
包阅导读总结
1. 关键词:Kafka、性能优化、网络闲置率、请求队列、资源节约
2. 总结:本文主要讲述去哪儿 Kafka 集群承载量大,春节高峰流量高。发现网络闲置率低,机器处理能力达上限。经排查优化,添加监控指标,调整 filebeat 参数,最终节约 2000 核 CPU,后续预计能继续提升集群性能。
3. 主要内容:
– Kafka 集群承载全司大量日志和数据
– 春节高峰流量巨大
– 发现问题
– 个别机器闲置率近 0,处理能力达上限
– 增加节点成本高,需优化服务本身
– 排查问题
– 服务端日志无法定位
– 机器硬件指标未达上限,cpu 压测期间下降表明集群性能有问题
– tcp 链接数无明显变化
– 优化措施
– 深入分析架构,添加监控信息
– 测试刷盘时间相关参数,对闲置率无影响
– 调整 filebeat 参数,降低请求量
– 优化效果
– 请求数降低 10 倍,机器闲置率提高,CPU 使用降低
– 上线一周后节约 2000 核 CPU,后续有望继续提升性能
思维导图: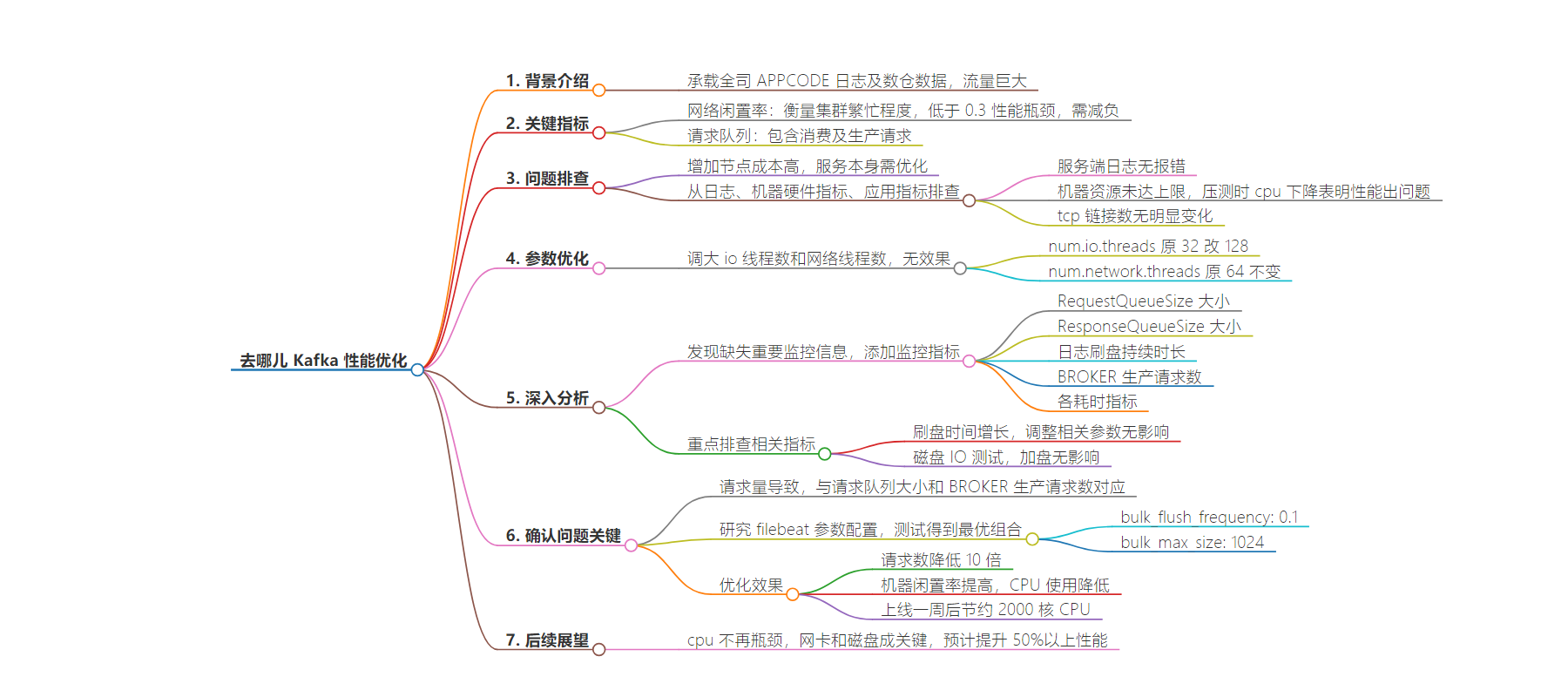
文章地址:https://mp.weixin.qq.com/s/hOkgWgi_sjemkFi93dYldQ
文章来源:mp.weixin.qq.com
