
包阅导读总结
1. 关键词:流量劫持、前端、后端、请求拦截、ReadableStream
2. 总结:本文介绍了统一认证平台项目开发中遇到的问题,引出流量劫持概念,从前台视角给出fetch和xhr请求拦截的方案设计及实现,还探讨了ReadableStream在请求中的应用,并提到上传下载方式及服务端相应改造。
3. 主要内容:
– 统一认证平台项目开发背景及问题
– 参与统一认证平台项目,需统一管理认证和授权
– 不同子项目前端框架和三方请求库不同,修改工作量大
– 流量劫持相关
– 定义及常见层级,如DNS、HTTP、HTTPS劫持
– 常见应用场景,如广告注入、内容过滤、监控、负载均衡
– 前后端流量劫持差异,如劫持方式和主要影响
– 前台视角的请求拦截方案
– 目的:客户端请求前后拦截处理
– fetch请求拦截
– 核心原理:复写apply实现
– 获取请求信息处理
– 处理request.body的特殊情况
– 处理响应
– xhr请求拦截
– 核心原理:复写构造函数、open和send实现
– open、send等函数的处理
– 延伸思考与学习ReadableStream
– 概念:可读的流数据源
– 使用场景与示例
– 网络请求响应、文件处理、音视频处理
– 文件下载与上传的实现方案
– 文件下载:小文件与大文件的处理方式
– 文件上传:FormData形式与ReadableStream形式,及服务端改造
思维导图: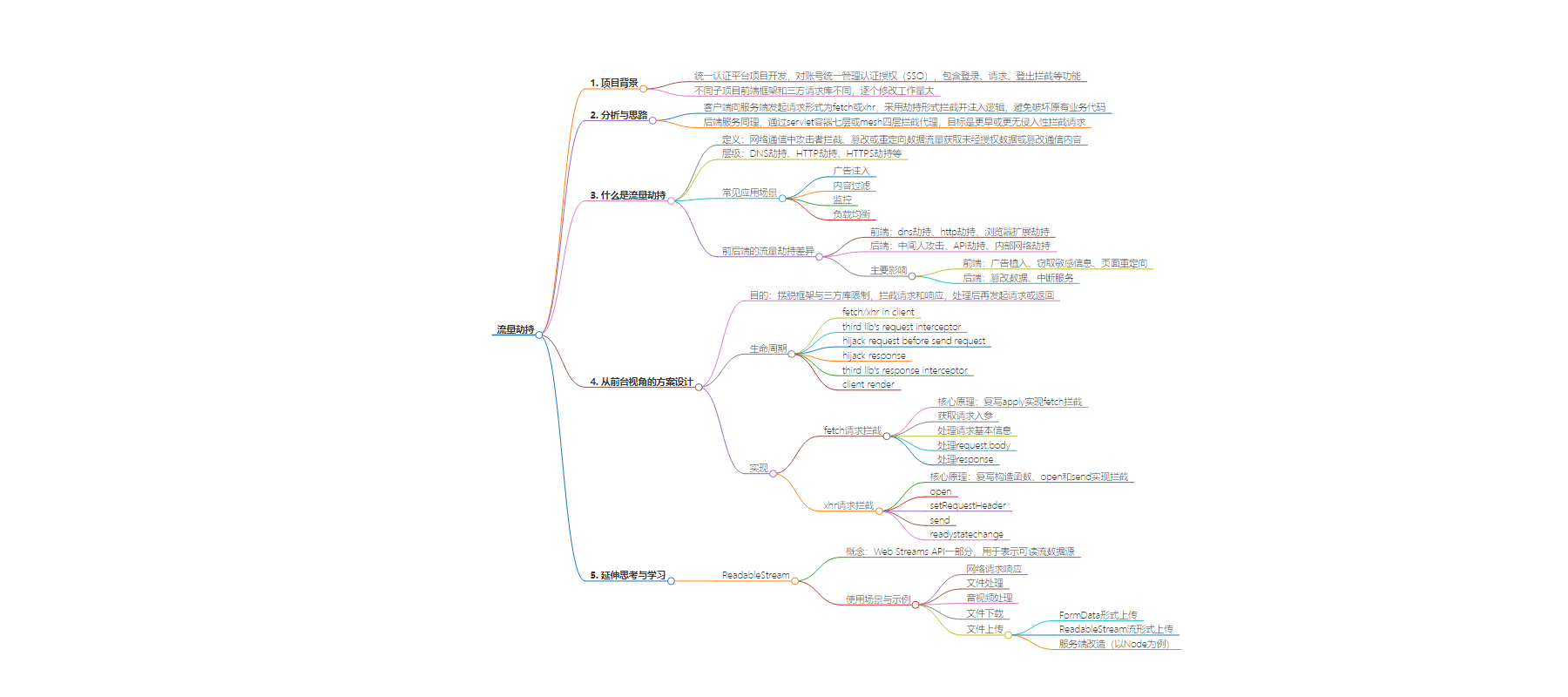
文章地址:https://mp.weixin.qq.com/s/XqfQQpd6PRF5gs4D6vxyXg
文章来源:mp.weixin.qq.com
作者:磊叔的技术博客
发布时间:2024/8/12 8:06
语言:中文
总字数:5965字
预计阅读时间:24分钟
评分:80分
标签:流量劫持,前端开发,后端服务,网络安全,请求拦截
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
点击关注公众号,“技术干货”及时达!
