
包阅导读总结
1. 时序异常检测、Embedding 空间、业务场景、样本分布、算法优化
2. 本文探讨了在 Embedding 空间中进行时序异常检测,针对安全、反作弊等业务场景下的流量与用户行为监控。介绍了传统方法及其限制,提出新方法并通过实验验证了有效性,还指出工程化应用需结合场景调整,发挥真正价值需考虑更多问题。
3.
– 传统方法
– 对流量和用户行为在业务维度上统计分析,提取指标特征,在时间维度建模分析,检测指标值是否背离历史分布规律。
– 限制:监控维度需离散可枚举、粒度合适,并非所有业务场景满足要求,攻击者会躲避检测。
– 新方法
– 将样本映射到高维空间,根据分布特征检测异常。
– 通过向量化处理、Embedding 等得到样本坐标,对分布特征建模。
– 人工构造异常样本进行实验,验证算法有效性。
– 未来应用
– 工程化应用需调整采样点数量等。
– 发挥价值要考虑更多问题。
思维导图: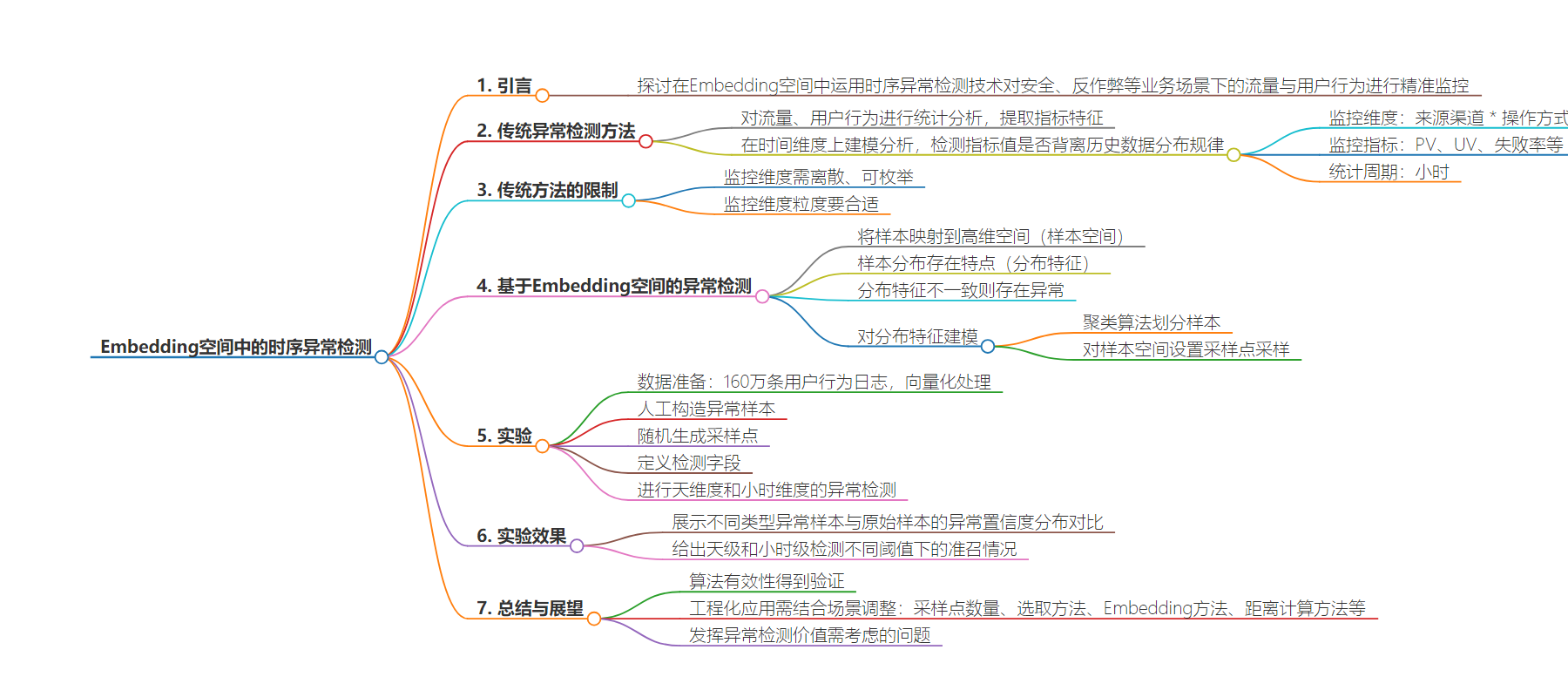
文章地址:https://mp.weixin.qq.com/s/XNb0VnQHG6421soLJWmyHQ
文章来源:mp.weixin.qq.com
作者:欢迎关注的
发布时间:2024/8/7 8:00
语言:中文
总字数:3100字
预计阅读时间:13分钟
评分:90分
标签:时序异常检测,Embedding技术,安全监控,反作弊,高维空间
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

在安全、反作弊等业务场景下,对流量、用户行为进行异常检测是基本的刚需。通常的做法是,在各个业务维度上,对流量、用户行为进行统计分析,提取出相应的指标特征,然后在时间维度上,对这些指标特征进行建模分析。再利用相关的算法来检测当前的指标值是否背离了该指标在历史数据中的分布规律。
