
包阅导读总结
1. 关键词:Python、Web Scraper、Beautiful Soup、Requests、数据提取
2. 总结:本文介绍了如何用 Python 构建网络爬虫,阐述了网页抓取的概念及用途,讲解了 Beautiful Soup 和 Python Requests 的协作方式、如何安装所需库,通过示例详细说明了构建爬虫的步骤,包括导入库、定义 URL 和 CSV 头、创建函数提取数据集详情和列表、保存数据到 CSV 等,最后给出完整代码。
3. 主要内容:
– 什么是网页抓取
– 是自动收集大量数据的技术,对多种专业人员有用。
– 所需学习内容
– Python 的 Requests 和 Beautiful Soup 库用于抓取网站。
– 两者结合能获取和解析 HTML 内容提取数据。
– 但有局限性,Requests 不能处理动态 JavaScript 内容网站。
– 如何用 Python 构建网络爬虫
– 前提准备
– 安装 Python 及 Requests 和 Beautiful Soup 库。
– 构建步骤
– 导入必要的库。
– 定义基础 URL 和 CSV 表头。
– 创建函数提取数据集详情。
– 创建函数提取数据集列表。
– 实现页面循环抓取。
– 保存抓取数据到 CSV 文件。
– 运行抓取函数。
– 给出完整代码。
思维导图: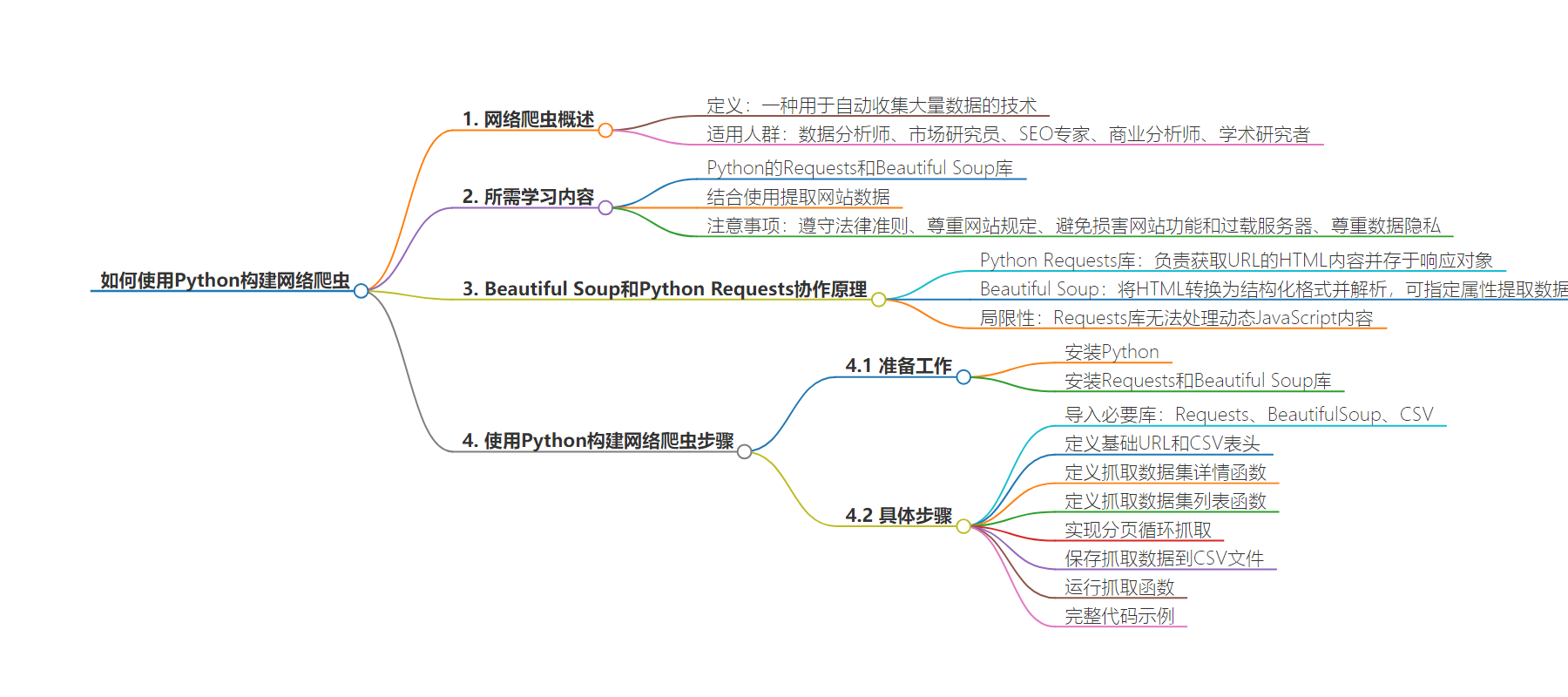
文章地址:https://www.freecodecamp.org/news/use-python-sdk-to-build-a-web-scraper/
文章来源:freecodecamp.org
作者:Jess Wilk
发布时间:2024/7/18 18:40
语言:英文
总字数:1729字
预计阅读时间:7分钟
评分:88分
标签:网页抓取,Python,Requests 库,Beautiful Soup,数据提取
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
What is Web scraping?