本文为稀土掘金技术社区首发签约文章
背景
最近在工作中参与了一个统一认证平台项目的开发,其核心目的是对整个大系统所关联的所有子系统的账号进行统一管理认证并且授权(SSO),方便后续的管理与使用。这其中包含功能如登录拦截、请求拦截、登出拦截等功能。
在对接中,存在一个很直接的问题,不同的子项目采用不同风格的前端框架,不同的三方请求库(eg: axios等)。如果逐个系统修改,势必会造成很大的重复工作量。如何在不破坏已有业务代码的基础上,无缝对接?
分析后,发现归根到底,客户端向服务端发起请求无外乎fetch或xhr的形式来进行,如果采用劫持的形式来对fetch 或xhr进行拦截,在拦截中注入特定的逻辑,从而可以避免破坏原有的业务代码。
上述是从前端的角度来剖析流量劫持问题,对于后端服务来说,也是同样的思路,不管是通过 servlet 容器在七层进行请求的拦截代理,还是通过 mesh 在四层来完成请求的拦截代理,主要的目标是实现如何更早或者更无侵入性的完成对于请求的拦截。
什么是流量劫持
本小节先介绍下什么是流量劫持,流量劫持在实际的业务场景的有哪些应用,以及我们所说的流量劫持在前后端实现逻辑上的差异有哪些等。
流量劫持
流量劫持(Traffic Hijacking)是指在网络通信过程中,攻击者通过拦截、篡改或重定向数据流量的方式,来获取未经授权的数据或对通信内容进行篡改。流量劫持可以发生在多个层级,包括 DNS 劫持、HTTP 劫持、HTTPS 劫持等。
流量劫持的常见应用场景
从网上看到大多数关于流量劫持都是和攻击相关,各种恶意软件、木马等等。但是流量劫持不仅仅是攻击手段,在某些合法业务场景中也会应用到流量劫持技术。如:
-
广告注入:一些 ISP 或公共 Wi-Fi 提供商可能会劫持 HTTP 流量,插入广告内容。 -
内容过滤:主要是针对教育行业或者传统企业,使用流量劫持来过滤不良内容或限制访问某些网站。 -
监控:这种在实际使用中最为常见,使用流量劫持技术进行网络流量的监控、分析。 -
负载均衡:即在负载均衡器中劫持流量,将请求分配到不同的服务器以均衡负载。
前后端的流量劫持差异
| 前端 | 后端 | |
|---|---|---|
| 劫持方式 | dns 劫持、http 劫持、浏览器扩展劫持 | 中间人攻击、API 劫持、内部网络劫持 |
| 主要影响 | 广告植入、窃取敏感信息、页面重定向 | 篡改数据、中断服务 |
下面笔者先基于项目中的情况从前台的视角给出一种解决思路,然后再衍生到后台服务以及 mesh,阐述流量劫持的基本实现逻辑。
从前台视角的方案设计
❝
目的:摆脱框架与三方库的限制,在客户端请求发起之前拦截请求,在服务端响应之后拦截响应,对拦截数据进行特殊处理后再发起请求或返回。
❞
生命周期
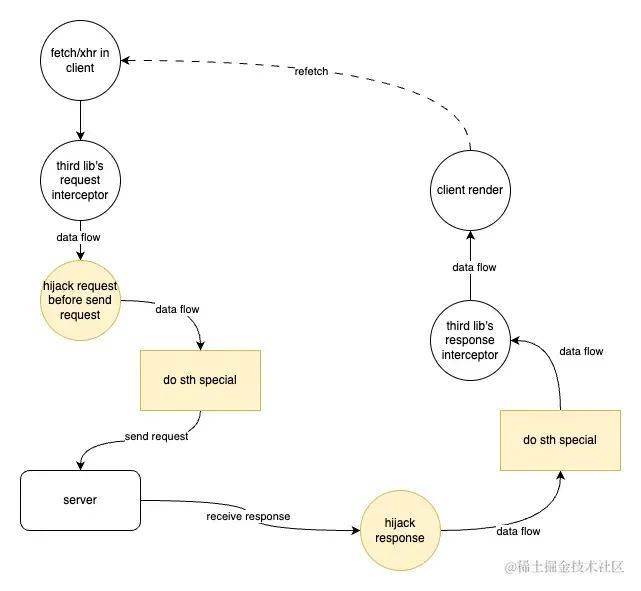
-
fetch/xhrin client:从客户端发起请求 -
third lib's request interceptor: 使用过axios的开发者都知道,axios本身提供了request interceptor和response interceptor,用于在请求发出之前和响应吐出给客户端之前做处理。针对axios或其他三方库,在真正发起请求之前的interceptor我们是拦截不到的。 -
hijack request before send request: 当客户端真正发起请求后,对请求进行劫持,捕获请求参数,并做特定修改后,重新发起请求 -
hijack response: 服务端返回响应后立即进行拦截,并对响应数据做特定修改后,返回数据流 -
third lib's response interceptor: 如前文所述,此时三方请求库会得到处理后的响应数据并展示在客户端。 -
client render: 客户端渲染后,后续若再次发起请求,则流程重新执行。
实现
这里统一使用Proxy来进行对象的代理。
fetch请求拦截
