
包阅导读总结
1. 关键词:Nvidia、GPU、硬件路线图、开发者、混合精度计算
2. 总结:Nvidia 因 AI 繁荣受益,计划每年发布一款 GPU 至 2027 年。其未来 GPU 转向混合精度计算,对开发者产生影响,面临技术挑战和竞争,同时致力于更高效编码和构建 AI 超级模型。
3. 主要内容:
– Nvidia 的硬件路线图
– 计划每年发布新 GPU 至 2027 年,如 Hopper、Blackwell 等。
– 面临 Blackwell 芯片制造的技术挑战。
– 对开发者的影响
– 转向混合精度计算,改变编程框架。
– 支持更多编程语言,如 Python 等。
– 功率效率
– 追求更高效编码,减少计算循环。
– 新 GPU 能耗大但性能强,支持新的低精度数据类型。
– AI 超级模型
– 开发框架,让开发者优化大型语言模型。
– 流程复杂,开发者需掌握多种技术。
– 竞争情况
– 英特尔和 AMD 等对手努力应对 Nvidia 的 CUDA 优势。
– 多家公司组成联盟开发 CUDA 开源替代品。
思维导图: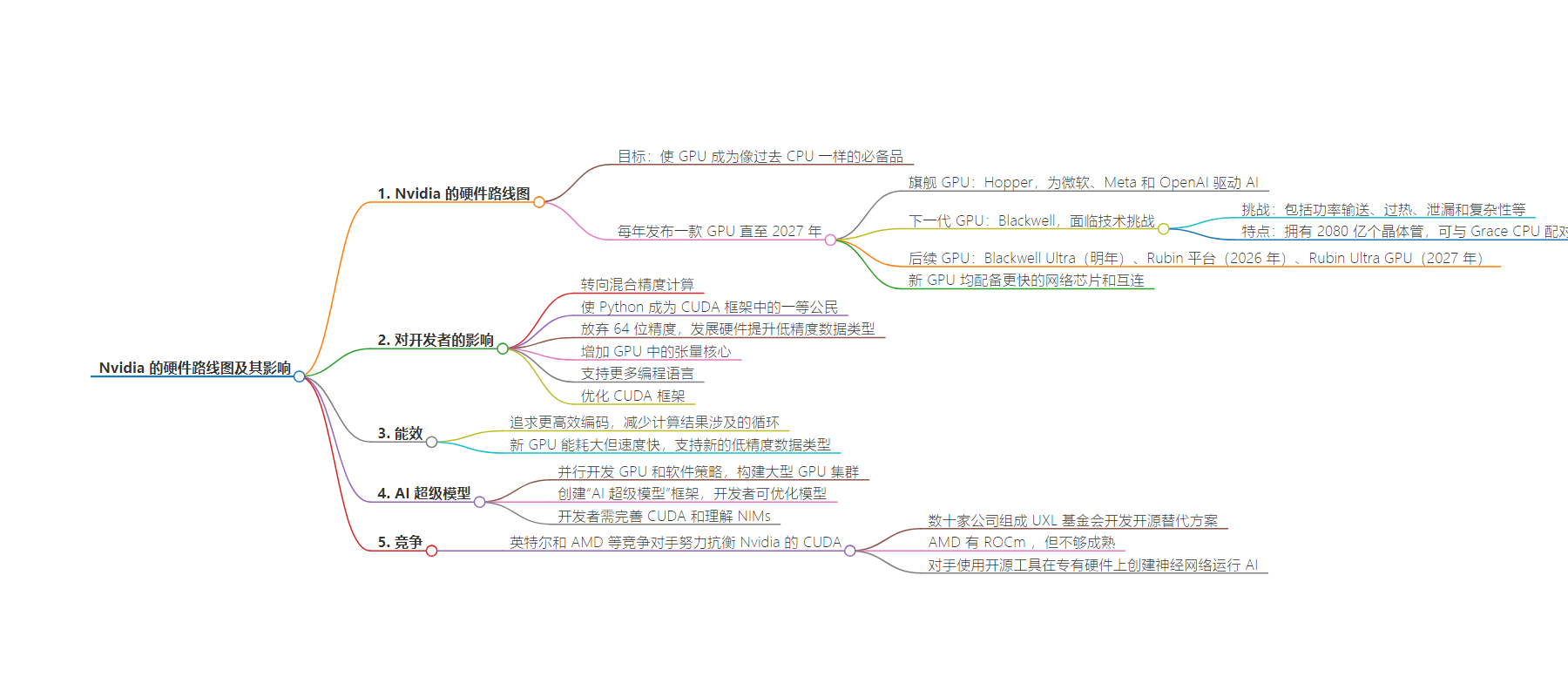
文章地址:https://thenewstack.io/nvidias-hardware-roadmap-and-its-impact-on-developers/
文章来源:thenewstack.io
作者:Agam Shah
发布时间:2024/8/12 14:08
语言:英文
总字数:1260字
预计阅读时间:6分钟
评分:90分
标签:英伟达,GPU 路线图,人工智能计算,软件开发,CUDA 框架
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Nvidia is the biggest beneficiary of the AI boom and is raking in cash from GPU sales.It is now putting its foot on the pedal with an unprecedented plan to release one GPU every year until 2027.
“Our basic philosophy is very simple,” said Nvidia CEO Jensen Huang at the Computex trade show in June. “Build the entire data center scale disaggregated and sell to you in parts on a one-year rhythm. We push everything to technology limits.”
Nvidia’s future GPUs indicate a diversified shift to mixed-precision computing, which mixes traditional and AI computing.
The likes of Microsoft and Meta are investing billions in new data centers and want the latest and greatest GPUs. As a result, Nvidia is innovating hardware technologies at a faster pace.
Financial analysts consider the company’s stock price to be at unsustainable levels. Like the dot-com boom, the AI boom will end, and Nvidia’s stock price will come down to earth. But the impact of Nvidia’s GPUs and advances will be permanent in software development.
The GPU Roadmap
Nvidia’s goal is to make GPUs a must-have in operations, much like CPUs in past years. Nvidia’s CEO Jensen Huang argues that CPUs aren’t enough, and GPUs are needed to process data faster.
“Software inertia is the single most important thing in computers. When a computer is backwards and architecturally compatible with all the software that has already been created, your ability to go to market is so much faster,” Huang said at a recent event.
All of the new GPUs are accompanied by faster networking chips and interconnects for faster server and chip communications.
Nvidia’s flagship GPU, called Hopper, drives AI for Microsoft, Meta and OpenAI. OpenAI and Microsoft are serving GPT-4 and 4.0 on Nvidia’s Hopper H100 and its predecessor A100 GPUs.
Microsoft has already placed orders for the next-generation GPUs called Blackwell, which will be in its data centers as early as next year.
But the Blackwell shipment dates are in question after Nvidia hit technical challenges in making the chip.
“This is a compute and power density that has never been achieved before, and given the system-level complexity needed, the ramp has proven challenging,” said analysts at SemiAnalysis in a report.
The challenges for Blackwell have been across the board, including power delivery, overheating, leakages and complexity, the analysts said.
Blackwell has 208 billion transistors, which makes it one of the most complex chips ever made. Up to 72 Blackwells can be packed into one rack server, and Nvidia is providing the connections to link up to 576 GPUs via Ethernet. That’s a lot of AI power.
Nvidia is pairing the Blackwell GPUs with its ARM-based Grace CPU. Nvidia is shipping its own servers with those chips, which are available in the cloud. Nvidia is trying to kill traditional programming models that pair its GPUs with x86 processors from Intel or AMD.
Nvidia next year will ship Blackwell Ultra, which, like Blackwell, will include HBM3E, but with more capacity. Following that, Nvidia in 2026 will unveil its Rubin platform, which will include an all-new GPU and CPUs and support for HBM4 memory. In 2027, Nvidia will release the Rubin Ultra GPU.
All of the new GPUs are accompanied by faster networking chips and interconnects for faster server and chip communications.
“This is basically what Nvidia is building and all of the richness of software on top of it,” Jensen said.
What it Means for Developers
Nvidia’s future GPUs indicate a diversified shift to mixed-precision computing, which mixes traditional and AI computing.
Nvidia is making Python a first-class citizen in its CUDA parallel-programming framework.
The company is abandoning its GPU focus on 64-bit precision, which is critical for accurate calculation. Instead, it is developing hardware features to boost lower-precision 4-bit, 8-bit and 16-bit data types used in probabilistic AI computing.
Nvidia is packing more tensor cores in its GPUs for matrix multiplications. An algorithm called GEMM is central to Nvidia’s AI model, as it takes advantage of the Tensor Cores and works with libraries in CUDA for programmers to interact with the GPU cores.
First and foremost, Nvidia wants to build more developers into its fold. Developers need to know C++ and Fortran for GPU programming, but Nvidia wants to support more programming languages — including Rust and Julia.
Nvidia is making Python a first-class citizen in its CUDA parallel-programming framework, including by expanding SDK and framework access to Python. The company won’t stop pouring gasoline on its C++ libraries, which are needed to unlock some of Nvidia’s GPU features.
But a warning: Once developers get stuck in CUDA, it’s hard to get out.
Power Efficiency
Nvidia is aiming for more efficient coding that reduces the loops involved to deliver computing results.
Nvidia claims its GPUs are green, but an ongoing joke among chip insiders is that the only thing green in Nvidia is its logo. Nvidia’s Blackwell GPU is a beast that consumes 1,200 watts of power and will require liquid cooling.
The upcoming GPUs will draw tremendous amounts of power but also deliver the fastest results. Blackwell will include support for new low-precision data types — FP4 and FP6 — that can squeeze out more performance per watt.
Nvidia is also preaching more efficient coding that reduces the loops involved to deliver computing results. The upcoming GPUs will include software layers that will redirect tasks to the right cores. That will also reduce the stress on coders.
AI Supermodel
Nvidia’s GPU and software strategies are being developed in parallel. The goal is to build out giant clusters of GPUs that will be able to handle AI models with trillions of parameters.
At the same time, Nvidia is creating a framework for “AI supermodels,” in which developers take a large language model and optimize it by plugging in customized models, guardrails, retrieval-augmented generation (RAG) and other tools.
Nvidia has optimized the open source Llama 3.1 for its AI supermodel strategy. Developers can arm the Llama 3.1 model with a series of adapters, Low-Rank Adaptation of Large Language (LoRA) models and guardrails to create their own model.
Nvidia has a complicated process to create AI supermodels. Developers need to figure out the ingredients of the optimized models, input localized data and determine adapters. Developers will need to implement procedures to extract and push relevant data to a vector database, which evaluates information and sends responses to users.
Developers will need to perfect CUDA and understand NIMs (Nvidia inference microservices), which are cloud native AI containers from Nvidia’s website.
The Competition
Nvidia rivals Intel and AMD are trying everything to keep developers at bay from Nvidia’s CUDA.
Dozens of companies, including Intel and Fujitsu, have formed a consortium called UXL Foundation to develop an open source alternative to CUDA.
UXL’s parallel-programming framework is built off Intel’s OneAPI. The goal is simple: a few changes in code will allow programs to run on Nvidia and non-Nvidia AI accelerators.
Of course, UXL also offers a tool to strip out CUDA code for programs to run on other AI chips, including FPGAs, ASICs and more.
AMD has ROCm, which is nowhere near maturity despite the hype.
All of the rivals use open source tools, minus internal tools to create neural networks on proprietary hardware to run AI.
But Nvidia is close to a decade ahead of its rivals with CUDA, which started in 2006 for high-performance computing and then became a force for AI.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.