学指导意义;
那么大模型时代,中国能否具有相应的行业高度与前瞻眼光,率先提出一个类似的摩尔定律呢?
说曹操曹操到——时代召唤面壁智能。
面壁智能——中国轻量化高效大模型先行者
笔者前些天去上海参加 WAIC 2024 的时候,听到面壁智能首席科学家刘知远在演讲中提出了大模型时代的面壁定律——模型的知识密度不断提升,平均每8个月提升一倍。其中,知识密度=模型能力 / 参与计算的模型参数 。
而 OpenAI 推出的更小、更便宜、更高效的 GPT-4o mini 其实恰恰印证了面壁定律的效力。
为何这样说?
因为OpenAI 这次一反往常大力出奇迹的暴力美学路线,没有把模型持续做大,而是反而做了一个mini的轻量化模型,这背后的本质,其实就是把模型的知识密度给提升上来,这和面壁定律不谋而合,未来大模型的发展趋势必然是提升大模型的知识密度。知识密度好比大模型的制程,制程越大,模型的上限才越大。
如下图所示,相比 OpenAI 于2020年发布的1750亿参数的 GPT-3,2024 年初,面壁发布具备 GPT-3 同等性能但参数仅为24亿的 MiniCPM-2.4B ,把知识密度提高了大概 86 倍 !
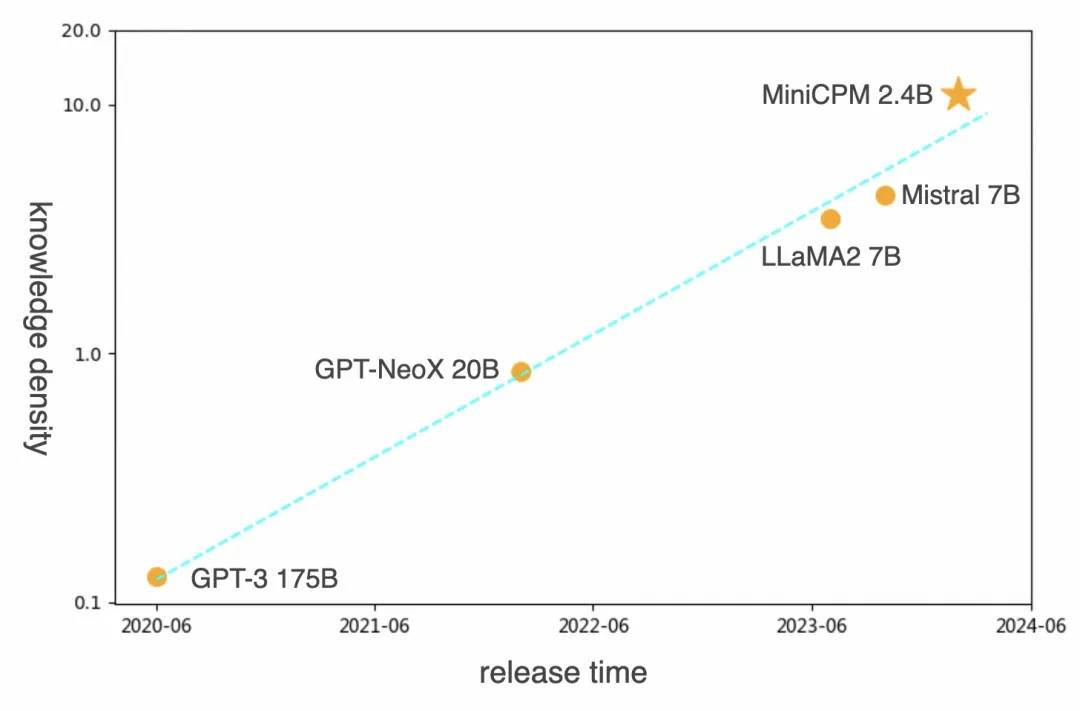
知识密度 86 倍提高并不是面壁智能的极限。
面壁新一代高效稀疏架构大模型MiniCPM-S将知识密度空前提升:达到同规模稠密模型 MiniCPM 1.2B 的 2.57 倍,Mistral-7B 的 12.1 倍;这是对面壁定律的又一次验证且在时间上进行了加速!面壁“高效 Scaling Law” 仍在持续演绎。
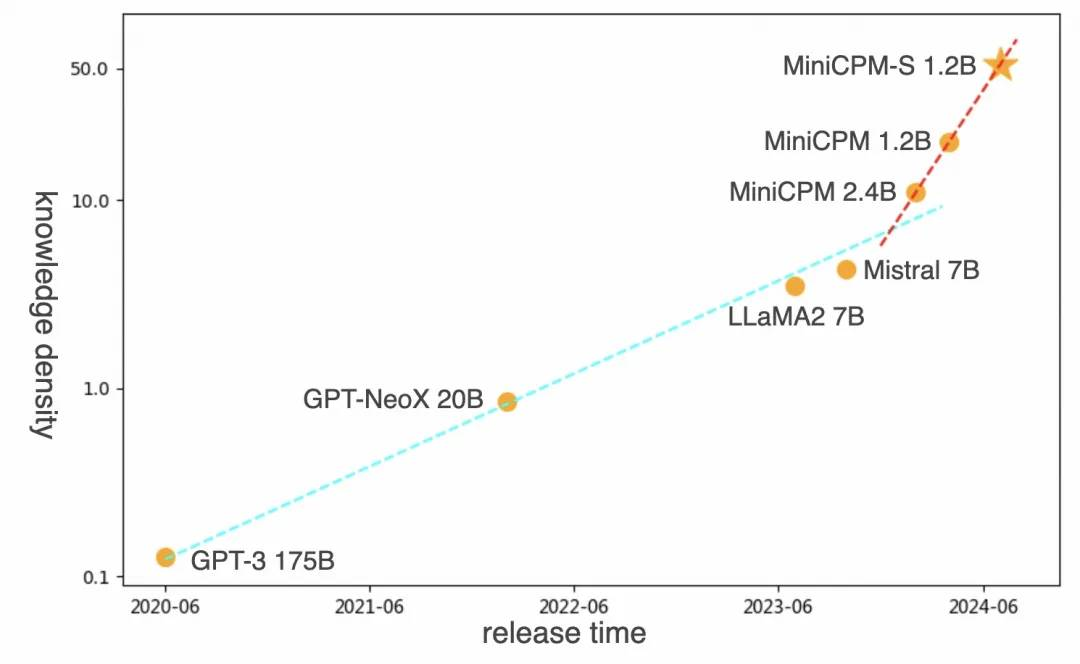
模型地址:
https://huggingface.co/openbmb/MiniCPM-S-1B-llama-format
可以说,在推出知识密度更高的轻量化高效大模型这件事上,面壁智能早了OpenAI差不多半年时间!
面壁早在今年 2 月 1 日就开源发布了面壁小钢炮第一版,4 月开源发布了第二版,5 月开源发布了2.5 版本。在 2.5 版本上,以 1% 的参数规模,形成了可以跟GPT-4V 和 Gemini Pro 多模态能力对标的性能,模型参数只有 8B 大小,能够跑在手机上。面壁小钢炮以其「以小博大」的性能、高效低成本的特色与卓越端侧表现,受到世界开源社区的检验并获得广泛赞誉,接连登顶 GitHub,Hugging Face热度榜。
