
包阅导读总结
1. 关键词:联邦语言模型、云模型、边缘模型、函数映射、响应生成
2. 总结:本文介绍了在联邦语言模型架构上运行代理的方法,包括在 Jetson Orin 上运行 Ollama、运行 MySQL DB 和 Flask API 服务器、索引 PDF 和在 Chroma DB 中摄取嵌入、运行联邦 LM 代理,实现从用户查询到最终响应的流程。
3. 主要内容:
– 联邦语言模型介绍
– 利用云的大语言模型和边缘的小语言模型
– 代理将用户查询和工具发给云模型,生成函数和参数
– 执行函数从数据库生成上下文,或用 RAG 机制在向量库搜索
– 将上下文发给边缘模型生成正确响应给用户
– 实践实现步骤
– 运行 Ollama 在 Jetson Orin 上
– 运行 MySQL DB 和 Flask API 服务器
– 索引 PDF 和在 Chroma DB 中摄取嵌入
– 运行联邦 LM 代理
– 导入暴露工具的 API 客户端
– 初始化云模型和边缘模型
– 让云模型映射提示到函数和参数
– 执行函数生成上下文,或用检索器
– 用边缘模型生成响应,实现代理流程
思维导图: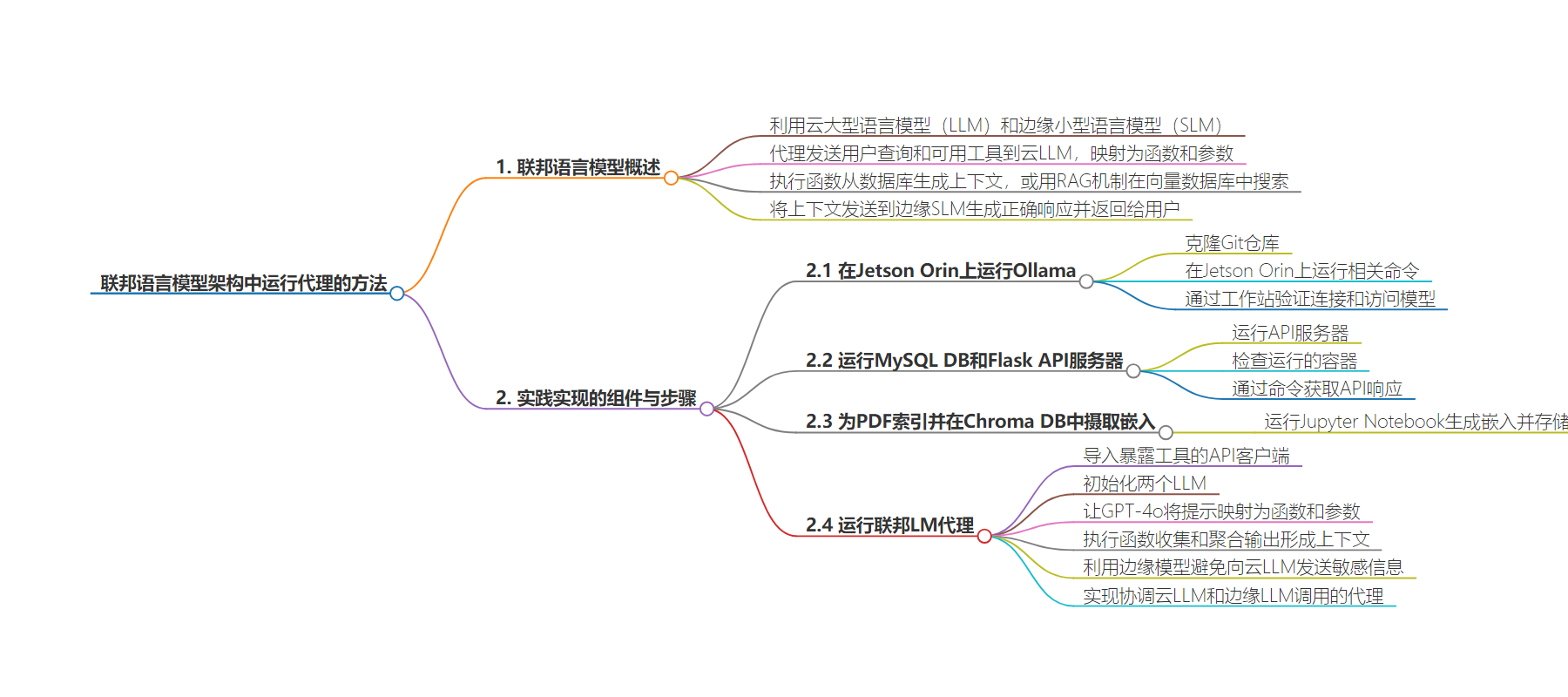
文章地址:https://thenewstack.io/how-to-run-an-agent-on-federated-language-model-architecture/
文章来源:thenewstack.io
作者:Janakiram MSV
发布时间:2024/8/3 3:53
语言:英文
总字数:976字
预计阅读时间:4分钟
评分:87分
标签:联合语言模型,边缘计算,AI代理,OpenAI GPT-4 Omni,微软Phi-3
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
In the first part of this series, I introduced the idea of federated language models, where we take advantage of a capable cloud-based large language model (LLM) and a small language model (SLM) running at the edge.
