
包阅导读总结
1.
关键词:PyTorch、技术路线图、发展方向、开源库、性能提升
2.
总结:PyTorch团队首次公布技术路线图,披露2024下半年发展方向。涵盖核心库与性能、分布式、相关模块等方面,包括提升性能、支持新技术、优化各模块等,重视团队协作、外部合作及社区互动。
3.
主要内容:
– PyTorch团队首发技术路线图
– 背景:2017年发布,在AI领域广泛应用
– 公布原因:提高透明度
– 路线图内容
– 核心库与核心性能
– 提出实现SOTA性能目标,支持常用开发技术
– 核心库的更新
– 分布式
– 涵盖训练、推理、微调环节
– 支持多种并行模式,与编译器团队合作
– torchune、Torchrec、TorchVision
– torchtune:支持LLM微调,与其他模块合作,加强社区互动
– TorchVision:继续在预处理方向努力
– TorchRec:秋季推出稳定版本
– PyTorch Edge:推出ExecuTorch的Beta版本
– 数据加载:让TorchData库重占主导地位
– 编译器核心及部署:完善对LLM和GenAI的支持,添加可视化功能,建立用户支持团队
思维导图: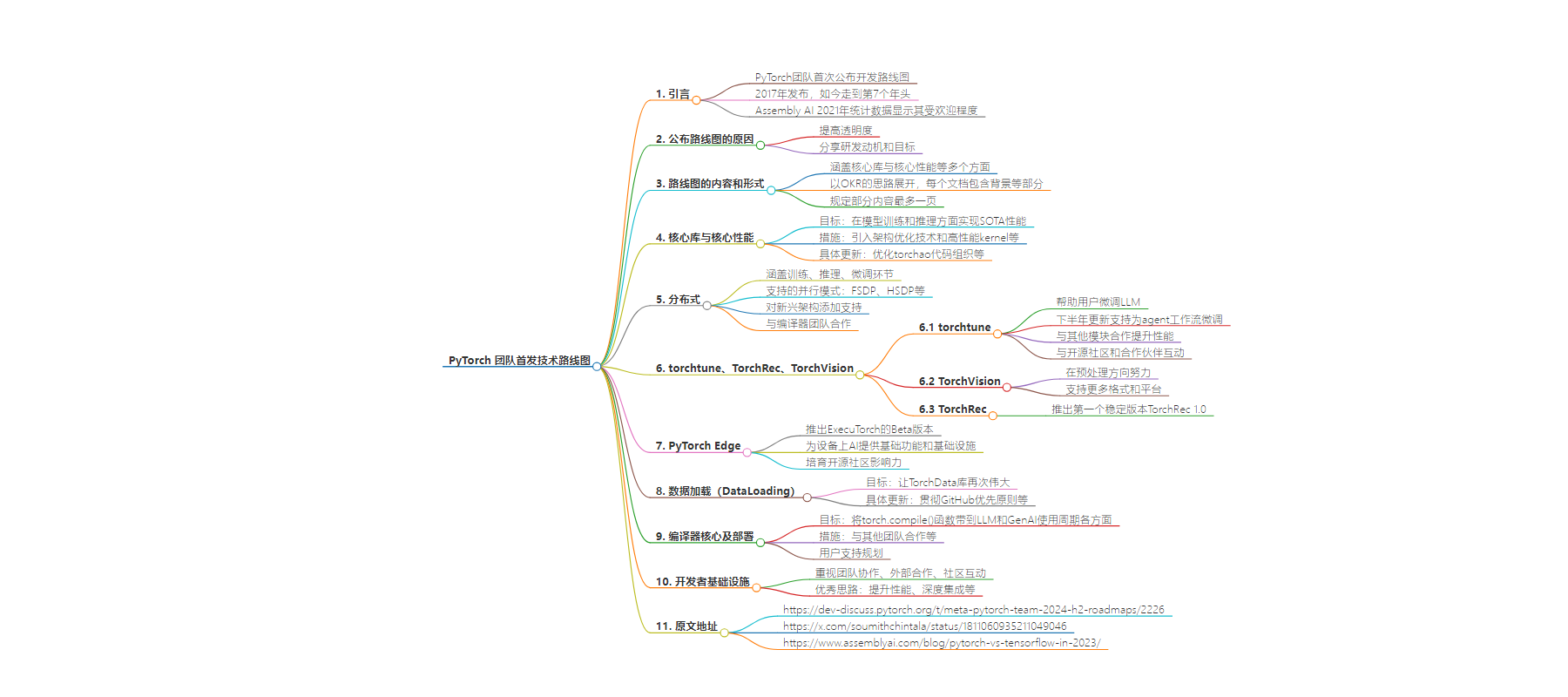
文章地址:https://mp.weixin.qq.com/s/HVI2UfawF9DDmcugHyytDg
文章来源:mp.weixin.qq.com
作者:新智元
发布时间:2024/7/15 5:00
语言:中文
总字数:4476字
预计阅读时间:18分钟
评分:88分
标签:PyTorch,技术路线图,深度学习,Meta AI,开源社区
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
【新智元导读】最近,PyTorch团队首次公布了开发路线图,由内部技术文档直接修改而来,披露了这个经典开源库下一步的发展方向。
如果你在AI领域用Python开发,想必PyTorch一定是你的老朋友之一。2017年,Meta AI发布了这个机器学习和深度学习领域的开源库,如今已经走到了第7个年头。
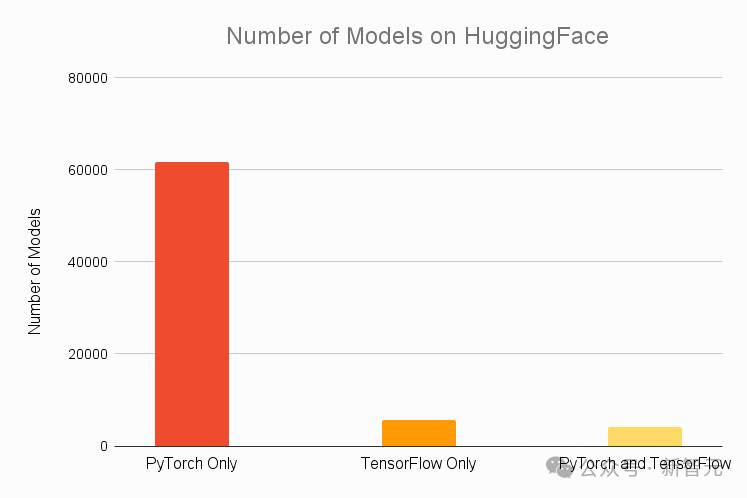
根据Assembly AI 2021年的统计数据,HuggingFace上最受欢迎的top 30模型都能在PyTorch上运行,有92%的模型是PyTorch专有的,这个占比让包括TensorFlow在内的一众竞争对手都望尘莫及。
就在7月10日,PyTorch的工程团队首次公开发布了他们的路线图文档,阐述2024年下半年的发展方向。