作者:余东&贾建东&徐伟
发布时间:2024/7/23 10:50
语言:中文
总字数:4088字
预计阅读时间:17分钟
评分:80分
标签:Kafka优化,性能优化,大数据运维,CPU资源节省,去哪儿旅行
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
-
日志KAFKA集群承载了全司的APPCODE日志,比如我们常用的QTRACE日志,以及实时离线数仓数据,体量非常大。
-
春节高峰每分钟流量1.3TP,每分钟接收20亿条数据。
-
每天数据流量1.5PB,每天接收消息条数超过两万亿。
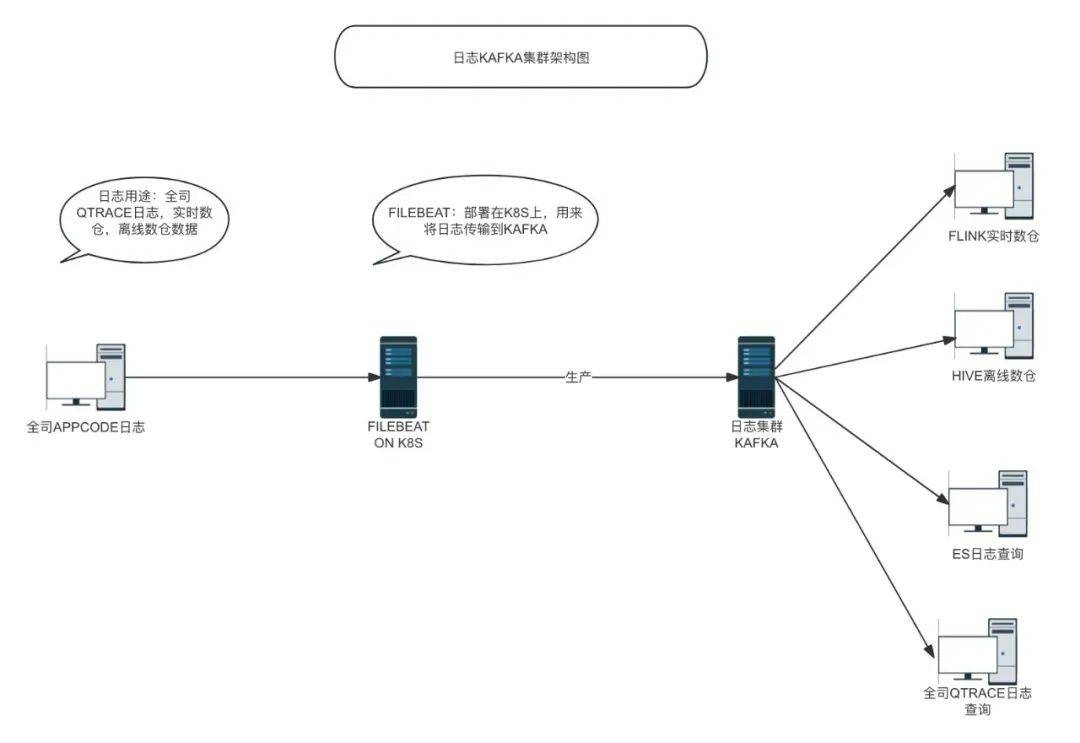
-
Broker:kafka集群中的一个节点。
-
网络闲置率:是kafka服务的一个重要指标,即网络线程池线程平均的空闲比例,通常用于衡量集群的繁忙程度。集群没有流量时为最大值1,随着集群压力变大会逐渐变小,达到0.3以下集群性能就会达到瓶颈,就表明你的网络线程池非常繁忙,集群无法保证读写请求的及时处理,造成生产丢数已经消费堆积的问题。需要通过增加网络线程数或将负载转移给其他服务器的方式,来给该 Broker 减负。
-
