
包阅导读总结
1. 大模型幻觉、TaD、RAG、LLM、京东技术
2. 本文介绍了京东技术团队联合清华大学提出的缓解大模型幻觉的新技术TaD,以及业内的RAG技术,阐述了大模型幻觉产生的原因和相关研究,还列举了TaD技术的优势和落地案例,最后对未来进行了思考与展望。
3.
– 背景介绍
– 生成式大语言模型掀起AI热潮,但不准确性制约其大规模落地,产生的不准确信息被称为“幻觉”。
– 京东在核心业务中探索LLM落地应用,提升业务效率和用户体验。
– 相关调研
– 大语言模型本质是语言模型,通过计算句子概率建模自然语言概率分布。
– 幻觉产生的来源包括数据、训练和推理,并给出了对应的缓解策略。
– 介绍了RAG技术及存在的问题,如最终输出仍可能产生幻觉。
– 技术突破
– 京东零售联合清华大学提出TaD技术,可缓解LLM本身的幻觉,通用性强。
– 介绍了TaD的基本原理、知识向量概念和实验效果。
– 落地案例
– 在京东通用知识问答系统中,通过TaD实现低幻觉的LLM,系统层面基于RAG注入自有事实性知识。
– 思考与展望
– 缓解LLM幻觉是未来探索路径,未来系统可能是RAG+Agent+More的复杂系统。
– 探索外部知识和LLM推理的深度融合,TaD类探索将成研究热点。
思维导图: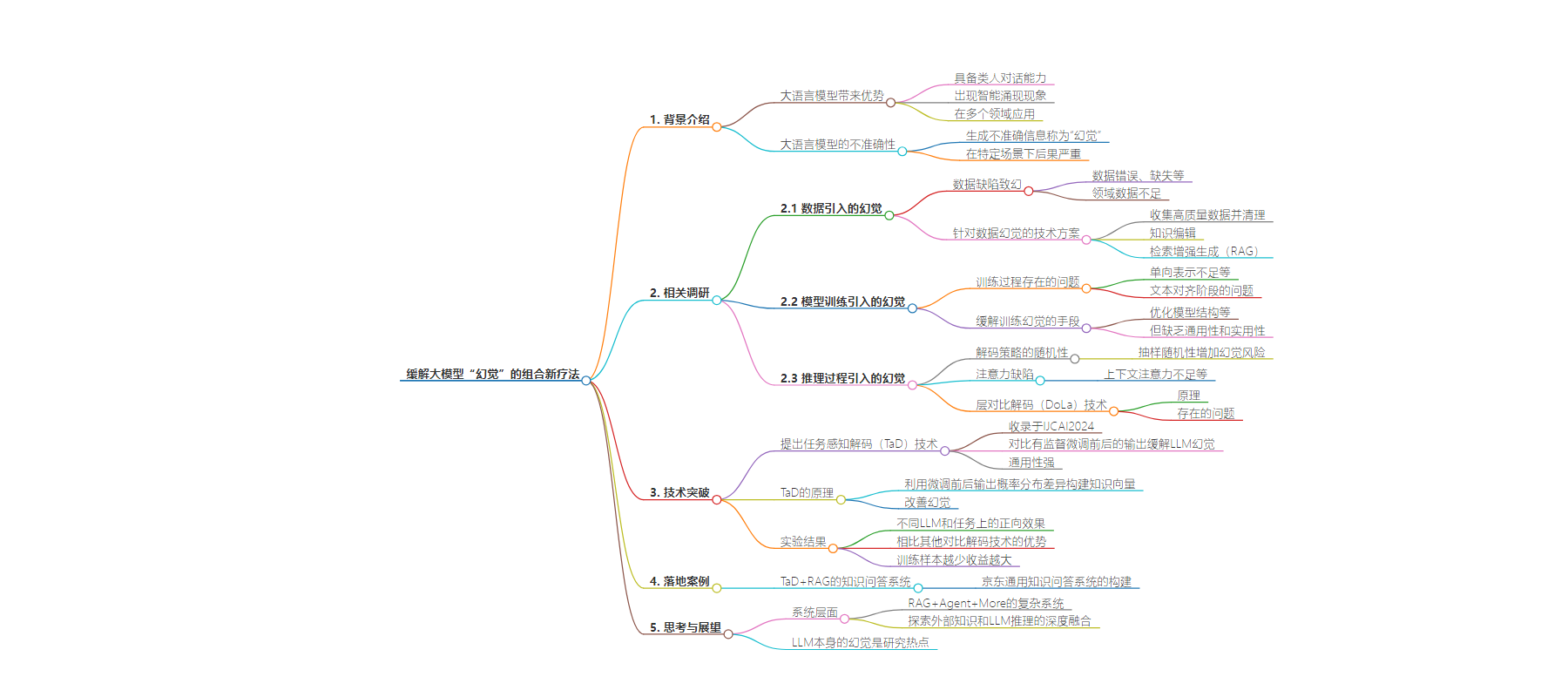
文章地址:https://mp.weixin.qq.com/s/jnD87hrEnrARsCRaL4cmcQ
文章来源:mp.weixin.qq.com
作者:京东零售产研中心
发布时间:2024/7/22 6:51
语言:中文
总字数:7341字
预计阅读时间:30分钟
评分:80分
标签:大语言模型,LLM幻觉,TaD,RAG,知识问答
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

本文入选顶会IJCAI2024,京东技术团队联合清华大学提出缓解大模型“幻觉”新技术!
