
包阅导读总结
1. 关键词:CrowdStrike、Outage、Configuration、Feature Flags、Prevention
2. 总结:本文探讨了 CrowdStrike 导致的全球大规模软件更新 outage 事件,分析了原因,从配置管理最佳实践角度提出预防类似事件的措施,包括测试、部署和增强弹性等,还探讨了 feature flags 在此事件中的作用及局限性。
3. 主要内容:
– CrowdStrike 软件更新导致大规模 outage
– 影响众多关键业务和社会服务
– 原因是配置变更触发未测试代码路径
– 配置一次性推送且检测和回滚耗时
– 预防类似事件的方法
– 测试与验证
– 配置要有模式和验证
– 检测逻辑错误
– 测试配置与生产代码
– 部署
– 内部测试
– 分阶段逐步部署
– 保证各阶段“烘焙”时间
– 有回滚机制
– 提高弹性
– 如使用 eBPF 交付更新
– 实施“配置隔离”
– Feature Flags 能否预防该 outage
– 虽能帮助但不够,因规模和复杂性
– 需与监控、CD 管道集成等
– 复杂配置需模式支持和提前纠错
– 应将配置视为代码一部分严格对待
思维导图: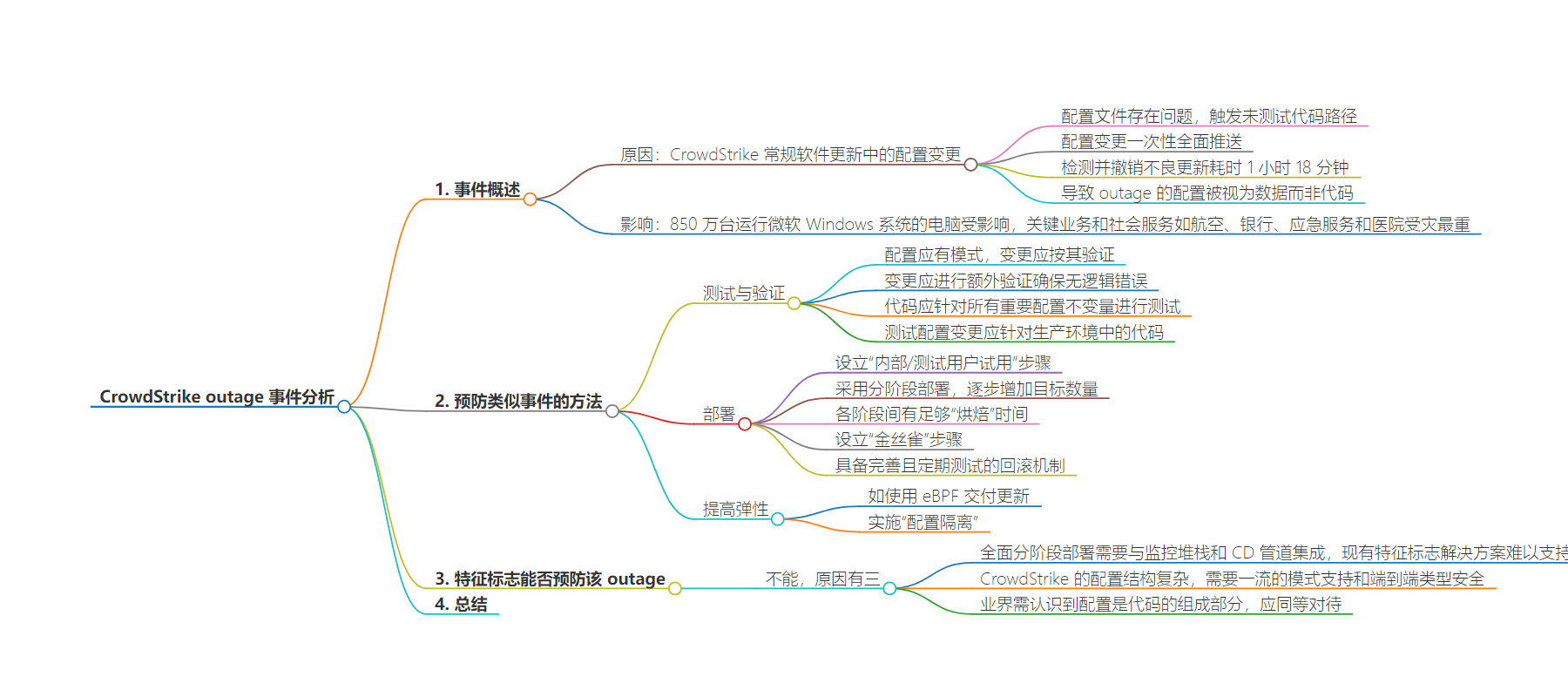
文章地址:https://thenewstack.io/feature-flags-wouldnt-have-prevented-the-crowdstrike-outage/
文章来源:thenewstack.io
作者:Sergey Passichenko
发布时间:2024/8/13 21:48
语言:英文
总字数:1187字
预计阅读时间:5分钟
评分:89分
标签:配置管理,软件故障,最佳实践,测试和验证,分阶段部署
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
On July 19, the world turned blue, or at least 8.5 million computers running the Microsoft Windows operating system. This was the largest global outage ever caused by software. Critical businesses and social services were affected the most: airlines, banks, emergency services and hospitals.