请求队列:客户端发起的请求首先存放在这个队列,服务端拉取请求并进行处理。主要包含了消费以及生产请求。

个别机器闲置率接近于0,代表当前KAFKA机器处理能力已经达到上限了。
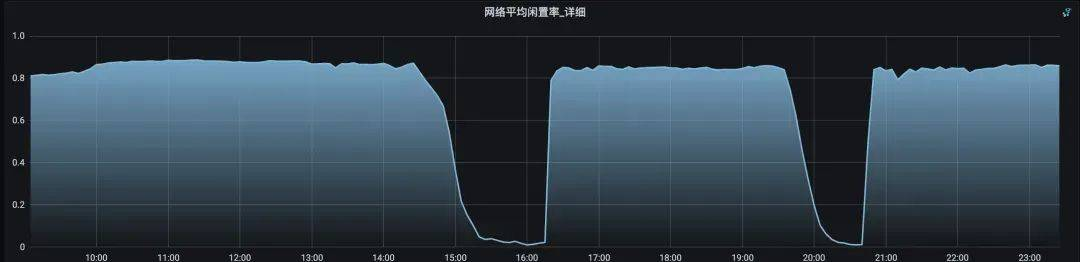
从现象及后面的测试发现,增加节点可以解决,但会产生巨大的成本。同时,机器层面还未达到瓶颈,这说明是服务本身需要优化,因此我们着重去优化kafka本身。
综合考虑后发现有两个外界因素在影响这个指标,一个是数据量变大,另一个是高峰期pod扩展较多,网络链接数变大。但具体什么问题需要精确定位,我们准备从日志、机器硬件指标、应用指标逐个排查。
通过对网络闲置率低的机器进行排查,服务端并没有明显的日志报错,日志无法定位具体问题。
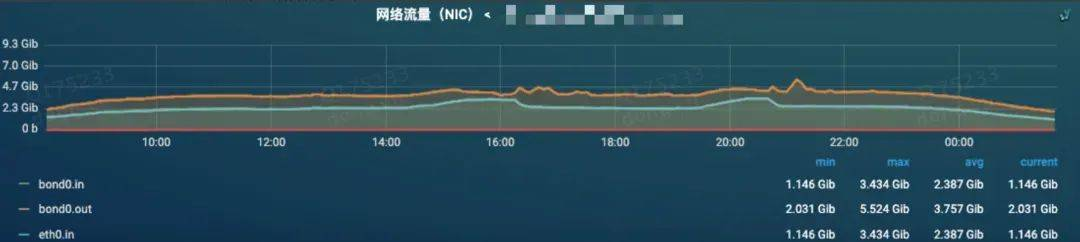
闲置率低的机器排查机器本身的资源使用,发现网卡流量、磁盘使用率、内存使用、cpu使用都没有达到上限、下面是各个指标的监控图:
网络流量监控,压测期间入口流量有所上涨,出口流量上涨不明显。
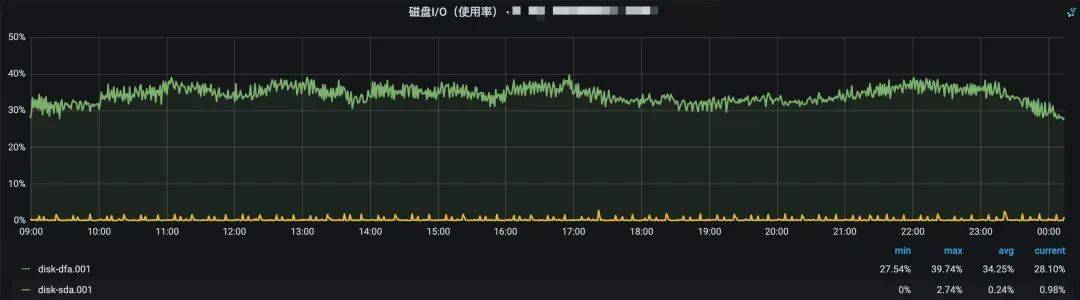
磁盘IO监控,可以发现压测期间IO使用率有所上涨,但并没有达到上限。
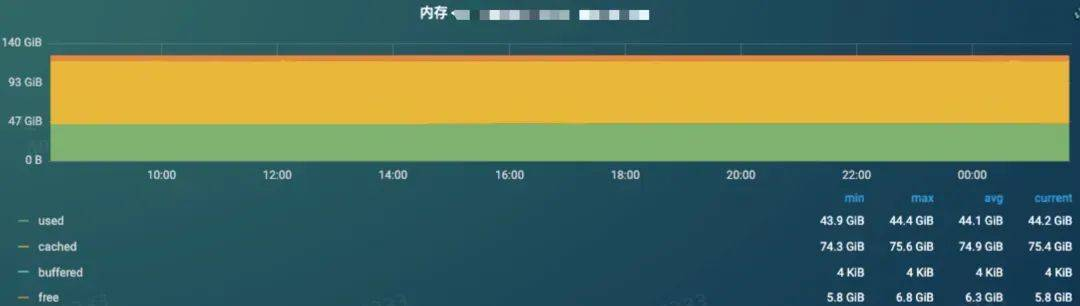