ChatGPT的横空出世标志着人工智能正式进入大模型时代,大模型也正逐步成为推动企业发展的新引擎。然而,大模型带来无与伦比创造力的同时,其“幻觉”,即“胡说八道”的坏毛病也让大批应用者苦不堪言。业内主要通过检索增强生成(RAG)技术,通过引入并检索第三方知识库缓解幻觉。但即便召回正确的信息,大模型依然可能因为自身幻觉生成错误结果,所以缓解大模型本身的幻觉也极其重要。
京东技术团队联合清华大学提出任务感知解码技术(Task-aware Decoding,TaD),通过对比有监督微调前后的输出,缓解LLM本身的幻觉;该方法通用性强,即插即用适应多种大模型结构、微调方法、下游任务。与此同时,项目团队在知识问答业务上进行落地实践,充分证明TaD+RAG是缓解LLM幻觉的最佳组合疗法。欢迎关注转发~
TaD:任务感知解码技术(Task-aware Decoding,简称TaD),京东联合清华大学针对大语言模型幻觉问题提出的一项技术,成果收录于IJCAI2024。
RAG:检索增强生成技术(Retrieval-augmented Generation,简称RAG),是业内解决LLM幻觉问题最有效的系统性方案。
本文入选顶会IJCAI2024,京东技术团队联合清华大学提出缓解大模型“幻觉”新技术!
ChatGPT的横空出世标志着人工智能正式进入大模型时代,大模型也正逐步成为推动企业发展的新引擎。然而,大模型带来无与伦比创造力的同时,其“幻觉”,即“胡说八道”的坏毛病也让大批应用者苦不堪言。业内主要通过检索增强生成(RAG)技术,通过引入并检索第三方知识库缓解幻觉。但即便召回正确的信息,大模型依然可能因为自身幻觉生成错误结果,所以缓解大模型本身的幻觉也极其重要。