To recap, an agent sends the user query (1) along with the available tools (2) to a cloud-based LLM to map the prompt into a set of functions and arguments (3). It then executes the functions to generate appropriate context from a database (4a). If there are no tools involved, it leverages the simple RAG mechanism to perform a semantic search in a vector database (4b). The context gathered from either of the sources is then sent (5) to an edge-based SLM to generate a factually correct response. The response (6) generated by the SLM is sent as the final answer (7) to the user query.
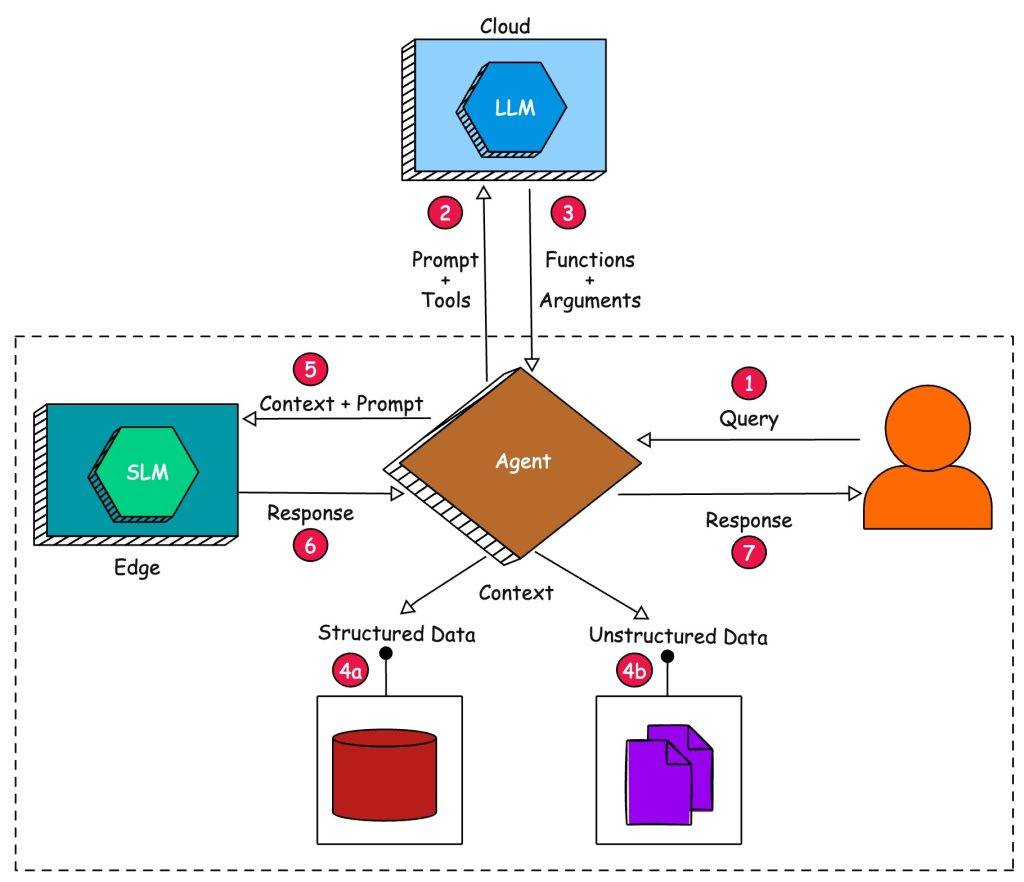
This tutorial focuses on the practical implementation of a federated LM architecture based on the below components:
Refer to the tutorial on setting up Ollama on Jetson Orin and implementing the RAG agent for additional context and details.