监控的维度:来源渠道 * 操作方式 = 100 * 10 = 1000个维度
监控的指标:PV、UV、失败率…
统计周期: 小时
上面的方法,通过合理的拆分监控维度,一方面可以有效的提高检测的灵敏度,避免较少的异常流量淹没在大盘监控在随机波动中;另一方面,也可以对异常流量进行快速的定位,便于及时处理。
上面的方法也存在诸多的限制,比如:
-
监控维度必需是离散、可枚举的,否则无法建立历史数据的统计模型; -
监控维度的粒度必须合适,否则或是灵敏度不足,或是噪声太多,无法有效检测异常。
显然,不是所有的业务场景都能满足上述的要求。即便是能满足上述要求的业务场景中,随着对攻击者的对抗不断深入,攻击者会尝试降低攻击的规模,并尽量将攻击行为分散到更多的维度中,从而躲避我们的检测手段。
那么,能否不依赖业务维度拆分,直接对指标进行异常检测呢?
首先,我们需要把待检测的每一条日志、数据当做一个独立的样本。接下来,不难联想到,这些样本都可以映射到某个高维空间中,我们把这个空间叫做样本空间。可以通过向量化、Embedding等方法,得到样本在这个空间中的坐标。
样本在这个空间中的分布必然不是完全随机的,而是会存在一定的特点(分布特征)。若当前时刻样本在这个空间中的分布特征与历史数据中的分布特征不一致,则说明当前样本存在异常。而分布在差异最大的区域中的样本,则可以认为是异常样本。
接下来的问题就变成了如何对这种分布特征进行建模?
最先想到的是,我们可以通过聚类算法,来对样本进行划分,再对每个Cluster,提取出统计特征。但在具体实现时还需要考虑以下问题:
-
Cluster的划分要尽可能稳定,才能在时间维度上执行异常检测。
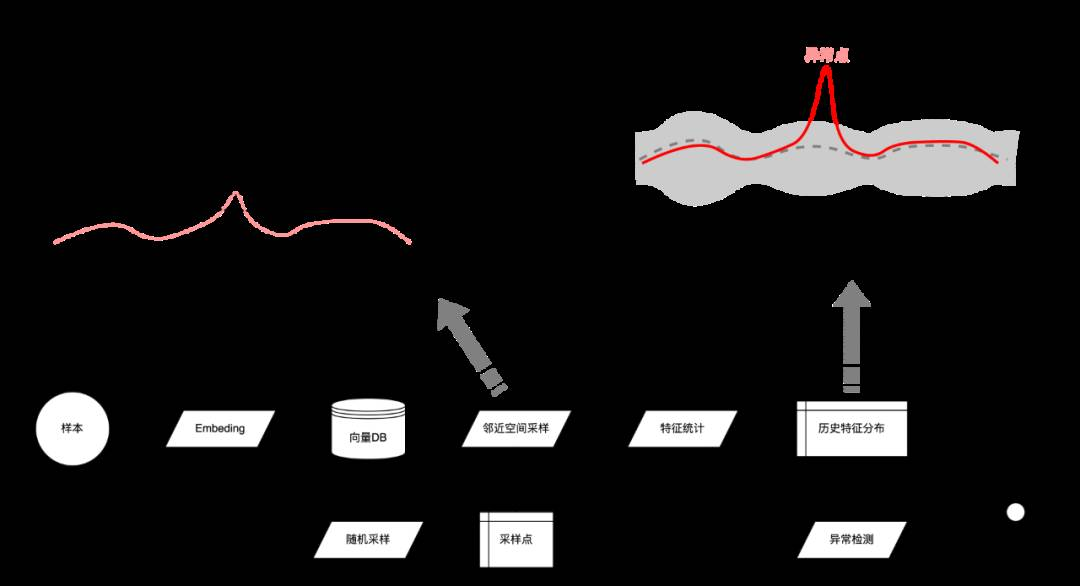