TaD:任务感知解码技术(Task-aware Decoding,简称TaD),京东联合清华大学针对大语言模型幻觉问题提出的一项技术,成果收录于IJCAI2024。
RAG:检索增强生成技术(Retrieval-augmented Generation,简称RAG),是业内解决LLM幻觉问题最有效的系统性方案。
背景介绍
近来,以ChatGPT为代表的生成式大语言模型(Large Language Model,简称LLM)掀起了新一轮AI热潮,并迅速席卷了整个社会的方方面面。得益于前所未有的模型规模、训练数据,以及引入人类反馈的训练新范式,LLM在一定程度上具备对人类意图的理解和甄别能力,可实现生动逼真的类人对话互动,其回答的准确率、逻辑性、流畅度都已经无限接近人类水平。此外,LLM还出现了神奇的“智能涌现”现象,其产生的强大的逻辑推理、智能规划等能力,已逐步应用到智能助理、辅助创作、科研启发等领域。京东在诸多核心业务如AI搜索、智能客服、智能导购、创意声称、推荐/广告、风控等场景下,均对LLM的落地应用进行了深入探索。这一举措提升了业务效率,增强了用户体验。
尽管具备惊艳的类人对话能力,大语言模型的另外一面——不准确性,却逐渐成为其大规模落地的制约和瓶颈。通俗地讲,LLM生成不准确、误导性或无意义的信息被称为“幻觉”,也就是常说的“胡说八道”。当然也有学者,比如OpenAI的CEO Sam Altman,将LLM产生的“幻觉”视为“非凡的创造力”。但是在大多数场景下,模型提供正确回答的能力至关重要,因此幻觉常常被认为是一种缺陷;尤其是在一些对输出内容准确性要求较高的场景下,比如医疗诊断、法律咨询、工业制造、售后客服等,幻觉问题导致的后果往往是灾难性的。
相关调研