核心原理:复写apply来实现fetch 的拦截,如下代码所示。
constorigin_fetch=window.fetch
consthandler={
apply(target:any,thisArg:any,arrArray:any){
const[request,init]=arrArray;
//hijackrequest
//code...
constnewRequest=newRequest(request.url,{
...request,
method:request.method,
headers:request.header,
body:request.body
})
returnorigin_fetch(newRequest,init).then((response)=>{
//hijackresponse
//code...
returnresponse
})
}
}
window.fetch=newProxy(origin_fetch,handler)
-
通过
arrArray获取请求入参包括Request对象和RequestInit对象 -
-
从MDN中可以得到
Reqeust对象的具体解释传送门(https://developer.mozilla.org/en-US/docs/Web/API/Request) -
关于请求基本信息:我们可以从
request中获取到包括header/method/url等基础请求信息,并对其进行针对性处理。如下代码所示//code..
//获取请求头
//可以通过插件或其他注入形式,在此阶段对requestheader做特殊出炉
constheader:Record<string,string>={}
request.headers.forEach((v:string,k:string)=>{
header[k]=v
})
//拦截注入header头
header['xxx']='bbbb'
//获取请求方法
constmethod=request.method
constnewRequest=newRequest(request.url,{
...request,
method:method,
headers:header,//注入到新的Request中
body:request.body
})
//发起新的请求
//code.. -
关于
request.body。当请求方法如post等时,某些三方库(如axios)有时会将request.body在请求组装阶段,就将其转化为ReadableStream对象。如果直接在new Request时将body对象赋值为request.body,会输出如下错误。关于ReadableStream请看下方ReadableStreamconstnewRequest=newRequest(request.url,{
...request,
method:method,
headers:header,
body:request.body//这里就会报错
})TypeError:Failedtoconstruct'Request':The`duplex`membermustbespecifiedforarequestwithastreamingbody此时你需要将
ReadableStream重新读取并二次转化(如Blob对象)后,塞入到body中进行请求。constread_stream=async(stream:ReadableStream):Promise<Blob>=>{
constchunks=[]
//获取reader
constreader=stream.getReader()
letdone,value
//读取流
while((({done,value}=awaitreader.read()),!done)){
chunks.push(value)
}
//重新转化为Blob
constblob=newBlob(chunks)
returnblob
}
//code...