取某业务场景下近30天的用户行为日志,约160万条,利用其中的UserAgent信息,对其进行向量化处理。每条日志的向量长度为128维。
向量化算法:
def to_vector(ua):if isinstance(ua, (list, tuple)):return [to_vector(c) for c in ua]else:vec = np.zeros(128)for c in ua:vec[ord(c) % 128] += 1l2 = np.sqrt(np.sum(vec * vec))if l2 != 0:vec /= l2return vec.tolist()
for day in days:for hour in hours:event_day = day.strftime("%Y%m%d")event_hour = "{:02d}".format(hour)collection = chroma_client.get_or_create_collection(name="{}_{}_{}".format(name_prefix, event_day, event_hour))sub_df = df_ua_pv[(df_ua_pv.event_day == event_day) & (df_ua_pv.event_hour == event_hour)]ids = [hashlib.md5(bytes(str(row), "utf-8")).hexdigest() for _, row in sub_df.iterrows()]docs = [row.ua for _, row in sub_df.iterrows()]metadatas = [{"pv": row.pv} for _, row in sub_df.iterrows()]embeddings = [to_vector(row.ua) for _, row in sub_df.iterrows()]batch_size = 10000for batch_id in range(0, len(docs), batch_size):collection.upsert(ids=ids[batch_id : batch_id + batch_size],documents=docs[batch_id : batch_id + batch_size],metadatas=metadatas[batch_id : batch_id + batch_size],embeddings=embeddings[batch_id : batch_id + batch_size],)print("{:>8d} / {}".format(batch_id + batch_size, len(docs)))collections[event_day + event_hour] = collection
为了更方便的验证算法的有效性,在数据集中,人工构造了一些异常样本,包括:
-
个别随机UA,PV增长:10%, 20%, 50%, 100%, 200%, 500%,1000%;数量:5;min_pv=100。
-
部分相似UA,PV增长:5%,10%,20%, 50%, 100%;数量:10, 20, 50, 100;min_pv=10。
-
生成相似UA,PV同比增长,数量:10, 20, 50, 100。
-
生成相似UA,整体PV不增长,数量:10, 20, 50, 100;min_pv=1。
随机生成采样点:
query_ua_list = (df_ua_pv[(df_ua_pv.event_day == event_day) & (df_ua_pv.event_hour == event_hour)].sample(100)["ua"].to_list())
