
包阅导读总结
1.
关键词:Uber、Apache Kafka、Tiered Storage、Efficiency、Complexity
2.
总结:Uber 为 Apache Kafka 引入分层存储功能,旨在解决大规模集群的可扩展性和效率问题。该功能虽有诸多优势,但也存在局限和引发新的复杂性,使用时需谨慎评估和监测。
3.
主要内容:
– Uber 为 Apache Kafka 3.6.0 增加分层存储功能,目前处于早期访问阶段。
– 功能目的是应对大规模 Kafka 集群的可扩展性和效率挑战。
– 允许扩展存储到远程系统,独立于计算资源扩展存储,降低成本和复杂度。
– 分层存储架构有本地和远程两层,可设不同保留策略。
– 引入新组件促进存储过程。
– AWS 进一步发展此概念,展示其在可用性、恢复、负载均衡和缩放方面的优势。
– 存在不同观点,有人认为可降低成本,也有人担忧引入新复杂和潜在失败模式。
– 如性能受影响、成本可能未节省、加重现有问题等。
– 该功能有当前局限,使用时需监测。
– 不支持多日志目录或压缩主题等。
– 关闭分层需转移数据。
思维导图: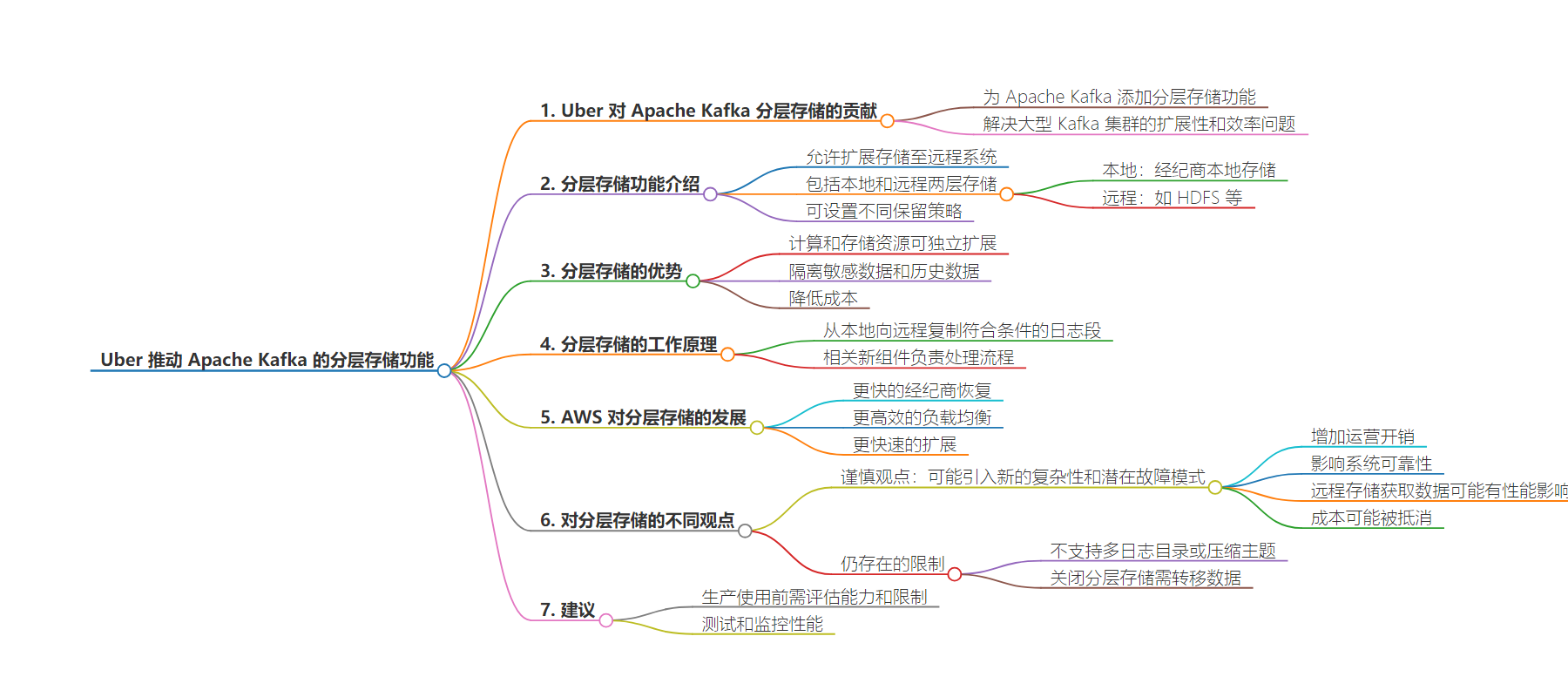
文章来源:infoq.com
作者:Matt Saunders
发布时间:2024/8/14 0:00
语言:英文
总字数:1083字
预计阅读时间:5分钟
评分:89分
标签:Apache Kafka,分级存储,Uber,亚马逊云服务,红帽
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Transportation company Uber have detailed their work in adding a new tiered storage feature toApache Kafka, the popular distributed event streaming platform. This feature, added in 3.6.0 and currently in early access, aims to address the scalability and efficiency challenges faced by organizations running large Kafka clusters.
Tiered storage allows Kafka to extend its storage capabilities beyond local broker disks to remote storage systems like HDFS, Amazon S3, Google Cloud Storage, and Azure Blob Storage. This enhancement enables Kafka clusters to scale storage independently from compute resources, potentially reducing costs and operational complexity.