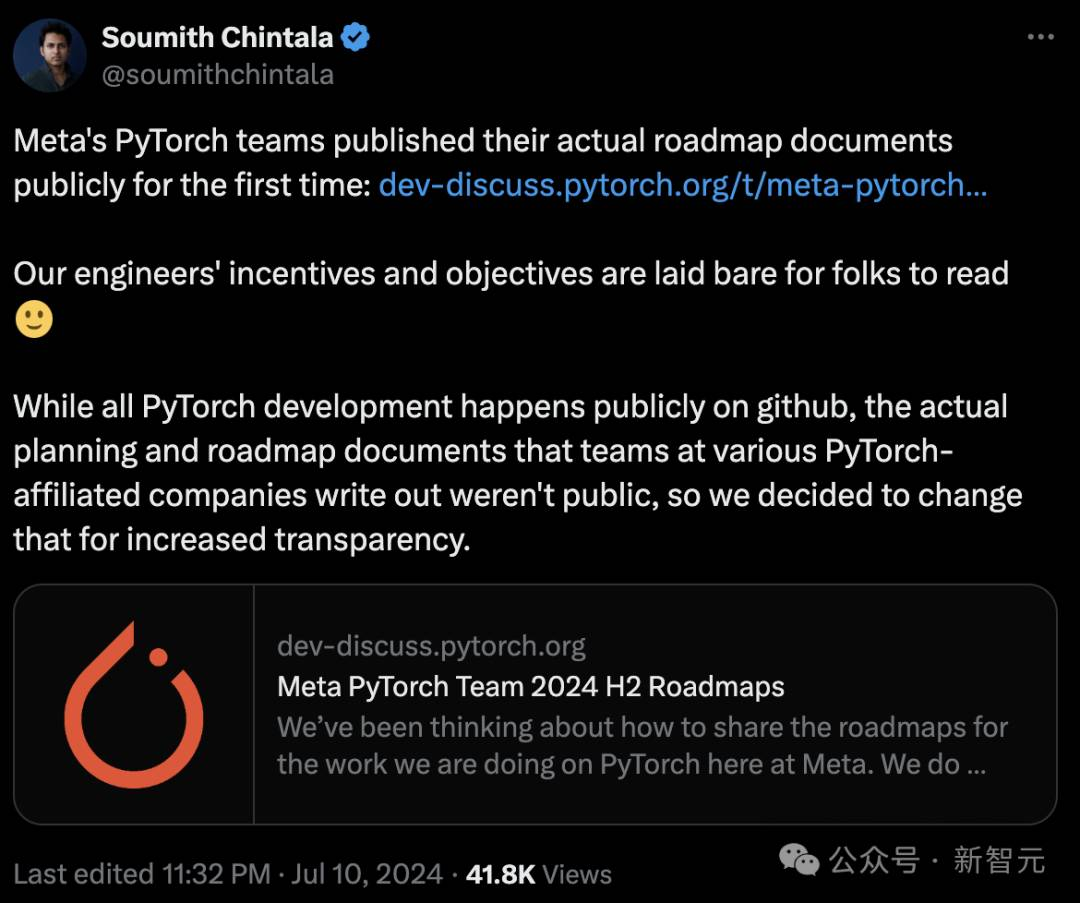
Meta共同创始人、领导PyTorch团队的Soumith Chintala在推特上官宣了这个消息。
他表示,希望公开工程师们的研发动机和目标。
「虽然所有PyTorch开发都在GitHub上公开,但各个PyTorch附属公司的团队编写的实际规划和路线图文档并不公开,因此我们决定做出改变,以提高透明度。」
PyTorch团队的技术项目经理Gott Brath也在论坛中发表了类似的声明。

我们一直在考虑,如何分享团队在PyTorch上所做的工作的路线图。我们每半年进行一次规划,因此这些是我们针对PyTorch中多个关键领域的2024年H2 OSS计划的一些公开版本。
这些文件基本就是PyTorch团队内部的文档和工作规划,删减掉了一些内容就发布出来成为路线图,其中涉及PyTorch的如下几个方面:
– 核心库与核心性能
– 分布式
– torchune、Torchrec、TorchVision
– PyTorch Edge
– 数据加载(DataLoading)
– 编译器核心及部署
– 开发者基础设施
每个文档都至少包含三个部分的内容,以OKR的思路展开:
– 背景
– Top5关注领域及目标:目标、关键结果、已知或未知风险以及相应缓解措施(最多一页)
– 提升工程水平的Top3~5个方面:BE Pillar分类、目标、指标/状态/具体目标、已知或未知风险以及缓解措施、影响/成本、优先级/信心程度(最多一页)
其中BE Pillar可以看作Meta写给开发团队的「五句箴言」,具体内容是:
BetterCode,BetterDoc,Empoweringteams,ModernCode,BetterArchitecture
「最多一页」的规定不知道有没有戳到卷文档长度的开发人员,毕竟文档贵精不贵长,将众多开发需求精简到一页的内容不仅节省同事时间,也十分考验撰写者的功力。
此外,文档中也可以看出Meta开发团队的一些优秀思路,比如重视各个模块团队的协作、重视和外部合作伙伴的API集成和共同开发,重视与开源社区和开发者的互动。
当推出ExecuTorch这样的新代码库,或者想要提升PyTorch编译器影响力时,团队一般都会从两方面思路入手:一是铆足力气提升性能,把目标直接顶到SOTA;另一方面从深度集成入手,提供更多开箱即用的案例。
或许,这些都是Meta多年来在开源领域如鱼得水、风生水起的关键所在。
以下是各个文档内容的部分截取和概括。
文档中涉及到的核心库包括TendorDict、torchao、NN、TorchRL等。