Start by cloning the Git repository https://github.com/janakiramm/federated-llm.git, which has the scripts, data, and Jupyter Notebooks. This tutorial assumes that you have access to OpenAI and an Nvidia Jetson Orin device. You can also run Ollama on your local workstation and change the IP address in the code.
Step 1: Run Ollama on Jetson Orin
SSH into Jetson Orin and run the commands mentioned in the file, setup_ollama.sh.
Verify that you are able to connect to and access the model by running the below command on your workstation, where you run Jupyter Notebook.
|
curl http://localhost:11434/v1/chat/completions \ –H “Content-Type: application/json” \ –d ‘{ “model”: “phi3:mini”, “messages”: [ { “role”: “system”, “content”: “You are a helpful assistant.” }, { “role”: “user”, “content”: “What is the capital of France?” } ] }’ |
Replace localhost with the IP address of your Jetson Orin device. If everything goes well, you should be able to get a response from the model.
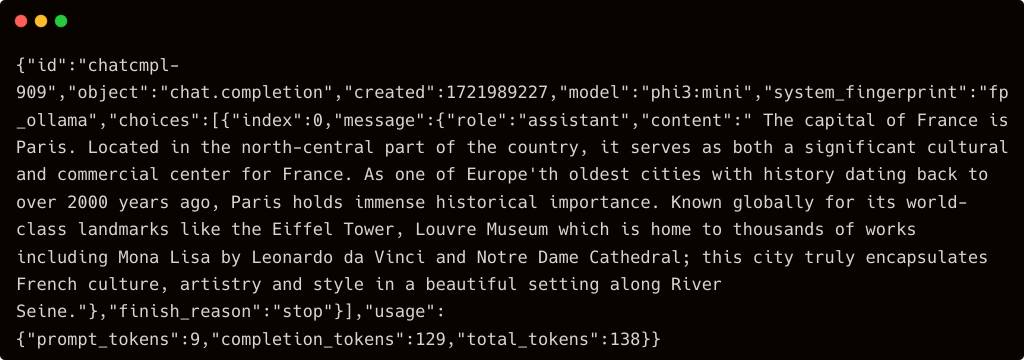
Congratulations, your edge inference server is now ready!
Step 2: Run MySQL DB and Flask API Server
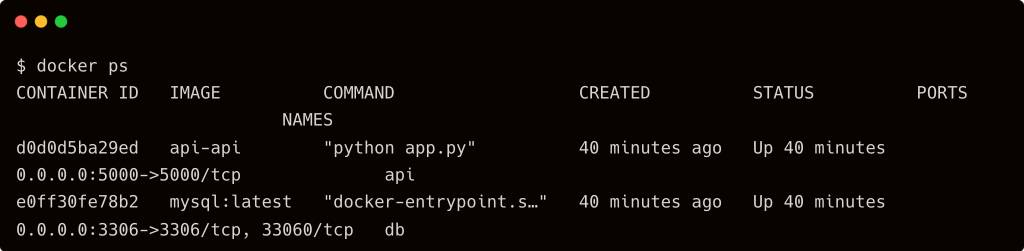
The next step is to run the API server, which exposes a set of functions that will be mapped to the prompt. To make this simple, I built a Docker Compose file that exposes the REST API endpoint for the MySQL database backend.
Switch to the api folder and run the below command:
Check if two containers are running on your workstation with the docker ps command.
If you run the command curl "http://localhost:5000/api/sales/trends?start_date=2023-05-01&end_date=2023-05-30", you should see the response from the API.
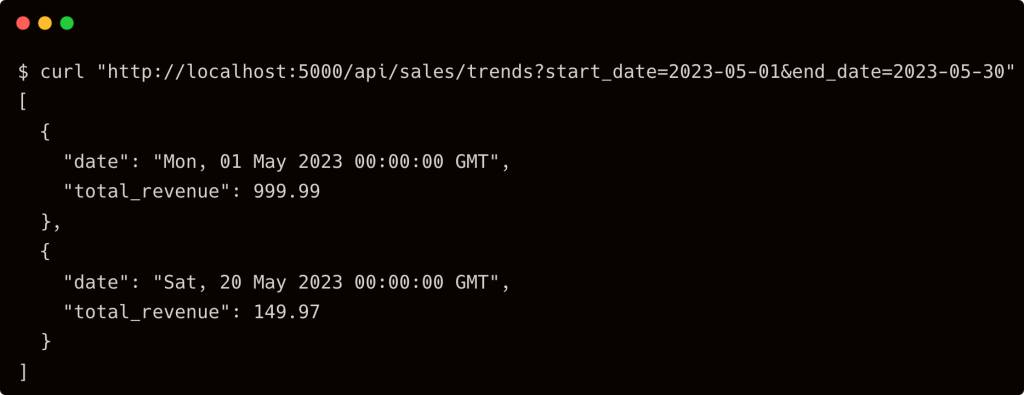
Step 3: Index the PDF and Ingest the Embeddings in Chroma DB
With the API in place, it’s time to generate the embeddings for the datasheet PDF and store them in the vector database.
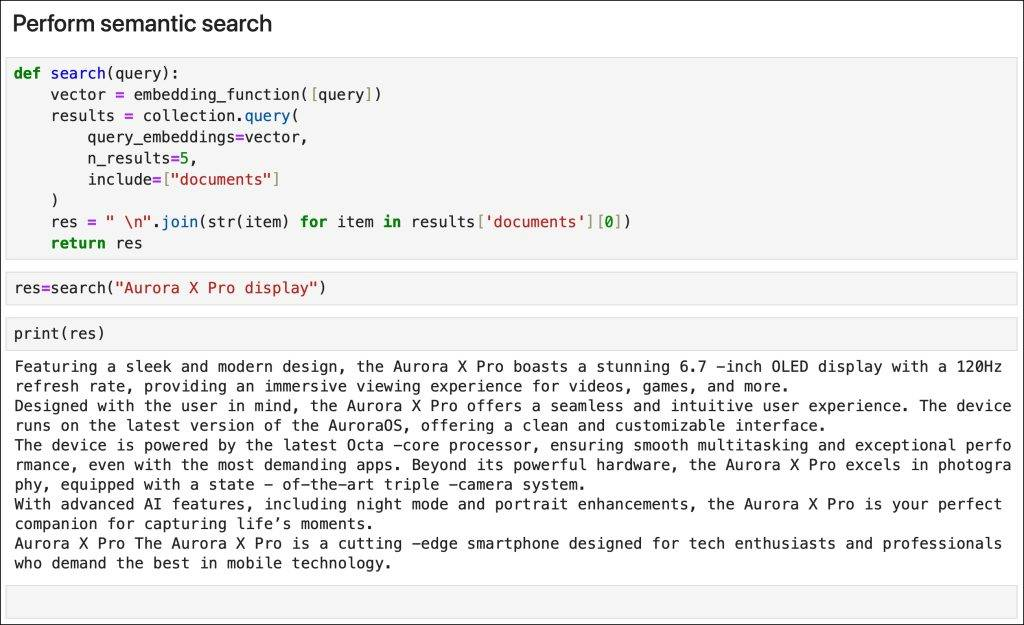
For this, run the Index_Datasheet.ipynb Jupyter Notebook, which is available in the notebooks folder.
A simple search retrieves the phrases that semantically match the query.
Step 4: Run the Federated LM Agent
The Jupyter Notebook, Federated-LM.ipynb, has the complete code to implement the logic. Let’s understand the key sections of the code.
We will import the API client that exposes the tools to the LLM.
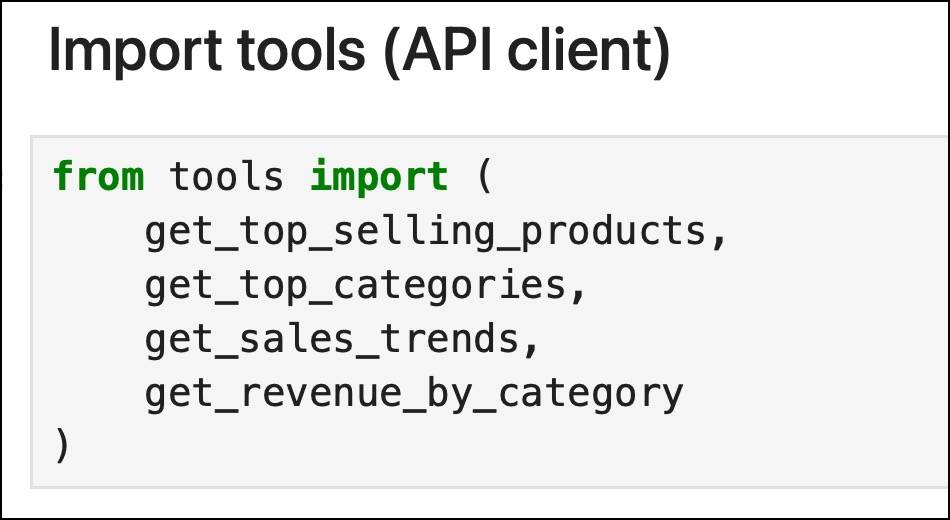
We will import the API client that exposes the tools to the LLM.
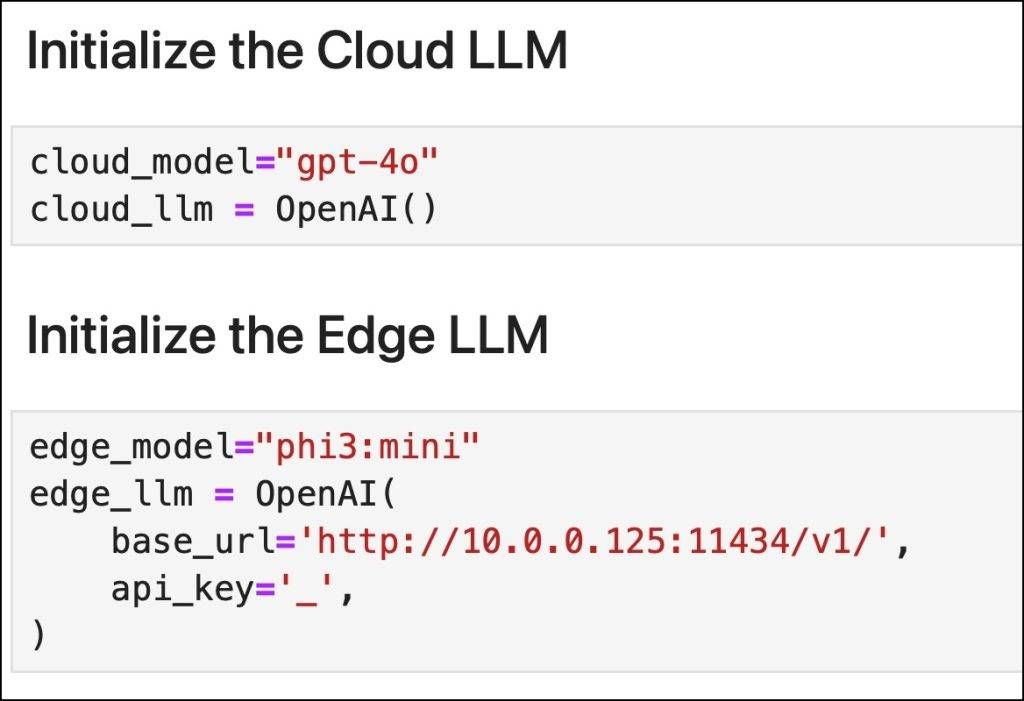
First, we initialize two LLMs: GPT-4o (Cloud) and Phi3:mini (Edge)
After creating a Python list with the signatures of the tools, we will let GPT-4o map the prompt to appropriate functions and their arguments.
For example, passing the prompt What was the top selling product in Q2 based on revenue? to GPT-4o results in the model responding with the function get_top_selling_products and the corresponding arguments. Notice that a capable model is able to translate Q2 into date range, starting from April 1st to June 30th. This is exactly the power we want to exploit from the cloud-based LLM.

Once we enumerate the tool(s) suggested by GPT-4o, we execute, collect, and aggregate the output to form the context.
If the prompt doesn’t translate to tools, we attempt to use the retriever based on the semantic search from the vector database.
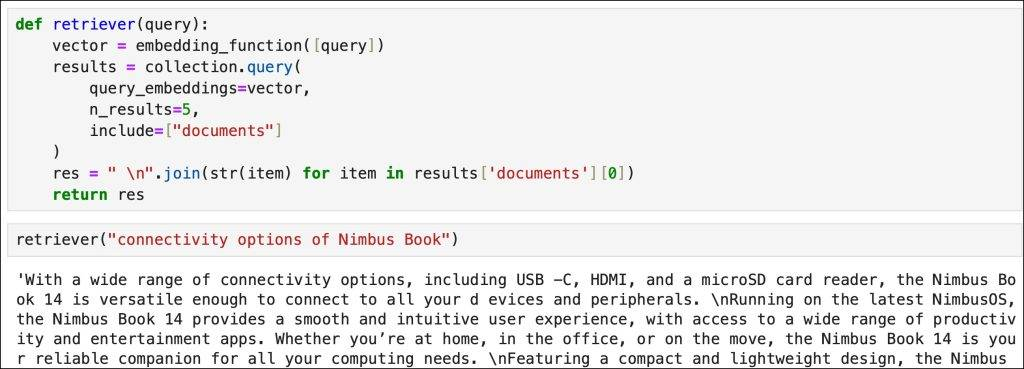
To avoid sending sensitive context to the cloud-based LLM, we leverage the model (edge_llm) at the edge for generation.

Finally, we implement the agent that orchestrates the calls between the cloud-based LLM and the edge-based LLM. It checks if the tools list is empty and then moves to the retriever to generate the context. If both are empty, the agent responds with the phrase “I don’t know.”

Below is the response from the agent based on tools, retriever, and unknown context.
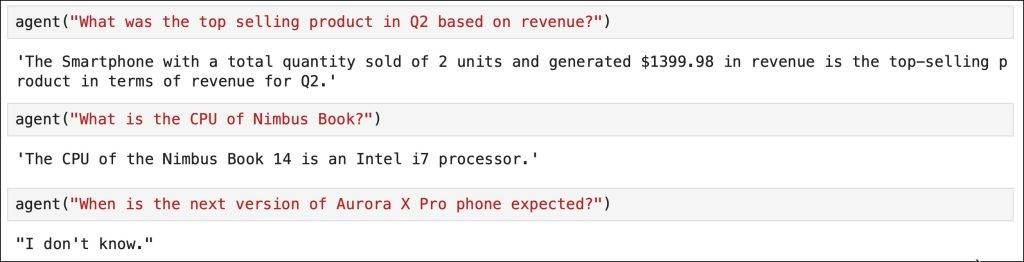
To summarize, we implemented a federated LLM approach where an agent sends the user query along with available tools to a cloud-based LLM, which maps the prompt into functions and arguments. The agent executes these functions to generate context from a database. If no tools are involved, a simple RAG mechanism is used for semantic search in a vector database. The context is then sent to an edge-based SLM to generate a factually correct response, which is provided as the final answer to the user query.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.