众所周知,大语言模型的本质依然是语言模型(Language Model,简称LM),该模型可通过计算句子概率建模自然语言概率分布。具体而言,LM基于统计对大量语料进行分析,按顺序预测下一个特定字/词的概率。LLM的主要功能是根据输入文本生成连贯且上下文恰当的回复,即生成与人类语言和写作的模式结构极为一致的文本。注意到,LLM并不擅长真正理解或传递事实信息。故而其幻觉不可彻底消除。亚利桑那州立大学教授Subbarao Kambhampati认为:LLM所生成的全都是幻觉,只是有时幻觉碰巧和你的现实一致而已。新加坡国立大学计算学院的Ziwei Xu和Sanjay Jain等也认为LLM的幻觉无法完全消除[1]。
2.1 数据引入的幻觉
RAG引入信息检索过程,通过第三方数据库中检索相关信息来增强LLM的生成过程,从而提高准确性和鲁棒性,降低幻觉。由于接入外部实时动态数据,RAG在理论上没有知识边界的限制,且无需频繁进行LLM的训练,故已经成为LLM行业落地最佳实践方案。下图1为RAG的一个标准实现方案[11],用户的Query首先会经由信息检索模块处理并召回相关文档;随后RAG方法将Prompt、用户query和召回文档一起输入LLM,最终由LLM生成最终的答案。
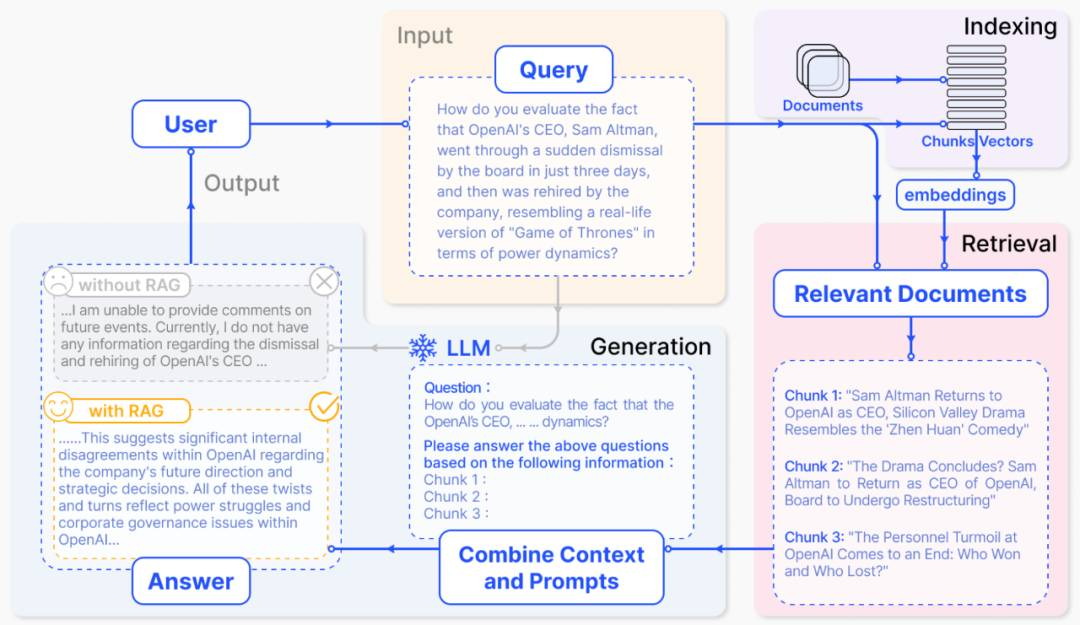 图1. RAG架构图
图1. RAG架构图
2.2 模型训练引入的幻觉
2.3 推理过程引入的幻觉
针对推理过程解码策略存在的缺陷,一项具有代表性且较为有效的解决方案是层对比解码(Decoding by Contrasting Layers, 简称DoLa)[9]。模型可解释性研究发现,在基于Transformer的语言模型中,下层transformer编码“低级”信息(词性、语法),而上层中包含更加“高级”的信息(事实知识)[10]。DoLa主要通过强调较上层中的知识相对于下层中的知识的“进步”,减少语言模型的幻觉。具体地,DoLa通过计算上层与下层之间的logits差,获得输出下一个词的概率。这种对比解码方法可放大LLM中的事实知识,从而减少幻觉。
