包阅导读总结
1. 关键词:Qwen2-Audio、语音模型、音频分析、语音聊天、开源
2. 总结:阿里新开源语音模型 Qwen2-Audio,它是大规模音频-语言模型,能接受音频输入,具备音频分析和语音聊天模式且能智能切换,模型总参数量 82 亿,训练分三阶段,目前无语音输出,AI 语音交互技术有望年底成熟。
3.
– Qwen2-Audio 模型
– 发布与开源
– 由阿里云发布并开源
– GitHub 和论文链接
– 功能特点
– 接受各种音频信号输入
– 执行音频分析和文字响应
– 自主判断并切换语音聊天和音频分析模式
– 具备分析音频情绪能力
– 两种模式
– 音频分析:分析各种音频,响应命令
– 语音聊天:像会话代理一样交互
– 模型炼成
– 音频编码器基于 Whisperlarge-v3 模型初始化
– 使用 Qwen-7B 为基础组件,总参数量 82 亿
– 训练分多任务预训练、监督微调、直接偏好优化三阶段
– 现状与展望
– 优秀但无语音输出
– AI 语音交互技术年底或基本成熟,期待国产惊艳模型
思维导图: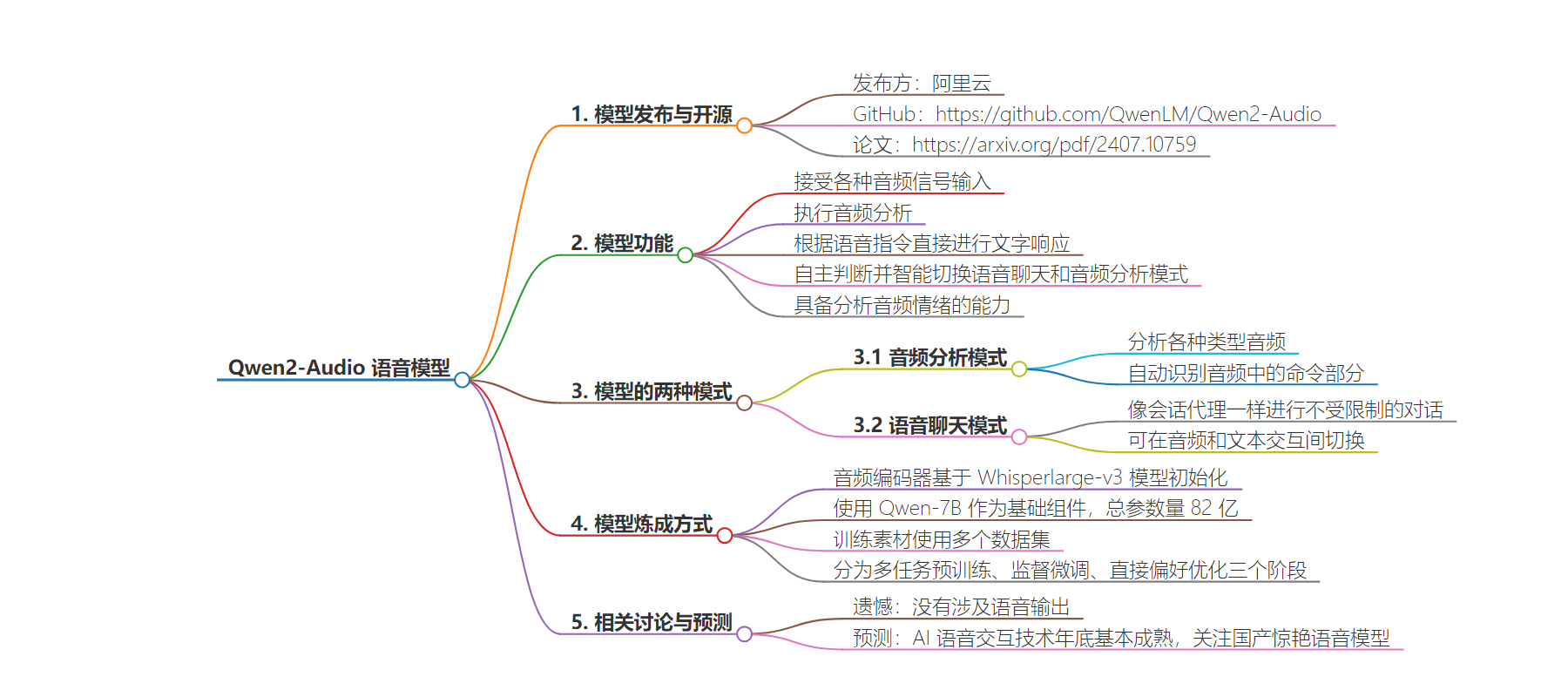
文章地址:https://mp.weixin.qq.com/s/w_IK_Uzxe289SLUIKOH7hg
文章来源:mp.weixin.qq.com
作者:51CTO技术栈
发布时间:2024/7/19 5:40
语言:中文
总字数:1511字
预计阅读时间:7分钟
评分:91分
标签:语音模型,音频分析,语音交互,阿里云,开源
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

SOTA水准的Qwen2家族又迎来了新成员!