性能方面,PyTorch团队提出了在模型训练和推理方面实现SOTA性能的目标,措施包括引入架构优化技术和高性能kernel,与整个PyTorch技术栈形成搭配组合。
过去一年的时间见证了GenAI的快速发展,许多支持研究领域进行开发的外部库应运而生,但其中很多并不直接依赖PyTorch,这会威胁到PyTorch在科研领域的主导地位。
为了重新跟上节奏,PyTorch将为量化、稀疏化、MoE和低精度训练等常用开发技术提供支持,包括构建模块和API(主要集成在torchao中),帮助各类Transformer架构的模型提升性能。
torchao库可以支持研究人员在PyTorch框架内自定义高性能的dtype、layout和优化技巧,将使用范围扩展到训练、推理、调优等各种场景。
此外,核心库的更新将包括以下方面:
– 推出的自动优化库torchao已经取得了突破性的成功,下一步提升其代码组织性,并将其中的数值运算与核心库分开
– 解决TendorDict的核心模块性,支持加载/存储的序列化,并使其在eager模式下的运行速度提高2倍
– 继续上半年在内存映射加载(memory mapped load)方面的成功,继续提升模型加载/存储的性能和安全性
– 将TorchRL的开销降低50%
– 加入对NoGIL的核心支持
– 修复用户反映的TORCH_env变量不起作用的问题
文档中还提及了要实现对nn.transformer模块的弃用,表示会发布一系列教程和用例,展示如何使用torch.compile、sdpa、NJT、FlexAttention、custom_op、torchao等模块构建Transformer。
LLM的预训练通常横跨数十个甚至上千个GPU,而且由于模型的参数规模逐渐增大,推理和微调也很难用单个GPU完成。
因此,PyTorch下一步对「分布式」的布局全面涵盖了训练、推理、微调这三个环节,提出要达成超大规模分布式训练、高内存效率的微调、多主机分布式推理。
训练
PyTorch原生支持的并行模式主要包括以下几种:
– 完全分片数据并行(full sharded data parallel,FSDP)
– 混合分片数据并行(hybrid sharding data parallel,HSDP)
– 张量并行(tensor parallel,TP)
– 流水线并行(pipeline parallel,PP)
– 序列并行(sequence parallel,SP)
– 上下文并行(context parallel,CP)
PyTorch希望在TorchTitan中将各种并行方式进一步模块化,让开发者可以自由组合,根据需要实现N维并行。

文档中特别提到,对MoE和多模态这两种新兴的架构需要添加支持,比如专家并行、路由算法的优化。