在样本空间进行邻近采样:
results = []query_ua_vec = to_vector(query_ua_list)for day in days:for hour in hours:res = get_collection(day, hour).query(query_embeddings=query_ua_vec, n_results=n_results)for i in range(len(query_ua_list)):for j in range(n_results):row = [query_ua_list[i],res["metadatas"][i][j]["event_day"],res["metadatas"][i][j]["event_hour"],res["documents"][i][j],res["metadatas"][i][j]["pv"],res["distances"][i][j],]if extra_fields:for field in extra_fields:row.append(res["metadatas"][i][j].get(field))results.append(row)cols = ["ua", "day", "hour", "doc", "pv", "dist"]if extra_fields:cols += extra_fieldsdf_results = pd.DataFrame(results, columns=cols)
定义要检测的字段:
AREA_EXP = [0, 2, 8]MODEL_FIELDS = ["pv", "dist"]MODEL_FIELDS += [f"dens_{i}" for i in AREA_EXP]MODEL_FIELDS += ["dens_s"]MODEL_AGGS = {}for col in MODEL_FIELDS:MODEL_AGGS[f"{col}_mean"] = (col, "mean")MODEL_AGGS[f"{col}_std"] = (col, "std")
进行天维度的异常检测:
df_query_results["dens_s"] = 1 / (df_query_results["dist"] ** 0.5 + 1)df_res_agg = df_query_results.groupby(["ua", "day"], as_index=False).agg(pv=("pv", "sum"),dist=("dist", "mean"),dens_s=("dens_s", "mean"),)for i in AREA_EXP:df_res_agg["area_{}".format(i)] = (df_res_agg["dist"] * 10) ** idf_res_agg["dens_{}".format(i)] = df_res_agg["pv"] / df_res_agg["area_{}".format(i)]df_model = df_res_agg[df_res_agg.day <= last_event_day].groupby("ua").agg(**MODEL_AGGS)df_check = df_res_agg.join(df_model, on="ua")for col in