constbody=awaitread_stream(request.body)
constnewRequest=newRequest(request.url,{
...request,
method:method,
headers:header,//注入到新的Request中
body
})
//发起新的请求
//code... -
关于
response。当服务器返回响应后,可以对响应信息做处理。如判断是否是指定status,并做相对应的拦截处理。操作结束后返回new Response对象,供下游读取。constheader:Record<string,string>={}
response.headers.forEach((v:string,k:string)=>{
header[k]=v
})
//响应头中塞入新的数据
header['xxx']='xxx'
returnnewReponse(response.body,{
...response,
status:200,//可以按需在拦截中,配置status。这个xhr是没有的。
headers:header//可以按需在拦截中,塞入新的响应头
}) -
以上是
fetch拦截的基本思路。详细代码请点击查看(https://github.com/SecretCastle/hijack_request/blob/master/src/core/fetch_hijack.ts)
-
xhr请求拦截
核心原理:通过复写XMLHttpRequest的构造函数,并复写open和send来实现拦截,如下方代码所示。
constorigin_xhr=window.XMLHttpRequest
consthandler={
construct(target,...args){
constxhr=newtarget(...args)
constorigin_open=xhr.open
xhr.open=function(){
returnorigin_open.apply(this,arguments)
}
constorigin_send=xhr.send;
xhr.send=function(){
//hijackrequest
//codehere
//请求发起前,请求拦截中为header注入数据
this.setRequestHeader('xx','xxx')
//代理readystatechange
this.addEventListener('readystatechange',()=>{
if(this.readyState===XMLHttpRequest.Done){
//hijackresponse
//codehere
}
})
returnorigin.apply(this,arguments)
}
returnxhr
}
}
window.XMLHttpRequest=newProxy(origin_xhr,handler)
-
open:xhr对象下用于创建请求的函数,它包含两个参数url和method。这里可以将其作为临时请求信息进行暂存xhr.open=function(method,url){
this.url=url
this.method=method
returnorigin_open.apply(this,arguments)
} -
setRequestHeader: 可在send之前向请求头中注入特定拦截信息。 -
send:xhr对象用于向服务器发送请求的函数, 它的参数为body。 -
readystatechange: 用于监听readyState的变化,从而判断响应是否返回。可根据响应信息做拦截处理。但是这里响应流会继续向下流转,所以xhr中的响应拦截,仅仅可在业务获取信息之前做拦截处理,但并不难阻止业务内部的异常捕获 -
归根结底:个人认为
XMLHttpRequest就是一个状态机,我们只可以被动的获取状态机吐出来的属性数据,而无法对其修改,如status -
以上是