According to Uber’s blog post, the project’s motivation was to overcome limitations in how Kafka clusters are typically scaled.
“Kafka cluster storage is typically scaled by adding more broker nodes. But this also adds needless memory and CPUs to the cluster, making overall storage cost less efficient compared to storing the older data in external storage”
They added that larger clusters with more nodes increase deployment complexity and operational costs due to the tight coupling of storage and processing.
The tiered storage architecture introduces two storage tiers: local and remote. The local tier consists of the broker’s local storage, while the remote tier is the extended storage such as HDFS or cloud object stores. Both tiers can have separate retention policies based on specific use cases.
/filters:no_upscale()/news/2024/08/apache-kafka-tiered-storage/en/resources/1unnamed-1723414838261.png)
Red Hat, in a detailed analysis of the feature, outlined its benefits:
- Elasticity: Compute and storage resources can now be scaled independently.
- Isolation: Latency-sensitive data can be served from the local tier, while historical data is served from the remote tier without changes to Kafka clients.
- Cost efficiency: Remote object storage systems are generally less expensive than fast local disks, making Kafka storage cheaper and virtually unlimited.
The tiered storage system works by copying eligible log segments from local to remote storage. A log segment is considered eligible if its end offset is less than the last stable offset of the partition. The broker acting as the leader for a topic partition is responsible for this copying process.
Uber’s implementation introduces new components to facilitate this process:
- RemoteStorageManager: Handles actions for remote log segments, including copying, fetching, and deleting from remote storage.
- RemoteLogMetadataManager: Manages metadata about remote log segments with strongly consistent semantics.
- RemoteLogManager: Oversees the lifecycle of remote log segments, including copying to remote storage, cleaning up expired segments, and fetching data from remote storage.
AWS has further developed this concept with Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage. According to AWS in a blog post , this feature significantly improves the availability and resiliency of Kafka clusters. The AWS engineers who authored the post highlight several key advantages:
- Faster broker recovery: With tiered storage, data automatically moves from faster Amazon Elastic Block Store (Amazon EBS) volumes to the more cost-effective storage tier over time. When a broker fails and recovers, the catch-up process is faster because it only needs to sync data stored on the local tier from the leader.
- Efficient load balancing: Load balancing in Amazon MSK with tiered storage is more efficient because there is less data to move while reassigning partitions. This faster, less resource-intensive process enables more frequent and seamless load-balancing operations.
- Faster scaling: Scaling an MSK cluster with tiered storage is seamless. New brokers can be added to the cluster without a large amount of data transfer and a longer partition rebalancing.
/filters:no_upscale()/news/2024/08/apache-kafka-tiered-storage/en/resources/1ts-p3-3-1024x524-1723414838261.jpg)
AWS conducted a real-world test to demonstrate these benefits using a three-node cluster with m7g instance types. They created a topic with a replication factor of three and ingested 300 GB of data. When adding three new brokers and moving all partitions from the existing brokers to the new ones, the operation took approximately 75 minutes without tiered storage and caused high CPU usage. After enabling tiered storage on the same topic, with a local retention period of 1 hour and a remote retention period of 1 year, they repeated the test. This time, the partition movement operation was completed in just under 15 minutes, with no noticeable CPU usage. AWS attributes this improvement to the fact that only the small active segment needs to be moved with tiered storage enabled, as all closed segments have already been transferred to tiered storage.
However, only some in the industry share the enthusiasm for tiered storage. Richard Artoul from WarpStream offers a more cautious perspective, arguing that while tiered storage can help reduce costs, it may introduce new complexities and potential failure modes. Artoul suggests that the added complexity of managing two storage tiers could increase operational overhead and impact system reliability.
Artoul raises concerns about the performance implications of fetching data from remote storage, which could introduce latency and affect real-time processing capabilities. He points out that the cost savings of tiered storage might be offset by the expenses associated with managing and accessing data in remote storage systems, particularly due to inter-zone networking fees in cloud environments. Furthermore, Artoul argues that tiered storage needs to address the two primary problems that users have with Kafka today: complexity and operational burden, as well as costs (specifically, inter-zone networking fees). He suggests that tiered storage may exacerbate these issues rather than solve them.
While tiered storage offers potential advantages, it’s important to note some current limitations. As per Red Hat’s analysis, the feature still needs to support multiple log directories (JBOD) or compacted topics. Additionally, turning off tiering on a topic requires transferring data to another topic or external storage before deleting the original topic.
Both Uber and Red Hat emphasize the importance of monitoring when using tiered storage. New metrics have been introduced to track remote storage operations, allowing users to monitor and create alerts for potential issues such as slow upload/download or high error rates.
Uber has been running this feature in production for 1-2 years on different workloads, but it’s still considered early access in the open-source Apache Kafka 3.6.0 release. Organizations considering adoption should carefully evaluate its current capabilities and limitations.
Introducing tiered storage potentially enables more efficient and cost-effective management of large-scale data streams. As demonstrated by AWS’s implementation in Amazon MSK, it can dramatically improve cluster resilience and scalability in some scenarios. However, Artoul’s critique highlights that the feature may only be a silver bullet for some Kafka users. As with any new feature, particularly in early access, users are advised to thoroughly test and monitor its performance in their specific environments before deploying to production, weighing the potential benefits against the added complexity and operational challenges.