除了TorchTitan本身的更新,分布式团队还需要与编译器团队进一步紧密合作,更好地与torch.compile模块集成,为大规模分布式场景带来额外的性能提升。
微调与推理
微调:联合torchtune,将FSDP2 LoRA/QLoRA方案投入使用,以及支持模型状态字典的NF4量化
推理:PP和DP已经成为分布式API的核心,下一步需要关注torchtitan的分布式推理,支持大模型PP+异步TP方式,将给出案例展示
文档中还提到,会将HuggingFace的推理API从PiPPy迁移到PyTorch(由HuggingFace完成)。
torchtune、TorchRec、TorchVision
torchtune
torchtune的推出旨在帮助用户更方便微调LLM,这也是官方给出的Llama模型微调的方案。
torchtune定义的「微调」范围非常广,主要可以概括为三类场景:
– 对特定领域数据集或者下游任务的模型适应
– 奖励和偏好建模,比如RLHF、DPO等
– 包含蒸馏与量化的训练过程
下半年的更新将支持为agent工作流进行的微调,同时着重关注微调性能的提升。
团队会与compile、core、distributed等模块进行合作,提供高效率微调,并在PyTorch生态内建立有代表性的微调性能基准。
由于torchtune也是一个较新的开源库,因此与开源社区的互动也必不可少。
文档提出发布博客文章和教程、举办技术讲座等方式,提升用户的理解;并会定义量化指标,衡量torchturn在LLM生态中的贡献份额。
除了开源社区,torchtune还会与至少一个合作伙伴集成,参与到它们的社区中,以促进torchtune的使用。
TorchVision
TorchVision作为CV领域内的绝对主宰者,技术也相对成熟,因此路线图中提出的更新很少。
团队将继续在预处理方向努力,在图像编码/解码空间中支持更多格式(如WebP、HEIC)和平台(如CUDA),并提升jpeg格式在GPU上的编码/解码性能。
TorchRec
TorchRec旨在提供大规模推荐系统中常用的稀疏性和并行性原语,将秋季推出第一个稳定版本TorchRec 1.0。
目前,开源库ExecuTorch已经推出了Alpha版本,主要依赖torch.compile和torch.export,用于支持移动设备和边缘设备(如AR/VR、可穿戴设备)上的模型分析、调试和推理。
下半年,Edge团队将推出xecuTorch的Beta版本,同时为Meta的Llama系列模型和其他开源模型提供PyTorch生态内的解决方案。
关键目标中主要涵盖两个方向。一是为设备上AI提供基础功能和可靠基础设施,包括:
– 确保C++和Python的API稳定性
– 实现一系列核心功能:支持模型压缩、代理缓存位置管理、数据和程序分离
二是为这个新生的代码库保驾护航,培育开源社区内的影响力,同时与Arm、Apple 和Qualcomm等公司保持良好合作关系。
其中社区影响力的目标甚至被量化到,要求代码在GitHub上得到3k标星,500次克隆(fork)。有兴趣的吃瓜群众可以去持续关注一下,看看团队能不能在年底完成这个OKR。
基于Apache Arrow格式的HuggingFace datasets库凭借无内存限制的高速加载/存储,近几年异军突起,似乎抢走了PyTorch相关功能的风头。
数据加载的文档中开篇就提出了雄心壮志,要让TorchData库再次伟大,重新确立PyTorch在数据加载方面的主宰地位。
要达到这个目标,就需要让相关功能变得灵活、可扩展、高性能、高内存效率,同时实现傻瓜式操作,支持各种规模的多模态训练。
具体的更新目标包括以下几个方面:
– DataLoader的功能开发和接口都将贯彻GitHub优先的原则,DataPipes和DataLoader v2则将被逐步被弃用、删除
– 确保TorchTune、TorchTitan、HuggingFace、TorchData之间的清晰边界和良好互通性,支持多数据集、多模态数据加载
PyTorch的编译器核心功能经过多年发展已经趋于完善,目前亟待弥补的只是对LLM和GenAI领域的更深度集成和更多优化支持。
路线图提出,要将torch.compile()函数带到LLM和GenAI的使用周期的各个方面(推理、微调、预训练),让重要模型在发行时就搭载原生的PyTorch编译。
为了实现这个目标,文档提出了很多具体措施,比如与torchtune与TorchTitan团队合作,提升编译性能,并在下半年发布至少两个高知名度模型的原生PyTorch编译版本。
此外,编译器可能添加可视化功能,在non-eager训练模式下生成表达前向计算/后向传播过程的模型图。
用户支持方面也有诸多规划,比如提升系统的监控性和可观察性,帮助户自行调试编译问题。关键目标还包括建立用户支持团队,针对几个关键领域(数据类、上下文管理等),解决开发者在GitHub等平台上发布的问题。
https://dev-discuss.pytorch.org/t/meta-pytorch-team-2024-h2-roadmaps/2226
https://x.com/soumithchintala/status/1811060935211049046
https://www.assemblyai.com/blog/pytorch-vs-tensorflow-in-2023/