内存监控,内存没有明显的变化。
cpu在压测期间反而在下降,充分说明集群性能此时已经出现问题。

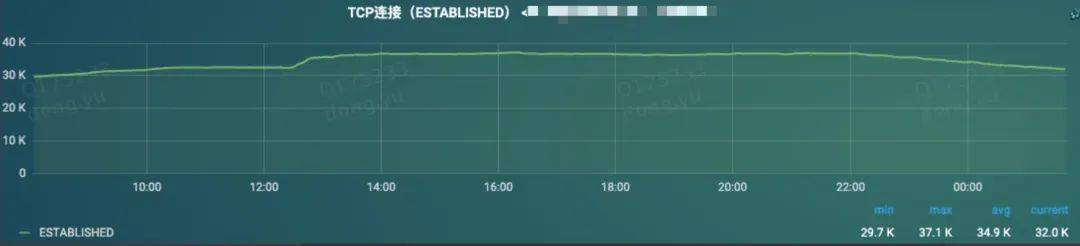
tcp链接数没有明显变化,说明长链接并没有大的变化。
影响网络闲置率最直接的两个参数就是io线程数和网络线程数。
系统默认值 num.io.threads=3、num.network.threads=8 这两个参数分别是代表磁盘IO的线程数量、处理网络请求的线程数量。这两个值集群已经做过优化,继续调大之后并没有效果。
原参数num.io.threads=32num.network.threads=64修改后参数num.io.threads=128num.network.threads=64
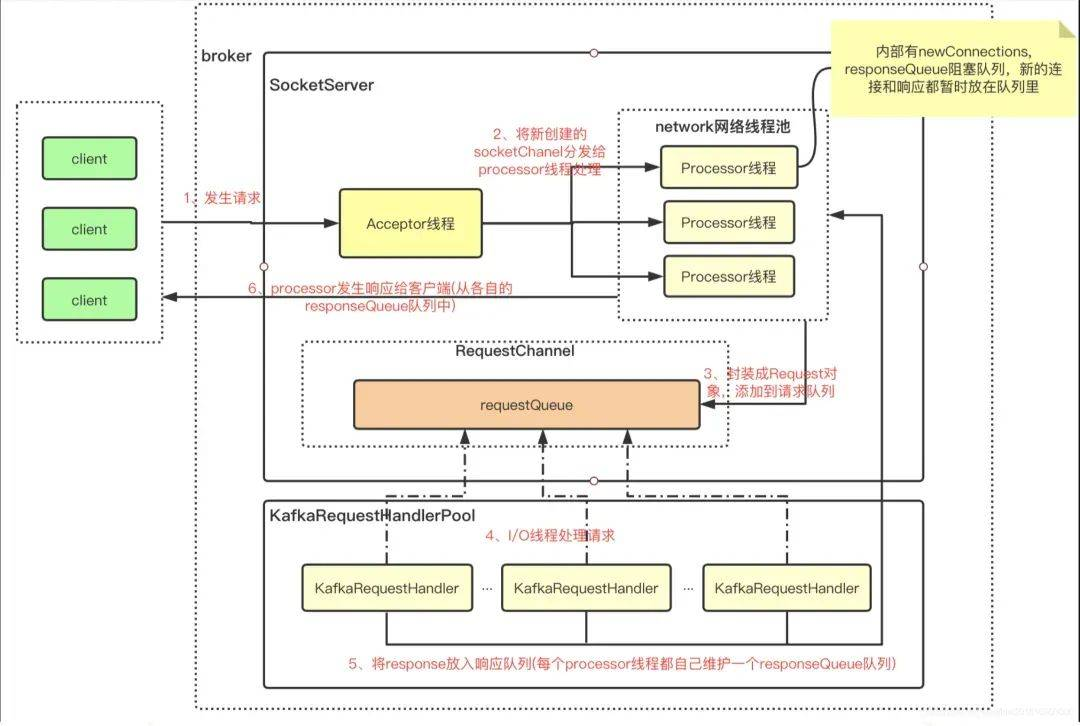
深入分析KAFKA架构,从客户端发起请求,到客户端处理逻辑流程进行深入分析。其中包含了客户端的发起请求后,服务端如何接收请求,以及如何处理请求后,反馈给客户端。
基于此分析,发现了KAFKA集群缺失了很多重要的监控信息,比如请求队列大小,请求耗时,客户端请求量。于是我们根据网络架构进行必要的监控添加,用于发现瓶颈。