有多热呢?热到令人忍不住抄袭!创造了美国抄袭中国大模型的历史~
在此前,面壁创始团队数次率行业之先,在中国大模型版图一片空白的时候呼吁要训练大模型、直接驱动了中国首个「悟道」大模型项目的立项;又引领性地开创了一系列世界前沿水平的Agent智能体研究项目;对于大模型从规模大到效率高的趋势,也在业内最早制定了清晰战略,并且推出了行业发展的指导规律——面壁定律。
有江湖传闻,国内大模型厂商在制定大模型战略时,会重点盯着面壁智能,堪称是大模型趋势风向标!
「高效」一直是面壁大模型发展的第一性原理,已经完成了高效训练、高效落地与高效推理的大模型全栈技术生产线布局。这背后是面壁通过对大模型训练过程进行精准建模、预测,打造出更加高效的Scaling Law增长曲线,实现同等参数性能更优、同等性能参数更小效果。
回到GPT-4o mini ,作为一个性价比很高的云端模型,它必然会对国内大模型API市场造成冲击,让国产大模型更难赚钱。
那么问题来了:我们该如何破局呢?
一方面要持续科研创新和提前赛道部署。
我们可以寄希望于类似 DeepSeek 的国产大模型继续科研创新,既能保持新的价格优势,又能保证利润。
同时笔者很看好面壁智能押注的端侧AI。端侧AI是未来的大趋势,除了端侧响应更快、数据隐私安全等优势外,端侧更接近各种传感器设备,如手机上的摄像头和麦克风,天然具备多模态输入能力。感知性输入应在端侧通过短链路处理,以提高效率,而非传输到云端再反馈。云端大模型则负责更高级的逻辑和决策处理,适用于更长链路的判断。端侧模型在用户交互和即时反馈上占优势,云端模型则擅长复杂决策和高级逻辑处理。另外据面壁定律所预言,未来两年把GPT-4水平的模型运行在手机上也不是难事。
另一方面要坚信开源生态的力量。
DeepSeek和面壁智能一直都是开源的忠实拥护者、贡献者和受益者。
DeepSeek老板梁文锋表示:在颠覆性的技术面前,闭源形成的护城河是短暂的。即使OpenAI闭源,也无法阻止被别人赶超。
总之,从DeepSeek和面壁智能身上,我看到了中国大模型公司的创新和开源力量。
中国大模型未来可期!