阿里云发布并开源语音模型Qwen2-Audio。
GitHub:
https://github.com/QwenLM/Qwen2-Audio
论文:
https://arxiv.org/pdf/2407.10759
作为大规模的音频-语言模型,Qwen2-Audio能够接受各种音频信号输入,并执行音频分析或根据语音指令直接进行文字响应。
很妙的是,在Qwen2-Audio支持的语音聊天(但没有音频输出)和音频分析这两种交互模式之间,模型可以自主判断,并在这两种模式之间智能地切换,无需系统提示。
同样让人惊喜的是,Qwen2-Audio模型具备分析音频情绪的能力。当用户对模型说,自己马上就要考试,总是睡不着觉的时候。Qwen2-Audio会识别用户的焦虑情绪,并给予可行的建议。
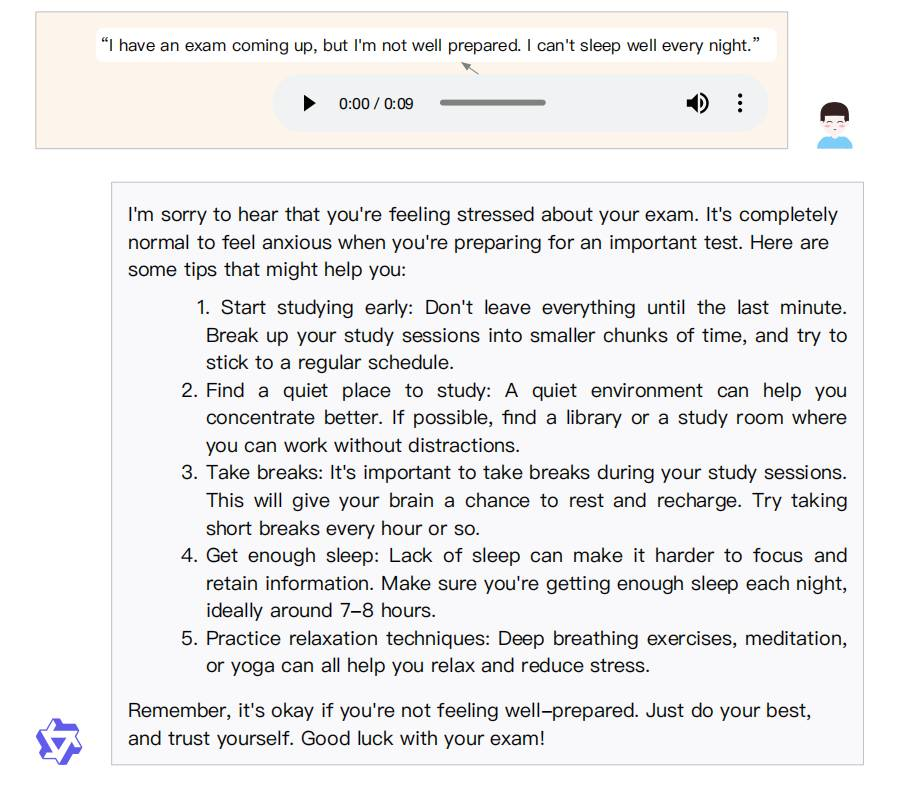
 Qwen2-Audio的两种模式:音频分析和语音聊天
Qwen2-Audio的两种模式:音频分析和语音聊天Qwen2-Audio支持两种截然不同的模式:音频分析和语音聊天。
这两种模式通过其功能区分,但模型会自动判断,用户无需感知和进行提示。
在音频分析模式中,用户可以利用Qwen2-Audio分析各种类型的音频,包括语音、声音、音乐或各种混合音频形式。命令可以通过音频或文本发出,Qwen2-Audio将自动识别音频中的命令部分。