kafka服务的各项指标,都是从jmx中获取,由于jmx中有大量指标,我们平时获取只关注了重点部分指标,这次准备把可能有关联的相关指标都打出来观察。
增加了下面这些指标:RequestQueueSize大小,ResponseQueueSize大小 ,日志刷盘持续时长,BROKER生产请求数,Produce耗时指标 P999,FetchFollower耗时指标 P999,FetchConsumer耗时指标P999,TotalFetchRequestsPerSec,TotalProduceRequestsPerSec。
添加指标后经过观察,趋势有相关的指标有 RequestQueueSize大小、日志刷盘持续时长、BROKER生产请求数,下面重点排查这些指标。
当闲置率低的时候,发现刷盘时间也在增长,刷盘时间有两部分因素控制,一部分是Kafka本身的参数,另一部分就是磁盘的IO。我们通过两部分的测试来验证是否有关联。
Kafka 的刷盘时间指的是将数据从内存刷新到持久存储设备(如硬盘)所需的时间。Kafka 的性能直接影响其可以处理的消息量,而这个时间就是影响这一性能的一个关键因素。刷盘时间相关重要的两个参数为:
通过对这两个参数的不同数值的调整,最后发现对闲置率没有影响。
log.flush.interval.messages=10000log.flush.interval.ms=1000