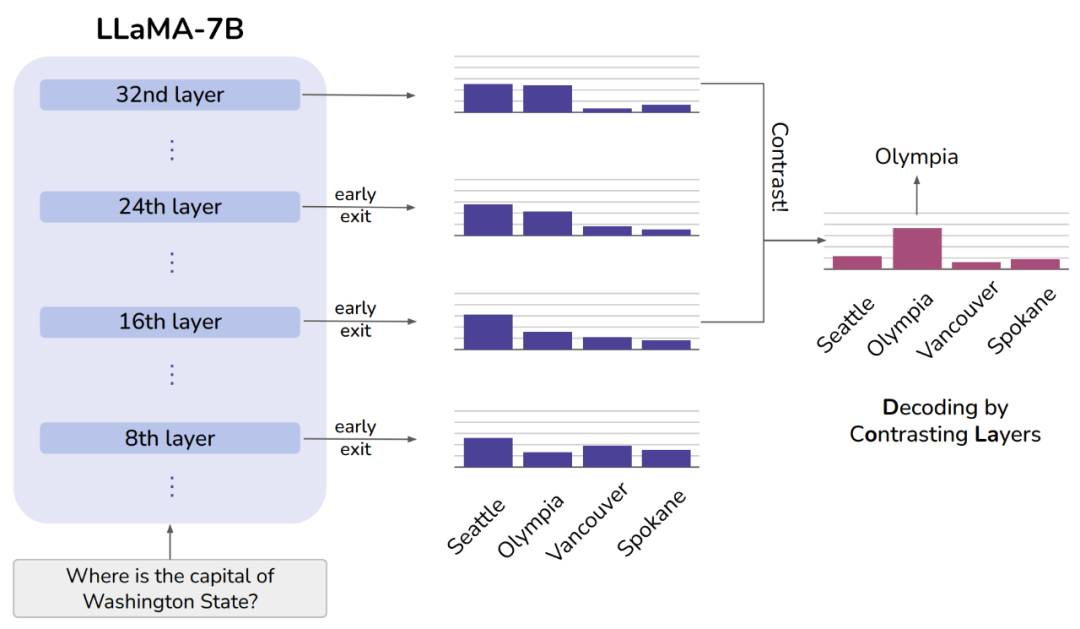 图2. DoLa示意图
图2. DoLa示意图
技术突破
TaD的基本原理如图3所示。微调前LLM和微调后LLM的输出词均为“engage”,但深入探究不难发现其相应的预测概率分布发生了明显的改变,这反映了LLM在微调期间试图将其固有知识尽可能地适应下游任务的特定领域知识。具体而言,经过微调,更加符合用户输入要求(“专业的”)的词“catalyze”的预测概率明显增加,而更通用的反映预训练过程习得的知识却不能更好满足下游任务用户需求的词“engage”的预测概率有所降低。TaD巧妙利用微调后LLM与微调前LLM的输出概率分布的差异来构建知识向量,得到更贴切的输出词“catalyze”,进而增强LLM的输出质量,使其更符合下游任务偏好,改善幻觉。
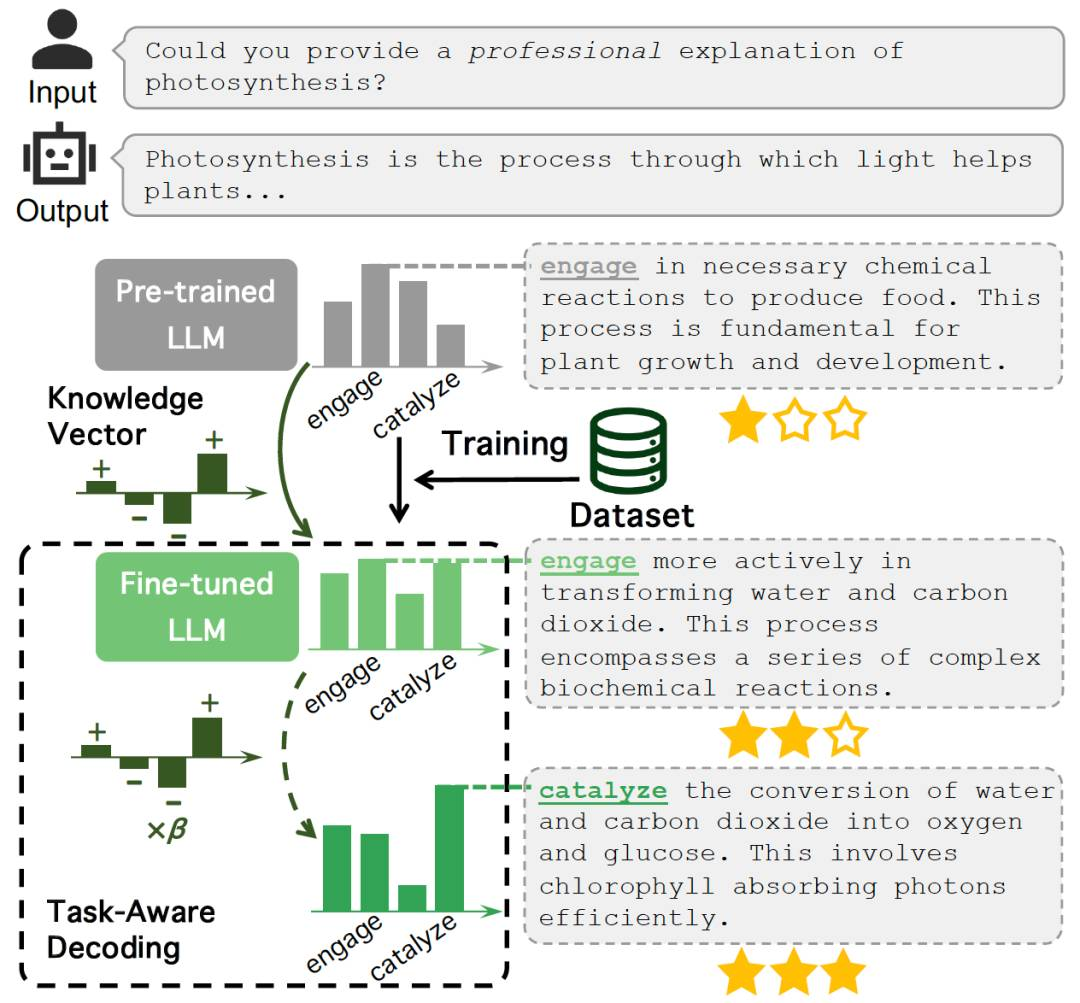 图3. TaD原理图
图3. TaD原理图
为了直观理解LLM在微调阶段学习到的特定领域知识,我们引入知识向量的概念,具体如图4所示。微调前LLM的输出条件概率分布为pθ,微调后LLM的输出条件概率分布为 pϕ。知识向量反应了微调前后LLM输出词的条件概率分布变化,也代表着LLM的能力从公共知识到下游特定领域知识的适应。基于TaD技术构建的知识向量可强化LLM微调过程中习得的领域特定知识,进一步改善LLM幻觉。
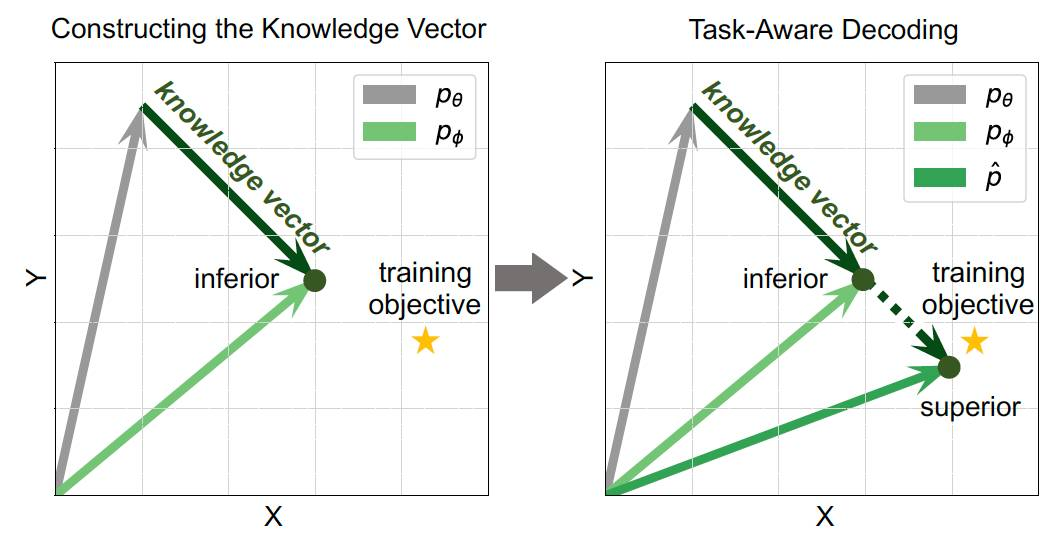 图4. 知识向量