如下图所示,Qwen2-Audio相应用户语音发出的翻译命令,通过文字相应完成了该任务。
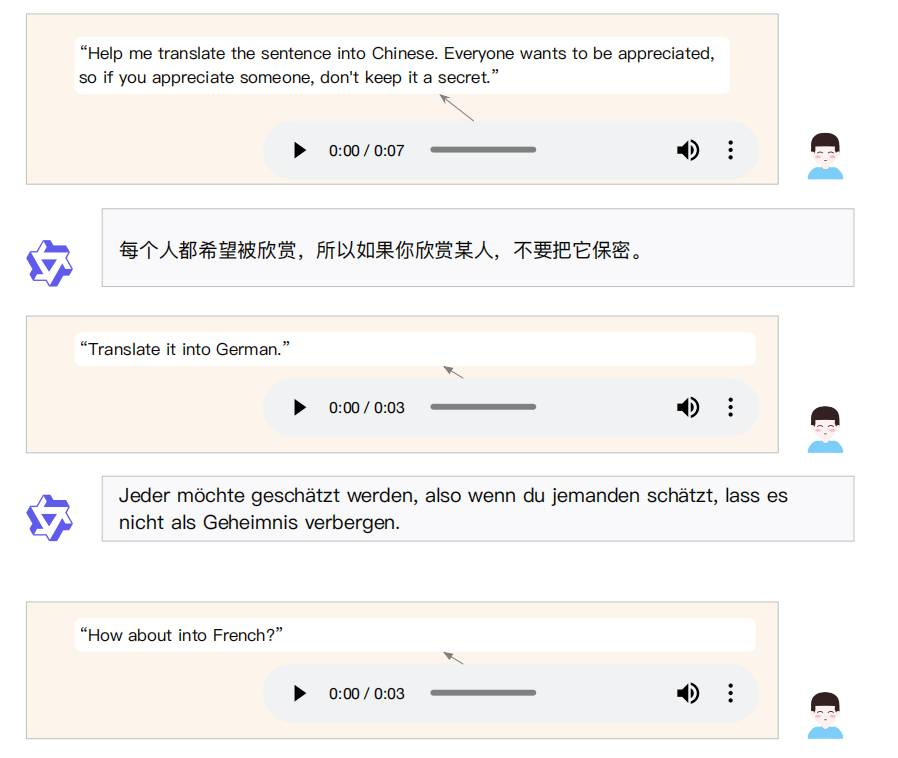
而在语音聊天模式中,用户可以与Qwen2-Audio进行交互,就像它是一个会话代理一样,进行不受限制的对话。
音频交互是可用的,用户可以随时选择切换到文本交互。例如,如果用户输入一个音频片段,其中初始部分是敲击键盘的声音,随后用户用口语问“这是什么声音?”,Qwen2-Audio预计将直接回应“这是键盘的声音。”
即使在较为嘈杂的环境,例如用户一边听歌,一边发出指令,让模型提取出歌词内容。Qwen2-Audio也能有较好的表现。
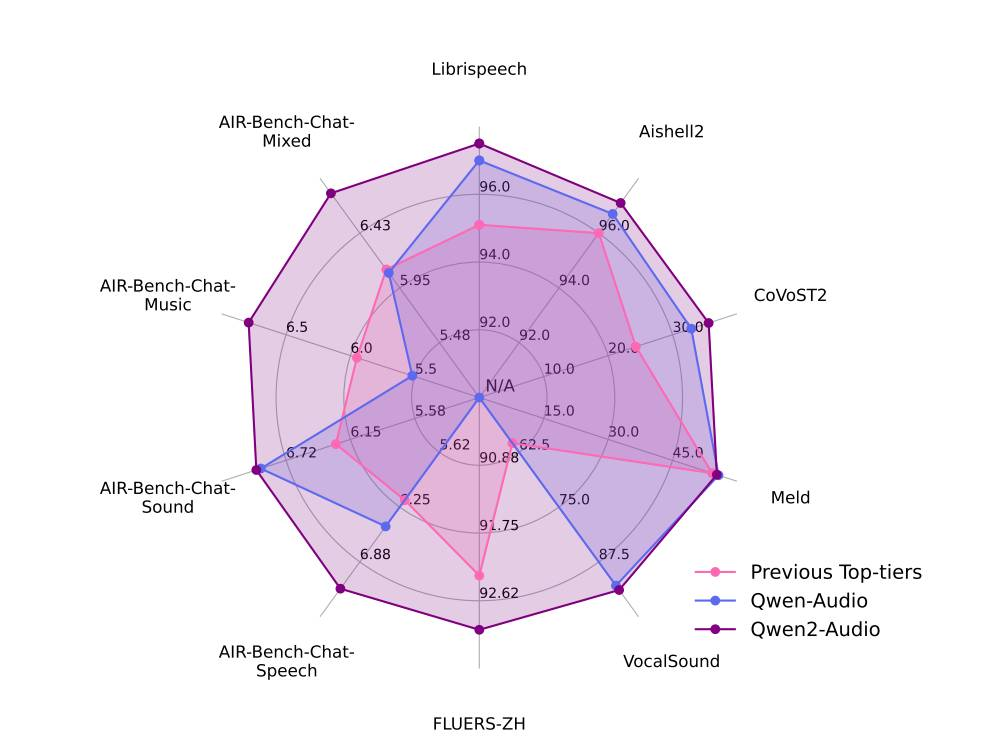
从论文中看,Qwen2-Audio在没有特定任务微调的情况下,超越了之前的大型音频-语言模型(LALMs),涵盖了多种任务。
 Qwen2-Audio是如何炼成的?
Qwen2-Audio是如何炼成的?
与Qwen-Audio不同的是,Qwen2-Audio的音频编码器基于Whisperlarge-v3模型初始化,负责将音频信号转换为模型可以理解的表示。
Qwen2-Audio使用了Qwen-7B作为其基础组件,模型总参数量为82亿。
在训练素材上,Qwen2-Audio使用了多个数据集。