对于磁盘IO的影响,线上我们都是用单盘提供服务,如果我们改用双盘,两个盘理论上是单盘IO两倍的性能,但是加盘之后,同样的压测数据,对闲置率没有影响。
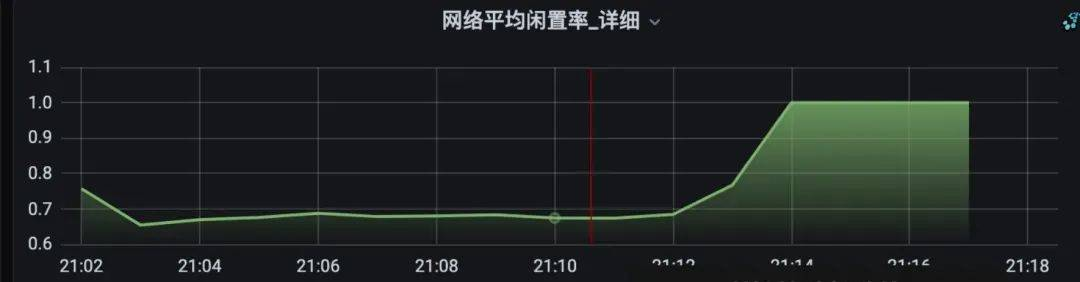
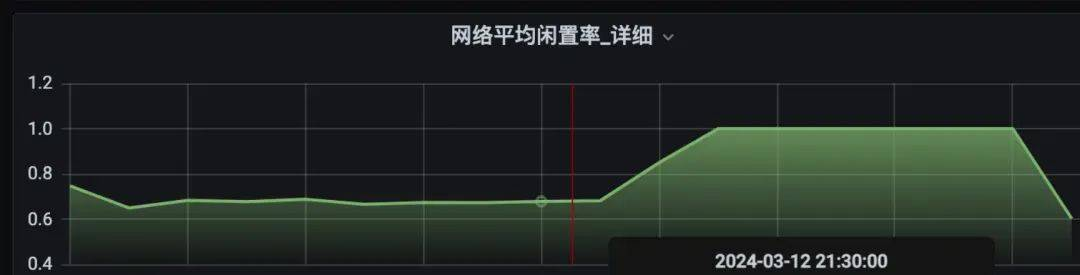
kafka每个broker会有一个请求队列,这个队列有一个默认值大小。当队列打满的时候说明服务端无法快速消化大量打过来的请求,这个指标和【BROKER生产请求数】指标可以对应上。同时也可以解释外部的两个因素,流量上涨和pod扩容。
通过测试环境确认,当broker请求量达到一定值以后,请求队列逐步打满,闲置率开始下降,cpu使用率开始下降,复现了线上的现象。
确认了问题的关键是请求量之后,需要想办法降低请求量,kafka的请求在filebeat客户端。我们需要研究filebeat的参数配置。
从filebeat官网确认,涉及到批次发送的有两个参数bulk_flush_frequency 和 bulk_max_size,线上使用的filebeat没有配置这两个参数。
其中含义如下:
针对这两个参数我们做了测试:
由于单条数据量不同会产生不同的效果,我们对不同的的数据长度做了测试,针对我司日志特点(单条日志大小),最后得到一个最优的组合如下,增加了这俩参数后,KAFKA TOPIC在不丢数的情况下,请求数降低了10倍左右。
bulk_flush_frequency: 0.1bulk_max_size:1024
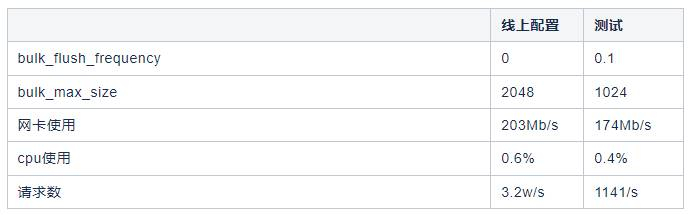
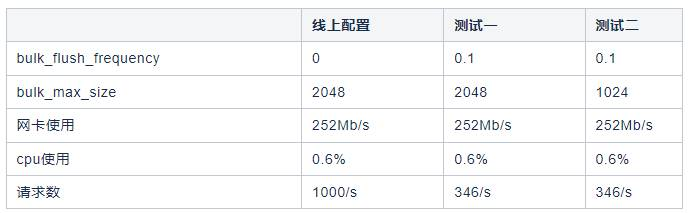
从上面测试结果可以看到不同的批次下,网卡流量会有变化,这个现象最初我们理解为kafka性能的下降。通过测试发现,批次提高后压缩比会提高,网络层面也是一个间接的优化效果。而且不光是网络,磁盘也会有节约,下面是不同批次下的压缩数据测试。
通过测试可以发现,条数超过50条的时候压缩比基本保持一致。这里的数据单条1KB。
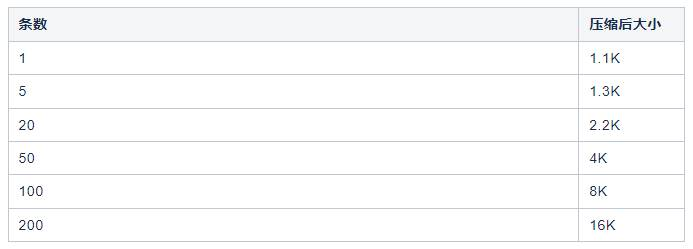
找到线上的一些代表性的topic进行测试,测试结果符合预期,生产请求数降到原来的1/10,所在机器闲置率提高0.02-0.06,同时分区所在机器CPU使用降低了5个点。
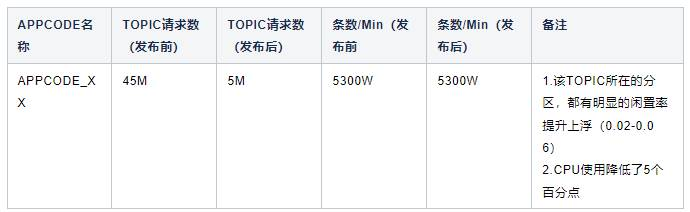