图4. 知识向量
1)针对不同的LLM,采用LoRA、AdapterP等方式、在不同的任务上进行微调,实验结果如下表1和表2所示。注意到,TaD技术均取得了明显的正向效果提升。
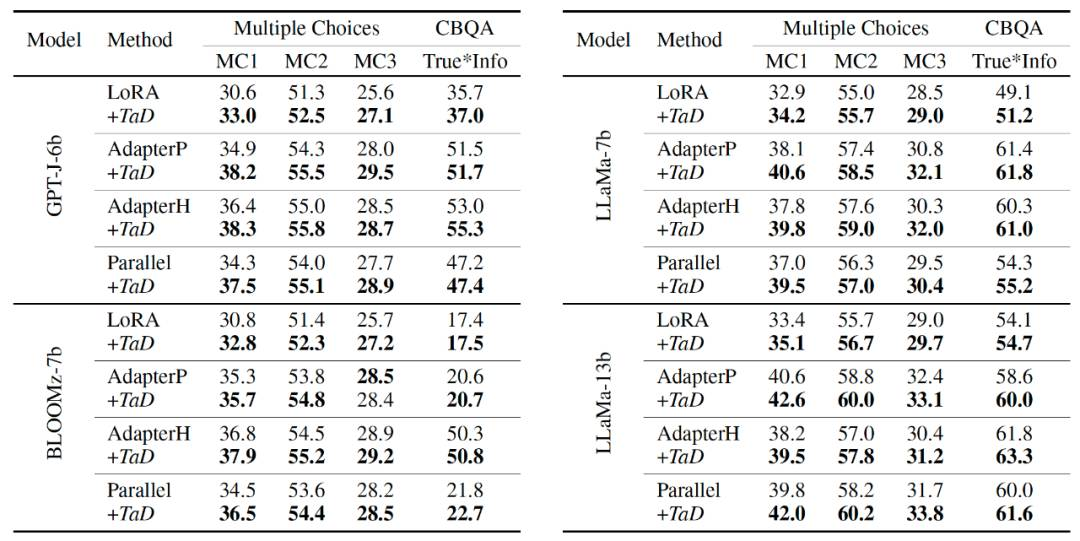 表1. Multiple Choices和CBQA任务结果
表1. Multiple Choices和CBQA任务结果 表2. 更具挑战性的推理任务结果
表2. 更具挑战性的推理任务结果
2)相比较其他对比解码技术,TaD技术在绝大部分场景下效果占优,具体如表3所示。需要特别强调的一点是,其他技术可能会导致LLM效果下降,TaD未表现上述风险。
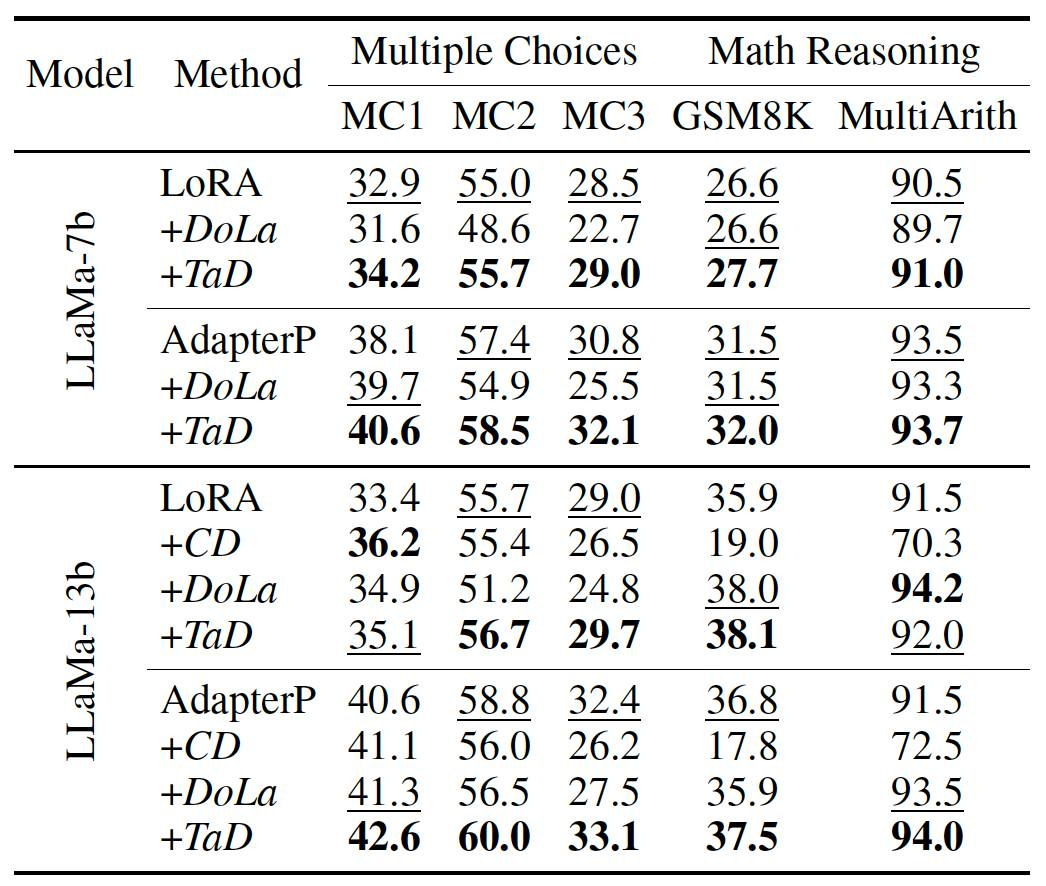 表3. 不同对比解码技术结果
表3. 不同对比解码技术结果
3)针对不同比例的训练样本进行实验,发现一个非常有趣的结果:训练样本越少,TaD技术带来的收益越大,具体如表4所示。因此,即使在有限的训练数据下,TaD技术也可以将LLM引导到正确的方向。由此可见,TaD技术能够在一定程度上突破训练数据有限情形下LLM的效果限制。
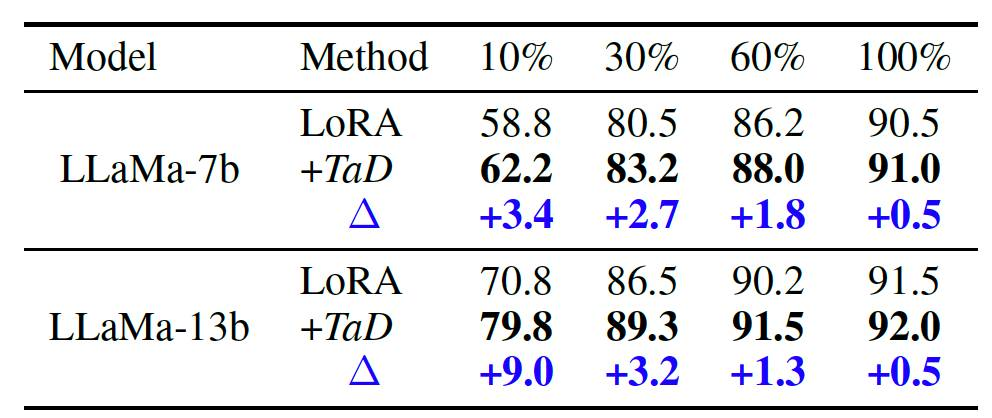 表4. 不同数据比例下的结果
表4. 不同数据比例下的结果落地案例
自从以ChatGPT为代表的LLM诞生之后,针对其应用的探索一直如火如荼,然而其幻觉已然成为限制落地的最大缺陷。综上分析,目前检索增强生成(RAG)+低幻觉的LLM是缓解LLM幻觉的最佳组合疗法。在京东通用知识问答系统的构建中,我们通过TaD技术实现低幻觉的LLM,系统层面基于RAG注入自有事实性知识,具体方案如图5所示,最大程度缓解了LLM的生成幻觉 。