在对音频数据进行预处理的阶段,音频被重新采样到16 kHz的频率,使用25ms的窗口大小和10ms的跳跃大小将原始波形转换为128通道的mel-频谱图。
此外,还加入了一个步幅为2的池化层,以减少音频表示的长度。最终,编码器输出的每一帧近似对应于原始音频信号的40 ms段。
整个Qwen2-Audio分为三个阶段:
-
第一阶段:多任务预训练,使用自然语言提示和大规模数据集进行预训练。
-
第二阶段:监督微调,通过高质量的SFT数据集进行微调,提高模型对人类指令的理解和响应能力。
-
第三阶段:直接偏好优化,通过DPO进一步优化模型,使其输出更符合人类的偏好。
 写在最后
写在最后
Qwen2-Audio虽然很优秀,但遗憾在没有涉及语音输出。而无论是语音助手、情感陪伴还是更远的具身智能,都迫切需要点亮这棵技能树。

Sora的横空出世,已经肉眼可见地催熟了文生视频的模型技术。
下一个值得关注的模态,似乎正瞄准了GPT-4o,瞄准了语音交互。
根据专家预测,AI语音交互技术将在今年年底发展到基本成熟。
快手凭借可灵获得了一片叫好,那么,语音界令我们惊艳的国产模型,又将花落谁家?
——好文推荐——
AI PC真值得入手?84%电脑发烧友拒绝买单:AI助手成了PDF加载的绊脚石!网友:真不仅仅是性能原因
GPT-4o们其实都是眼盲!OpenAI奥特曼自曝自家模型:推理比人弱。研究证明:多模态能力还差得远,杨立昆上大分