xhr拦截的基本思路,详细代码请点击查看(https://github.com/SecretCastle/hijack_request/blob/master/src/core/xhr_hijack.ts)
❝
示例代码:https://github.com/SecretCastle/hijack_request
❞
延伸思考与学习
ReadableStream
上文中可以看到,当使用fetch进行请求时,某些三方库(如axios)会将body转化为ReadableStream来塞入Request中进行传输。基于此,来尝试简单探究下ReadableStrea。
概念
ReadableStream 是 Web Streams API 的一部分用于表示一个可读的流数据源。它允许你从数据源中逐块读取数据,而不需要一次性加载所有数据到内存中。它可用于处理日常开发过程中遇到的各种类型的数据流,如网络数据流、文件读取、音视频流等。
使用场景与示例
使用场景
-
「网络请求响应」:处理大型或实时数据响应,如文件下载、流媒体。
-
「文件处理」:逐块读取大型文件,避免一次性加载到内存中。
-
「音视频处理」:处理音视频流,实现实时播放和处理。
示例
下面简单介绍文件下载与上传的实现方案与示例:
「文件下载」
通常针对小文件而言,我们可以根据请求返回的blob与URL.createObjectUrl来实现文件下载与保存至本地,如下方的代码片段。
asyncfunctiondownload_file(url){
constres=awaitfetch(url)
constblob=res.blob();
consturl=URL.createObjectURL(blob)
consta_tag=document.createElement('a')
a_tag.href=url
a_tag.download='xxxx.xxx'
a_tag.click();
URL.revokeObjectURL(url)
}
以上有如下优缺点
优点:
-
利用现代 Fetch API 和 Blob 对象。
缺点:
-
不适合非常大的文件,整个文件需要先下载到内存中,然后再创建 Blob,可能会导致内存溢出。
解决方式:
我们可以使用ReadableStream来对下载的文件流进行处理,支持大文件下载,逐块处理数据,避免一次性加载整个文件到内存。
asyncfunctiondownload_file(url){
constres=awaitfetch(url)
constreader=res.body.getReader()
conststream=newReadableStream({
start(controller){
functionpush(){
reader.read().then(({done,value})=>{
if(done){
controller.close()
return
}
//这里还可以增加下载进度的示例
controller.enqueue(value)
push()
})
}
push()
}
})
constresponse=newResponse(stream)
//会须根据response做处理
returnresponse
}
以上有如下优缺点
优点:
-
支持大文件下载,逐块处理数据,避免一次性加载整个文件到内存。
缺点:
「文件上传」
文件上传,在日常的开发过程中,前端常会以FormData形式向服务端发送数据。服务端触发上传调用后,会接收前端传递过来的文件二进制流并保存文件。
然而,除了FormData形式,我们也可以通过ReadableStream流来完成文件的上传。它优点在于可以帮助我们实时的获取数据读取进度并显示“实时”上传进度(这里的实时并不是真正的从前端传递给服务端的实时进度),同时减少文件上传时的内存占用。当然服务端可能或多或少也需要同步改造。
「FormData形式上传」
//从input中获取选择上传的文件
constfile=event.target.files[0]
constformData=newFormData()
formData.append("file",File)
//触发上传请求
constres=fetch(url,{method:'POST',body:formData})
上传时,我们只需要在获取到file对象后,塞入到FormData中,调用上传接口,传递文件二进制数据即可。
「ReadableStream流形式上传」
constfile=event.target.files[0]
conststream=newReadableStream({
start(controller){
constreader=file.stream()?.getReader()
constpush=async()=>{
const{done,value}=awaitreader.read()
if(done){
controller.close()
return
}
controller.enqueue(value)
//上传进度“实时”展示
progressBar.value=(uploadedSize/totalSize)*100
awaitpush()
}
push()
}
})
constheader=newHeader()
header.append("Content-Type","application/octet-stream")
fetch(url,{
method:'POST',
headers,
body:stream,
duplex:"half"//半双工
})
以上,客户端在读取了文件流后,会调用fetch且body携带stream进行上传。
❝
duplex: 'half'请查看传送门(https://developer.chrome.com/docs/capabilities/web-apis/fetch-streaming-requests?hl=zh-cn#half_duplex)❞
上面说,如果使用ReadableStream来进行上传到话,服务端也需要进行相应的改造。服务端框架不同改造点也可能不同,大致包含如下内容:
因为如果使用http/1.1协议,那么可能存在部分请求头或响应头不兼容的问题,从而导致客户端在发起请求时被拒绝。例如当使用node + express作为服务端来接收ReadableStream流时出现的问题。以Node为例,此时需要使用三方库来兼容http2,并且需要在配置时指定证书,如下方代码所示。有兴趣请点击传送门查看。
constspdy=require('spdy');
spdy.createServer(
{
key:fs.readFileSync(
path.join(__dirname,"path/to/your/<hostname>-key.pem"),
),
cert:fs.readFileSync(path.join(__dirname,"certs","path/to/your/<hostname>.pem")),
},
app,
).listen(PORT,()=>{
console.log(`Serverisrunningonhttp://localhost:${PORT}`)
})
❝
不论是
FormData形式,还是ReadableStream形式,最终上传都是需要一次性调用接口并传递文件数据给服务端。如果如果需要更细致的优化,服务端支持采用分片上传形式是其中的一种方案,当然也可以采用
websocket来实现实时推数据来实现上传能力,这取决于具体的业务场景。❞
「最后」
如上阐述的上传与下载的方式,如果读过axios源码的开发者可能会很熟悉,我们常用的axios三方库在请求配置中包含如下的配置:
{
onDownloadProgress:function(progressEvent){
//处理原生进度事件
}
onUploadProgress:function(progressEvent){
//处理原生进度事件
}
}
它们的底层实质就是通过对文件流的读取,从而实现文件上传或下载的实时进度的实现。核心代码如下。
returnnewReadableStream({
//将迭代器转化为可读流
asyncpull(controller){
try{
const{done,value}=awaititerator.next();
//读取完成后,退出
if(done){
_onFinish();
controller.close();
return;
}
letlen=value.byteLength;
//实时进度核心逻辑
if(onProgress){
//通过计算每一个processchunk的大小来实现实时进度的计算
letloadedBytes=bytes+=len;
onProgress(loadedBytes);
}
controller.enqueue(newUint8Array(value));
}catch(err){
_onFinish(err);
throwerr;
}
},
cancel(reason){
_onFinish(reason);
returniterator.return();
}
},{
highWaterMark:2
})
有兴趣可点击查看传送门(https://github.com/axios/axios/blob/c6cce43cd94489f655f4488c5a50ecaf781c94f2/lib/helpers/trackStream.js#L26)
❝
示例代码:https://github.com/SecretCastle/explore_stream
❞
后端服务中的请求拦截
针对后端服务来说,实现请求拦截主要包括以下几种方式
-
对于基于 servlet 容器来说,通过扩展 filter 接口实现
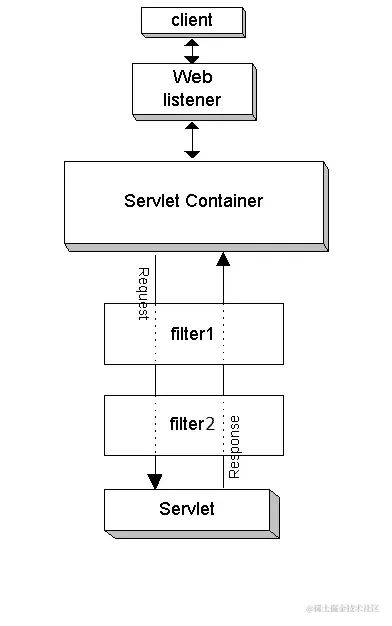
-
针对 spring 应用来说,可以通过 aop 实现 -
普通 java 应用来说,可以通过 agent 实现
不管是哪种方式,基本思路都是要实现对于实际请求的拦截、包装、记录和转发。自顶向下来看,从应用层、框架层、jvm 层、运行时容器层、系统调用层、网络协议层均能实现上述目标。这里笔者不再针对后端的具体实现进行讨论,仅抛出基本的实现思路。
mesh 中的请求拦截
前端后端的流量劫持本质上没有脱离出应用代码本身,不管是侵入性强还是弱,劫持代码都是和业务代码一并交付的。云原生场景下,service mesh 提供了独立于应用本身的实现方式。Service Mesh 发展中核心就是不断对Sidecar 模式配备更加完善的流量管理解决方案,虽然 Sidecar 本身对于业务应用来说是透明的,但是其实现流程管理的最关键步骤就是通过 sidecar 进行流量劫持。mesh 中最常见的流量劫持方式是通过 iptables 实现的,以 istio 为例,下图展示了istio透明流量劫持的大体逻辑:
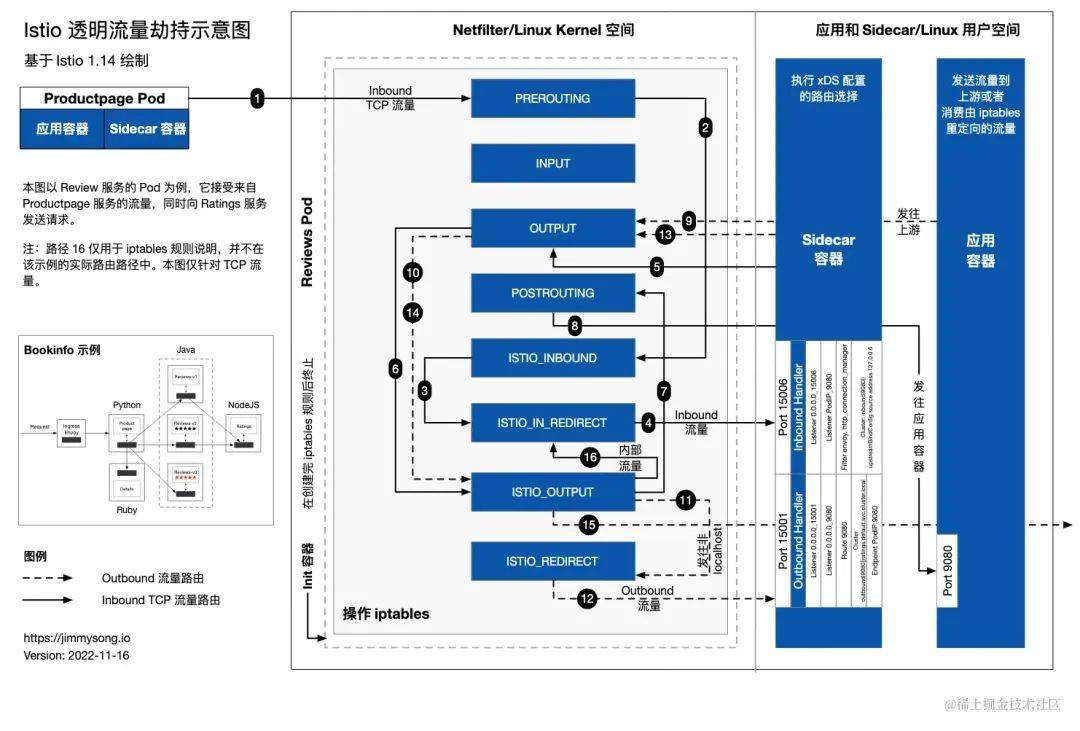
iptables 通过 NAT 表的 redirect 动作执行流量重定向,通过 syn 包触发新建 nefilter 层的连接,后续报文到来时查找连接转换目的地址与端口。新建连接时同时会记录下原始目的地址,应用程序可以通过(SOL_IP、SO_ORIGINAL_DST)获取到真实的目的地址,iptables 做流量劫持可以简化为下图来理解:
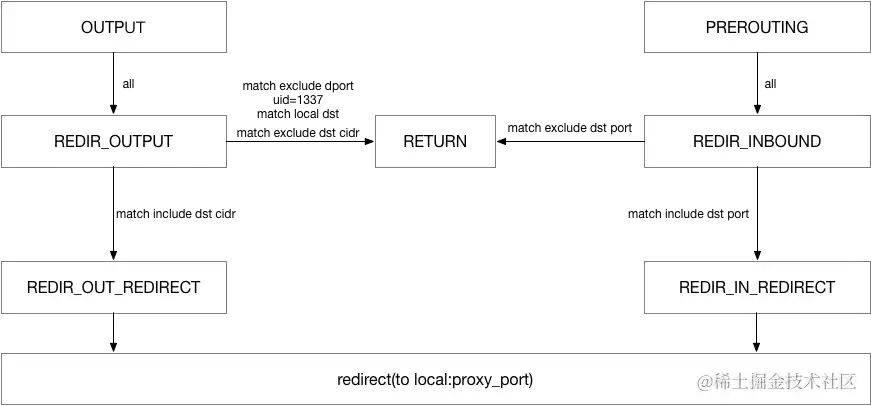
总结
本篇从一个实际项目问题作为切入点,主要探讨了关于流量劫持的一些基本问题,包括从前后端的视角、流量劫持场景以及实现方式上对流量劫持技术进行了简单的介绍。期望通过此篇文章,读者可以从更加宽泛的视角理解流量劫持,以及依据文中针对不同场景介绍的几种实现思路来实现具体应用中的场景。
参考
-
Istio 中的 Sidecar 注入、透明流量劫持及流量路由过程详解 -
https://mosn.io/docs/products/structure/traffic-hijack/