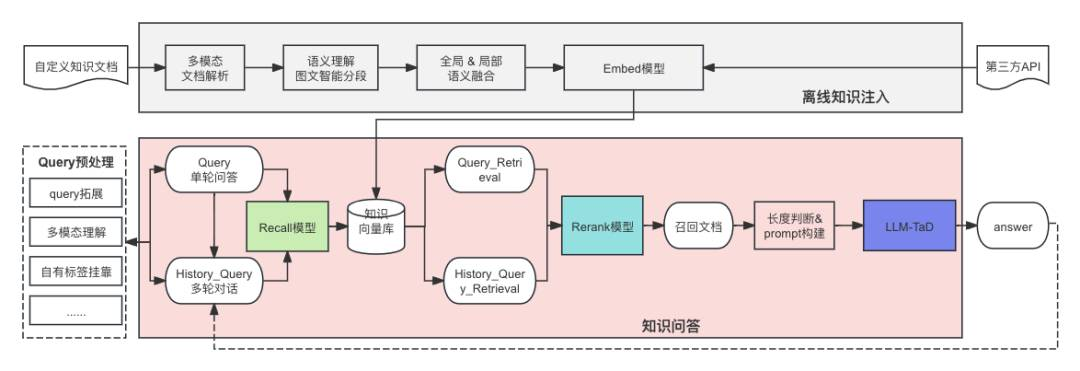 图5. TaD+RAG的知识问答系统
图5. TaD+RAG的知识问答系统
思考与展望
如果LLM依然按照语言模型的模式发展,那么其幻觉就无法彻底消除。目前业内还没有一种超脱语言模型范畴,且可以高效完成自然语言相关的任务新的模型结构。因此,缓解LLM的生成幻觉,仍然是未来一段时期的探索路径。以下是我们在系统、知识、LLM三个层面的一些简单的思考,希望能够抛砖引玉。
LLM本身的幻觉是问题的根本和瓶颈,我们认为随着LLM更广泛的应用,类似TaD可缓解LLM本身幻觉的探索一定会成为业内的更大的研究热点。
落地案例
缓解LLM幻觉一定是个复杂的系统问题,我们可以综合不同的技术方案、从多个层级协同去降低LLM的幻觉。虽然现有方案无法保证从根本上解决幻觉,但随着不断探索,我们坚信业内终将找到限制LLM幻觉的更有效的方案,也期待届时LLM相关应用的再次爆发式增长。
【参考文献】
[1] Hallucination is Inevitable: An Innate Limitation of Large Language Models
[2] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
[3] Unveiling the Causes of LLM Hallucination and Overcoming LLM Hallucination
[4] Editing Large Language Models: Problems, Methods, and Opportunities
[5] ACL 2023 Tutorial: Retrieval-based Language Models and Applications
[6] Theoretical Limitations of Self-Attention in Neural Sequence Models
[7] Sequence level training with recurrent neural networks.
[8] Discovering language model behaviors with model-written evaluations
[9] Dola: Decoding by contrasting layers improves factuality in large language models
[10] Bert rediscovers the classical nlp pipeline
[11] Retrieval-Augmented Generation for Large Language Models: A Survey
[12] TaD: A Plug-and-Play Task-Aware Decoding Method toBetter Adapt LLM on Downstream Tasks
[13] Inference-time intervention: Eliciting truthful answers from a language model
[14] Beyond RAG: Building Advanced Context-Augmented LLM Applications
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活