Web scraping is a technique used to collect large amounts of data automatically using a programming script. This makes it useful for many professionals such as data analysts, market researchers, SEO specialists, business analysts, and academic researchers.
What You’ll Learn Here
Python provides two libraries, Requests and Beautiful Soup, that help you scrape websites more easily. The combined use of Python’s Requests and Beautiful Soup can retrieve HTML content from a website and then parse it to extract the data you need. In this article, I’ll show you how to use these libraries with an example.
By the end of this guide, you will be equipped to build your own Web Scraper and have a more profound understanding of working with a large amount of data and how to apply it to make data-driven decisions.
Please note that while a web scraper is a useful tool, make sure you’re compliant with all legal guidelines. This involves respecting the website’s robots.txt file and adhering to the terms of service so you avoid unauthorized data extraction.
Also, before scraping, make sure that the scraping process does not harm the website’s functionality or overload its servers. Finally, respect data privacy by not scraping personal or sensitive information without proper consent.
How Beautiful Soup and Python Requests Work Together
Let’s understand the role of each library.
The Python Requests library is responsible for fetching HTML content from the URL you provide in the script. Once it retrieves the content, it stores the data in a response object.
Beautiful Soup then takes over, transforming the raw HTML from the Requests response into a structured format and parsing it. You can then scrape data from the parsed HTML by specifying attributes, allowing you to automate the collection of specific data from websites or repositories.
But this duo has its limitations. The Requests library can’t handle websites with dynamic JavaScript content. So you should use it primarily for sites that serve static content from servers. If you need to scrape a dynamically loaded site, you will have to use more advanced automation tools like Selenium.
How to Build a Web Scraper with Python
Now that we understand what Beautiful Soup and Python Requests can do, let’s discuss how we can scrape data using these tools.
In the following example, we’ll be scraping data from the UC Irvine Machine Learning Repository.
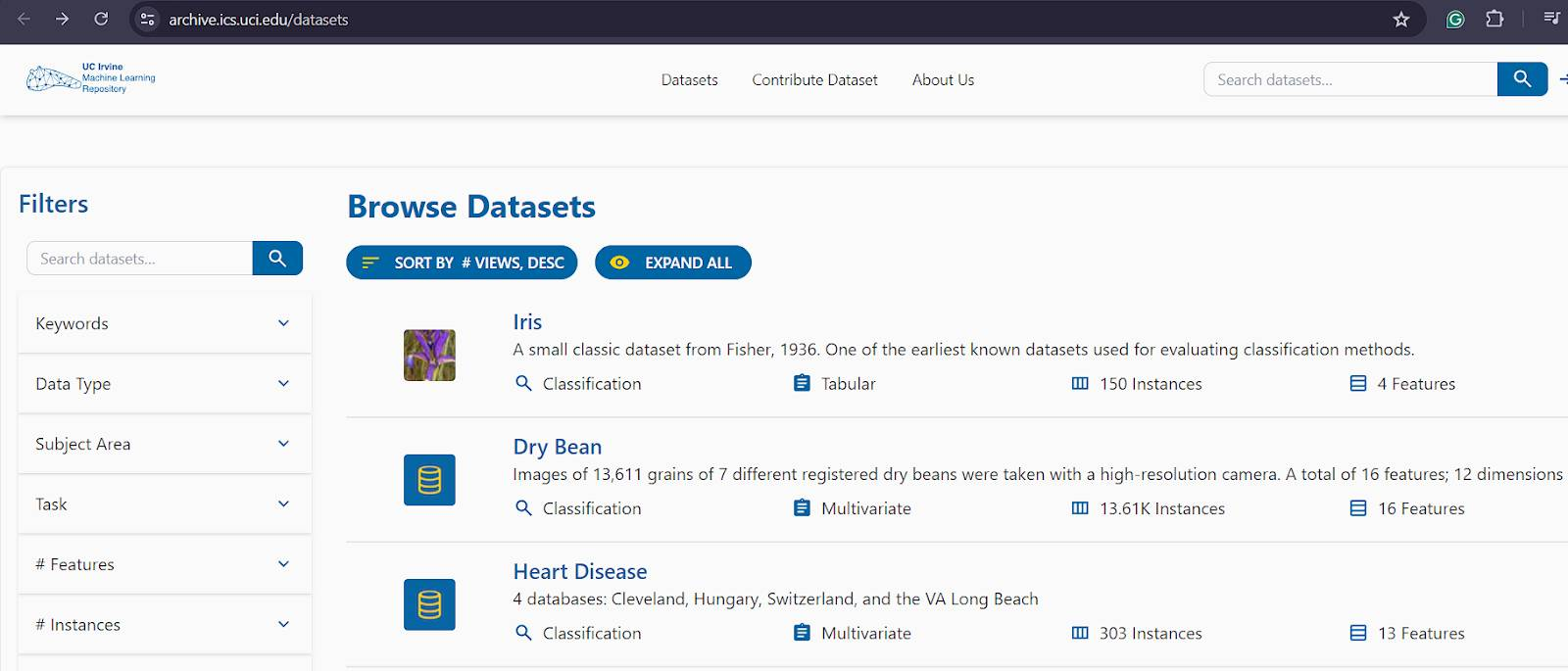
As you can see, it contains many datasets, and you can find further details about each dataset by going to a dedicated page for the dataset. You can access the dedicated page by clicking on the dataset name in the list above.
Check out the image below to get an idea of the information provided for each dataset.
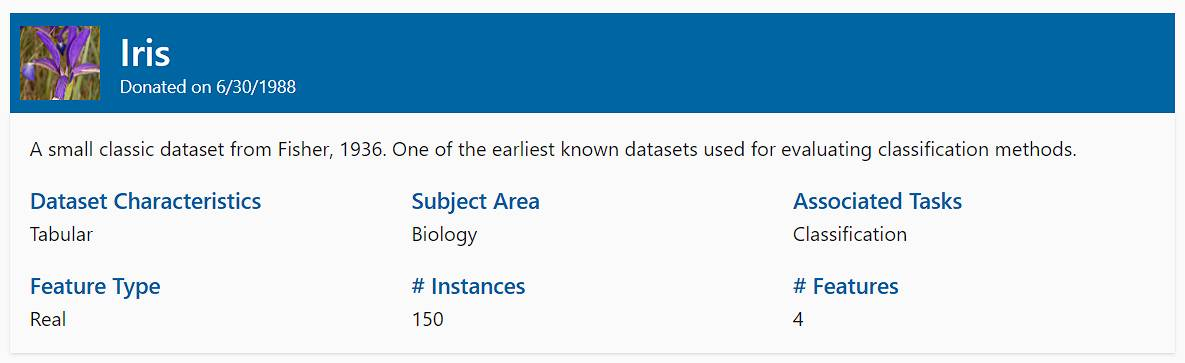
The code we write below will go through each dataset, scrape the details, and save them to a CSV file.
Prerequisites
To try out this tutorial, you need several prerequisites set up.
I am assuming you already have a Python installation on your machine. If not, please download the latest Python from the official website.
The Requests and Beautiful Soup libraries don’t come with Python. You will have to install them separately. For this, you can use the pip package manager which is included by default with Python installation since Python 3.4.
You can use pip to install the Requests and Beautiful Soup libraries using the following commands:
pip install requestspip install beautifulsoup4If they were successfully installed, now you are ready to start coding.
Step 1: Import Necessary Libraries
First, import the necessary libraries: Requests for making HTTP requests, BeautifulSoup for parsing HTML content (if you don’t already have it installed from the previous step), and CSV for saving the data.
import requestsfrom bs4 import BeautifulSoupimport csvStep 2: Define the Base URL and CSV Headers
Set the base URL for the dataset listings and define the headers for the CSV file where the scraped data will be saved.
def scrape_uci_datasets(): base_url = "https://archive.ics.uci.edu/datasets" headers = [ "Dataset Name", "Donated Date", "Description", "Dataset Characteristics", "Subject Area", "Associated Tasks", "Feature Type", "Instances", "Features" ] data = []Step 3: Create a Function to Scrape Dataset Details
Define a function scrape_dataset_details that takes the URL of an individual dataset page, retrieves the HTML content, parses it using BeautifulSoup, and extracts relevant information.
def scrape_dataset_details(dataset_url): response = requests.get(dataset_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_name = soup.find( 'h1', class_='text-3xl font-semibold text-primary-content') dataset_name = dataset_name.text.strip() if dataset_name else "N/A" donated_date = soup.find('h2', class_='text-sm text-primary-content') donated_date = donated_date.text.strip().replace( 'Donated on ', '') if donated_date else "N/A" description = soup.find('p', class_='svelte-17wf9gp') description = description.text.strip() if description else "N/A" details = soup.find_all('div', class_='col-span-4') dataset_characteristics = details[0].find('p').text.strip() if len( details) > 0 else "N/A" subject_area = details[1].find('p').text.strip() if len( details) > 1 else "N/A" associated_tasks = details[2].find('p').text.strip() if len( details) > 2 else "N/A" feature_type = details[3].find('p').text.strip() if len( details) > 3 else "N/A" instances = details[4].find('p').text.strip() if len( details) > 4 else "N/A" features = details[5].find('p').text.strip() if len( details) > 5 else "N/A" return [ dataset_name, donated_date, description, dataset_characteristics, subject_area, associated_tasks, feature_type, instances, features ]The scrape_dataset_details function retrieves the HTML content of a dataset page and parses it using BeautifulSoup. It extracts information by targeting specific HTML elements based on their tags and classes, such as dataset names, donation dates, and descriptions.
The function uses methods like find and find_all to locate these elements and retrieve their text content, handling cases where elements might be missing by providing default values.
This systematic approach ensures that the relevant details are accurately captured and returned in a structured format.
Step 4: Create a Function to Scrape Dataset Listings
Define a function scrape_datasets that takes the URL of a page listing multiple datasets, retrieves the HTML content, and finds all dataset links. For each link, it calls scrape_dataset_details to get detailed information.
def scrape_datasets(page_url): response = requests.get(page_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_list = soup.find_all( 'a', class_='link-hover link text-xl font-semibold') if not dataset_list: print("No dataset links found") return for dataset in dataset_list: dataset_link = "https://archive.ics.uci.edu" + dataset['href'] print(f"Scraping details for {dataset.text.strip()}...") dataset_details = scrape_dataset_details(dataset_link) data.append(dataset_details)Implement a loop to navigate through the pages using pagination parameters. The loop continues until no new data is added, indicating that all pages have been scraped.
skip = 0 take = 10 while True: page_url = f"https://archive.ics.uci.edu/datasets?skip={skip}&take={take}&sort=desc&orderBy=NumHits&search=" print(f"Scraping page: {page_url}") initial_data_count = len(data) scrape_datasets(page_url) if len( data ) == initial_data_count: break skip += takeStep 6: Save the Scraped Data to a CSV File
After scraping all the data, save it to a CSV file.
with open('uci_datasets.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerow(headers) writer.writerows(data) print("Scraping complete. Data saved to 'uci_datasets.csv'.")Step 7: Run the Scraping Function
Finally, call the scrape_uci_datasets function to start the scraping process.
scrape_uci_datasets()Full Code
Here is the complete code for the web scraper:
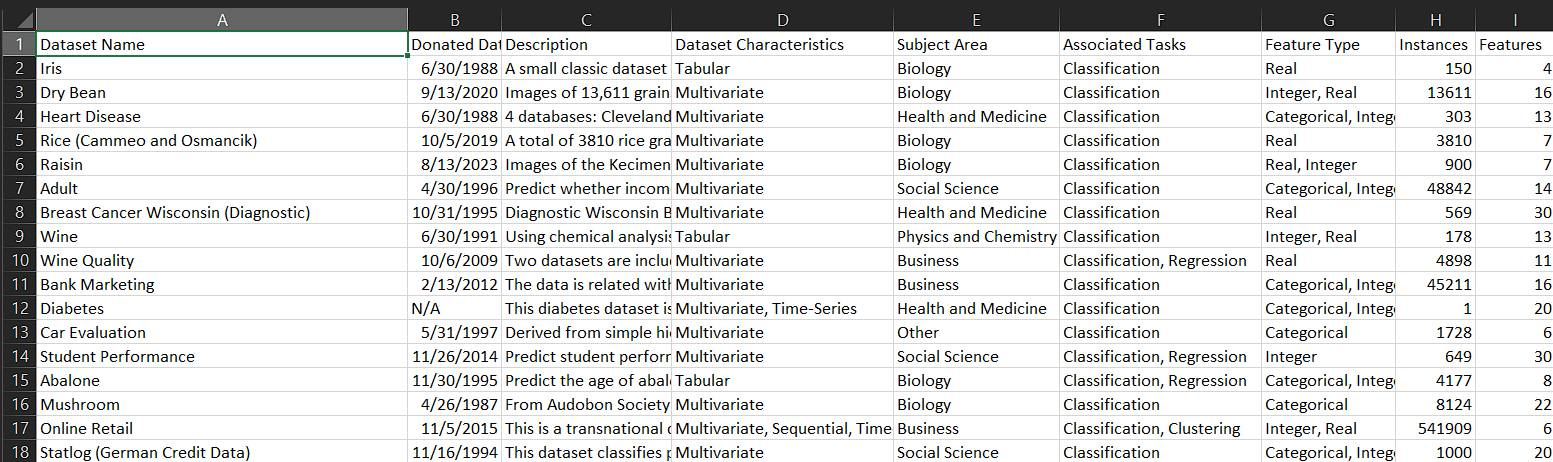
import requestsfrom bs4 import BeautifulSoupimport csvdef scrape_uci_datasets(): base_url = "https://archive.ics.uci.edu/datasets" headers = [ "Dataset Name", "Donated Date", "Description", "Dataset Characteristics", "Subject Area", "Associated Tasks", "Feature Type", "Instances", "Features" ] # List to store the scraped data data = [] def scrape_dataset_details(dataset_url): response = requests.get(dataset_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_name = soup.find( 'h1', class_='text-3xl font-semibold text-primary-content') dataset_name = dataset_name.text.strip() if dataset_name else "N/A" donated_date = soup.find('h2', class_='text-sm text-primary-content') donated_date = donated_date.text.strip().replace( 'Donated on ', '') if donated_date else "N/A" description = soup.find('p', class_='svelte-17wf9gp') description = description.text.strip() if description else "N/A" details = soup.find_all('div', class_='col-span-4') dataset_characteristics = details[0].find('p').text.strip() if len( details) > 0 else "N/A" subject_area = details[1].find('p').text.strip() if len( details) > 1 else "N/A" associated_tasks = details[2].find('p').text.strip() if len( details) > 2 else "N/A" feature_type = details[3].find('p').text.strip() if len( details) > 3 else "N/A" instances = details[4].find('p').text.strip() if len( details) > 4 else "N/A" features = details[5].find('p').text.strip() if len( details) > 5 else "N/A" return [ dataset_name, donated_date, description, dataset_characteristics, subject_area, associated_tasks, feature_type, instances, features ] def scrape_datasets(page_url): response = requests.get(page_url) soup = BeautifulSoup(response.text, 'html.parser') dataset_list = soup.find_all( 'a', class_='link-hover link text-xl font-semibold') if not dataset_list: print("No dataset links found") return for dataset in dataset_list: dataset_link = "https://archive.ics.uci.edu" + dataset['href'] print(f"Scraping details for {dataset.text.strip()}...") dataset_details = scrape_dataset_details(dataset_link) data.append(dataset_details) # Loop through the pages using the pagination parameters skip = 0 take = 10 while True: page_url = f"https://archive.ics.uci.edu/datasets?skip={skip}&take={take}&sort=desc&orderBy=NumHits&search=" print(f"Scraping page: {page_url}") initial_data_count = len(data) scrape_datasets(page_url) if len( data ) == initial_data_count: break skip += take with open('uci_datasets.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerow(headers) writer.writerows(data) print("Scraping complete. Data saved to 'uci_datasets.csv'.")scrape_uci_datasets()Once you run the script, it will run for a while until the terminal says “No dataset links found”, followed by “Scraping complete. Data saved to ‘uci_datasets.csv’”, indicating that the scraped data has been saved in a CSV file.

To view the scraped data, open the ‘uci_datasets.csv’, you should be able to see the data organized by Dataset Name, Donated Date, Description, Characteristics, Subject Area, and so on.

You can have a better view of the data if you open the file via Excel.
By following the logic mentioned in this article, you can scrape many sites. All you need to do is start from the base URL, figure out how to navigate through the list, and go to the dedicated page for each list item. Then, identify suitable page elements like IDs and classes where you can isolate and extract the data you want.
You also need to understand the logic behind pagination. Most often, pagination makes slight changes to the URL, which you can use to loop from one page to another.
Finally, you can write the data to a CSV file, which is suitable for storing and as input for visualization.
Conclusion
Using Python along with Requests and Beautiful Soup allows you to create fully functional web scrapers to extract data from websites. While this functionality can be highly advantageous for data-driven decision-making, it is important to keep ethical and legal considerations in mind.
Once you become familiar with the methods used in this script, you can explore techniques like proxy management and data persistence. You can also familiarize yourself with other libraries like Scrapy, Selenium, and Puppeteer to fulfill your data collection needs.
Thank you for reading! I’m Jess, and I’m an expert at Hyperskill. You can check out my Python developer course on the platform.