灰度测试没问题后,开始发布线上版本,但线上应用,需要重新发布才能生效。发布一周后效果明显,cpu、网络流量、磁盘都有不同程度的资源节约。
下面是上线一周后的数据:
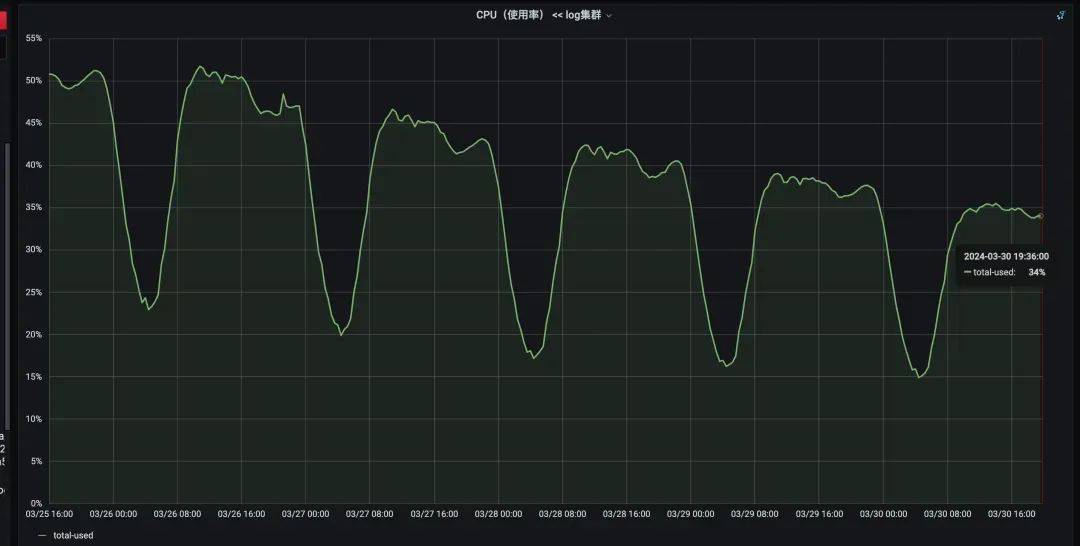
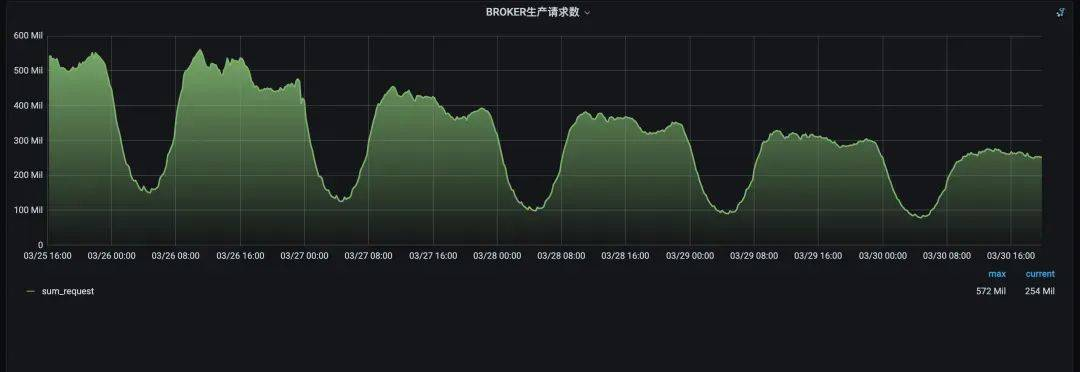
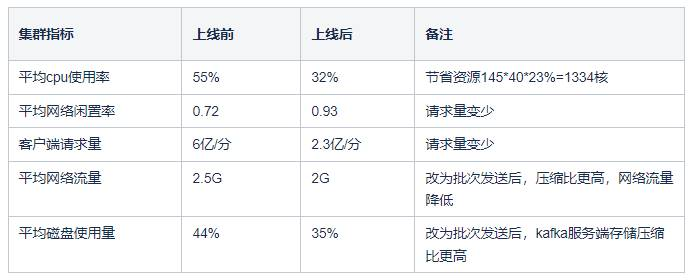
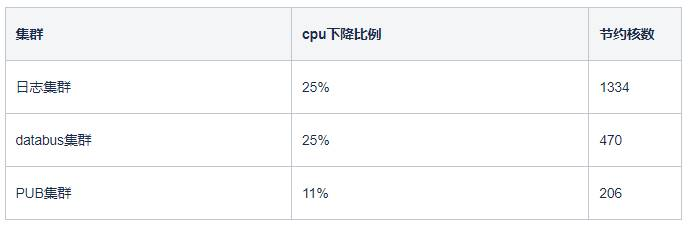
日志集群CPU明细图, 降低了145*40*23%=1334核
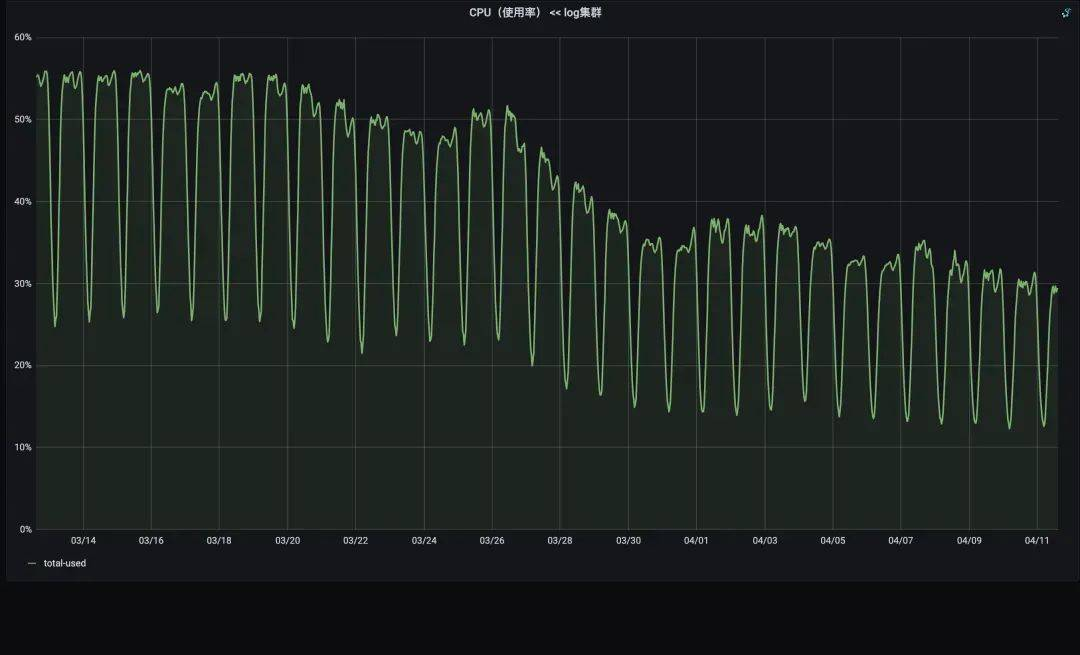
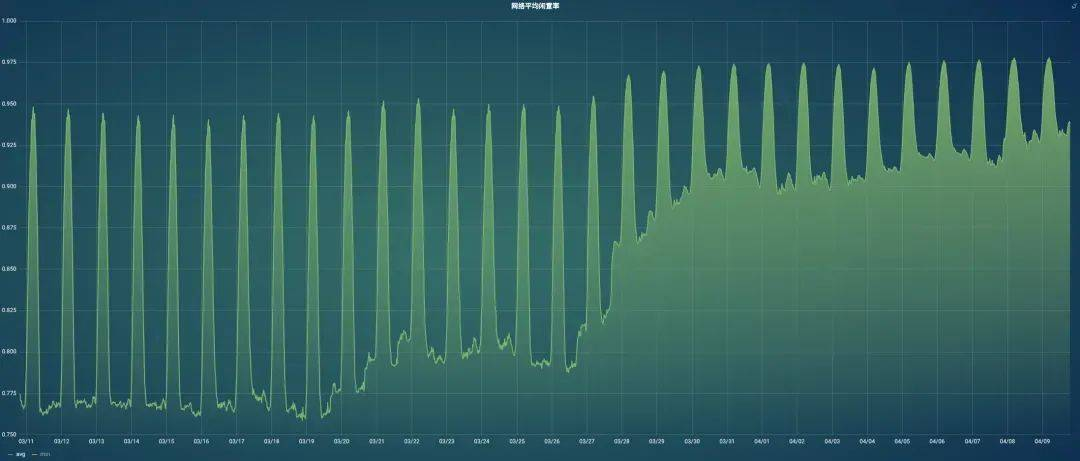
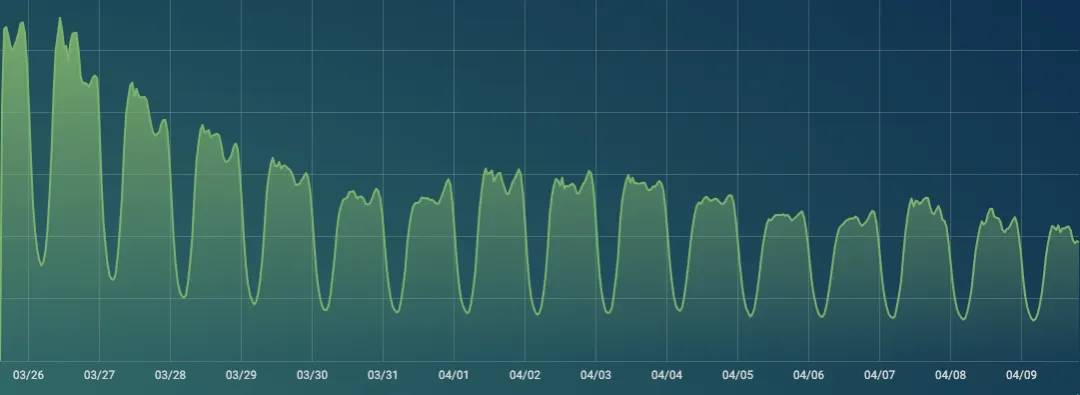
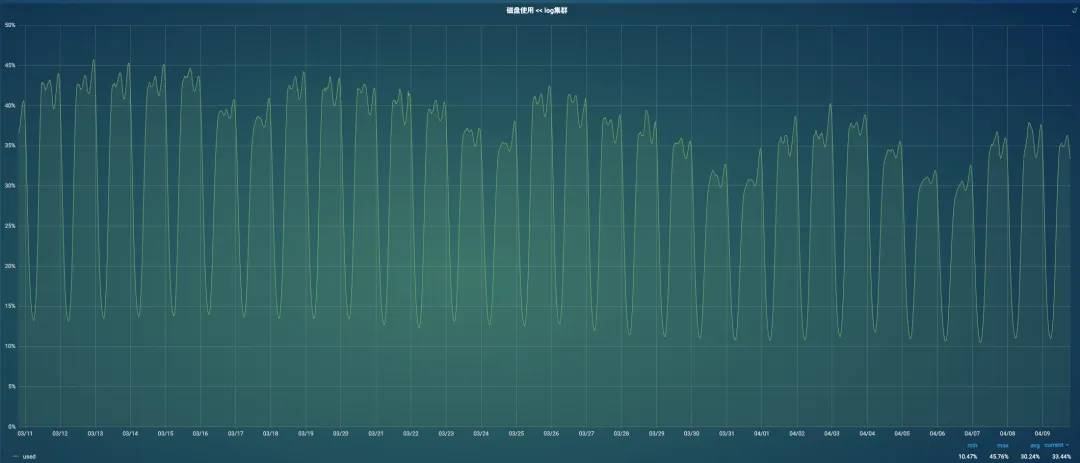
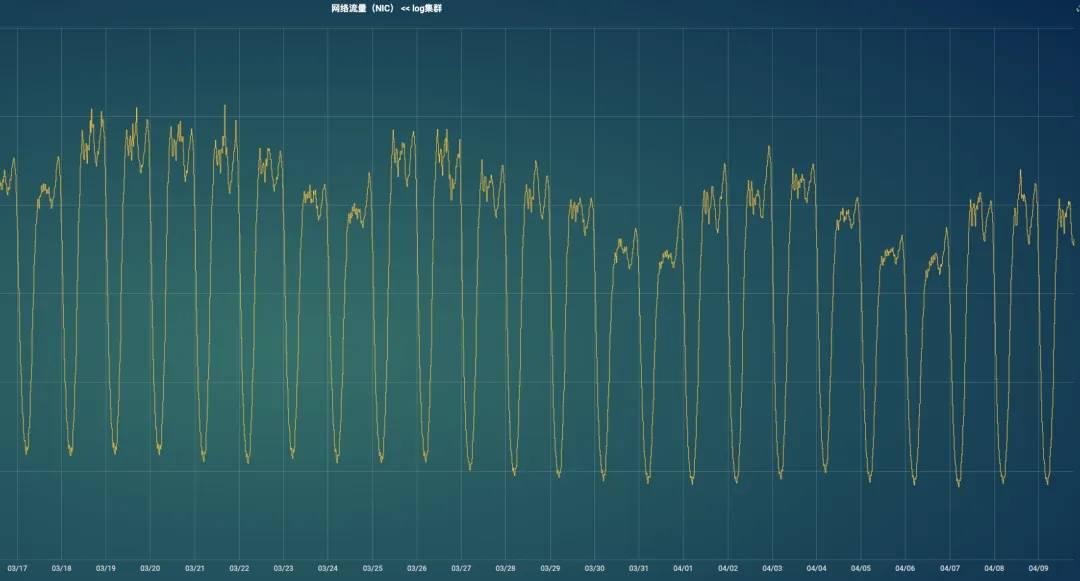
3个KAFKA集群一起优化后,最终节约2000核。
经过上述优化后,cpu不再是单机的性能瓶颈,转而变成网卡和磁盘。
在不改变CPU和内存的情况下,通过这两方面的改造后,预计可以继续提升集群50%以上的性能。