MODEL_FIELDS:df_check[f"{col}_sigma"] = (df_check[col] - df_check[f"{col}_mean"]) / df_check[f"{col}_std"]df_check["dens_avg_sigma"] = df_check[["dens_s_sigma"] + [f"dens_{i}_sigma" for i in AREA_EXP]].mean(axis=1)df_check["dens_max_sigma"] = df_check[["dens_s_sigma"] + [f"dens_{i}_sigma" for i in AREA_EXP]].max(axis=1)df_check["dens_min_sigma"] = df_check[["dens_s_sigma"] + [f"dens_{i}_sigma" for i in AREA_EXP]].min(axis=1)
实验效果
个别随机UA,PV增长:10%, 20%, 50%, 100%, 200%, 500%,1000%;数量:5;min_pv=100。
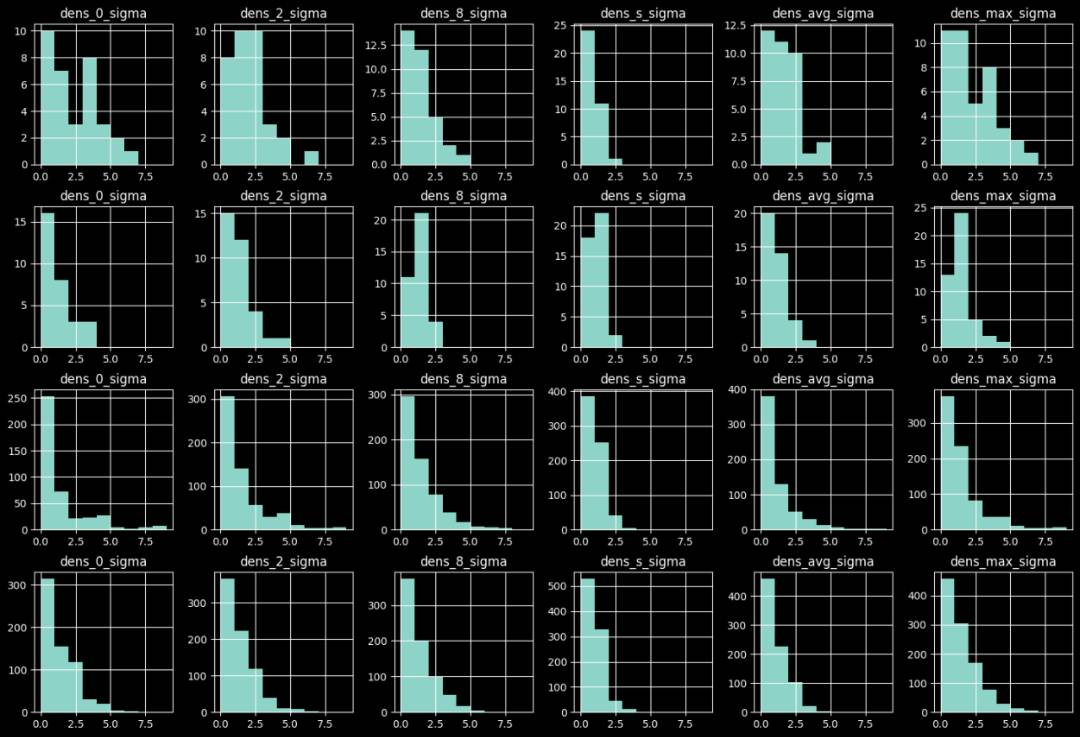
异常样本与原始样本的异常置信度分布对比如下图,由上到下分别为:
-
天级检测下异常样本的置信度分布;
-
天级检测下正常样本的置信度分布;
-
小时级检测下异常样本的置信度分布;
-
小时级检测下正常样本的置信度分布。
天级检测不同阈值下的准召情况:
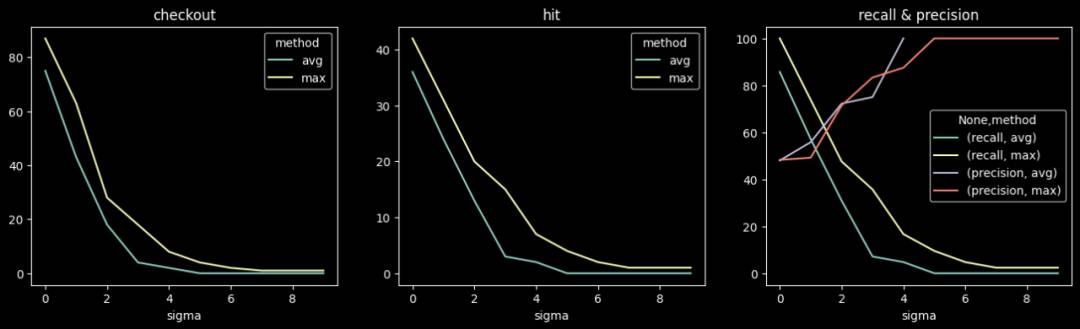
小时级检测不同阈值下的准召情况:
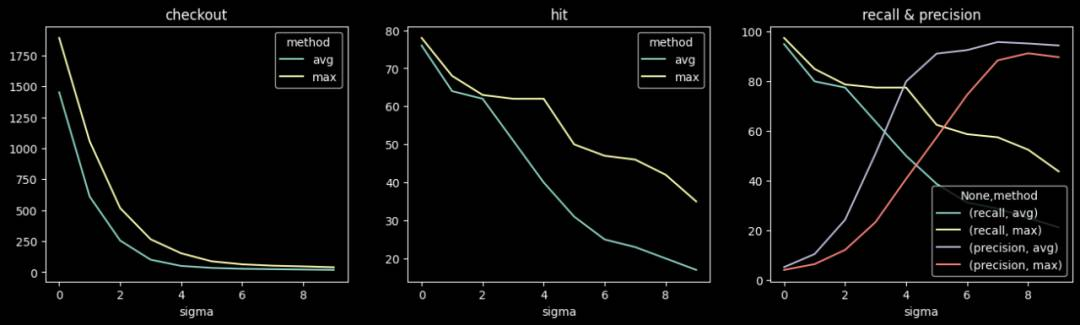
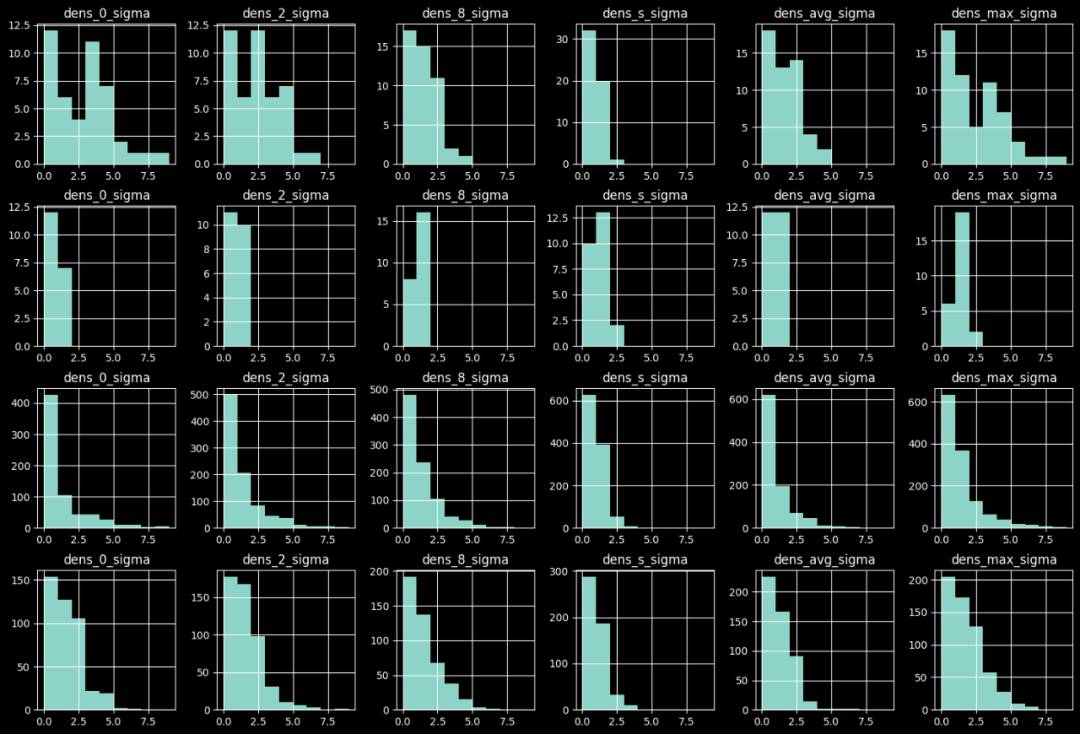
部分相似UA,PV增长:5%,10%,20%, 50%, 100%;数量:5, 10, 20; min_pv=10。