The cause was a routine software update by cybersecurity company CrowdStrike, a market leader in endpoint security — an advanced antivirus that protects devices from network-related attacks. Such software usually runs as a kernel driver to get the necessary access. But when a kernel driver crashes, it crashes the whole operating system, and the computer has to restart. If the failure persists at reboot, the operating system can’t start and the computer is stuck in a broken state. This is what happened with the CrowdStrike update.
In this article, we will examine the publicly available technical details of the incident and analyze them from the configuration management best practices perspective.
What Happened?
- A configuration change caused the outage: The configuration files mentioned above are referred to as “Channel Files” and are part of the behavioral protection mechanisms used by the Falcon sensor.
- Config was either malformed or invalid and triggered an untested code path: Channel File 291 contained problematic content, which caused affected Windows systems to crash due to an out-of-bounds memory read.
- CrowdStrike has a comprehensive release process for the sensor (software that runs on every computer), but it uses a separate delivery method for configuration (Channel Files): Updates to Channel Files are a normal part of the sensor’s operation and occur several times daily in response to novel tactics, techniques and procedures discovered by CrowdStrike.
- Config change was pushed everywhere at once: CrowdStrike didn’t share details about its configuration deployment process, but based on the follow-ups, it wasn’t gradual.
- It took one hour and 18 minutes to detect and revert the bad update.
- Configuration that caused the outage is considered as data, not code. This Rapid Response Content is stored in a proprietary binary file that contains configuration data. It is not code or a kernel driver.
What Can Prevent Similar Events?
Configs are code that is updated more frequently and deployed faster; you have to be more careful with them, not less
Let’s start with the obvious but frequently forgotten fact: configs are not content; configs are code. Config changes are code changes; you should use the same principles when testing and releasing them. Since config updates happen more frequently and can be deployed to production quickly, you have to be even more careful with them than with code updates.
So, how can we protect ourselves from bad config updates?
Testing and Validation
The idea is to detect bad changes while they are being made (either during local testing or on CI).
- Configs should have a schema, and any change should be validated against it. Schema definition and serialization format should support enforcing backward-compatible changes (for example, protobuf).
- Any change should undergo additional validation to ensure no logical errors in the configuration. For example, certain fields are required only for specific rule types, or the data size limit should be less than 4MB for a business rule.
- Code should be tested with all (or at least all important) config invariants to ensure that config changes can’t trigger a logical error in the code. Property-based testing and fuzzing could be used for that.
- Test config changes against code that is deployed in production.
Deploy
No reasonable amount of testing can catch all bugs because production is always different and more diverse than even the best testing environment. You need to be prepared to catch issues in production and prevent as many of them as possible from becoming major incidents.
- Have a “dogfood” step: let internal/beta users test a new version for some meaningful period.
- Deploy config changes using staged rollout, gradually increasing the number of targets until the change is deployed everywhere.
- Have sufficient “bake” time between stages, so your monitoring has a chance to detect an issue.
- More stages mean slower deployment, but at least one “canary” step can catch most critical bugs.
- Have a well-documented and regularly tested rollback mechanism. Reversing a config change shouldn’t take hours, and this is especially important for critical configs.
Improve Resiliency
Bad config changes could still reach production even if you do the above. Failing fast (and loudly) is the best option for most common use cases: a bad push would be detected and reverted, and everything would recover smoothly. But sometimes, the system can’t recover on its own and can’t bring itself online to receive an update (like the CrowdStrike sensor software!). Critical components must be more resilient and have additional isolation levels in such cases.
For example, the CrowdStrike sensor could use eBPF to deliver updates.
Another option is to implement “config quarantine”:
- A new version of the config is not considered stable unless the component is healthy for a certain period after starting to use it.
- If the config is not stable after a timeout, mark it as “rejected” and stop using it.
- This adds complexity, but it could be the right tradeoff for critical components that can’t go down.
Could Feature Flags Have Prevented the CrowdStrike Outage?
Once it was clear the culprit was a config change, it was suggested that the outage could have been prevented by using feature flags. The reasoning goes that a staged rollout is a solution, and the most common way to do a staged rollout is to use feature flags.
Feature flagging is a valuable technique for decoupling the release of new features from code deployment, and advanced feature flagging tools usually support percentage-based rollouts. For example, you can enable a feature on X% of targets to ensure it works before reaching 100%.
While it’s true that feature flags can help to prevent outages, given the scale and complexity of the CrowdStrike incident, they would not have been sufficient for three reasons.
First, a comprehensive staged rollout requires more than just “gradually enable this flag over the next few days”:
- There has to be an integration with the monitoring stack to perform health checks and stop the rollout if there are problems.
- There has to be a way to integrate with the CD pipeline to reuse the list of targets to roll out to and a list of health checks to track.
Available feature flagging solutions require much work and expertise to support staged rollout at any reasonable scale.
Second, CrowdStrike’s config had a complex structure requiring a “configuration system” and a “content interpreter.” Such configs would benefit from first-class schema support and end-to-end type safety (guaranteeing that any change is compatible with the schema the code expects). It’s also better to catch errors before they make it into production.
Lastly, this outage highlights something the industry needs to realize: configs are not an external system but an integral part of your code that has to be treated with the same rigor and engineering practices. This is why leading technology companies embrace a more comprehensive approach: dynamic configuration.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.