异常样本与原始样本的异常置信度分布对比如下图,由上到下分别为:
-
天级检测下异常样本的置信度分布;
-
天级检测下正常样本的置信度分布;
-
小时级检测下异常样本的置信度分布;
-
小时级检测下正常样本的置信度分布。
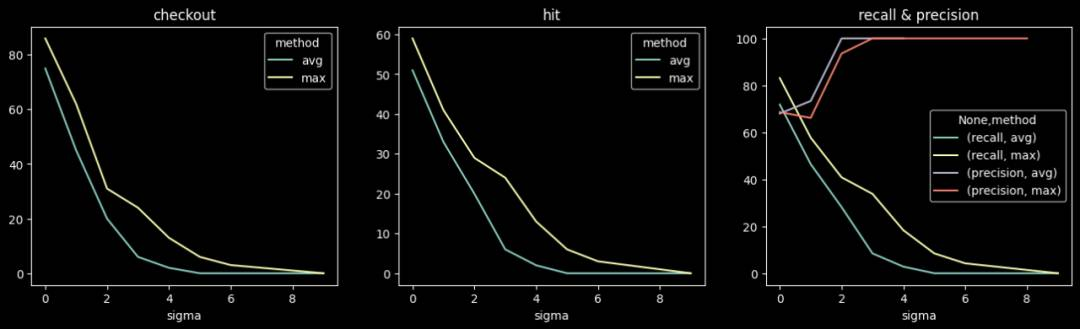
天级检测不同阈值下的准召情况:
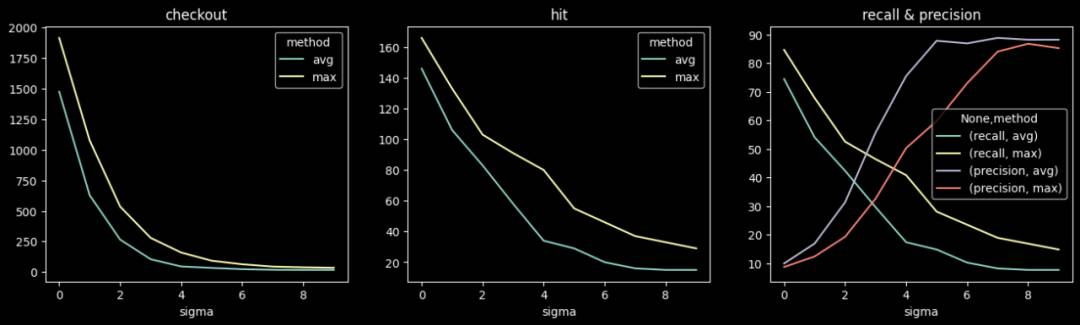
小时级检测不同阈值下的准召情况:
生成相似UA,PV同比增长,数量:5, 10, 20, 50, 100。
异常样本与原始样本的异常置信度分布对比如下图,由上到下分别为:
-
天级检测下异常样本的置信度分布;
-
天级检测下正常样本的置信度分布;
-
小时级检测下异常样本的置信度分布;
-
小时级检测下正常样本的置信度分布。

天级检测不同阈值下的准召情况:
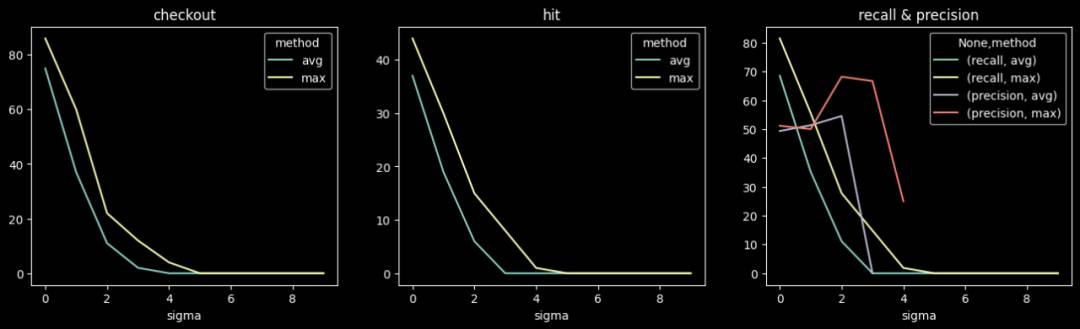
小时级检测不同阈值下的准召情况:
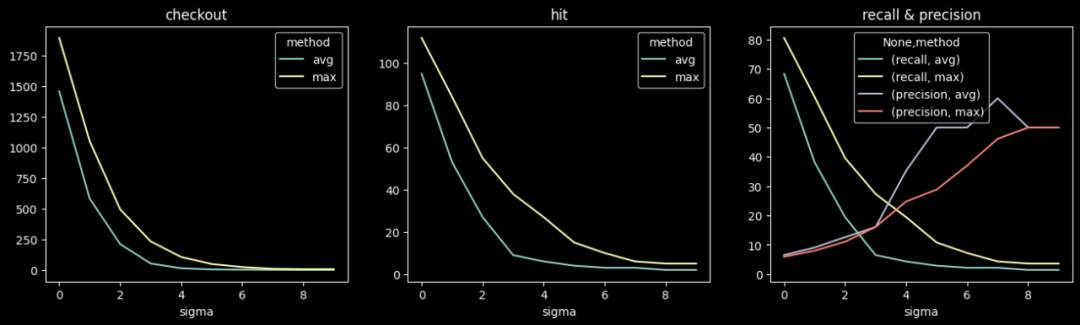
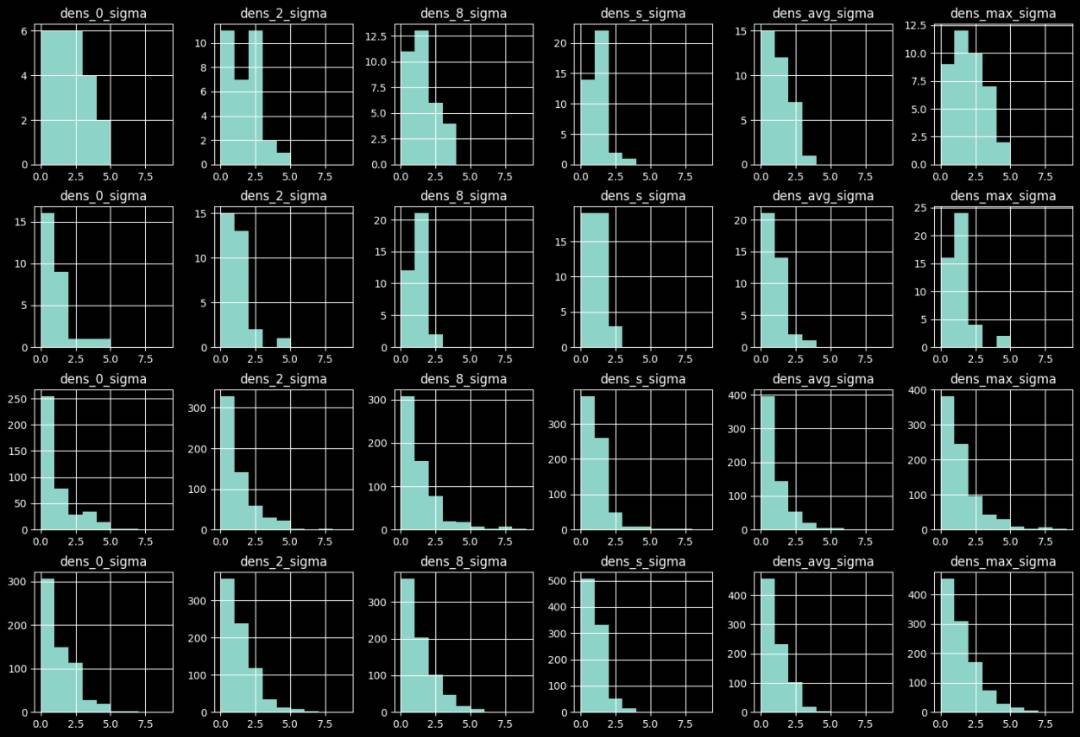
生成相似UA,整体PV不增长,数量:10, 20, 50, 100;min_pv=1。
异常样本与原始样本的异常置信度分布对比如下图,由上到下分别为:
-
天级检测下异常样本的置信度分布;
-
天级检测下正常样本的置信度分布;
-
小时级检测下异常样本的置信度分布;
-
小时级检测下正常样本的置信度分布。
天级检测不同阈值下的准召情况:
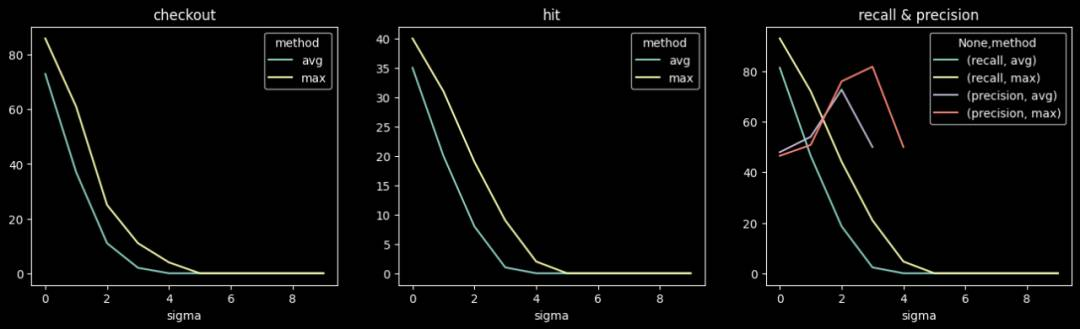
小时级检测不同阈值下的准召情况:
此外,在实践中,若要发挥出异常检测的真正价值,还需要考虑以下问题: